

В посте расскажу о моем успешном взаимодействии с некоммерческим проектом ЗабастКом, который поддерживает наемных работников в отстаивании своих трудовых прав и интересов. Моя цель была реализовать что-то похожее на ML4SG проект, где волонтеры-специалисты по анализу данных направляют свою энергию на пользу обществу. Например, применяют алгоритмы искусственного интеллекта для спасения потерявшихся людей, для мониторинга качества воздуха или для анализа новостного потока.
Для Забасткома получилось улучшить систему автоматической обработки новостей с помощью алгоритмов машинного обучения. Это привело к увеличению охвата важных событий и уменьшению ручного труда редакторов. Добавлю, что работа с ребятами была похожа на мечту любого DS специалиста: "заказчик" легко шел на контакт; присутствовала заинтересованность и неплохое понимание ML алгоритмов; некоторая продакшн-система уже функционировала; данные для обучения алгоритмов легко собирались. А под катом — поделюсь подробностями и кодом.
О проекте

ЗабастКом — это содружество технических специалистов, которые неравнодушны к проблемам наемных работников и которые решили вместе освещать трудовые конфликты в России и странах ближнего зарубежья. Среди волонтеров этого проекта есть ребята из Yandex, VK, Tinkoff, OZON и других известных компаний. Трудовой конфликт – это когда ваш рабочий коллектив “нагрели” с зарплатой, обманули в процессе трудоустройства или как-то несправедливо поступили, а вы — организованно возмутились. Как показывает практика, чем громче и шире подобная новость разойдется в обществе, тем быстрее будет оказана помощь работникам, сглажена несправедливость и решена проблема. А Забастком как раз нацелен на максимальную огласку новости. Для этого у проекта есть свой новостной интернет-портал, база данных, мобильные приложения, telegram канал и др. соцсети, где оперативно публикуются отобранные редакторами новости. Отобранная информация может быть полезна другим активистам, которые оперативно оказывали бы бастующим юридическую и другую помощь. Все ПО Забасткома разработано и поддерживается добровольцами-активистами. Внутри проекта чувствуется атмосфера небольшой НКО или ИТ стартапа.
Подобной активностью занимаются и международные организации. Например, BHHRC следит за влиянием компаний на своих работников по всему миру. В своем октябрьском докладе и документе BHHRC приводит данные о систематическом нарушении прав трудящихся на предприятиях легкой промышленности в странах Азии. В документе приводятся причины возникающих забастовок и трудовых конфликтов между собственником предприятия и коллективом наемных работников:
- ухудшение условий труда
- необоснованное снижение заработной платы
- отмена оплаты сверхурочных работ
- сокращения и увеличение нагрузки
- экономия на защите жизни и здоровья
- увеличение продолжительности рабочего дня
- хищение заработной платы, выходных и др. пособий
Негодование коллектива усиливается ввиду вышеперечисленного на фоне увеличения чистой прибыли их компании, подобно этой ситуации. Трудящиеся недовольны, когда прибыль возрастает за счет экономического наступления на их права. Часто выходит так, что профессия человека может быть применима только на одном предприятии его города, нет возможности сменить компанию. А еще единственное градообразующее предприятие могут искусственно банкротить. Поэтому пикеты, забастовки и стачки являются ответной реакцией работников на действия руководства, если другие формы выражения коллективных требований (обращение, жалоба, протест) были проигнорированы. Акции рабочего протеста не направлены против потребителей производимого товара или пользователей.
У проекта ЗабастКом есть собственный API. Любой желающий может написать программный запрос и получить доступ к пополняющейся базе данных. База данных накоплена за 5 лет и содержит информацию об освещенных забастовках, пикетах, жалобах и результатах этих конфликтов. Использование API может осуществляться свободно и бесплатно, но без целей извлечения прибыли.
# python
import json
import requests
LINK = 'https://zabastcom.org/api/v2/all/events'
r = requests.get(LINK, params={'perPage': 100, 'page': 1})
r = json.loads(r.text)
print('Events:', r['meta'])
# Events: {'total': 5570, 'currentPage': 1, 'perPage': 100, 'lastPage': 56}
print('Number of events on current page:', len(r['data']), '\n')
# Number of events on this page: 100
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(r['data'][0]){ 'conflict': { 'automanagingMainType': False,
'companyName': 'Алтайский краевой кардиологический '
'диспансер',
'conflictReasonId': 1,
'conflictResultId': 7,
'createdAt': 1672223749,
'dateFrom': 1672223670,
'dateTo': None,
'id': 3314,
'industryId': 10,
'latitude': 53.368935,
'longitude': 83.70607,
'mainTypeId': 9,
'parentEventId': None,
'titleDe': None,
'titleEn': None,
'titleEs': None,
'titleRu': 'Невыплата годовой премии медсестрам '
'барнаульского Кардиоцентра'},
'conflictId': 3314,
'contentDe': None,
'contentEn': None,
'contentEs': None,
'contentRu': 'В Барнауле прокуратура начала проверку после жалоб медсестер '
'Алтайского краевого кардиологического диспансера на '
'невыплату итоговой премии за год. Деньги пообещали дать '
'врачам и младшему медперсоналу, а вот средний медперсонал '
'финансовой помощи лишили.',
'createdAt': 1672223877,
'date': 1672223752,
'eventStatusId': 2,
'eventTypeId': 9,
'id': 5905,
'latitude': 53.368935,
'longitude': 83.70607,
'photoUrls': [ 'https://api.amic.ru/uploads/news/images/6A490C7E5FEE4C749EDF9DB8A6A3F324.png'],
'published': True,
'sourceLink': 'https://www.amic.ru/news/medicine/prokuratura-nachala-proverku-posle-zhaloby-medsester-barnaulskogo-kardiocentra-na-otmenu-godovoy-itogovoy-vyplaty',
'tags': [],
'titleDe': None,
'titleEn': None,
'titleEs': None,
'titleRu': 'Жалоба медсестёр барнаульского кардиоцентра',
'videos': [],
'views': 348}Визуализируем данные
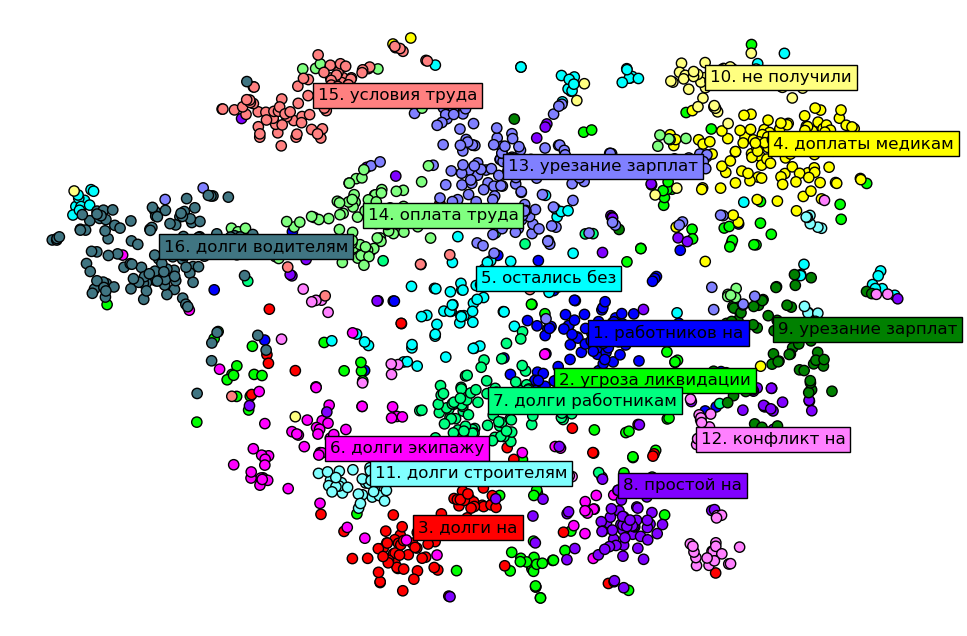
На визуализации показана кластеризация трудовых конфликтов на основе поля 'titleRu' для всех данных из API. Алгоритм кластеризации объединил схожие по смыслу тексты в группы. В каждой группе найдено самое частое словосочетание. Оси графика не являются интерпретируемыми, однако похожие тексты лежат близко друг к другу, а менее похожие — дальше друг от друга. По рисунку видно, что проблемы работников в СНГ мало чем отличаются от проблем, описанных в докладе BHHRC, и от проблем зарубежных наемных работников в странах Азии, Европы или Америки.
Для каждого текста был получен 312-размерный эмбеддинг помощью дистилированного берта. Для проектирования 312-размерных эмбеддингов на 2-размерное пространство использовал алгоритм t-SNE с метрикой косинусного расстояния. Для кластеризации выбрал K-Means с метрикой косинусного расстояния.
# python
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics import pairwise_distances
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
def embed_bert_cls(text,model,tokenizer):
t = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**{k: v.to(model.device) for k, v in t.items()})
embeddings = model_output.last_hidden_state[:, 0, :]
embeddings = torch.nn.functional.normalize(embeddings)
return embeddings[0].cpu().numpy()
def get_bert_emb(list_of_texts):
# https://huggingface.co/cointegrated/rubert-tiny2
HF_model = "cointegrated/rubert-tiny2"
tokenizer = AutoTokenizer.from_pretrained(HF_model)
sent2vec = AutoModel.from_pretrained(HF_model)
embeddings = []
for i in range(len(list_of_texts)):
embeddings.append(embed_bert_cls(list_of_texts[i], sent2vec, tokenizer))
return np.array(embeddings)
def get_clusters(embeddings,n_clusters):
model = KMeans(n_clusters=n_clusters, random_state=42)
length = np.sqrt((embeddings**2).sum(axis=1))[:,None]
embeddings_ = embeddings/length
clusters = model.fit_predict(embeddings_)
idx_clusters = []
for x in np.unique(clusters):
idx_clusters.append(np.where(clusters==x)[0].tolist())
keywords_clusters = []
for i in range(n_clusters):
corpus_cluster = []
for j in range(len(list_of_texts)):
if clusters[j]==i:
corpus_cluster.append(list_of_texts[j].lower())
vectorizer = CountVectorizer(analyzer='word', ngram_range=(2, 2))
Y = vectorizer.fit_transform(corpus_cluster)
id_max = Y.toarray().sum(axis=0).argmax()
keywords_clusters.append(vectorizer.get_feature_names_out()[id_max])
return clusters,idx_clusters,keywords_clusters
def get_plot(embeddings,clusters,keywords_clusters,perplexity=30):
# get 2D projection of embeddings
distance_matrix = pairwise_distances(embeddings,embeddings,
metric='cosine',
n_jobs=-1)
model = TSNE(n_components=2,
perplexity=perplexity,
learning_rate='auto',
init='random',
metric="precomputed",
square_distances=True,
random_state = 42)
embeddings_2D = model.fit_transform(distance_matrix)
# visualize
colors = np.array([[0.,0.,1.],[0.,1.,0.],
[1.,0.,0.],[1.,1.,0.],
[0.,1.,1.],[1.,0.,1.],
[0.,1.,0.5],[0.5,0.,1.],
[0.,0.5,0.],[1.,1.,0.5],
[0.5,1.,1.],[1.,0.5,1.],
[0.5,0.5,1.],[0.5,1.,0.5],
[1.,0.5,0.5],[0.25,0.46,0.51]]*3)
fig, ax = plt.subplots(figsize=(12,8))
for i in np.unique(clusters):
ax.scatter(embeddings_2D[clusters==i][:, 0], embeddings_2D[clusters==i][:, 1],
c=np.array([colors[i]]*len(embeddings_2D[clusters==i])),
edgecolors='black', s=55, label=i)
ax.text(np.median(embeddings_2D[clusters==i][:, 0]),
np.median(embeddings_2D[clusters==i][:, 1]),
f'{i+1}. '+keywords_clusters[i], size=12,
bbox=dict(boxstyle="square",ec=(0., 0., 0.),fc=colors[i]))
# plt.legend(fontsize=10)
plt.axis('off')
plt.show()
#////////////////////////////////////////////////////////////////////////////
list_of_texts = ['Ковидные доплаты медикам', # 0
'Урезание зарплат работникам супермаркета', # 1
'Долги работникам организации утилизирующей отходы', # 2
'Снижения зарплат курьерам', # 3
'Долги работникам светотехнического предприятия', # 4
'Оплата и условия труда на месторождении', # 5
'Жалоба медиков', # 6
'Долги работникам строительной компании', # 7
'Нарушение условий соглашения с рабочими', # 8
'Урезание зарплат рабочим котельной', # 9
'Доплаты медикам медсанчасти', # 10
'Ухудшение условий труда медиков', # 11
'Задержка и урезание зарплат на заводе', # 12
'Отсутствие доплат медикам', # 13
'Долги работникам фабрики дверей'] # 14
embeddings = get_bert_emb(list_of_texts)
clusters,idx_clusters,keywords_clusters = get_clusters(embeddings,n_clusters=4)
print('Индексы текстов в группах: ',idx_clusters)
# Индексы текстов в группах: [[8, 11], [1, 3, 5, 9, 12], [0, 6, 10, 13], [2, 4, 7, 14]]
get_plot(embeddings,clusters,keywords_clusters,perplexity=2)Разрабатываем классификатор новостей

Ребятам нужно уметь оперативно выделять информацию о забастовках в огромном новостном потоке. За 5 лет существования проекта подходы к поиску интересующих новостей постоянно улучшались. В ноябре 2022 года процесс был настроен так: парсеры автоматически собирали тексты новостей из сотен источников; далее работали алгоритмы фильтрации на основе простых правил и ключевых слов; после – редакторы в ручном режиме проверяли каждую новость. Алгоритмы фильтрации работали, но могли пропускать важные новости о забастовках или, наоборот, могли выдавать много новостей на сторонние темы. Поэтому улучшение алгоритмов фильтрации с помощью ML-классификатора стало очень актуальной задачей. Без решения этой задачи было невозможно масштабирование проекта без привлечения значительных усилий.
Для неподготовленных читателей посоветую прочитать ml ликбез и приведу простой пример классификации текста с помощью машинного обучения: в любой электронной почте есть детектор спама. Это алгоритм, который умеет отличать хорошее письмо от плохого письма-спама. Чтобы научить алгоритм решать эту задачу, нужно показать ему примеры решения этой задачи человеком. То есть нужно подготовить примеры спам-писем и хороших писем. Во время обучения алгоритм самостоятельно найдет, какие слова, словосочетания и группы символов часто присутствуют в спам письмах. После обучения он сможет оценивать текст каждого нового письма на принадлежность к спаму.
Про модели: Ребята уже задумывались о внедрении машинного обучения в процесс фильтрации и даже пробовали конструировать прототип. Им хотелось, чтобы ML-алгоритм мог относить каждый текст новости к одному из двух классов: класс 1 — если текст о трудовом коллективном конфликте и его стоит посмотреть редактору, класс 0 – если новость про что-то другое и на нее не нужно тратить время. Этот ML-алгоритм мог бы работать вместе с правилами фильтрации или вместо них. Поэтому после короткого обсуждения было решено взять побольше данных для обучения, сделать качественную предобработку текстов и обучить линейную модель для бинарной классификации с tf-idf векторизацией. Word2Vec/FastText, CNN/RNN сеточки, трансформерные эмбеддинги решили пока не применять, так как вычислительные ресурсы проекта пока слабы.
Обучающие данные собрать было легко: примеры новостей класса 1 взяли из базы данных проекта, выгрузив из API. Примеры новостей класса 0 запарсили за тот же временной промежуток. Класс 0 можно было бы дополнить известными датасетами новостей. В итоге получился такой баланс классов: класс 1 — около 5 тыс. примеров; класс 0 — около 300 тыс. примеров.
Про предобработку текстов: линейным моделям можно помочь — для этого нужно как можно сильнее уменьшить размер общего словаря слов в данных с помощью удаления неинформативных слов и лемматизации. А с помощью NER моделей из библиотеки natasha можно автоматически заменять группы слов на один и тот же токен:
- все ФИО заменяются на слово _пер
- все названия организаций заменяются на слово _орг
- все названия стран, городов, районов и тд заменяются на слово _лок
- все числа, написанные цифрами или буквами, заменяются на слово _чсл
- все названия месяцев, год и др. заменяются на слово _дат
# python
import re
from natasha import Segmenter,MorphVocab,NewsEmbedding,NewsMorphTagger,Doc
from navec import Navec
from slovnet import NER
rename_dict = {'ORG': ' _орг ',
'PER': ' _пер ',
'LOC': ' _лок '}
text_numbers = ['ноль', 'нуль', 'один', 'два', 'три','четыре','пять',
'шесть','семь','восемь','девять','десять',
'одиннадцать','двенадцать','тринадцать','четырнадцать',
'пятнадцать','шестнадцать','семнадцать','восемнадцать','девятнадцать',
'двадцать','тридцать','сорок','пятьдесят','шестьдесят',
'семьдесят','восемьдесят','девяносто',
'сто','двести','триста','четыреста','пятьсот',
'шестьсот','семьсот','восемьсот','девятьсот',
'тысяча','миллион','миллиард','триллион',
'полтысяча','полмиллиона','полмиллиард','полумиллиард','полмиллиарда',
'полутриллион','полтриллиона','млрд','млд','млн']
dats = ['декабрь','январь','февраль','март','апрель','май',
'июнь','июль','август','сентябрь','октябрь','ноябрь',
'понедельник','вторник','среда','четверг','пятница','суббота','воскресение']
stops = ['что','как','все','она','так','его','только','мне',
'было','меня','еще','нет','ему','теперь','когда','даже',
'вдруг','если','уже','или','быть','был','него','вас',
'нибудь','опять','вам','ведь','там','потом','себя','ничего',
'может','они','тут','где','есть','надо','ней','для',
'тебя','чем','была','сам','чтоб','без','будто','чего',
'раз','тоже','себе','под','будет','тогда','кто','этот',
'того','потому','этого','какой','совсем','ним','здесь','этом',
'один','почти','мой','тем','чтобы','нее','сейчас','были',
'куда','зачем','всех','никогда','можно','при','наконец','два',
'другой','хоть','после','над','больше','тот','через','эти',
'нас','про','всего','них','какая','много','разве','три',
'эту','моя','впрочем','хорошо','свою','этой','перед','иногда',
'лучше','чуть','том','нельзя','такой','более','всегда','конечно',
'всю','между','это','вовремя','вновь','вовсе']
class News_cleaner:
def __init__(self,path_navec_weights,path_ner_weights):
self.stops = set(stops)
self.ner = self.prepare_ner(path_navec_weights, path_ner_weights)
self.morph_vocab = MorphVocab()
self.segmenter = Segmenter()
self.morph_tagger = NewsMorphTagger(NewsEmbedding())
def prepare_ner(self,path_navec_weights,path_ner_weights):
navec = Navec.load(path_navec_weights)
ner = NER.load(path_ner_weights)
ner.navec(navec)
return ner
def clean_text(self,text):
ner_tokens = self.ner(text)
text = text.lower()
lemm_tokens = []
doc = Doc(text)
doc.segment(self.segmenter)
doc.tag_morph(self.morph_tagger)
for x in doc.tokens:
flag = False
for span in ner_tokens.spans:
if span.start<=x.start and span.stop>=x.stop:
flag = True
y = rename_dict[span.type]
lemm_tokens.append(y)
break
if flag==False:
x.lemmatize(self.morph_vocab)
y = x.lemma
lemm_tokens.append(y)
text = ' '.join(lemm_tokens)
text = re.sub(r'\d+',r' _чсл ',text)
for x in text_numbers:
text = text.replace(' '+x+' ',' _чсл ')
for x in dats:
text = text.replace(' '+x+' ',' _дат ')
text = re.sub(r'[^а-я_ ]',r' ',text)
text = re.sub(r' _ ',r' ', text)
text = ' '.join([w for w in text.split() if len(w)>2])
text = ' '.join([w for w in text.split() if w not in self.stops])
text = re.sub(r'(_орг )+',r'_орг ',text+' ')
text = re.sub(r'(_пер )+',r'_пер ',text+' ')
text = re.sub(r'(_лок )+',r'_лок ',text+' ')
text = re.sub(r'(_чсл )+',r'_чсл ',text+' ')
text = re.sub(r'(_дат )+',r'_дат ',text+' ')
return text.strip()
#//////////////////////////////////////////////////////////////////////////////////////
# weighs from github.com/natasha/navec and github.com/natasha/slovnet
path_navec_weights = './resources/navec_news_v1_1B_250K_300d_100q.tar'
path_ner_weights = './resources/slovnet_ner_news_v1.tar'
cleaner = News_cleaner(path_navec_weights,path_ner_weights)
text = 'В Лондоне курьеры ООО "Рога и копыта" во главе с Ивановым \
уже объявляли предупредительную забастовку на два дня в мае 2020 г.'
result = cleaner.clean_text(text)
print(result)
#_лок курьер _орг глава _пер объявлять предупредительный забастовка _чсл день _дат _чсл
Для анализа обученного классификатора можно посмотреть на самые сильные слова-триггеры, на которые модель обращает внимание при отнесении текста к классу 1. Метрика ROC AUC, равная 0.992 на валидации, выглядит неплохо, но в триггерах присутствуют слова, обозначающие профессии людей:

Для повышения универсальности модели слова-профессии можно заменить на какой-нибудь токен _прф в следующих экспериментах. Для этого, по хорошему, нужно применить NER модель. Но можно обойтись костылем на основе большого словаря профессий и синонимов, найденных с помощью word2vec.
Разрабатываем дедубликатор новостей

В новостном потоке появляется много дубликатов, когда несколько СМИ пишут про одно и то же событие. Иногда СМИ просто перепечатывает новость из другого источника с минимальными изменениями текста. Чтобы редакторы не тратили время на просмотр текстовых копий, нужна система, которая автоматически удаляет дубликаты. Для этого в NLP существует задача text similarity. При решении этой задачи каждый текст превращается в вектор чисел (BOW, tf-idf, doc2vec, взвешенная сумма эмбеддингов слов word2vec, эмбеддинг из sentence-трансформера) и полученные вектора сравниваются по некоторой метрике. Я реализовал через tf-idf векторизацию и косинусное расстояние с высоким порогом сходства.
# python
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
class Dedublicator:
def __init__(self):
self.vectorizer = TfidfVectorizer()
def get_embeddings(self,list_of_texts):
#list_of_texts = clean_texts(list_of_texts)
embeddings = self.vectorizer.fit_transform(list_of_texts)
return embeddings
def find_duplicates(self,list_of_texts,sim=0.95):
sim = round(sim,2)
if not (-1<=sim<=1):
raise ValueError('sim-threshold have to be in [-1,1]')
embeddings = self.get_embeddings(list_of_texts)
clusters = np.array([-1]*len(list_of_texts))
for i in range(len(list_of_texts)):
if clusters[i]==-1:
tj = (clusters==-1)
cos_dist = embeddings[tj,:].dot(embeddings[i,:].T).T.toarray()[0]
cos_dist = np.round(cos_dist,2)>=sim
clusters[tj] += cos_dist.astype(np.int32)*(i+1)
idx_clusters = []
for x in np.unique(clusters):
idx_clusters.append(np.where(clusters == x)[0].tolist())
return idx_clusters
data = ['my text1', # i=0
'our text2', # i=1
'our text3', # i=2
'my text1', # i=3
'your text4'] # i=4
ded = Dedublicator()
print(ded.find_duplicates(data,0.9)) #[[0, 3], [1], [2], [4]]
print(ded.find_duplicates(data,0.3)) #[[0, 3], [1, 2], [4]]Результаты

За месяц работы с командой проекта удалось разработать и запустить в работу классификатор и дедубликатор новостей. Это привело к увеличению охвата важных событий и уменьшило количество ручного труда редакторов. Косвенно возросла оперативность реагирования на новость о конфликте, так как старые алгоритмы могли пропускать некоторые события и редакторам приходилось публиковать информацию намного позже — вечером, после дополнительной проверки. Теперь появилась возможность масштабировать решение на большее количество источников информации — в планах постепенное увеличение источников с 800 до 8-10 тысяч.
Если вы знаете, как сделать что-то круто/правильно/красиво с помощью вашей экспертизы в некоторой области — свяжитесь с проектом через tg bot или почту. Уверен, что ребята будут рады всем здравым предложениям для решения различных технических вызовов: от улучшения бэкенда до дизайна сайта и приложений. Есть интересные задачи и для Data Science специалиста:
- Настроить автоматическое создание документов-отчетов по шаблону, подобно годовым отчетам за 2021 и 2022 год.
- Сделать более глубокий анализ данных из API и дополнить им раздел сайта со статистикой.
- Автоматизировать поиск подобных новостей о травмах/трагедиях на работе.
- Обучить (или применить существующую) NER модель для автоматического выделения профессий и других важных слов.
- Улучшить текущий классификатор с помощью увеличенного количества данных, быстрого трансформера, разнообразных текстовых аугментаций.
- Автоматизировать поиск и заполнение большинства полей из API, обрабатывая текст новости (сейчас все поля конфликта заполняются редактором): 'titleRu' — заголовок, 'conflictReasonId' — причина трудового конфликта, 'conflictResultId' — итог конфликта, 'industryId' — индустрия, 'companyName' — название предприятия и др.
- Настроить показ интерактивных дашбордов на сайте.
Вместо заключения
ЗабастКом передает пламенный привет всем единомышленникам и призывает других технических специалистов быть неравнодушными к проблемам людей. Людей, которые лечат, учат, строят, готовят, доставляют, водят, делают уборку и многое необходимое другое. Благодаря разделению труда и профессиям, создающим все блага для жизни, другие люди могут заниматься умственным трудом (программированием, наукой, искусством) и целенаправленно работать над улучшением жизни всех трудящихся масс.
Последнее время меня всё больше интересуют социально-экономические аспекты устройства общества. Возможно, поэтому тема поста оказалась на пересечении нескольких направлений. Во время работы с данными по этой теме увидел, как могут быть устроены отношения между рабочим коллективом и работодателем. Больнее всего видеть и чувствовать, какой несправедливости и издевательствам подвергают многих трудящихся эти "эффективные собственники". Несправедливость, в свою очередь, всегда вызывала, вызывает и будет вызывать наш коллективно-трудовой отпор. Еще вспоминается известная фраза: ничего личного, просто бизнес. Ее можно переформулировать, когда речь идет о праве Человека на достойный труд: это не бизнес, это личное.




