
История о трех бессонных ночах ресерча и преисполнении в познании
")
В этой статье я расскажу о том, как мы поучаствовали в хакатоне “Цифровой прорыв” в северо-западном федеральном округе, и познакомлю вас с концепцией Meta Learning, которая позволила нам построить достойный алгоритм и победить!
Содержание:
Описание кейса
Что такое Meta Learning?
Наше решение
Напоследок
Описание кейса
Мы выбрали кейс от Центрального Банка о прогнозировании макроэнономических показателей, соответственно, занимались предсказанием временных рядов.
Описание данных:
train часть представляля из себя 69 размеченных рядов ~ по 200 точек в каждом.
test часть состояла ~ из 4500 небольших файлов, в которых встречалось от 3-х до 6-ти рядов, для каждого из которых нужно было предсказывать индивидуальное количество точек вперед. Она была дана нам лишь на последние 3 часа хакатона, в течение которых мы активно занимались прогнозированием и записью полученных результатов.
Дополнительно train часть содержала лист со значениями по кварталам, соответсвенно, в некоторых из test-файлов нужно было предсказывать и квартальные значения.
Вопросы вызывали две вещи:
Скудное количество train данных
Неопределенность в фичах в test-датасетах
Поясняю второй пункт: если для train датасета мы знали, какие показатели нам даны (ВВП, уровень инфляции и т.д.), то в test части столбцы были зашифрованы. Мы, привыкшие решать более классические supervised задачи, были немного смущены этим фактом, но решение само нашло себя.
Что такое Meta Learning?
В ознакомительных англоязычных статьях чаще всего встречается неформальное определение по типу “learning to learn”.
Человеческому мозгу не нужны огромные массивы данных, чтобы быстро и качественно научиться решать незнакомую задачу задачу (например, определять ранее незнакомую породу собаки, встретив ее лишь несколько раз).
С этим можно поспорить — ведь у человека на развитие интеллекта была как минимум эволюция, но в дискуссию мы уходить не будем. Мы, очевидно, хотим идти в светлое будущее и развивать существующие алгоритмы, и было бы очень здорово научить модели адаптироваться под незнакомые задачи с помощью небольших датасетов.
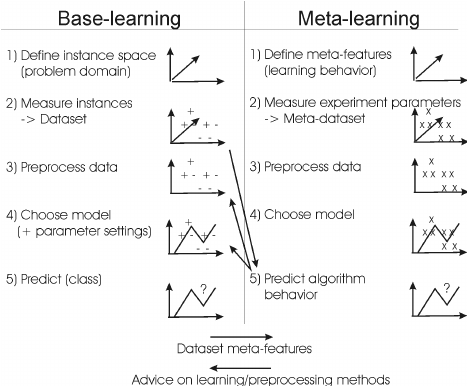
Как по мне, чем-то напоминает идею fine-tuning’а (transfer learning’а), но я бы отметил, что при таком подходе мы все же хотим обучить базовый алгоритм на огромных массивах данных и иметь представление о схожести задачи, на которую мы будем дообучаться, с задачей, которую мы уже имеем решать. Meta Learning не всегда требует этого от нас.
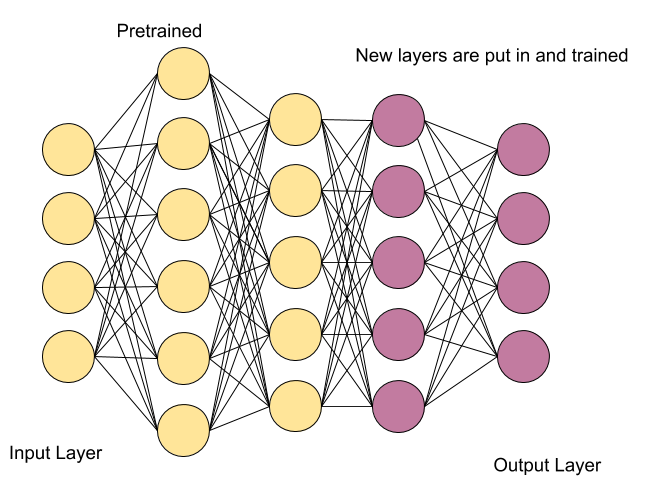
Если вы хотите больше проникнуться данной концепцией, то вот статьи, которые я могу порекомендовать:
A Gentle Introduction to Meta-Learning by Edward Ma
(https://pub.towardsai.net/a-gentle-introduction-to-meta-learning-8e36f3d93f61)
From zero to research — An introduction to Meta-learning by Thomas Wolf
(https://medium.com/huggingface/from-zero-to-research-an-introduction-to-meta-learning-8e16e677f78a)
Я же расскажу о том, что сделали конкретно мы.
Наше решение
Мы подумали, что круто было бы обучить не одну модель, пытающуюся предсказывать все ряды из test’а, а подбирать оптимальную модель для каждого нового ряда из test-выборки.
Звучит логично: рядов для предсказания уйма (более 20 тысяч), каждый имеет свою специфику, так что единственной модели вряд ли бы удалось хорошо обучиться на тех данных, что у нас имелись.
Но как понять, какой алгоритм использовать в каждом отдельном случае?
Мы и наше время не бесконечны, поэтому давайте выберем N моделей, которые могли бы подойти. Для этого мы (относительно) быстро прогнали кросс-валидацию для train’е и с помощью PyCaret (https://habr.com/ru/company/otus/blog/497770/) сравнили между собой более 60-ти алгоритмов и выбрали 6 (Prophet, ARIMA, SARIMA, Theta, Holt-Winters, STLF) наиболее успешных.
Теперь давайте посмотрим на ряды, которые мы имеем в train части, из каждого извлечем основные эконометрические фичи (количество точек, mean, std, энтропия, степень линейности, etc), прогоним на нем кросс-валидацией N моделей, которые мы хотим сравнивать и по заданной метрике посмотрим, какая из них лучше справилась с задачей!
Таким образом, мы получим meta train dataset, где будут уже не сами ряды, а их мета-признаки (порядка 40 штук); тип модели, проявившей себя лучшим образом; ее параметры и средняя метрика (R-Squared) после CV.
Затем мы введем в игру главную мета-модель, которая по полученным выше данным научиться решать классическую задачу классификации на N классов (в нашем случае каждый класс — определенная модель)

Как с этими знаниями делать предсказания?
Теперь все просто: получая новый ряд, мы извлекаем его мета-признаки, отдаем их мета-моделе, принимающей решение (a.k.a. Сахипзадовна Ильвира Набиуллина), какой алгоритм для предсказания мы будем использовать.
Валидируемся на известной части test-сета и настраиваем гипер-параметры и делаем долгожданное предсказание.
Было бы идеально расширить train set данными из интернета, но мы делали meta train dataset практически всю первую ночь. При его кратном увеличении мы бы получили его к закрытию хакатона).
Поэтому пришлось тюнить мета-модели аккуратнее. По дефолту Kats предлагает использовать RandomForestClassifier с 500 деревьями. Я лично отвечал за эту часть. На мой взгляд, на 69 сэмплах такой лес очень просто переобучится, поэтому я экспериментировал с моделями проще (RandomTreeClaffier, LogisticRegression, KNN, NaiveBayes).
Из полученных шагов мы написали pipeline, который и запустили в последние 3 часа.
В реализации описанных шагов, нам помогла чудесная open-source библиотека Kats, которая как раз и использует концепцую Meta Learning’а для предсказания временных рядов.
Ссылка на GiHub: (горячо рекомендую директорию tutorials) ****
https://github.com/facebookresearch/Kats

Напоследок
Как мне кажется, весь этот хакатон был про важность быть открытым новому. Изначально у нас были другие идеи, но лучше всего зашел подход, о котором мы даже не слышали до начала соревнования.
Мы были заряжены узнать и попробовать что-то принципиально новое лично для нас, и это стремление полностью оправдало себя. Будьте открытыми людям и идеям вокруг!
 с CRM Битрикс24")



