
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Все мы хотим быть в курсе происходящего поэтому часть своего времени тратим на чтение новостей, и сейчас все чаще новости приходят не из новостных сайтов или газет, а из каки-то телеграм-каналов. В итоге, через какое-то время, оказывается, что ты подписан на десяток(а может и на десятки каналов), которые постоянно что-то пишут – как следствие, тратится либо огромное количество времени на то, чтобы "что-то не пропустить". Но если посмотреть – большинство из них пишут примерно об одном, просто по-разному. Так и пришла идея научить ИИ отбирать новости, которые действительно являются главными. Конечно, есть разные ТОП-ы, вроде Яндекс.Новостей или что-то вроде итогов дня от какого-то уважаемого СМИ, но везде есть нюансики. В этой статье я постараюсь описать эти нюансики и что у нас получилось, а что нет.
Нюансики и источники
Вообще новости очень субъективная вещь, каждый сам выбирает источники – кому верить, а кому нет, именно поэтому очень часто получается достаточно однобокая картинка мира, если читать какое-то одно издание – там есть редакционная политика, которая чаще всего топит "за определенную повестку". Да, раньше был прекрасный проект Яндекс.Новости, который сейчас тоже превратился в инструмент, где транслируется определенный пул новостей – и это не проблема конкретного прокта, скорее это проблема того пула источников с которым они работают. Сразу забегая вперед – у нас была аналогичная проблема, когда мы отбирали источники себе.
Чтобы побороть эту пресловутую однобокость мы для себя поставили задачу следующим образом:
У нас в качестве источников будут новостные телеграмм-каналы, которые оперативно следят за происходящим
Мы постарались отобрать телеграмм каналы с разной повесткой, как раз для того, чтобы уйти от однобокого освещения каких-либо новостей(да-да, по большому счету это тоже можно назвать редакционной политикой на этапе отбора, но придумать более объективный способ у нас не получилось)
Все отобранные источники – равны, это значит, что канал с 100 тыс. подписчиками и канал с 10 тыс. подписчиками(но при этом уважаемого издания) – с точки зрения авторитетности равны. Ну не умеет какое-то гос. СМИ в СММ, ну не игнорировать же его сообщения
Таким образом у нас получилось собрать порядка 100 изданий, который мы "читаем" и пытаемся собрать актуальную новостную картину дня. При этом для начала мы прошлись по рейтингу медиалогии для того, чтобы отобрать топовые – таким образом у нас есть и, например, новости из телеграм-канала Известий, GQ, личного канала Ксении Собчак и т.д. Конечно мы посмотрели топовые каналы с огромным количеством подписчиков - типа канала Ивлеевой, но, если честно какой-то полезной информации мы там не нашли.
Собираем свой ТОП
Есть миллион разных вариантов, как можно собирать ТОП, особенно когда ты большой поисковик с кучей ресурсов, кучей перекрёстных данных, индексами цитирования, данными по просмотрам и т.д. Но у нас, очевидно всего этого нет и надо было как-то выкручиваться. В итоге пришлось придумать свою методику отбора сообщений из того, что есть. А было не много – просто текст, количество просмотров сейчас и потенциальное количество просмотров(из статистики по каналу в целом)... и вообщем-то все. И да, еще надо не ошибиться – то, что ты уже запостил "отпостить" нельзя(конечно технически можно, но тогда надо опять же садить человека, который будет следить и в общем-то теряется весь смысл). Короче, если ты выбрал какую-то новость и запостил помимо всего прочего надо следить за сюжетом и новые сообщения, которые добавляются в сюжет уже постить не надо, даже если очень хочется.
Таким образом перед собой мы поставили себе такую задачу чтобы обрабатывать весь этот поток данных:
У нас должна быть методика отбора новостей из разных каналов по принципу "похожести контекста", чтобы понимать – что разные источники пишут одну и туже новость
У нас должна быть возможность отбирать "сообщения", которые бы максимально коротко и емко описывали новость – т.е. чтобы в одном сообщении было как можно меньше "воды" и максимальное количество фактов
Новость должна быть "интересной" и эмоциональной – т.е. мы должны как-то определить, что аудитория интересуется этой темой сейчас
А с точки зрения того, что должна уметь наша нейрона, чтобы вот это все можно было делать без человеческого вмешательства:
определять похожесть текста(потом мы обошлись без нейронки)
понимать в каком тексте у нас больше всего фактов – тут мы решаем классическую NLP задачу по поиску NER тексте – чем больше этих самых сущностей, тем больше фактов
уметь как-то понимать "будет" ли эта новость интересна читателям или нет
Технически получилось достаточно простое решение – у нас есть всего 3 компонента, которые все эти сложные вещи автоматизируют: парсим источники, обрабатываем сообщения и добавляем метаданные по которым можно собирать и ранжировать(этим и занимается нейронка), обратная интеграция – постим в канал. Ну и все это упаковываем в оркестратор, чтобы у нас все интеграции обработки не отваливались, а если и отваливались - то данные не просаживались.
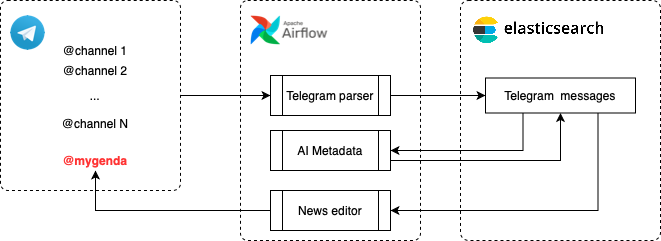
"Идеальная" нейросеть для NLP
Прочитав кучу статей про достижения трансформеров в решении задачи NLP, конечно же было решено сразу попробовать BERT, ведь с помощью одной обученной нейросети сразу решить все задачи. В интернете даже оказалось несколько обученных моделей на русском языке. Но не тут-то было. На самом деле мы попробовали несколько нейросетей и отказались от них по одной и тоже причине – нейросеть, которая отлично себя показывает в MVP не всегда лучший вариант для работы в продуктиве:
Какая бы идеально обученная или оттюненая ни была модель на момент запуска ее надо будет регулярно дообучать. Особенно это касается задач, связанных с NLP в тех ситуациях, когда у вас меняется язык – вводятся новые сущности, меняются интересы и т.п. Как вы понимаете - новости это то поле, где это все плывет очень быстро. И даже если вы нашли и обучили модель на датасете полугодовой давности, то совсем не факт, что у вас эта модель будет хорошо показывать результаты сейчас.
Тяжелые нейронные сети, вроде BERT достаточно ресурсоемкие – если нет проблем с ресурсами, конечно это все можно запросто отбалансировать и запускать в параллели, но зачем это делать, если можно ту же самую задачу почти с такими же результатами решить с меньшими затратами на ресурсы.
В итоге, наш MVP с BERT умер в первый же день, когда мы попробовали обрабатывать 20 каналов – обученная сеть искала криво(надо было тюнить), отдельный сервак, выделенный под работу BERT - отставал от новостей, т.е. количество сообщений приходивших для обработки росло быстрее, чем нейросеть могла их обрабатывать. Конечно можно было купить еще ресурсов, отбалансировать, но в этот момент мы поняли, что придется все начинать с нуля – искать другую нейросеть, собирать свои датасеты и обучать(ну или тюнить).
Что перебрали и не выбрали:
BERT – ресурсоемкая, медленная, сложно добавлять новые сущности NER в существующую модель, нужно достаточно большое количество ресурсов для обучения
Natasha – очень крутой проект, если вам надо решать задачи NLP для русского языка: быстрая, точная, простой API, но без возможности тюнить самостоятельно. Т.е. если вам хватает функциональности "из коробки" – отличное решение
Stanza – достаточно популярный пакет готовых инструментов для решения NLP задач, наличием готовых моделей, относительно быстрый и точный
Но в итоге мы становились на Spacy, который на наш взгляд дал все, что нужно было нам:
достаточную скорость
точность и гибкость обучения
решение сразу нескольких NLP задач, используя один пакет: NER, лематизацию, анализ тональности текста, анализ зависимостей
небольшое потребление ресурсов(по сравнению с той же BERT)
Большой минус - отсутствие готовой русскоязычной модели нужно качества, но в нашем случае такой модели не могло быть в принципе, поэтому решили собирать движок для выделения метаданных из текста с помощью Spacy.
Тут нужно сделать небольшую ремарку, в процессе написания статьи обнаружилось, что есть проект: Natasha-spacy, в котором ребята решили большинство граблей и этой моделью можно будет пользоваться в большинстве проектов, где не нужно регулярно обновлять модель. Но даже в этом случае, если бы была такая модель на момент решения задачи в рамках нашего проекта - пару недель, а то и больше, мы бы точно сэкономили.
Собираем датасет
Ни для кого не секрет, что если есть готовая модель и готовый датасет – то вопрос обучения, это вопрос времени и ресурсов. И если посмотреть на тот же самый английский язык – там все хорошо: есть куча готовых моделей на все случаи жизни. Нет модели – окей, есть датасет, дополняй его и обучай или тюнингуй модель для своей задачи. У нас же проблема усугублялась тем, что при решении задачи NER нам было недостаточно стандартных PER, LOC, ORG сущностей, нам важно было добавить еще выделение "денег" и "дат" в разных форматах и формах, т.к. это тоже касается важных фактах в новостях.
Датасеты на которых можно обучить основную часть языковой модели - словоформы, леммы, зависимости и т.п. Причем датасеты уже подготовлены к наиболее популярному формату CONLLU, именно этот формат чаще всего используется для базового обучения моделей на разных языках. Наиболее часто используемые датасеты:
GSD
SynTagRus
Taiga
В зависимости от решаемой задачи можно выбирать один из них или миксовать как-то. Но у всех у них есть одна проблема - они не содержат NER. Конечно можно посадить большое количество людей и разметить нужные вам тексты на нужные вам термины в этих текстах. Но, только если у вас есть ресурсы и время на разметку. У нас такой роскоши не было, и надо было как-то выкручиваться. Поэтому после недолгих поисков был найден еще один прекрасный проект – «Открытый корпус», который как раз и занимается тем, что собирает и выделяет набор сущностей в тексте. Да, конечно у проекта своя методология выделения сущностей(не совместимы с CONLLU), свои форматы выгружаемых текстов для которых пришлось писать свой парсер для приведения этого корпуса к формату CONLLU. Но, основной плюс этого всего был в том, что весь этот корпус собран вручную.
Но что касается сущностей для выявления "денег" и "дат" – у нас все равно не было данных. Но это оказалась простая задача, решаемая простыми regexp-ами, через которые мы прогнали уже собранный вручную текст и обогатили и этими сущностями.
Эмоциональная окраска
Что может быть проще, думали мы и к тому моменту нашли уже несколько датасетов в которых все тексты разделялись на "позитивный" и "негативный". Но когда мы открыли и посмотрели на эти датасеты - нас ждало очередное разочарование:
все они в большей степени подходили для оценки комментариев, например для оценки товара, сервиса или продукта
большая часть из них вызывала споры, т.к. посмотрев на репрезентативную выборку мы поняли, что понятие "позитивный" или "негативный" очень сильно разнится у разных людей, нам же нужна "среднестистическая оценка"
когда мы говорим про новости – зачастую очень сложно понять - а позитивная это новость или негативная, посмотрите, например, на актуальный ТОП сегодняшних новостей и ради интереса попробуйте отнести их к той или иной категории, а потом спросите хотя бы у 3-х друзей – как они их отнесут
Короче нас ждал очередной провал и мы уже хотели отказаться от этой фичи. Ну подумаешь, ну мы не будем понимать что за новость, интересная она или нет.
Отказываться было нельзя, поэтому решили собрать свой собственный датасет из "открытых данных". К открытым данным мы отнесли публичные старицы в Facebook(например themeduza, forbesrussia) новостных изданий и, внезапно, новости на государственном сайте ria.ru. И это стало нашим спасением – если внимательно посмотреть на любую публикацию - внизу есть важная и нужная нам информация о среднестатистической реакции читателей на эту новость. О чудо! У нас есть - заголовки, короткий текст и полный текст новости, а главное набор реакций большого количества разных людей, реагирующей на эту информацию. После небольшого усложнения нашей инфраструктуры и ~полутора месяцев скрупулёзного сбора данных у нас появился нужный нам датасет.

В итоге, наша модель с помощью собранного датасета должна была уметь не только определять "позитивная" или "негативная" эта новость, а понимать злит, радует, расстраивает, восхищает ли она людей, и вообще интересная она или нет.

Если посмотреть на среднее количество действий пользователей под каждым постом для каждой отдельно взятой страницы можно достаточно просто понять, какие новости вызывают максимальный интерес у пользователей – они чаще на них реагируют и с какими эмоциями. Именно такие темы новостей мы будем считать "наиболее интересными" на данный момент времени, и очевидно - эти интересы регулярно меняются.
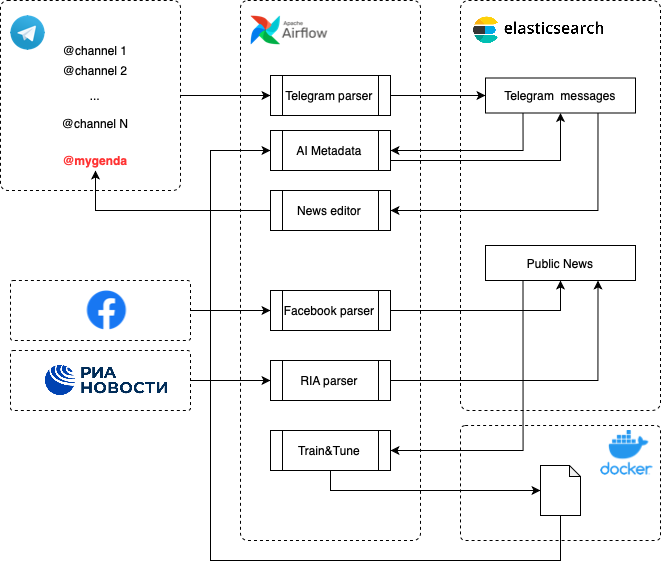
Перенос в продуктив
Тут наверное немного надо еще рассказать про инфраструктуру – собственно сколько ресурсов нужно для того, чтобы это все работало и не проседало при той нагрузке, которая у нас есть. А есть у нас есть примерно 4-5 тыс сообщений, которые надо распарсить, прогнать через нейронную сеть, которая должна обогатить каждое сообщение метаданными, а потом еще выбрать какое-то сообщение в качестве "главного".

И вся эта инфраструктура крутится на 4 GB RAM, 2 vCPUs со средней нагрузкой 8% на CPU, короче все очень экономичненько. Да, много сил и времени заняла тонкая настройка airflow, но это дало свои плоды(для понимания - airflow "из коробки" перманентно нагружал инстанс 16 GB RAM, 4 vCPUs в среднем на 32%). Очевидно, что использование более тяжелых моделей нейросетей требовало бы еще большего количество ресурсов. А в нашем случае, когда у нас сообщения анализируются порционно и все это происходит в рамках DAG-ов, которые каждый раз загружают и выгружают соответствующие модели – это бы порушило архитектуру в целом.

Наконец настал "день X", когда мы собрали и запустили все компоненты в продуктив. На тот момент у нас было:
Загруженная история из интересующих каналов за последние полгода(интеграционное решение построено таким образом, что при добавлении нового канала оно подгружает историю за последние полгода, можно и больше, но не интересно)
Обученная нейронная сеть, которая могла обогащать каждое из сообщений дополнительной информацией – выявлять NER для каждой записи, оценивать сообщения по уровню "интересности" и эмоциональному окрасу новости, выглядит это примерно так(абсолютно рандомный пример если что)
"source": {
"id": 1115468824,
"username": "lentadnya",
"title": "Лента дня",
"participants": 47148
},
"text": "«Россия, матушка, забери Донбасс домой»: Маргарита Симоньян попросила присоединить Донбасс к России. Тут лучше не пересказывать, просто послушайте",
"views": 405,
"link": "https://t.me/lentadnya/16263",
"interesting": 0.12,
"reaction": {
"enjoyment": 0.04400996118783951,
"sadness": 0.0019097710028290749,
"disgust": 0.8650462031364441,
"anger": 0.08112426102161407,
"fear": 0.00790974497795105
},
"entities": [
"Россия",
"Маргарита Симоньян",
"Донбасс",
"России"
],
"tags": [
"россия",
"маргарита симоньян",
"донбасс",
"россия"
]И после первого же прогона у нас получились достаточно спорные результаты, которые заставили еще немного усложнить архитектуру решения и немного перекроить нашу нейронку.
Проблема №1: Эмоциональная окраска и "интересность" хорошо аранжировалась только для сообщений, который были примерно в том же временном периоде, что и данные для обучения. Это как бы очевидно, но в действительности – уже через 3-4 недели, показатели начинают плыть. Т.е. с историей мы уже ничего не сделаем, т.к. у нас нет никакой выборки по истории на которой мы могли бы нормально обучить модель и прогнать историю, чтобы она была нормально отранжирована. Для новый данных – на регулярной основе мы продолжаем собирать данные из публичных источников и поддерживать актуальность модели.
Проблема №2: Актуальность NER – тут тоже происходит деградация модели. Конечно медленнее, чем для эмоций и интересов, но все равно точность просаживается. Пока эта проблема решается костылем. Костыль в нашем случае вылудит следующим образом - раз в неделю мы деваемы выборку по 100 рандомным сообщениям и вручную(да, к сожалению пока так) оцениваем на сколько точно происходит выявление NER и их лемматизация. Как только показатель падает меньше чем 85%. Происходит обучение модели на новых данных и снова контролируем этот показатель. Есть гипотеза обучить более тяжелую модель, например BERT в качестве "эталонной" и просто периодически сверяться на ней, но пока эта гипотеза только в проработке - если будет интересно, отдельно расскажем об этом как-нибудь.
Проблема №3: Дело в том, что в процессе анализа источников и выборки сообщения для формирования своего собственного рейтинга главных новостей, как я писал в начале, мы используем в том числе показатель, который показывает количество разных источников, которые написали сообщения в этом сюжете. Чтобы понять на сколько этот сюжет сейчас интересный. Ведь чем больше каналов пишут об этом - тем эта "новость" более важна и актуальная. Но мы столкнулись с тем, что в телеграмме есть "консорциумы", которые в определенный момент времени начинают форсить какое либо сообщение. Да, они не репостят одно и тоже сообщение(с этим было бы проще), но они в свойственной тому или иному каналу форсят одну и ту же мысль с указанием одинаковыми набором NER и эмоциональной окраской выводят "новость в топ". Не будем называть конкретные каналы, но в результате таких манипуляций внезапно мы сталкиваемся с картиной, которую мы видим, например в топе новостей у Яндекса. При этом "независимые" каналы, в случае какой-то важной новости реже "в унисон" – как следствие. Новости "сеток" прорываются и в наш топ. Да, можно выкинуть соответствующие "сетки" и оставить только один канал из группы, но это противоречит концепции нашей внутренней цензуры, так что пока думаем как решить эту проблему. Если есть предложения пишите в комментарии.
Ну и кто дочитал до этого момента, я надеюсь будет интересно а как же выглядит наш топ: https://t.me/mygenda.
Ну и как говорят модные блоггеры: подписывайтесь, делитесь комментариями и задайте вопросы. Надеюсь это было интересно.




