

Привет! На связи Евгений Бокарев и Надежда Грачёва, в этой статье мы расскажем про внедрение switchback A/B-тестов в логистике Delivery Club. Обсудим, как оценивать результат эксперимента, если эффективность доставки одного заказа влияет на другие. И на примере покажем, как мы снизили долю невыполненных заказов, с какими сложностями столкнулись и как их решали.
Сначала давайте познакомимся. Мы — часть команды логистики, которая отвечает за операционную эффективность: назначение курьеров, регулирование спроса и предложения, прогноз длительности различных участков пути и многое другое. В логистике, как и в других командах, для качественного принятия решений необходимы A/B-тесты. Но в нашем случае обычные A/B-тесты не подходят из-за «сетевых» эффектов, поэтому требуется другой подход к их проведению. Какой — опишем в статье.
Как проходит эксперимент с классическими тестами
В 9 из 10 статей про A/B-тесты обсуждается взаимодействие пользователей и веб-страниц. Это классический пример тестирования, когда сущностью для эксперимента является пользователь. Пользователей делят на несколько групп случайным образом, и обычно выделяют:
контрольную группу, которая будет использовать текущую функциональность;
тестовую группу, которой будет доступна обновленная версия интерфейса.
После накопления необходимого количества наблюдений мы оцениваем общее влияние тестируемого изменения на бизнес-метрики и измеряем статистическую значимость полученных различий между группами. Это важно, чтобы понимать, не был ли отмеченный при эксперименте эффект случайным.
Важно ещё раз подчеркнуть, что тестируемое изменение влияет только на тестовую группу и не влияет на контрольную, даже косвенно. Но так бывает не всегда…
Подводные камни: сетевой эффект
Один из наших примеров тестов, когда мы хотим влиять только на тестовую группу, но проявляется скрытый эффект и в контрольной группе — это тестирование алгоритмов назначения, распределяющих заказы по курьерам наиболее оптимальным образом. По сути, это набор приоритетов, которые учитываются при подборе курьера: расстояние до ресторана или клиента, возможность дать второй заказ, чтобы выполнить по пути, тип транспорта и многое другое. Выбор влияет на метрики заказа, например, на длительность и себестоимость доставки.
Предположим, мы хотим протестировать новый алгоритм назначения, в котором длительность доставки будет важнее себестоимости. Для начала определим, что будем делить на тестовую и контрольную группу, чтобы в тестовой действовал новый алгоритм, а в контрольной — старый. Причём делить на группы можно заказы, рестораны, курьеров или клиентов. Для примера рассмотрим деление на уровне заказов.
Допустим, заказ находится в тестовой группе, тогда для него будет применяться новый алгоритм назначения. Он будет охотнее выбирать автокурьеров: себестоимость доставки у них выше, зато доставляют быстрее. Казалось бы, мы влияем только на тестовую группу, а в контрольной всё осталось как раньше, но не всё так просто. Без эксперимента в распоряжении нынешней контрольной группы было бы больше автокурьеров, а теперь они чаще заняты выполнением заказов из тестовой группы — получается, и контрольную тоже косвенно задели. Такой A/B-тест не подходит. Ситуация, когда изменение в одной группе влияет на другие, называется сетевым эффектом.
Подобный эффект будет также возникать при проведении этого эксперимента на уровне ресторана, курьера или клиента. Необходимо создать условия, когда выделенная группа ресторанов, курьеров и клиентов будет изолирована, чтобы любые изменения в ней минимально влияли на соседнюю.
Тут возникает идея делить группы территориально, чтобы в пределах одной территории применялся только один алгоритм. Да, алгоритм из одной территории может дотянуться до курьеров из соседней, но такой эффект будет уже значительно меньше и им можно управлять, по особому деля города на кусочки — кластеры.
Switchback-тесты
В логистических Switchback-тестах можно выделить две ключевые особенности:
В тестовую или контрольную группу попадает не отдельный заказ или ресторан, а вся категория целиком — в данном случае по территориальному признаку.
Каждая категория попадает в тестовую или контрольную не навсегда, через фиксированное время происходит случайное перераспределение.
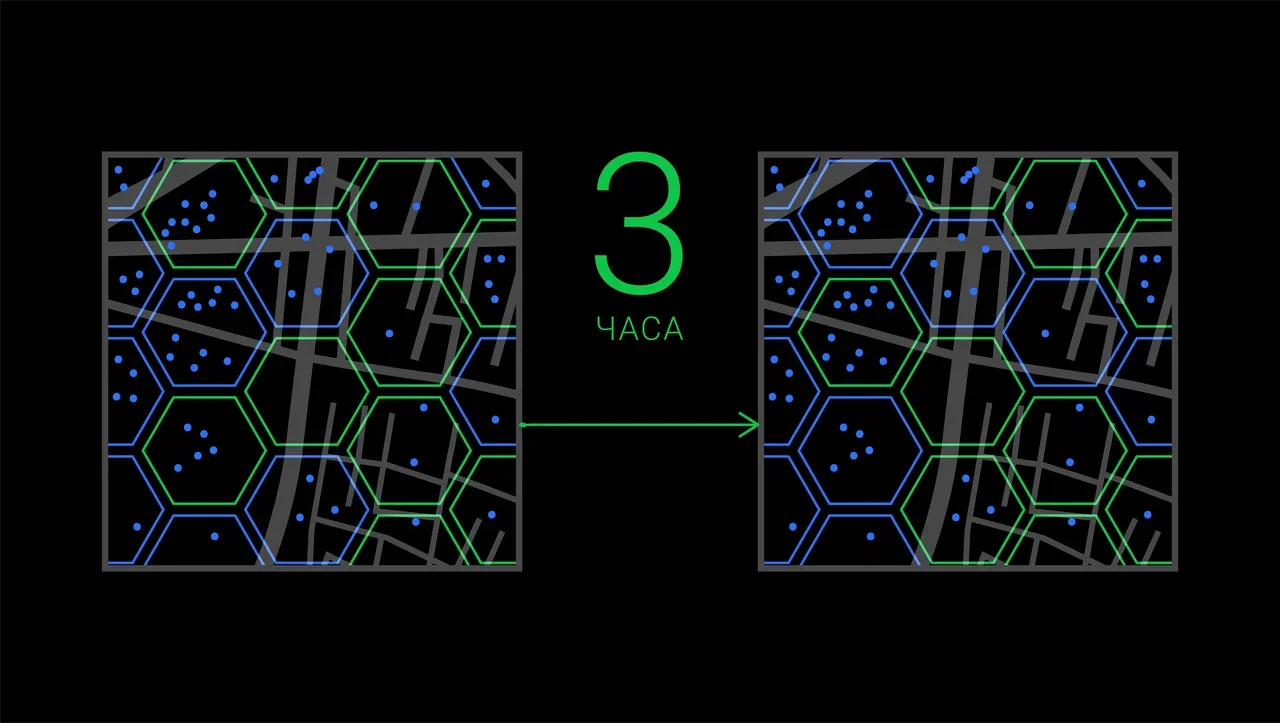
Первое необходимо для минимизации сетевых эффектов, но есть ещё несколько проблем:
Кластеры могут сильно отличаться друг от друга. Они находятся в разных городах, и в каждом городе есть центр и окраины, а также бывают погодные явления.
Кластеров достаточно мало, поэтому их отличие будет приводить к шуму в метриках. Чувствительность таких тестов будет достаточно низкой и длительность эксперимента не сильно её увеличит, потому что новых кластеров не появится.
Можно через фиксированный период времени перераспределять кластеры между тестируемыми группами случайным образом и наблюдать состояние кластера в течение этого периода. Так мы увеличим количество наблюдений и снизим дисперсию. Если в один из дней эксперимента лил дождь, то из-за переключения это отразится и на тестовой, и на контрольной группе.
Так как определение тестируемой группы является случайным, то наблюдения будут независимыми. Кластер может поменять группу, а может и не поменять. И каждая метрика будет рассчитываться как агрегированное значение для кластера-периода времени.
Внедрение
Мы определили несколько шагов, которые нужно проделать перед запуском первого switchback A/B-эксперимента в логистике:
Выбрать кластеры, чтобы сетевой эффект между ними отсутствовал или был минимальным.
Определить время переключения всех кластеров.
Провести A/A-тест, чтобы проверить корректность работы платформы с кластерами и определить чувствительность тестов.
Выбрать кластеры
Цель — сделать каждый кластер автономным, чтобы он был максимально независим от других. Для этого можно ввести несколько метрик. Например, долю заказов, когда ресторан, клиент и курьер при назначении находились в одном кластере, и варьируя границы каждого кластера на исторических данных максимизировать эту метрику или сделать её не меньше выбранного значения X. Таким образом получатся максимально самостоятельные кластеры, взаимодействие которых с соседями сведено к минимуму. Как правило, такое разделение будет определяться реками, крупными магистралями, лесополосами и так далее — они естественным образом делят города на фрагменты. Например, если курьер находится на другом берегу реки от ресторана, он с меньшей вероятностью будет выбран для заказа из него, потому что наверняка есть другой курьер, которому не нужно будет пересекать реку и который доставит быстрее. Но такое разделение возможно не во всех городах, в этом случае весь город будет находиться в одном кластере.

Определяем время переключения каждого кластера
Цель — увеличить чувствительность тестов. Здесь логика следующая:
Маленький временной интервал — много измерений и низкая дисперсия, но есть риск «памяти» кластера, и после переключения останется эффект от предыдущей механики.
Большой временной интервал — мало измерений и выше дисперсия, но риск «памяти» кластера меньше.
«А маленький временной интервал — это сколько?» — спросите вы. Зависит от вашей бизнес-системы и тестируемого алгоритма. Для начала можно опираться на среднюю длительность вашего целевого действия и взять окно в несколько раз больше.
Мы в Delivery Club пришли к тому, что у нас есть определённый набор интервалов переключения. При проектировании эксперимента мы просчитываем MDE для всех вариантов, затем выбираем интервал согласно результатам и требованиям самого алгоритма.
Также важную роль играют отложенные эффекты тестируемого изменения. Если эффект не только проявляется на одном заказе, но ещё и сохраняется долгое время, то период переключения switchback’а должен быть больше, иначе группы будут влиять друг на друга, не говоря уже о возможном появлении багов и неисправности сервисов. Например, когда у заказа половину длительности доставки действовала одна механика, а потом кластер переключил тестовую группу и включилась другая механика.
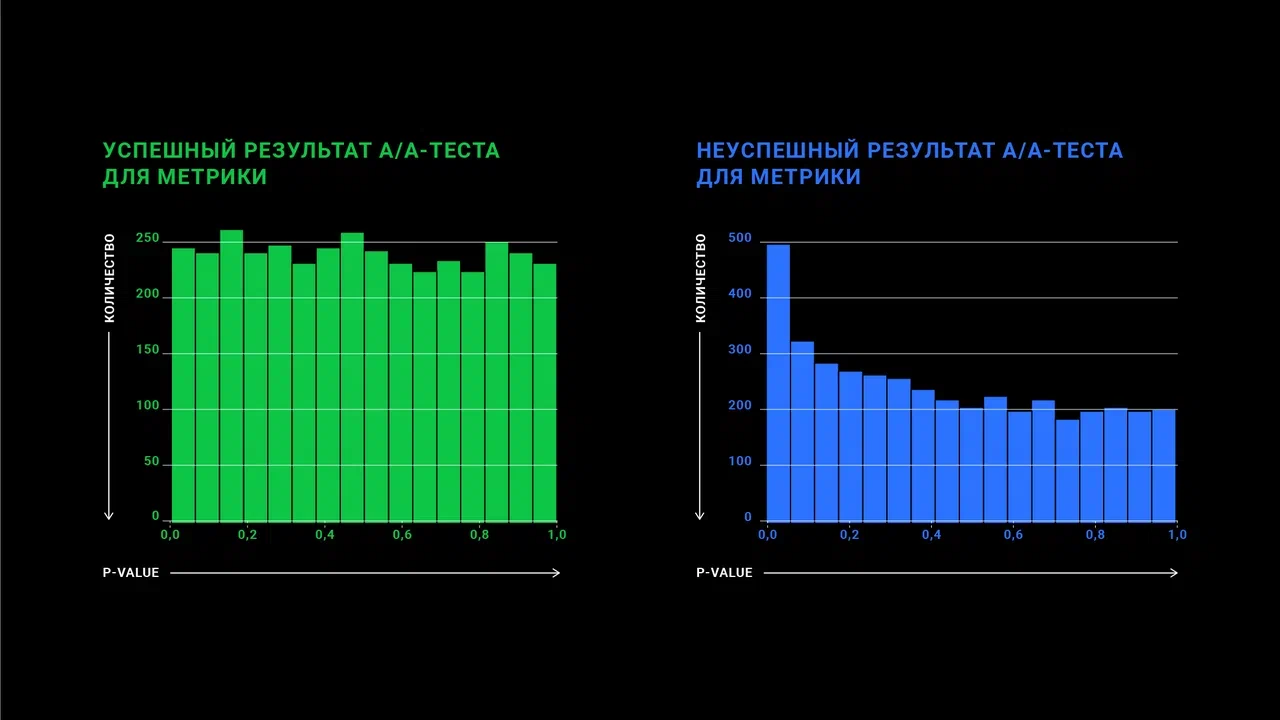
Проводим А/А-тест
При А/А-тесте делят сущности на группы, как и при A/B-тесте, но за одним исключением: между группами нет различий. Далее оценивают статистическую значимость различия между группами. Такое разделение с последующей оценкой статистической значимости проводят многократно. На выходе получаем распределение p-value. Можем оценить, как часто при отсутствии реальных различий критерий показал, что они существуют. Поскольку различий между группами нет, мы ожидаем, что распределение p-value будет равномерным, то есть нет каких-то отклонений в сторону конкретных диапазонов p-value.
Итоги внедрения
По мере запуска экспериментов мы столкнулись и с рядом других проблем:
Некоторые механики имеют положительный эффект в Москве, но не работают в регионах, или наоборот. Москва, Санкт-Петербург и регионы сильно отличаются друг от друга, например, плотностью заказов и курьеров. Если выборка для эксперимента будет содержать кластеры сразу из всех городов, то мы можем не увидеть изменений из-за противоположного эффекта в различных группах. Поэтому наиболее рискованные механики требуют трёх различных экспериментов.
Некоторые механики технически могут быть раскатаны только на весь город. Иногда город нельзя поделить на тестовую и контрольную группу, потому что новая функция продукта не может быть локализована до части города. В этом случае необходимо, чтобы весь город оказывался в тестовой или контрольной группе.
Сохранённые сетевые эффекты. Правильной отрисовки кластеров и подбора периода переключения недостаточно. Они позволяют минимизировать сетевые эффекты, но те всё равно могут возникать. Поэтому в реальных экспериментах для улучшения качества, можно:
вырезать подозрительные заказы, которые находятся на границе кластеров;
вырезать заказы на стыке переключения, так как если заказ попал в обе группы, то это тоже может приводить к неожиданным последствиям.
Что в итоге:
мы выбрали кластеры;
подобрали периоды переключения switchback’а;
определили три пространства для запуска экспериментов: Москва, Санкт-Петербург, регионы.
В каждом пространстве два типа кластеров: весь город и часть города. Если выбираем часть какого-нибудь города, то он уже не может быть использован в эксперименте по всему городу.
Далее рассмотрим пример применения switchback A/B-теста на практике.
Switchback-тест на примере fallback-механики
Мы в команде баланса спроса и предложения всегда ищем механики, которые помогут улучшить пользовательский опыт. На него сильно влияют заказы, которые были созданы пользователями, но по каким-либо причинам не были доставлены. Так как заказы могут быть отменены на разных этапах по множеству причин, решать эту проблему нужно разнонаправленно. Одним из подходов к сокращению доли отмен является механика fallback, которую мы недавно протестировали. Это дополнительная блокировка ресторанов, разработанная как запасная система на случай, если другие механики не справляются. Давайте на её примере разберём, как проходил switchback-тест.
Проблематика
Существуют алгоритмы автоматического назначения заказов, которые выбирают лучшего курьера для заказа. После назначения заказа курьеру у него есть несколько минут, чтобы его принять. Если за X минут заказ не может быть назначен автоматически, то есть курьера поблизости нет, или он есть, но заказы не принимает, то заказ падает в очередь на переназначение. Само по себе такое событие можно использовать как триггер, говорящий о плохой логистической ситуации в некоторой геозоне.
Гипотеза
Если вокруг ресторана нет курьеров, либо они не принимают заказы, то можно временно скрыть партнёра с платформы, так как заказы, попадающие в этот ресторан, сейчас доставить некому. Таким образом мы уменьшаем вероятность отмены заказа после его создания. Упрощённо гипотезу можно сформулировать так: скрытие вендора на платформе на A минут при попадании B заказов в очередь переназначения за прошедшие C минут сократит долю отменённых заказов на D %.

А зачем это тестировать?
А что если скрывая рестораны с платформы мы уменьшаем конверсию пользователей, так как они хотят заказывать именно в скрытых ресторанах? Или вовсе и не уменьшаем долю отменённых заказов? Иногда наши гипотезы кажутся абсолютно верными, но мы можем ошибаться. Численно подтвердить вклад новой механики в наши метрики — правильное решение.
Сущность
На какой сущности проводить эксперимент, чтобы убедиться, что гипотеза была верна? Давайте ещё раз посмотрим на проблему и наши действия по её решению.
До решения проблемы:
пользователь делает заказ в ресторане;
заказ не может быть автоматически назначен;
заказ некому доставить;
заказ отменяется;
другой пользователь делает заказ в этом ресторане;
заказ снова отменяется.
В результате внедрения новой механики:
пользователь делает заказ в ресторане;
заказ не может быть автоматически назначен;
скрываем ресторан на платформе;
следующий пользователь делает заказ в другом ресторане поблизости;
заказ назначается доступному курьеру;
это влияет на следующий по времени заказ в этой зоне;
так как свободный курьер был назначен на более ранний заказ, время доставки следующего заказа может увеличиться из-за ожидания свободного курьера.
Налицо сетевой эффект, и для его уменьшения мы используем switchback-тест.
Дизайн
Для запуска эксперимента нужно заранее его тщательно обдумать и подготовить проект: оформленный документ, содержащий гипотезу, цель эксперимента, выбор метрик для анализа и ожидаемое изменение, рассчитанные MDE для этих метрик и длительность эксперимента.
Метрики
Одна из ключевых метрик в операционной аналитике Delivery Club — это доля отменённых заказов, или Fail Rate (FR). Так как целью эксперимента является сокращение FR, то именно она будет приёмочной метрикой в этом тесте. По ней мы принимаем решение о раскатке. Помимо приёмочной мы всегда выбираем контрольные метрики. Они не являются целевыми, но лучше иметь больше информации для более полного понимания ситуации.
A/B-тест
Когда все необходимые шаги сделаны, можно запускать тест на A/B-платформе.
Анализ
После завершения теста важно корректно агрегировать собранные данные до уровня наблюдения, чтобы точно оценить статистическую значимость. Наблюдением в switchback-тестах называют измерение в пределах кластера-времени. Следующий шаг после агрегации — применение статистических методов для оценки значимости результатов. Подробно об этом можно прочитать тут.
Сложности
Switchback не только требует определённого подхода к проектированию и анализу, но также расчёта самих метрик, который не всегда так же прост, как в классических тестах.
При switchback-тесте один и тот же пользователь может находится сначала в контрольной группе, а через N минут — в тестовой. Это может сильно влиять на его поведение.
Более того, не всегда очевидно, к какой группе относится пользователь.
Для отнесения пользователя к тестовой или контрольной группе необходимо знать один из параметров:
координаты адреса пользователя;
координаты создания заказа;
координаты ресторанов, доступных пользователю в каталоге в текущий момент.
Разберём эти тонкости на примере конверсии — метрики, без которой не обходится ни одна статья про A/B-тесты.
Конверсия в классическом A/B-тесте
Как считается конверсия из захода в приложение в заказ? Классический метод расчёта предполагает бинарный исход: если пользователь зашёл в приложение и не сделал заказ, то конверсия равна 0, а если зашёл и сделал — 1. Все эти наблюдения рассматриваются в рамках одного дня. А как меняется расчёт для switchback-теста?
Конверсия в switchback тесте — время
Во-первых, важно определить интервал переключения switchback. Важно выбрать интервал, значительно превышающий время от захода в приложение до создания заказа. При таком временном окне в рамках одной сессии пользователь с большей вероятностью будет принадлежать только одной группе — тестовой или контрольной. Если выбрать интервал переключения в 24 часа, расчёт упростится до классического случая, но мы получим слишком мало измерений, а это отрицательно скажется на длительности теста. Дополнительно необходимо заранее определиться с количеством минут для вырезания на границах интервала переключения. Это следует сделать для исключения сценариев, когда на поведение пользователя повлияло нахождение в двух потенциально разных группах подряд: тестовой и контрольной.
Конверсия в switchback тесте — место
Во-вторых, важно уметь относить пользователя к контрольной или тестовой группе по местоположению. Это очень важно, потому что при клиентских тестах вы априори знаете, к какой группе принадлежит пользователь. Тут важно оценить доступные данные и формат их хранения. Пользовательские логи, как правило, — огромный источник информации, который нужно будет распарсить, выбрав необходимые события, а затем на каждое из них повесить флаг геозоны. Придётся исследовать, как часто ваши пользователи меняют зону между первым и вторым событием, чтобы оценить потенциальные искажения метрики. И снова исключить пользователей, но теперь уже тех, кто находится на границах геозон, чтобы уменьшить влияние соседних групп друг на друга.
Вознаграждение
Если вы определились с периодом переключения, размером геозоны для switchback, оценили и минимизировали влияние соседних групп друг на друга по местоположению и времени, то можно сформулировать окончательную методику расчёта конверсии в вашем switchback-эксперименте.
Результаты
Мы провели A/B-тест в Москве и регионах. Анализ показал, что мы статистически значимо сокращаем Fail Rate на 0,3% в Москве, в то время как статистически значимых различий в регионах не получили — следствие разной плотности магазинов. Это показывает важность проведения независимых тестов в регионах с разными бизнес-показателями, так как одна и та же механика не всегда и не везде работает одинаково, необходимо настраивать параметры. Конверсия пользователей не снизилась, и в этом важно было убедиться. Ура! Самое время заказать вкусную пиццу в Delivery Club, порадоваться и идти проектировать следующий эксперимент.
Планы
Мы провели много исследований для внедрения switchback-тестов и пытаемся развивать технологию дальше. Планируем внедрить слои — это возможность проводить больше тестов благодаря присутствию одной сущности в нескольких экспериментах единовременно. В то время как многие компании пользуются в клиентских A/B-тестах слоями, ими могут выступать различные страницы приложения, если доказано, что эксперимент на одной странице не влияет на эксперимент на другой. Switchback-подход со слоями вызывает гораздо больше вопросов о влиянии экспериментов друг на друга. Проводить тесты новых алгоритмов на слоях рискованно, это требует внимательной оценки эффектов.
Итоги
Путём проб и ошибок у нас получилось итерационно находить новые проблемы и пути их решения. В итоге switchback A/B-тесты позволили нам проводить эксперименты в логистике и принимать обоснованные решения.
Если ваш продукт находится в среде, где сложно отделить тестовую группу от контрольной, чтобы они не влияли друг на друга, попробуйте адаптировать изложенные идеи в своём продукте, например, делить пользователей на группы так, чтобы каждая группа практически гарантированно не контактировала с другой.
Спасибо за прочтение. Давайте обсудим статью в комментариях.


 Европе?» — легализуем гей-браки в Crusader Kings III с помощью Ghidra")
