
В преддверии старта нового потока по курсу «Разработчик Golang» подготовили перевод интересного материала.
Наш авторитетный DNS-сервер используют десятки тысяч веб-сайтов. Мы ежедневно отвечаем на миллионы запросов. В наши дни DNS-атаки становятся все более и более распространенными, DNS является важной частью нашей системы, и мы должны убедиться, что мы можем хорошо работать под высокой нагрузкой.
dnsflood — это небольшой инструмент, способный генерировать огромное количество udp запросов.
Мониторинг систем показал, что использование памяти нашим сервисом росло так быстро, что нам пришлось остановить его, иначе мы столкнулись бы с OOM ошибками. Это было похоже на проблему утечки памяти; существуют различные причины «похожих на» и «реальных» утечек памяти в go:
Этот пост содержит подробное объяснение различных случаев утечек.
Прежде чем делать какие-либо выводы, давайте сначала проведем профилирование.
Различные средства отладки можно включить с помощью переменной среды
Трассировка планировщика (scheduler trace) может предоставить информацию о поведении горутин во время выполнения. Чтобы включить трассировку планировщика, запустите программу с
runqueue — это длина глобальной очереди запускаемых горутин. Числа в скобках — это длина очереди процессов.
Идеальная ситуация — когда все процессы заняты выполнением горутин, и умеренная длина очереди выполнения равномерно распределена между всеми процессами:
Глядя на вывод schedtrace, мы можем видеть периоды времени, когда почти все процессы простаивают. Это означает, что мы не используем процессор на полную мощность.
Чтобы включить трассировку сборщика мусора (GC), запустите программу с переменной среды
Как мы здесь видим, объем используемой памяти увеличивается, также увеличивается и количество времени, необходимое gc для выполнения своей работы. Это означает, что мы потребляем больше памяти, чем он может обработать.
Больше о
Все, что нам нужно сделать для второго варианта, это импортировать пакет «net/http/pprof»:
затем добавить http-листнер:
У pprof есть несколько профилей по умолчанию:
Профилировщик процессора по умолчанию работает в течение 30 секунд (мы можем изменить это, задав параметр
Используйте
используйте
Команда
Большое количество времени, проводимого в функциях GC, таких как
Большое количество времени, затрачиваемое на механизмы синхронизации, такие как
Большое количество времени, затрачиваемое на
По умолчанию он показывает время жизни выделенной памяти. Мы можем увидеть количество выделенных объектов, используя
Обычно, если вы хотите уменьшить потребление памяти, вам нужно посмотреть на
Важно сначала определить тип узкого места (процессор, ввод/вывод, память), с которым мы имеем дело. Помимо профилировщиков, есть еще один вид инструментов.
Сгенерированный файл можно просмотреть с помощью инструмента трассировки:
Go tool trace — это веб-приложение, которое использует протокол Chrome DevTools и совместимо только с браузерами Chrome. Главная страница выглядит примерно так:
View trace (0s-409.575266ms)
View trace (411.075559ms-747.252311ms)
View trace (747.252311ms-1.234968945s)
View trace (1.234968945s-1.774245108s)
View trace (1.774245484s-2.111339514s)
View trace (2.111339514s-2.674030898s)
View trace (2.674031362s-3.044145798s)
View trace (3.044145798s-3.458795252s)
View trace (3.43953778s-4.075080634s)
View trace (4.075081098s-4.439271287s)
View trace (4.439271635s-4.814869651s)
View trace (4.814869651s-5.253597835s)
Goroutine analysis
Network blocking profile ()
Synchronization blocking profile ()
Syscall blocking profile ()
Scheduler latency profile ()
User-defined tasks
User-defined regions
Minimum mutator utilization
Трассировка разделяет время трассировки, чтобы ваш браузер мог справиться с этим
Здесь огромное множество данных, что делает их практически нечитаемыми, если мы не знаем что ищем. Давайте пока оставим это.
Следующая ссылка на главной странице — «goroutine analysis», который показывает различные виды работающих горутин в программе в течение периода трассировки:
Нажмите на первый элемент с N = 441703, вот что мы получим:
анализ горутин
Это очень интересно. Большинство операций практически не тратят времени на выполнение, а большую часть времени проводят в блоке Sync. Давайте подробнее рассмотрим одну из них:
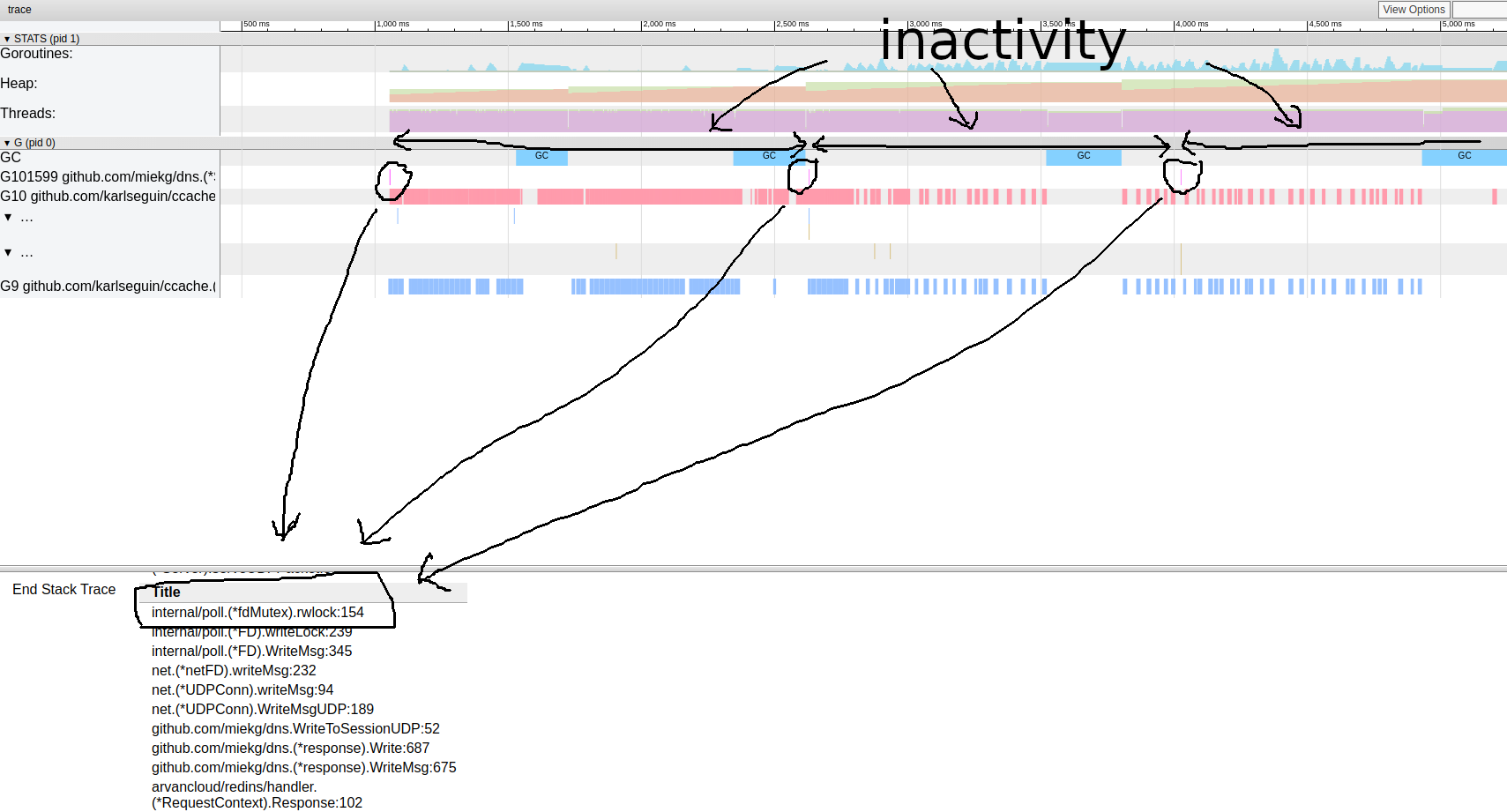
схема трассировки горутин
Похоже, наша программа почти всегда неактивна. Отсюда мы можем перейти непосредственно к инструменту блокировки; профилирование блокировки по умолчанию отключено, нам нужно сначала включить его в нашем коде:
Теперь мы можем получить выборку блокировок:
Здесь у нас есть две разные блокировки (poll.fdMutex и sync.Mutex), отвечающие почти за 100% блокировок. Это подтверждает наше предположение о конфликте блокировок, теперь нам нужно только найти, где это происходит:
Эта команда создает векторный граф всех узлов, учитывающих конфликты, с упором на функции блокировки:
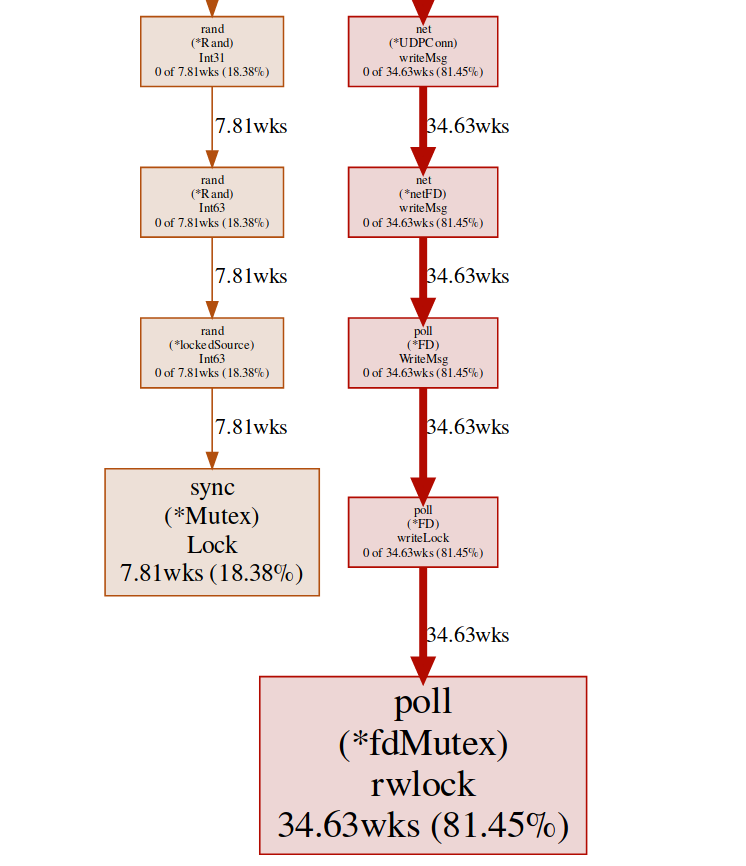
svg-график эндпонта блокировки
мы можем получить тот же результат из эндпоинта горутины:
и затем:
почти все наши программы находятся в runtime.gopark, это планировщик go, усыпляющий горутины; очень распространенная причина этого — конфликт блокировок
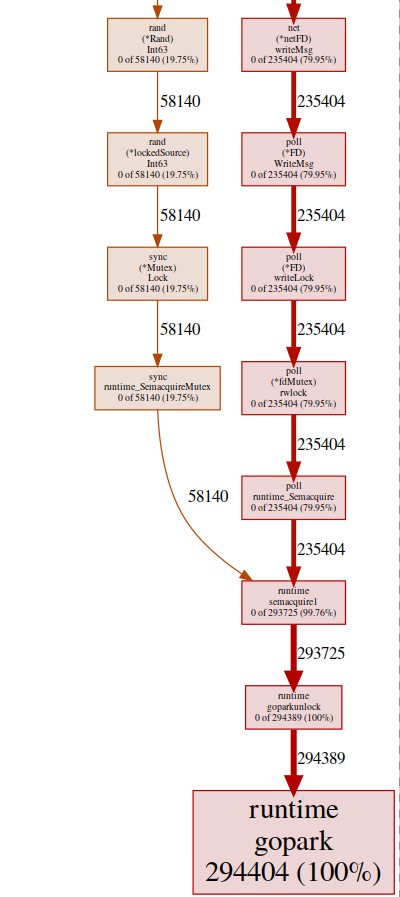
svg-график конечной точки горутин
Здесь мы видим два источника конфликтов:
Похоже, что все ответы заканчиваются записью на один и тот же FD (отсюда и блокировка), это имеет смысл, поскольку все они имеют один и тот же адрес источника.
Мы провели небольшой эксперимент с различными решениями, и в конце решили использовать несколько листнеров для балансировки нагрузки. Таким образом, мы позволяем ОС балансировать входящие запросы между различными соединениями и уменьшать конфликты.
Похоже, что в обычных math/rand функциях есть блокировка (подробнее об этом здесь). Это можно легко исправить с помощью
Это немного лучше, но создавать новый источник каждый раз дорого. Можно ли сделать еще лучше? В нашем случае нам действительно не нужно случайное число. Нам просто нужно равномерное распределение для балансировки нагрузки, и получается, что
Теперь, когда мы устранили все лишние блокировки, давайте посмотрим на результаты:
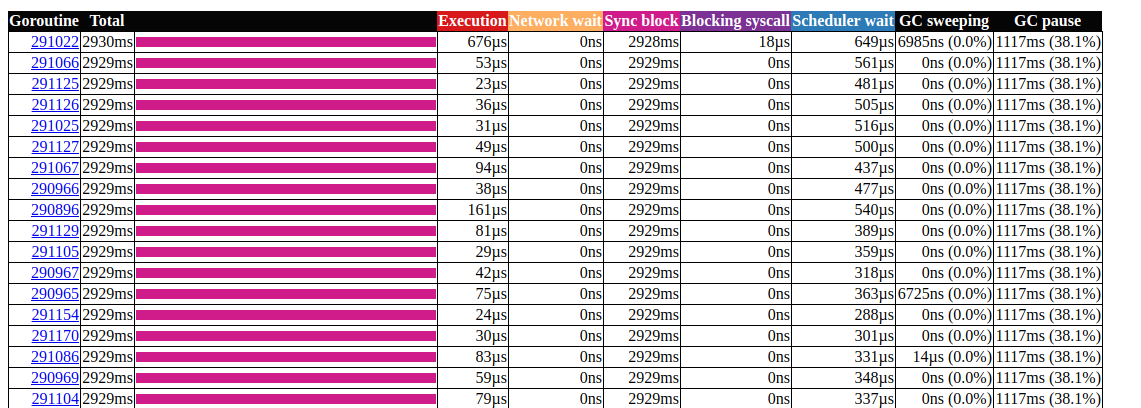
анализ горутин
Выглядит лучше, но все же большая часть времени уходит на блокировку синхронизации. Давайте посмотрим на профиль блокировки синхронизации с главной страницы пользовательского интерфейса трассировки:
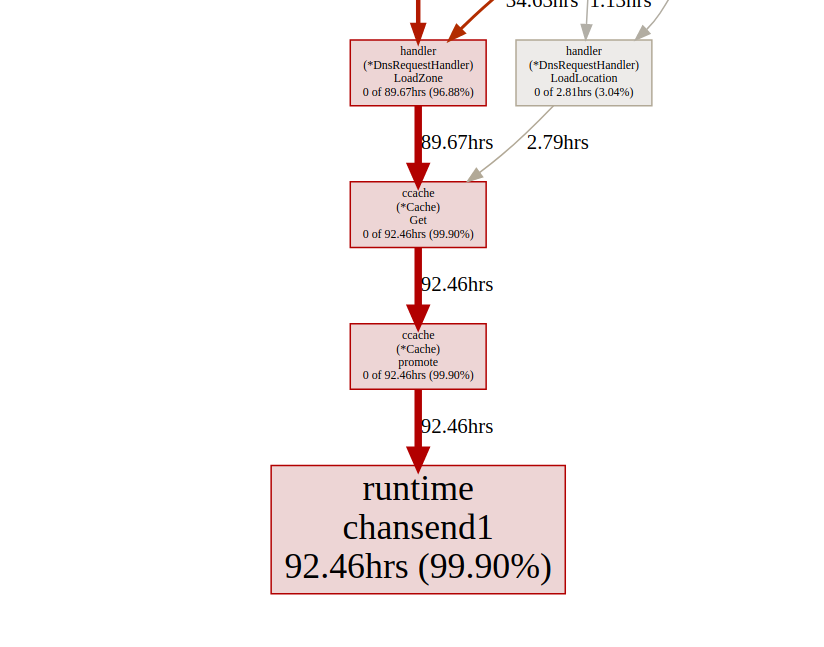
график времени блокировки синхронизации
Давайте взглянем на функцию повышения
Все вызовы
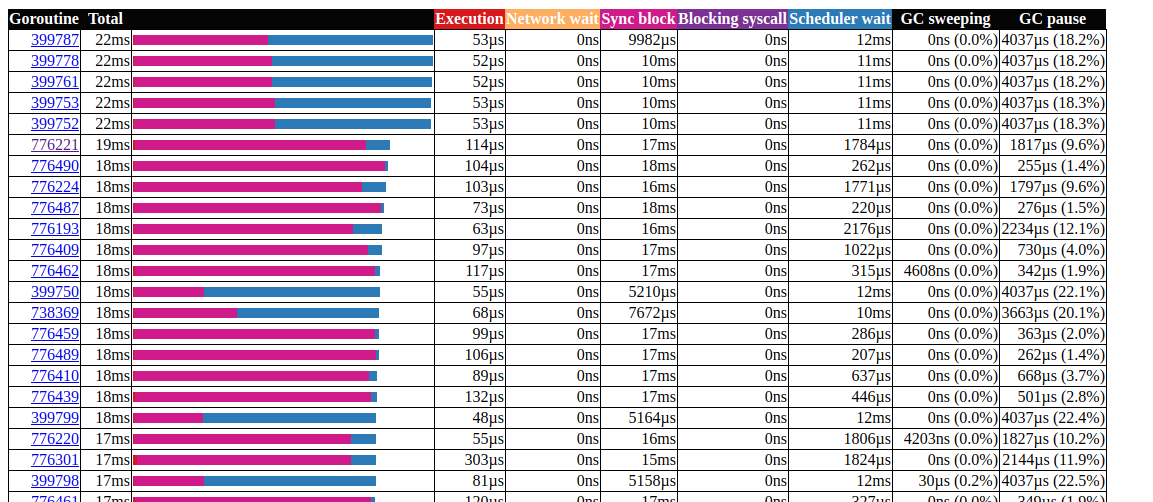
анализ горутин
Отлично!
Нам удалось сократить максимальное время выполнения горутины с 5000 мс до 22 мс. Тем не менее, большая часть времени выполнения делится между «блокировкой синхронизации» и «ожиданием планировщика». Давайте посмотрим, сможем ли мы что-нибудь с этим сделать:
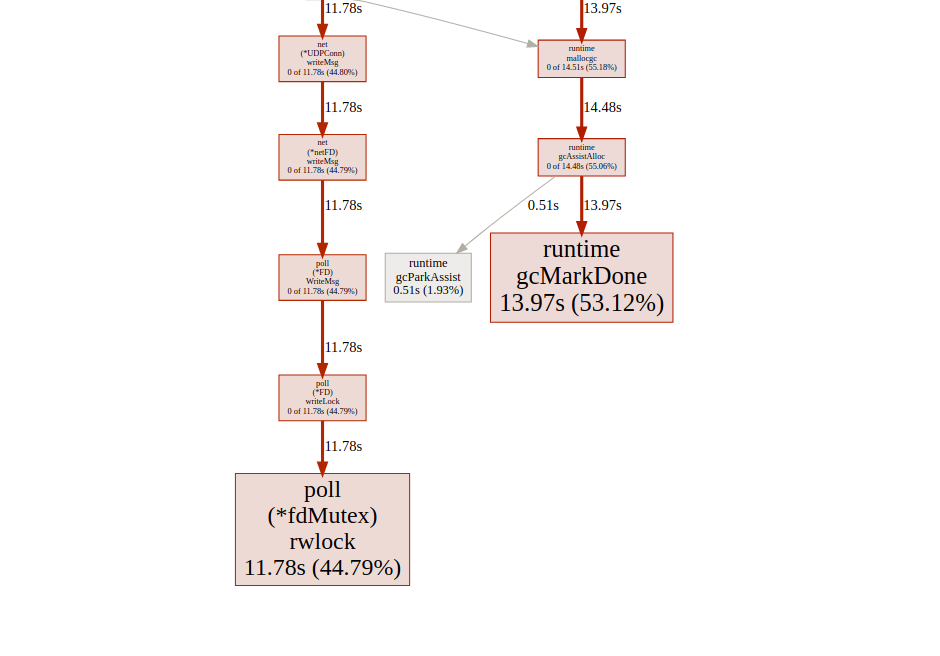
график времени блокировки синхронизации
Мы мало что можем сделать с
На этом этапе может быть полезно посмотреть, как работает сборка мусора; Go использует mark-and-sweep сборщик. Он отслеживает все, что выделено, и как только он достигает в два раза большего (или любого другого значения, на которое установлено GOGC) размера от предыдущего размера, запускается очистка GC. Оценка происходит в три этапа:
Фазы «Остановить мир» (Stop The World, STW) останавливают весь процесс, хотя они, как правило, очень короткие, сплошные циклы могут увеличить продолжительность. Это потому, что в настоящее время (go v1.13) горутины являются вытесняемыми только в точках вызова функции, поэтому для сплошного цикла возможно произвольно большое время паузы, поскольку GC ожидает остановки всех горутин.
Во время маркировки gc использует около 25%
Следует отметить две вещи:
Для получения дополнительной информации о модели памяти Go и архитектуры GC смотрите эту презентацию.
для оптимизации выделения памяти мы используем набор инструментов go:
Давайте начнем с профилировщика процессора:
Нас особенно интересуют функции, связанные с
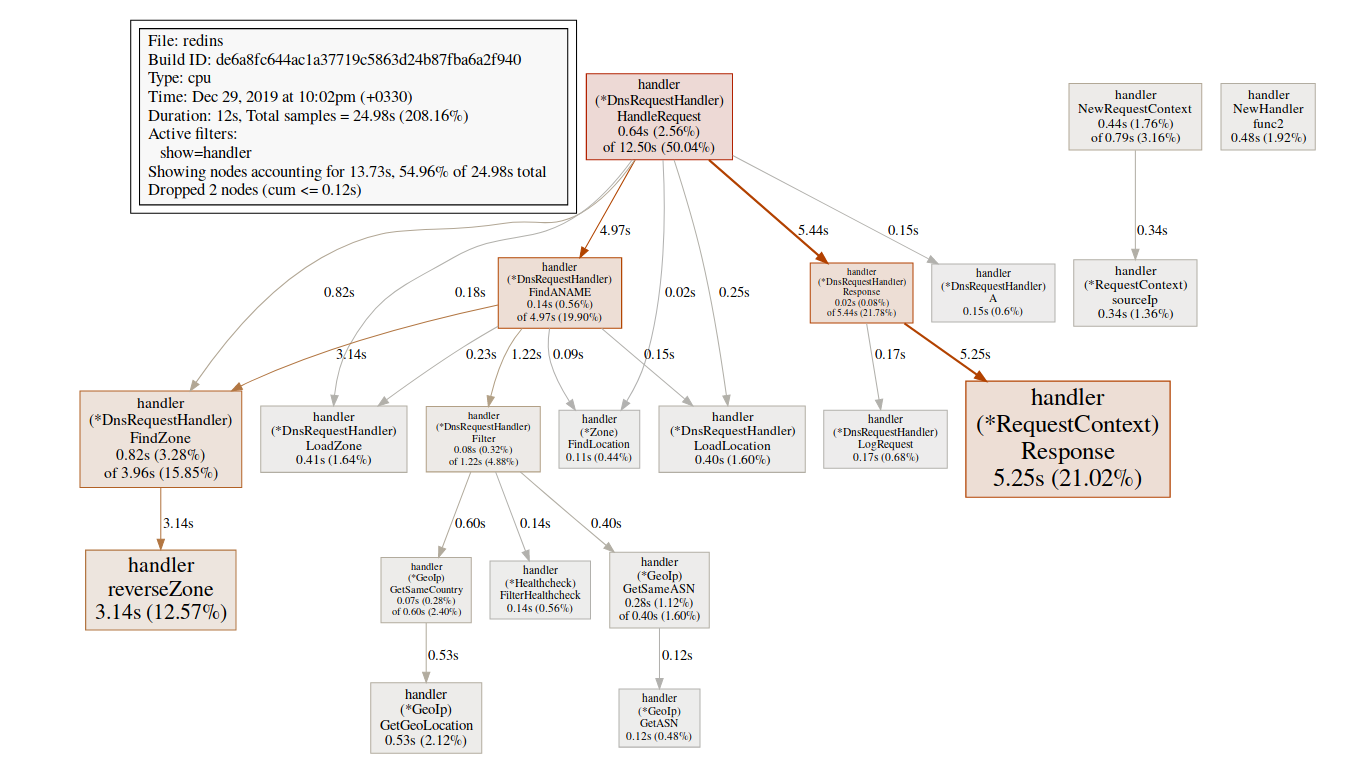
Мы можем отслеживать распределение, используя конечную точку
С этого момента мы можем использовать list для каждой функции и посмотреть, сможем ли мы уменьшить выделение памяти. Давайте проверим:
printf-подобные функции
Строка 41 особенно интересна, даже когда отладка отключена, там все еще выделяется память, мы можем использовать escape-анализ, чтобы исследовать ее подробнее.
Инструмент Escape-анализа Go на самом деле флаг компилятора
Вы можете добавить другой -m для получения дополнительной информации
для более удобного интерфейса используйте view-annotated-file.
Здесь все параметры
Все параметры
Для получения дополнительной информации об escape- анализе см. «allocation eficiency in golang».
Работа со строками
Поскольку строка в Go является неизменяемой, создание временной строки вызывает выделение памяти. Начиная с Go 1.10, можно использовать
Поскольку нас не волнует значение перевернутой строки, мы можем устранить
Прочитать подробнее о работе со строками можно здесь.
Мы используем функции maxmiddb для получения данных геолокации. Эти функции принимают
мы можем использовать
Больше о sync.Pool здесь.
Есть много других возможных оптимизаций, но на данный момент, кажется, мы уже сделали достаточно. Для получения дополнительной информации о методах оптимизации памяти, можете прочитать Allocation efficiency in high-performance Go services.
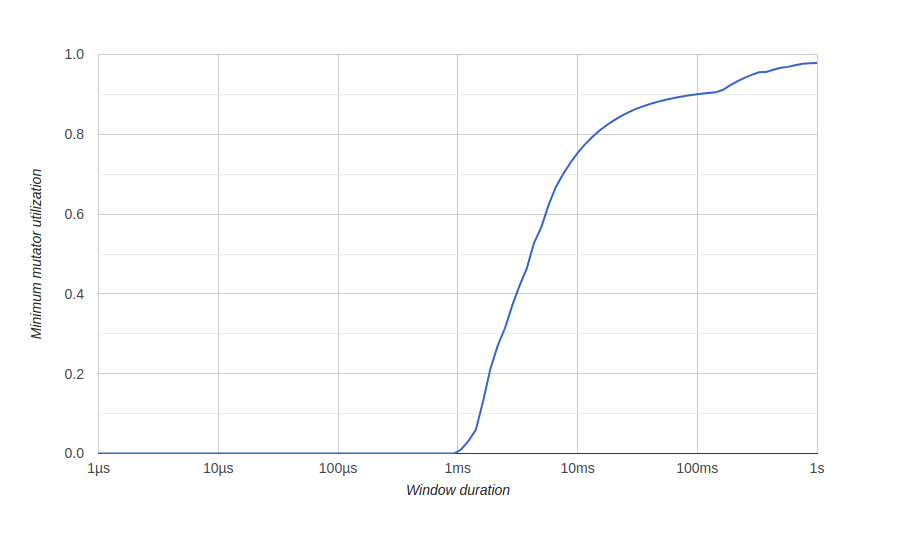
Чтобы визуализировать результаты оптимизации памяти, мы используем диаграмму в
До оптимизации:

Здесь у нас есть окно около 500 миллисекунд без эффективного использования (gc потребляет все ресурсы), и мы никогда не получим 80% эффективного использования в долгосрочной перспективе. Мы хотим, чтобы окно нулевого эффективного использования было как можно меньше, и максимально быстро достигать 100% использования, как-то так:
после оптимизации:
С помощью инструментов go нам удалось оптимизировать наш сервис для обработки большого количества запросов и лучшего использования системных ресурсов.
Вы можете посмотреть наш исходный код на GitHub. Вот неоптимизированная версия и вот оптимизированная.
На этом все. До встречи на курсе!
Наш авторитетный DNS-сервер используют десятки тысяч веб-сайтов. Мы ежедневно отвечаем на миллионы запросов. В наши дни DNS-атаки становятся все более и более распространенными, DNS является важной частью нашей системы, и мы должны убедиться, что мы можем хорошо работать под высокой нагрузкой.
dnsflood — это небольшой инструмент, способный генерировать огромное количество udp запросов.
# timeout 20s ./dnsflood example.com 127.0.0.1 -p 2053Мониторинг систем показал, что использование памяти нашим сервисом росло так быстро, что нам пришлось остановить его, иначе мы столкнулись бы с OOM ошибками. Это было похоже на проблему утечки памяти; существуют различные причины «похожих на» и «реальных» утечек памяти в go:
- висящие горутины
- неправильное использование defer и finalizer
- подстроки и подсрезы
- глобальные переменные
Этот пост содержит подробное объяснение различных случаев утечек.
Прежде чем делать какие-либо выводы, давайте сначала проведем профилирование.
GODEBUG
Различные средства отладки можно включить с помощью переменной среды
GODEBUG, передав список разделенных запятыми пар name=value.Трассировка планировщика
Трассировка планировщика (scheduler trace) может предоставить информацию о поведении горутин во время выполнения. Чтобы включить трассировку планировщика, запустите программу с
GODEBUG=schedtrace=100, значение определяет период вывода в мс.$ GODEBUG=schedtrace=100 ./redins -c config.json
SCHED 2952ms: ... runqueue=3 [26 11 7 18 13 30 6 3 24 25 11 0]
SCHED 3053ms: ... runqueue=3 [0 0 0 0 0 0 0 0 4 0 21 0]
SCHED 3154ms: ... runqueue=0 [0 6 2 4 0 30 0 5 0 11 2 5]
SCHED 3255ms: ... runqueue=1 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3355ms: ... runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3456ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3557ms: ... runqueue=0 [13 0 3 0 3 33 2 0 10 8 10 14]
SCHED 3657ms: ...runqueue=3 [14 1 0 5 19 54 9 1 0 1 29 0]
SCHED 3758ms: ... runqueue=0 [67 1 5 0 0 1 0 0 87 4 0 0]
SCHED 3859ms: ... runqueue=6 [0 0 3 6 0 0 0 0 3 2 2 19]
SCHED 3960ms: ... runqueue=0 [0 0 1 0 1 0 0 1 0 1 0 0]
SCHED 4060ms: ... runqueue=5 [4 0 5 0 1 0 0 0 0 0 0 0]
SCHED 4161ms: ... runqueue=0 [0 0 0 0 0 0 0 1 0 0 0 0]
SCHED 4262ms: ... runqueue=4 [0 128 21 172 1 19 8 2 43 5 139 37]
SCHED 4362ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 4463ms: ... runqueue=6 [0 28 23 39 4 11 4 11 25 0 25 0]
SCHED 4564ms: ... runqueue=354 [51 45 33 32 15 20 8 7 5 42 6 0]runqueue — это длина глобальной очереди запускаемых горутин. Числа в скобках — это длина очереди процессов.
Идеальная ситуация — когда все процессы заняты выполнением горутин, и умеренная длина очереди выполнения равномерно распределена между всеми процессами:
SCHED 2449ms: gomaxprocs=12 idleprocs=0 threads=40 spinningthreads=1 idlethreads=1 runqueue=20 [20 20 20 20 20 20 20 20 20 20 20]Глядя на вывод schedtrace, мы можем видеть периоды времени, когда почти все процессы простаивают. Это означает, что мы не используем процессор на полную мощность.
Трассировка сборщика мусора
Чтобы включить трассировку сборщика мусора (GC), запустите программу с переменной среды
GODEBUG=gctrace=1:GODEBUG=gctrace=1 ./redins -c config1.json
.
.
.
gc 30 @3.727s 1%: 0.066+21+0.093 ms clock, 0.79+128/59/0+1.1 ms cpu, 67->71->45 MB, 76 MB goal, 12 P
gc 31 @3.784s 2%: 0.030+27+0.053 ms clock, 0.36+177/81/7.8+0.63 ms cpu, 79->84->55 MB, 90 MB goal, 12 P
gc 32 @3.858s 3%: 0.026+34+0.024 ms clock, 0.32+234/104/0+0.29 ms cpu, 96->100->65 MB, 110 MB goal, 12 P
gc 33 @3.954s 3%: 0.026+44+0.13 ms clock, 0.32+191/131/57+1.6 ms cpu, 117->123->79 MB, 131 MB goal, 12 P
gc 34 @4.077s 4%: 0.010+53+0.024 ms clock, 0.12+241/159/69+0.29 ms cpu, 142->147->91 MB, 158 MB goal, 12 P
gc 35 @4.228s 5%: 0.017+61+0.12 ms clock, 0.20+296/179/94+1.5 ms cpu, 166->174->105 MB, 182 MB goal, 12 P
gc 36 @4.391s 6%: 0.017+73+0.086 ms clock, 0.21+492/216/4.0+1.0 ms cpu, 191->198->122 MB, 210 MB goal, 12 P
gc 37 @4.590s 7%: 0.049+85+0.095 ms clock, 0.59+618/253/0+1.1 ms cpu, 222->230->140 MB, 244 MB goal, 12 P
.
.
.Как мы здесь видим, объем используемой памяти увеличивается, также увеличивается и количество времени, необходимое gc для выполнения своей работы. Это означает, что мы потребляем больше памяти, чем он может обработать.
Больше о
GODEBUG и некоторых других переменных среды golang можно узнать здесь.Включение профилировщика
go tool pprof — инструмент для анализа и профилирования данных. Есть два способа настроить pprof: либо напрямую вызывать функции runtime/pprof в вашем коде, например pprof.StartCPUProfile(), либо установить net/http/pprof http-листнер и получать оттуда данные, что мы и сделали. У pprof очень маленькое ресурсопотребление, поэтому его можно безопасно использовать в разработке, но эндпоинт профиля не должен быть публично доступен, поскольку могут быть раскрыты конфиденциальные данные.Все, что нам нужно сделать для второго варианта, это импортировать пакет «net/http/pprof»:
import (
_ "net/http/pprof"
)затем добавить http-листнер:
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()У pprof есть несколько профилей по умолчанию:
- allocs: выборка всех прошлых распределений памяти
- block: трассировка стека, которая привела к блокировке примитивов синхронизации
- goroutine: трассировка стека всех текущих горутин
- heap: выборка выделений памяти живых объектов.
- mutex: трассировка стека держателей конфликтующих мьютексов
- profile: профиль процессора.
- threadcreate: трассировка стека, которая привела к созданию новых потоков в ОС
- trace: трассировка выполнения текущей программы.
Примечание: эндпоинт трассировки, в отличие от всех других эндпоинтов, является профилем трассировки, а не pprof, вы можете просмотреть его, используя go tool trace вместо go tool pprof.Теперь, когда все подготовлено, мы можем посмотреть на доступные инструменты.Профилировщик процессора
$ go tool pprof http://localhost:6060/debug/pprof/profile?seconds=10Профилировщик процессора по умолчанию работает в течение 30 секунд (мы можем изменить это, задав параметр
seconds) и собирает выборки каждые 100 миллисекунд, после чего он переходит в интерактивный режим. Наиболее распространенными из доступных команд являются top, list, web.Используйте
top n для просмотра самых горячих записей в текстовом формате, также есть две опции для сортировки вывода, -cum для кумулятивного порядка и -flat.(pprof) top 10 -cum
Showing nodes accounting for 1.50s, 6.19% of 24.23s total
Dropped 347 nodes (cum <= 0.12s)
Showing top 10 nodes out of 186
flat flat% sum% cum cum%
0.03s 0.12% 0.12% 16.7s 69.13% (*Server).serveUDPPacket
0.05s 0.21% 0.33% 15.6s 64.51% (*Server).serveDNS
0 0% 0.33% 14.3s 59.10% (*ServeMux).ServeDNS
0 0% 0.33% 14.2s 58.73% HandlerFunc.ServeDNS
0.01s 0.04% 0.37% 14.2s 58.73% main.handleRequest
0.07s 0.29% 0.66% 13.5s 56.00% (*DnsRequestHandler).HandleRequest
0.99s 4.09% 4.75% 7.56s 31.20% runtime.gentraceback
0.02s 0.08% 4.83% 7.02s 28.97% runtime.systemstack
0.31s 1.28% 6.11% 6.62s 27.32% runtime.mallocgc
0.02s 0.08% 6.19% 6.35s 26.21% (*DnsRequestHandler).FindANAME
(pprof)используйте
list, чтобы исследовать функцию.(pprof) list handleRequest
Total: 24.23s
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
10ms 14.23s (flat, cum) 58.73% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
10ms 610ms 40: context := handler.NewRequestContext(w, r)
. 50ms 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 13.57s 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
(pprof)
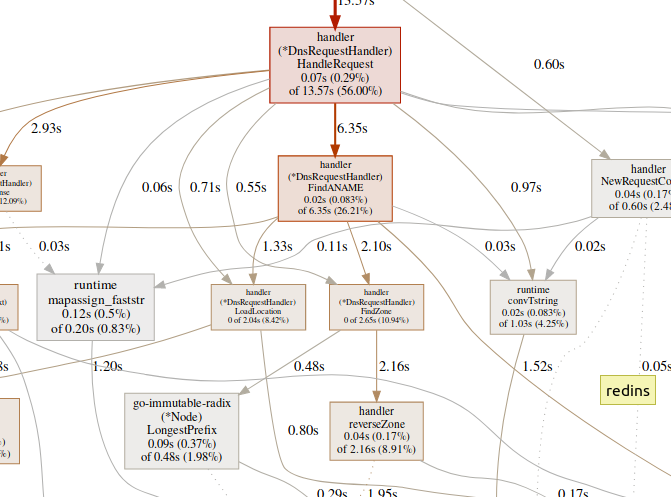
Команда
web генерирует SVG-график критических участков и открывает его в браузере.(pprof)web handleRequesБольшое количество времени, проводимого в функциях GC, таких как
runtime.mallocgc, часто приводит к значительному выделению памяти, что может добавить нагрузки на сборщик мусора и увеличить задержку.Большое количество времени, затрачиваемое на механизмы синхронизации, такие как
runtime.chansend или runtime.lock, может быть признаком конфликта.Большое количество времени, затрачиваемое на
syscall.Read/Write означает чрезмерное использование операций ввода-вывода.Профилировщик памяти
$ go tool pprof http://localhost:6060/debug/pprof/allocsПо умолчанию он показывает время жизни выделенной памяти. Мы можем увидеть количество выделенных объектов, используя
-alloc_objects, другие полезные опции: -iuse_objects и -inuse_space для проверки живой памяти.Обычно, если вы хотите уменьшить потребление памяти, вам нужно посмотреть на
-inuse_space, но если вы хотите уменьшить задержку, посмотрите на -alloc_objects после достаточного времени выполнения/загрузки.Выявление узкого места
Важно сначала определить тип узкого места (процессор, ввод/вывод, память), с которым мы имеем дело. Помимо профилировщиков, есть еще один вид инструментов.
go tool trace может показать, что горутины делают в деталях. Чтобы собрать пример трассировки, нам нужно отправить http запрос на эндпоинт трассировки:$ curl http://localhost:6060/debug/pprof/trace?seconds=5 --output trace.outСгенерированный файл можно просмотреть с помощью инструмента трассировки:
$ go tool trace trace.out
2019/12/25 15:30:50 Parsing trace...
2019/12/25 15:30:59 Splitting trace...
2019/12/25 15:31:10 Opening browser. Trace viewer is listening on http://127.0.0.1:42703Go tool trace — это веб-приложение, которое использует протокол Chrome DevTools и совместимо только с браузерами Chrome. Главная страница выглядит примерно так:
View trace (0s-409.575266ms)
View trace (411.075559ms-747.252311ms)
View trace (747.252311ms-1.234968945s)
View trace (1.234968945s-1.774245108s)
View trace (1.774245484s-2.111339514s)
View trace (2.111339514s-2.674030898s)
View trace (2.674031362s-3.044145798s)
View trace (3.044145798s-3.458795252s)
View trace (3.43953778s-4.075080634s)
View trace (4.075081098s-4.439271287s)
View trace (4.439271635s-4.814869651s)
View trace (4.814869651s-5.253597835s)
Goroutine analysis
Network blocking profile ()
Synchronization blocking profile ()
Syscall blocking profile ()
Scheduler latency profile ()
User-defined tasks
User-defined regions
Minimum mutator utilization
Трассировка разделяет время трассировки, чтобы ваш браузер мог справиться с этим
Здесь огромное множество данных, что делает их практически нечитаемыми, если мы не знаем что ищем. Давайте пока оставим это.
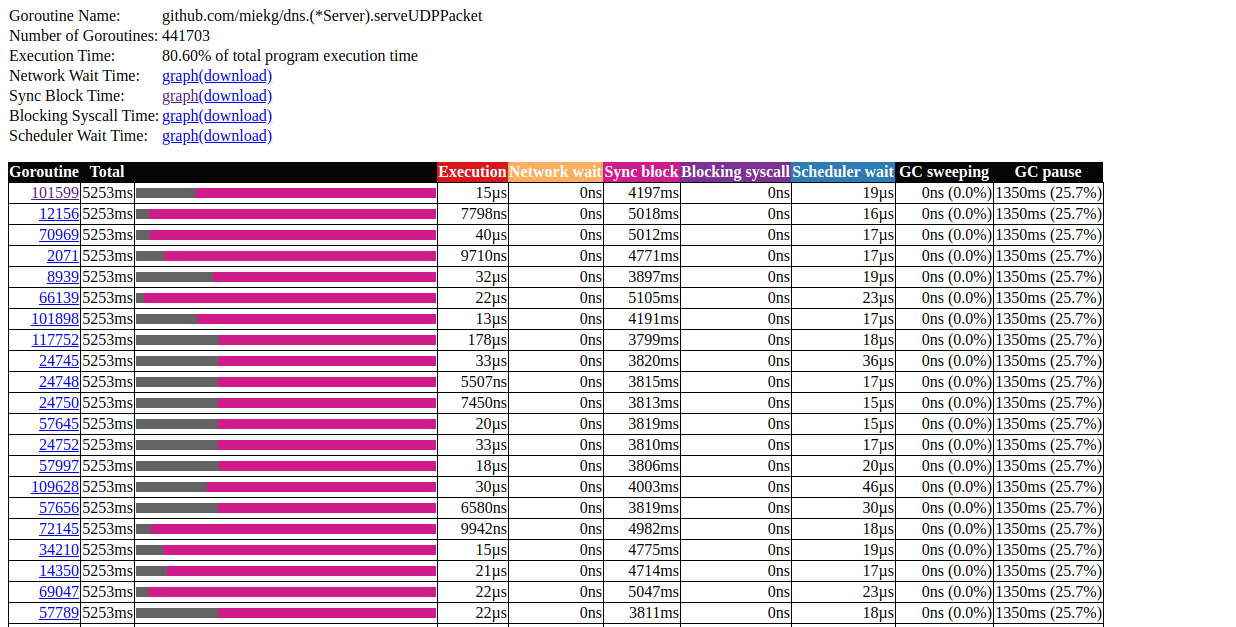
Следующая ссылка на главной странице — «goroutine analysis», который показывает различные виды работающих горутин в программе в течение периода трассировки:
Goroutines:
github.com/miekg/dns.(*Server).serveUDPPacket N=441703
runtime.gcBgMarkWorker N=12
github.com/karlseguin/ccache.(*Cache).worker N=2
main.Start.func1 N=1
runtime.bgsweep N=1
arvancloud/redins/handler.NewHandler.func2 N=1
runtime/trace.Start.func1 N=1
net/http.(*conn).serve N=1
runtime.timerproc N=3
net/http.(*connReader).backgroundRead N=1
N=40Нажмите на первый элемент с N = 441703, вот что мы получим:
анализ горутин
Это очень интересно. Большинство операций практически не тратят времени на выполнение, а большую часть времени проводят в блоке Sync. Давайте подробнее рассмотрим одну из них:
схема трассировки горутин
Похоже, наша программа почти всегда неактивна. Отсюда мы можем перейти непосредственно к инструменту блокировки; профилирование блокировки по умолчанию отключено, нам нужно сначала включить его в нашем коде:
runtime.SetBlockProfileRate(1)Теперь мы можем получить выборку блокировок:
$ go tool pprof http://localhost:6060/debug/pprof/block
(pprof) top
Showing nodes accounting for 16.03wks, 99.75% of 16.07wks total
Dropped 87 nodes (cum <= 0.08wks)
Showing top 10 nodes out of 27
flat flat% sum% cum cum%
10.78wks 67.08% 67.08% 10.78wks 67.08% internal/poll.(*fdMutex).rwlock
5.25wks 32.67% 99.75% 5.25wks 32.67% sync.(*Mutex).Lock
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 99.75% 5.25wks 32.68% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 99.75% 16.04wks 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*RequestContext).Response
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.ChooseIp
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*Server).serveDNS
(pprof)Здесь у нас есть две разные блокировки (poll.fdMutex и sync.Mutex), отвечающие почти за 100% блокировок. Это подтверждает наше предположение о конфликте блокировок, теперь нам нужно только найти, где это происходит:
(pprof) svg lockЭта команда создает векторный граф всех узлов, учитывающих конфликты, с упором на функции блокировки:
svg-график эндпонта блокировки
мы можем получить тот же результат из эндпоинта горутины:
$ go tool pprof http://localhost:6060/debug/pprof/goroutineи затем:
(pprof) top
Showing nodes accounting for 294412, 100% of 294424 total
Dropped 84 nodes (cum <= 1472)
Showing top 10 nodes out of 32
flat flat% sum% cum cum%
294404 100% 100% 294404 100% runtime.gopark
8 0.0027% 100% 294405 100% github.com/miekg/dns.(*Server).serveUDPPacket
0 0% 100% 58257 19.79% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 100% 58259 19.79% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 100% 293852 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*RequestContext).Response
0 0% 100% 58140 19.75% arvancloud/redins/handler.ChooseIp
0 0% 100% 293852 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 100% 293900 99.82% github.com/miekg/dns.(*Server).serveDNS
(pprof)почти все наши программы находятся в runtime.gopark, это планировщик go, усыпляющий горутины; очень распространенная причина этого — конфликт блокировок
(pprof) svg goparksvg-график конечной точки горутин
Здесь мы видим два источника конфликтов:
UDPConn.WriteMsg()
Похоже, что все ответы заканчиваются записью на один и тот же FD (отсюда и блокировка), это имеет смысл, поскольку все они имеют один и тот же адрес источника.
Мы провели небольшой эксперимент с различными решениями, и в конце решили использовать несколько листнеров для балансировки нагрузки. Таким образом, мы позволяем ОС балансировать входящие запросы между различными соединениями и уменьшать конфликты.
Rand()
Похоже, что в обычных math/rand функциях есть блокировка (подробнее об этом здесь). Это можно легко исправить с помощью
Rand.New(), который создает генератор случайных чисел без блокировочной оберткиrg := rand.New(rand.NewSource(int64(time.Now().Nanosecond())))Это немного лучше, но создавать новый источник каждый раз дорого. Можно ли сделать еще лучше? В нашем случае нам действительно не нужно случайное число. Нам просто нужно равномерное распределение для балансировки нагрузки, и получается, что
Time.Nanoseconds() может нам подойти.Теперь, когда мы устранили все лишние блокировки, давайте посмотрим на результаты:
анализ горутин
Выглядит лучше, но все же большая часть времени уходит на блокировку синхронизации. Давайте посмотрим на профиль блокировки синхронизации с главной страницы пользовательского интерфейса трассировки:
график времени блокировки синхронизации
Давайте взглянем на функцию повышения
ccache с конечной точки блокировки pprof:(pprof) list promote
ROUTINE ======================== github.com/karlseguin/ccache.(*Cache).promote in ...
0 9.66days (flat, cum) 99.70% of Total
. . 155: h.Write([]byte(key))
. . 156: return c.buckets[h.Sum32()&c.bucketMask]
. . 157:}
. . 158:
. . 159:func (c *Cache) promote(item *Item) {
. 9.66days 160: c.promotables <- item
. . 161:}
. . 162:
. . 163:func (c *Cache) worker() {
. . 164: defer close(c.donec)
. . 165:Все вызовы
ccache.Get() заканчиваются отправкой на один канал c.promotables. Кэширование является важной частью нашего сервиса, мы должны рассмотреть другие варианты; У Dgraph есть отличная статья о состоянии кэша в go, у них также есть отличный модуль кэширования под названием ristretto. К сожалению, ristretto пока не поддерживает высвобождение на основе Ttl, мы могли бы обойти эту проблему, используя очень большой MaxCost и сохранив значение тайм-аута в нашей структуре кэша (мы хотим сохранить устаревшие данные в кэше). Давайте посмотрим результат при использовании ristretto:анализ горутин
Отлично!
Нам удалось сократить максимальное время выполнения горутины с 5000 мс до 22 мс. Тем не менее, большая часть времени выполнения делится между «блокировкой синхронизации» и «ожиданием планировщика». Давайте посмотрим, сможем ли мы что-нибудь с этим сделать:
график времени блокировки синхронизации
Мы мало что можем сделать с
fdMutex.rwlock, теперь давайте сосредоточимся на другом: gcMarkDone, который отвечает за 53% времени блока. Эта функция является частью процесса сбора мусора. Их наличие в критическом участке часто является признаком того, что мы перегружаем gc.оптимизация аллокаций
На этом этапе может быть полезно посмотреть, как работает сборка мусора; Go использует mark-and-sweep сборщик. Он отслеживает все, что выделено, и как только он достигает в два раза большего (или любого другого значения, на которое установлено GOGC) размера от предыдущего размера, запускается очистка GC. Оценка происходит в три этапа:
- Установка маркера (STW)
- Маркировка (параллельно)
- Окончание маркировки (STW)
Фазы «Остановить мир» (Stop The World, STW) останавливают весь процесс, хотя они, как правило, очень короткие, сплошные циклы могут увеличить продолжительность. Это потому, что в настоящее время (go v1.13) горутины являются вытесняемыми только в точках вызова функции, поэтому для сплошного цикла возможно произвольно большое время паузы, поскольку GC ожидает остановки всех горутин.
Во время маркировки gc использует около 25%
GOMAXPROCS, но дополнительные вспомогательные функции могут быть принудительно добавлены в mark assist, это происходит, когда быстро выделяющаяся горутина опережает фоновый маркер, чтобы уменьшить задержку, вызванную gc, нам нужно минимизировать использование кучи.Следует отметить две вещи:
- количество выделений имеет большее значение, чем размер (например, 1000 выделений памяти из 20-байтовой структуры создают гораздо больше нагрузки на кучу, чем одно выделение 20000 байтов);
- в отличие от таких языков, как C/C++, не все выделения памяти оказываются в куче. Компилятор go решает, будет ли переменная перемещаться в кучу или она может быть размещена внутри фрейма стека. В отличие от переменных, размещаемых в куче, переменные, выделенные в стеке, не нагружают gc.
Для получения дополнительной информации о модели памяти Go и архитектуры GC смотрите эту презентацию.
для оптимизации выделения памяти мы используем набор инструментов go:
- профилировщик процессора, чтобы найти горячие распределения;
- профилировщик памяти для отслеживания выделений;
- трассировщик для паттернов; GC
- escape-анализ, чтобы выяснить, почему происходит аллокация.
Давайте начнем с профилировщика процессора:
$ go tool pprof http://localhost:6060/debug/pprof/profile?seconds=20
(pprof) top 20 -cum
Showing nodes accounting for 7.27s, 29.10% of 24.98s total
Dropped 315 nodes (cum <= 0.12s)
Showing top 20 nodes out of 201
flat flat% sum% cum cum%
0 0% 0% 16.42s 65.73% github.com/miekg/dns.(*Server).serveUDPPacket
0.02s 0.08% 0.08% 16.02s 64.13% github.com/miekg/dns.(*Server).serveDNS
0.02s 0.08% 0.16% 13.69s 54.80% github.com/miekg/dns.(*ServeMux).ServeDNS
0.01s 0.04% 0.2% 13.48s 53.96% github.com/miekg/dns.HandlerFunc.ServeDNS
0.02s 0.08% 0.28% 13.47s 53.92% main.handleRequest
0.24s 0.96% 1.24% 12.50s 50.04% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0.81s 3.24% 4.48% 6.91s 27.66% runtime.gentraceback
3.82s 15.29% 19.78% 5.48s 21.94% syscall.Syscall
0.02s 0.08% 19.86% 5.44s 21.78% arvancloud/redins/handler.(*DnsRequestHandler).Response
0.06s 0.24% 20.10% 5.25s 21.02% arvancloud/redins/handler.(*RequestContext).Response
0.03s 0.12% 20.22% 4.97s 19.90% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0.56s 2.24% 22.46% 4.92s 19.70% runtime.mallocgc
0.07s 0.28% 22.74% 4.90s 19.62% github.com/miekg/dns.(*response).WriteMsg
0.04s 0.16% 22.90% 4.40s 17.61% github.com/miekg/dns.(*response).Write
0.01s 0.04% 22.94% 4.36s 17.45% github.com/miekg/dns.WriteToSessionUDP
1.43s 5.72% 28.66% 4.30s 17.21% runtime.pcvalue
0.01s 0.04% 28.70% 4.15s 16.61% runtime.newstack
0.06s 0.24% 28.94% 4.09s 16.37% runtime.copystack
0.01s 0.04% 28.98% 4.05s 16.21% net.(*UDPConn).WriteMsgUDP
0.03s 0.12% 29.10% 4.04s 16.17% net.(*UDPConn).writeMsgНас особенно интересуют функции, связанные с
mallocgc, именно здесь происходит помощь с метками(pprof) svg mallocgcМы можем отслеживать распределение, используя конечную точку
alloc, опция alloc_object означает общее количество аллокаций, есть и другие варианты использования памяти и пространства выделения.$ go tool pprof -alloc_objects http://localhost:6060/debug/pprof/allocs
(pprof) top -cum
Active filters:
show=handler
Showing nodes accounting for 58464353, 59.78% of 97803168 total
Dropped 1 node (cum <= 489015)
Showing top 10 nodes out of 19
flat flat% sum% cum cum%
15401215 15.75% 15.75% 70279955 71.86% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
2392100 2.45% 18.19% 27198697 27.81% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
711174 0.73% 18.92% 14936976 15.27% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 18.92% 14161410 14.48% arvancloud/redins/handler.(*DnsRequestHandler).Response
14161410 14.48% 33.40% 14161410 14.48% arvancloud/redins/handler.(*RequestContext).Response
7284487 7.45% 40.85% 11118401 11.37% arvancloud/redins/handler.NewRequestContext
10439697 10.67% 51.52% 10439697 10.67% arvancloud/redins/handler.reverseZone
0 0% 51.52% 10371430 10.60% arvancloud/redins/handler.(*DnsRequestHandler).FindZone
2680723 2.74% 54.26% 8022046 8.20% arvancloud/redins/handler.(*GeoIp).GetSameCountry
5393547 5.51% 59.78% 5393547 5.51% arvancloud/redins/handler.(*DnsRequestHandler).LoadLocationС этого момента мы можем использовать list для каждой функции и посмотреть, сможем ли мы уменьшить выделение памяти. Давайте проверим:
printf-подобные функции
(pprof) list handleRequest
Total: 97803168
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
2555943 83954299 (flat, cum) 85.84% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
. 11118401 40: context := handler.NewRequestContext(w, r)
2555943 2555943 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 70279955 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:Строка 41 особенно интересна, даже когда отладка отключена, там все еще выделяется память, мы можем использовать escape-анализ, чтобы исследовать ее подробнее.
Инструмент Escape-анализа Go на самом деле флаг компилятора
$ go build -gcflags '-m'Вы можете добавить другой -m для получения дополнительной информации
$ go build -gcflags '-m 'для более удобного интерфейса используйте view-annotated-file.
$ go build -gcflags '-m'
.
.
.
../redins.go:39:20: leaking param: w
./redins.go:39:42: leaking param: r
./redins.go:41:55: r.MsgHdr.Id escapes to heap
./redins.go:41:75: context.RawName() escapes to heap
./redins.go:41:91: context.Request.Type() escapes to heap
./redins.go:41:23: handleRequest []interface {} literal does not escape
./redins.go:219:17: leaking param: path
.
.
.Здесь все параметры
Debugf уходят в кучу. Это происходит из-за способа определения Debugf:func (l *EventLogger) Debugf(format string, args ...interface{})Все параметры
args преобразуются в тип interface{}, который всегда сбрасывается в кучу. Мы можем либо удалить журналы отладки, либо использовать библиотеку журналов с нулевым распределением, например, zerolog.Для получения дополнительной информации об escape- анализе см. «allocation eficiency in golang».
Работа со строками
(pprof) list reverseZone
Total: 100817064
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
6127746 10379086 (flat, cum) 10.29% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 4251340 401: x := strings.Split(zone, ".")
. . 402: var y string
. . 403: for i := len(x) - 1; i >= 0; i-- {
6127746 6127746 404: y += x[i] + "."
. . 405: }
. . 406: return y
. . 407:}
. . 408:
. . 409:func (h *DnsRequestHandler) LoadZones() {
(pprof)Поскольку строка в Go является неизменяемой, создание временной строки вызывает выделение памяти. Начиная с Go 1.10, можно использовать
strings.Builder для создания строки.(pprof) list reverseZone
Total: 93437002
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
0 7580611 (flat, cum) 8.11% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 3681140 401: x := strings.Split(zone, ".")
. . 402: var sb strings.Builder
. 3899471 403: sb.Grow(len(zone)+1)
. . 404: for i := len(x) - 1; i >= 0; i-- {
. . 405: sb.WriteString(x[i])
. . 406: sb.WriteByte('.')
. . 407: }
. . 408: return sb.String()Поскольку нас не волнует значение перевернутой строки, мы можем устранить
Split(), просто перевернув всю строку.(pprof) list reverseZone
Total: 89094296
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
3801168 3801168 (flat, cum) 4.27% of Total
. . 400:func reverseZone(zone string) []byte {
. . 401: runes := []rune("." + zone)
. . 402: for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
. . 403: runes[i], runes[j] = runes[j], runes[i]
. . 404: }
3801168 3801168 405: return []byte(string(runes))
. . 406:}
. . 407:
. . 408:func (h *DnsRequestHandler) LoadZones() {
. . 409: h.LastZoneUpdate = time.Now()
. . 410: zones, err := h.Redis.SMembers("redins:zones")Прочитать подробнее о работе со строками можно здесь.
sync.Pool
(pprof) list GetASN
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetASN in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1146897 1146897 (flat, cum) 1.66% of Total
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
1146897 1146897 232: var record struct {
. . 233: AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
. . 234: }
. . 235: err := g.ASNDB.Lookup(ip, &record)
. . 236: if err != nil {
. . 237: logger.Default.Errorf("lookup failed : %s", err)
(pprof) list GetGeoLocation
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetGeoLocation in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1376298 3604572 (flat, cum) 5.22% of Total
. . 207:
. . 208:func (g *GeoIp) GetGeoLocation(ip net.IP) (latitude float64, longitude float64, country string, err error) {
. . 209: if !g.Enable || g.CountryDB == nil {
. . 210: return
. . 211: }
1376298 1376298 212: var record struct {
. . 213: Location struct {
. . 214: Latitude float64 `maxminddb:"latitude"`
. . 215: LongitudeOffset uintptr `maxminddb:"longitude"`
. . 216: } `maxminddb:"location"`
. . 217: Country struct {
. . 218: ISOCode string `maxminddb:"iso_code"`
. . 219: } `maxminddb:"country"`
. . 220: }
. . 221: // logger.Default.Debugf("ip : %s", ip)
. . 222: if err := g.CountryDB.Lookup(ip, &record); err != nil {
. . 223: logger.Default.Errorf("lookup failed : %s", err)
. . 224: return 0, 0, "", err
. . 225: }
. 2228274 226: _ = g.CountryDB.Decode(record.Location.LongitudeOffset, &longitude)
. . 227: // logger.Default.Debug("lat = ", record.Location.Latitude, " lang = ", longitude, " country = ", record.Country.ISOCode)
. . 228: return record.Location.Latitude, longitude, record.Country.ISOCode, nil
. . 229:}
. . 230:
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {Мы используем функции maxmiddb для получения данных геолокации. Эти функции принимают
interface{} в качестве параметров, которые, как мы видели ранее, могут вызывать побеги кучи.мы можем использовать
sync.Pool для кэширования выделенных, но неиспользуемых элементов для последующего повторного использования.type MMDBGeoLocation struct {
Coordinations struct {
Latitude float64 `maxminddb:"latitude"`
Longitude float64
LongitudeOffset uintptr `maxminddb:"longitude"`
} `maxminddb:"location"`
Country struct {
ISOCode string `maxminddb:"iso_code"`
} `maxminddb:"country"`
}
type MMDBASN struct {
AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
}
func (g *GeoIp) GetGeoLocation(ip net.IP) (*MMDBGeoLocation, error) {
if !g.Enable || g.CountryDB == nil {
return nil, EMMDBNotAvailable
}
var record *MMDBGeoLocation = g.LocationPool.Get().(*MMDBGeoLocation)
logger.Default.Debugf("ip : %s", ip)
if err := g.CountryDB.Lookup(ip, &record); err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return nil, err
}
_ = g.CountryDB.Decode(record.Coordinations.LongitudeOffset, &record.Coordinations.Longitude)
logger.Default.Debug("lat = ", record.Coordinations.Latitude, " lang = ", record.Coordinations.Longitude, " country = ", record.Country.ISOCode)
return record, nil
}
func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
var record *MMDBASN = g.AsnPool.Get().(*MMDBASN)
err := g.ASNDB.Lookup(ip, record)
if err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return 0, err
}
logger.Default.Debug("asn = ", record.AutonomousSystemNumber)
return record.AutonomousSystemNumber, nil
}Больше о sync.Pool здесь.
Есть много других возможных оптимизаций, но на данный момент, кажется, мы уже сделали достаточно. Для получения дополнительной информации о методах оптимизации памяти, можете прочитать Allocation efficiency in high-performance Go services.
Результаты
Чтобы визуализировать результаты оптимизации памяти, мы используем диаграмму в
go tool trace под названием «Minimum Mutator Utilization», здесь Mutator означает не gc.До оптимизации:
Здесь у нас есть окно около 500 миллисекунд без эффективного использования (gc потребляет все ресурсы), и мы никогда не получим 80% эффективного использования в долгосрочной перспективе. Мы хотим, чтобы окно нулевого эффективного использования было как можно меньше, и максимально быстро достигать 100% использования, как-то так:
после оптимизации:
Вывод
С помощью инструментов go нам удалось оптимизировать наш сервис для обработки большого количества запросов и лучшего использования системных ресурсов.
Вы можете посмотреть наш исходный код на GitHub. Вот неоптимизированная версия и вот оптимизированная.
Также будет полезно
- go perfbook
- effective go
- so you wanna go fast
- writing high performace go
На этом все. До встречи на курсе!
")

