

Привет! Меня зовут Иван Гаас, я руковожу автоматизацией процессов разработки в Почтатехе — компании, создающей цифровые продукты для Почты России.
Среднее количество сообщений, которые мы обрабатываем в Почте — от 500 тысяч до миллиона в секунду. В пики, когда наша big data прогоняет свои 25 петабайт данных — до 3 миллионов. При этом кластер Kafka состоит всего из 12 серверов в каждом из 3 дата-центров и справляется с этим.
C 2016 года мы в три раза увеличили количество новых цифровых сервисов. Корпоративная шина на Kafka помогла быстро масштабироваться: количество интеграций за последнее время упало с 1000 до 300 и теперь растёт незначительно. Если раньше интеграция сервиса растягивалась на месяцы, то теперь достаточно нескольких дней.
Я расскажу, как мы построили шину, которая обеспечивает такую производительность.
Как было раньше
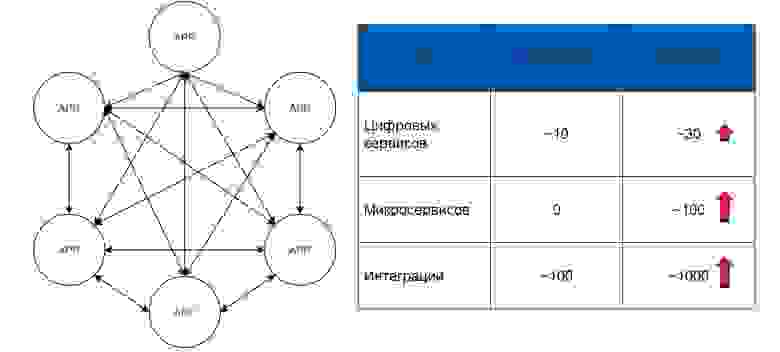
На 2014 год все сервисы Почты России интегрировались по схеме full-mesh. Было всего 100 интеграций, а цифровых сервисов — порядка 10.
За следующие два года мы написали около 30 цифровых продуктов и пришли к микросервисной архитектуре. Появилось порядка 100 микросервисов, а интеграции выросли до 1000. В таких условиях каждый новый сервис — это 1000 договоренностей с кучей команд и 1000 форматов данных. Это занимало бы не месяцы, а годы. Мы поняли, что развиваться по той же схеме, что и раньше, уже невозможно.
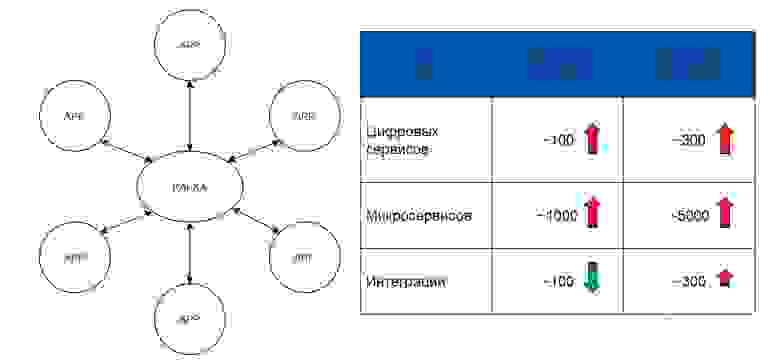
Наши архитекторы посмотрели, что есть из паттернов и архитектурных решений, и предложили уйти от full-mesh к «звезде». То есть поставить в центре сервис-ориентированное решение, с которым будет интегрироваться абсолютно всё. Так появилась наша корпоративная шина на Kafka.
Почему Kafka
Мы рассматривали разные брокеры очередей: RabbitMQ, ActiveMQ и Kafka, которая тогда ещё только появилась. Решение, в нашем понимании, должно было соответствовать следующим требованиям:
Open source — возможность расширять функциональность своими силами.
Производительность не ниже 1 000 000 RPS. На тот момент у нас уже была big data, которая поднимала и обрабатывала большие объёмы данных за ночь.
Масштабируемость — возможность наращивать производительность горизонтальным увеличением мощностей. Мы понимали, что данных будет всё больше и больше, так как количество цифровых продуктов в Почте России продолжит увеличиваться.
Управляемость (rate limits). Мы сильно рисковали, когда ставили единый продукт в центре всего, потому что при его отказе перестанет работать вся Почта России, а не какой-то кусочек. Поэтому хотели максимальной управляемости.
RabbitMQ не подошёл, потому что на рынке было мало тех, кто пишет на Erlang. ActiveMQ не устроил нас по управляемости и производительности. Kafka в наших тестах выдавала больше, так что подходила лучше всего.
Требования к корпоративной шине
Kafka — отличный продукт, но это просто шина. Нам была нужна корпоративная шина данных. Вот что требовалось доработать.
Трансформация и обогащение данных на лету. Это главное требование. Среди сервисов Почты России огромная связанность. Например, вы забрали посылку в отделении. Первый сервис формирует сообщение о том, что мы её отдали. Далее оно обогащается данными из второго сервиса: на основе какого документа вы получили эту посылку. Третий сервис сложит скан документа в наше хранилище. А четвертый — составит из всего этого единое сообщение.
Дополнительные интерфейсы. Мы хотели, чтобы были свои интерфейсы для клиентов, а не только Kafka-native.
Дополнительный слой для работы с большими данными. Тесты показали, что сообщения больше мегабайта критически роняют перформанс Kafka.
Система аутентификации и авторизации. Важно было соответствовать требованиям законодательства о безопасности.
Система контроля лимитов. Мы понимали: если задедосят какой-то сервис и мы упадём, то потеряем все сервисы.
Системы эксплуатации и мониторинга. Нужно было представлять, как работать с продуктом и что происходит внутри него, и получать уведомления об авариях.
Компоненты корпоративной шины
В итоге у нас получилась такая шина:
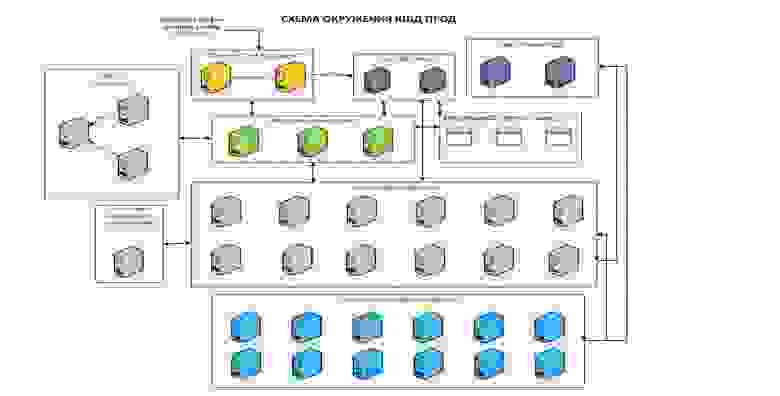
Рассмотрим её компоненты.
С балансировщиками всё просто. Есть несколько nginx, между ними keepalived для того, чтобы сохранять IP-адрес (просто для отказоустойчивости), поэтому углубляться не будем.
А вот шлюз авторизации мы написали самостоятельно. Он как раз управляет теми требованиями, которые мы выдвигали к корпоративной шине. У него есть своя БД — это PostgreSQL. Почти все наши кластеры в продакшене, которые используют эту базу, на Patroni. Так исторически сложилось.
НСИ REST Proxy существует для того, чтобы выдавать внешние сервисы как собственный сервис Kafka — справочники, интеграции с внешними системами данных. Например, с 1С, чтобы клиентам не пришлось ходить за этими данными в другую систему. Они могут как обычно интегрироваться с Kafka, спросить у неё данные и получить.
Мы изобрели велосипед и написали своё СХФ (файловое хранилище). Это было нужно, чтобы создать дополнительный слой для работы с большими данными. Когда нам приходит больше 1 МБ, они сохраняются не в очередь, а в файловое хранилище, которое доступно всем по REST, а в сообщение помещается ссылка. Все, кому понадобятся данные из этого сообщения, увидят ссылку, смогут по ней пройти и по собственному токену получить доступ именно к этому файлу в СХФ.
Система мониторинга достаточно классическая — Grafana, Prometheus, Elastic под логи.
У нас ещё остаются Kafka и маршрутизатор, их мы разберём более подробно.
Шлюз авторизации (API Gateway)
Шлюз авторизации, который мы называем API Gateway, мы сами написали на Java.
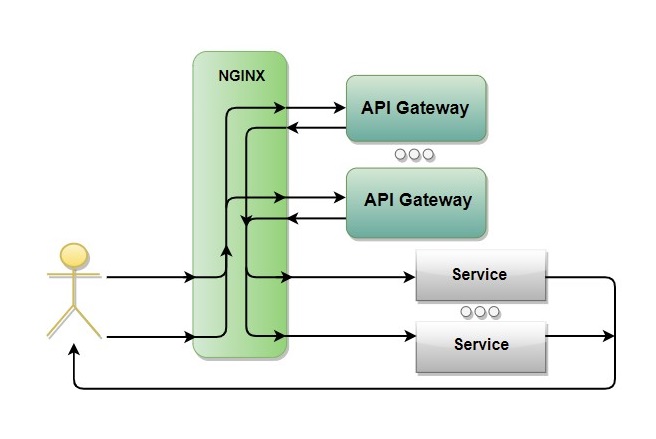
Его целью было предоставить REST API для наших клиентов. Когда мы это делали, ещё не было Confluent, а только Kafka-native. Поэтому пришлось дописывать самостоятельно. На REST мы проверяем, что токен позволяет клиенту получить доступ (пройти аутентификацию).
Ещё API Gateway должен контролировать и учитывать лимиты. Kafka может сама ограничивать лимиты через native, но через REST — нет. В том числе для этого API Gateway и нужна БД. Он должен заблокировать доступ, если кто-то нас дедосит или превысил свои лимиты.
Веб-портал
Этот компонент мы тоже написали сами.

Он управляет аутентификацией и авторизацией. В этом решении они локальные, без LDAP (Lightweight Directory Access Protocol) и прочего. Именно через портал создаются токен, топики и раздаются права на них.
Здесь же можно выставить лимиты, которые мы предусматриваем. Например, сколько сообщений будем принимать в секунду, в минуту и какого объёма.
Ещё мы мониторим состояние yarn jobs, потому что в качестве scheduler стоит yarn, а в виде маршрутизатора — Hadoop.
Маршрутизатор — Hadoop
Это самый сложный компонент. Если вкратце, то мы называем его маршрутизатором, потому что он делает всю магию с данными:
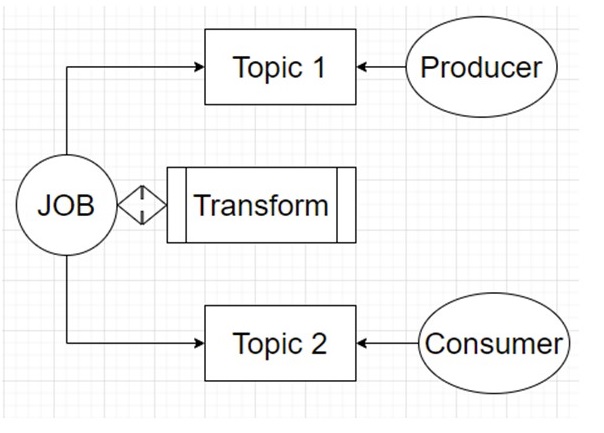
У него написана логика работы с данными. Он смотрит в один топик, забирает оттуда данные, если нужно, трансформирует и обогащает. Ещё он умеет их фильтровать, то есть пропускать «грязные» данные и перекладывать их для консьюмера в топик 2. Система перекладывания сообщений такая: пишется всегда в один топик, а читается из другого. И так почти для каждой системы. На данный момент у нас в шине почти тысяча топиков.
Для интеграции с внешними системами мы используем Hadoop, но в основном для того, чтобы легко и удобно запускать yarn scheduler. Сам HDFS мы особо не используем. В yarn jobs запускаем два фреймворка:
Sansa в real-time следит за данными.
Spark — так называемые batch job, их всего две: обработка логов и выкачка больших словарей данных к себе по scheduler.
Всё, что написано под Sansa, ещё запускается на Apache Camel. У него удобный набор инструментов для обработки сообщений: split, merge, transform. Мы взяли его, чтобы каждый раз не писать всю эту логику самостоятельно. В принципе, можно это сделать, а вместо Sansa попробовать Flink, но Sansa нативное решение от компании LinkedIn, которая в свое время открыла Kafka. Они очень классно интегрируются.
Производительность корпоративной шины
Посмотрим на статистику Почты России.
У нас 3 ЦОДа: 2 в Москве и 1 в Адлере. Между ними MirrorMaker v2. Таким образом у нас во всех ЦОДах по Kafka расползаются одинаковые данные. Чтобы запустить эту систему в 3 ЦОДах, мы закупили 98 серверов. Все они bare metal, в каждом:
72 ядра (с hyper threading)
386 ГБ оперативной памяти
20 TБ SAS-дисков
В каждом сервере по 2 сетевых интерфейса 10 Гб в секунду.

В среднем нагрузка на сетевых интерфейсах 2 Гб в секунду, в пике она достигает 7–8 Гб в секунду. Для этого нам понадобился bonding, потому что производительности одного сетевого интерфейса не хватает при таких нагрузках.

Практически на каждом сервере скорость обработки сообщений — до 3 млн в секунду. То есть в нормальном состоянии мы обрабатываем от 500 тысяч до миллиона, а в пики, когда big data прогоняет 25 ПБ, — до 3 миллионов в секунду. Рост начинается приблизительно с 6 вечера до 9 утра (в нерабочее время), чтобы никому не мешать. При этом кластер Kafka состоит из 12 серверов в каждом дата-центре и вполне с этим справляется.

В это время на серверах всё отлично. Kafka практически не потребляет CPU.
Как добивались такой производительности
Выделенные сервера и сетевой контур
Мы пробовали запускаться на виртуальных серверах. Скажу честно, получилось не очень. И дело даже не в CPU, а вот в чём:
Появляется latency на память
Невозможно выделять большие блоки памяти, а именно память даёт такую скорость
Нужны выделенные SAS-диски
Для Kafka точно так же, как для Cassandra, под партиции нужны отдельные диски. Поэтому нам пришлось покупать выделенные сервера с корзинами по 20–24 диска и забивать их небольшими (до терабайта) дисками, чтобы выделять их под партиции. Только тогда мы стали получать приемлемую скорость. Если вы смешаете на одном диске несколько партиций, никогда не получите такой перформанс, как у нас на картинках.
Ещё один важный момент — это выделенный сетевой контур L2. Нам пришлось полностью построить отдельный сетевой контур для Kafka, потому что, когда Kafka перемалывает сообщения, на её свитчах никто больше работать не может. Что бы мы ни пробовали делать, какие бы свитчи ни брали — и ультрасовременные, и суперскоростные — ничего не помогало. Поэтому построили отдельный сетевой контур, чтобы Kafka никто не мешал работать и она, соответственно, тоже.
Память под cache операционной системы
Это самый важный пункт про скорость! Мы дарим память не Kafka, ей она не нужна. Kafka при любых нагрузках почти никогда не выедает больше 20 ГБ.
Вся память отправляется в cache ОС:
Мы работаем даже не с дисками. ОС кэширует данные, к которым мы чаще всего обращаемся, и именно за счёт этого позволяет с максимальной скоростью читать и обрабатывать их на кластере.
Параметры Java-машины
Чтобы Kafka работала с такой производительностью, также немаловажно затюнить Java-машину. Её параметры у нас такие:
Xms24G -Xmx24G -XX:MetaspaceSize=96m -XX:+UseG1GC
XX:MaxGCPauseMillis=20
XX:InitiatingHeapOccupancyPercent=35
XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50
XX:MaxMetaspaceFreeRatio=80
Из-за того что Kafka не потребляет много памяти, мы её даже ограничили 24 ГБ. Потому что, если она съест больше, у ОС останется мало кэша, и мы получим деградацию.
Заметьте, мы используем G1 GC, а не стандартный garbage collector. Мы выставляем для него MaxGCPause в миллисекундах. То есть сообщаем garbage collector: неважно, сколько мусора у нас в Java, неважно, что и как ты будешь делать, но ты не имеешь права остановить процессинг больше, чем на 20 мс. За счёт этого мы никогда не получаем длинный stop-the-world.
Параметр MetaspaceSize отвечает за то, когда запустить full scan garbage collector. Если меньше 80% от 96 МБ занято, то full scan вообще никогда не запускается.
Параметры Kafka
Здесь я привёл не все параметры, но самые важные, которые нам пришлось выкрутить от дефолтных значений:
background.threads=20
У нас параллельная обработка, поэтому нужно больше threads.
num.io.threads=60
По умолчанию, этот параметр достаточно маленький. Мы выкрутили его до максимума, ориентируясь на количество наших дисков. Если такое значение поставить на одном диске, вы убьёте его io в ноль, и у вас не будет ничего работать.
num.network.threads=30
Мы выкрутили количество сетевых threads из-за того, что сеть часто становилась узким местом, и нам нужно было её разогнать.
num.replica.fetchers=5
Этот параметр контролирует количество процессов, отвечающих за репликацию внутри кластера. По умолчанию, он равен 1, но мы выкрутили его, потому что нам важно получать быструю репликацию.
queued.max.requests=1000
Этот параметр говорит о том, сколько максимально requests в параллель мы будем обрабатывать в каждом топике. По дефолту, в Kafka он тоже не такой большой.
socket.receive.buffer.bytes=1048576
socket.send.buffer.bytes=1048576
Мы увеличили буферы на TCP, чтобы буферизировать больше информации, поступающей по сети.
Преимущества и недостатки нашего решения
Преимущества
Мы упростили достижение большого количества интеграций. Теперь интеграция делается максимум 30 дней, и это если очень сложная трансформация данных. Если продюсер и консьюмер работают в одном формате, то всего два дня.
Ещё это решение сильный драйвер для старта новых проектов и сервисов. Его разрабатывает, поддерживает и интегрирует отдельная команда:
6 разработчиков Java/Scala
12 аналитиков
6 специалистов эксплуатации (2 девопса и 4 инженера поддержки)
Когда появляется новый цифровой сервис и приходит запрос на интеграцию, аналитики договариваются, в каком формате принимать и отдавать данные. То есть, по сути, команда разработки сервиса вообще не должна думать о том, как работать с данными. Единственное, что должно их заботить, — то, что их данные отдаются в JSON. А какие данные — Kafka сама разберётся: «грязные», «сухие» — любые, без разницы. Разработчики не тратят на это время, они просто пишут код, а вы за них делаете всю интеграцию и отдаёте консьюмерам в нормальном виде.
У нас получается высокий уровень надёжности из коробки. Так уж написана Kafka, что даже по дефолту у неё минимум 2 реплики для каждого топика. Это достаточно надёжно. У нас лишь для суперважных топиков с персональными данными стоит 3.
Но у решения, к сожалению, есть и недостатки.
Недостатки
В случае отказа у вас остановятся все сервисы. Конечно, если вы не захотите ещё fallback сделать, например тот же full-mesh. Но это уже перебор, если честно.
Со временем решение может превратиться в бутылочное горлышко. Мы проходили этот этап. Оно, как ни странно, появляется из-за преимущества. Тот самый сильный драйвер позволяет очень быстро запускать большое количество цифровых сервисов, и в какой-то момент они начинают появляться намного быстрее, чем команда интеграции успевает делать интеграции.
Ещё это дорого на внедрении и поддержке для небольших масштабов интеграций. Если у вас 5–10 сервисов, и вы не планируете увеличить их хотя бы в 5 раз, нет большого количества интеграций, маленькая связанность — вам просто не нужно такое решение.
Ну и последний минус: решение даёт высокую нагрузку на сетевое оборудование и требует отдельного железа.
Выводы
Если бы меня вернули на восемь лет назад и попросили построить такое решение, я бы использовал те же технологии. Взял бы ту же самую Sansa и Kafka. Может быть, пересмотрел кое-что. Например, тогда уже был Keystone, поэтому не стоило делать локальную выдачу токенов.
Если бы меня попросили построить такое решение сейчас, я бы пересмотрел архитектуру. Не стал писать файловое хранилище, взял S3, скорее всего, отказался от Hadoop, потому что мы не используем HDFS. Поменял бы запуск yarn: если уж нужен такой scheduler, его можно и в Kubernetes запускать. Наверное, не стал бы трогать Sansa и Camel. Но Kafka оставил бы.
Этот пост — по мотивам доклада на Highload++ 2021. В этом году Почтатех тоже участвует в конференции: Александр Коптин расскажет про автоматизированную сортировку Почты России. Подробности о докладе смотрите здесь.
Конференция Highload++ Foundation 2022 пройдёт 13 и 14 мая в Москве, в Крокус-Экспо. Описание докладов и расписание уже готовы. Билеты можно купить на сайте.
Главный зал «Терминус» будет свободно транслироваться. Всё, что вам нужно, чтобы её смотреть, — зарегистрироваться. Также вы сможете задать вопросы спикерам, а после конференции получите доступ к видеозаписи трансляции. Программу смотрите здесь.


