
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Habr!
Вы или ваши близкие точно сталкиваетесь с тем, что раз в месяц нужно выйти на лестничную площадку, включить фонарик в телефоне и переписать показания счётчика электроэнергии, а ещё снять показания счётчиков воды, и, возможно, даже природного газа. Нашим коллегам из департамента недвижимости и эксплуатации приходится проделывать такое упражнение ежемесячно на 18 тысячах объектов! Поэтому у нас в команде Центра искусственного интеллекта (ЦИИ) Блока «Сервисы» появилась идея облегчить жизнь сервис-менеджера с помощью технологии Computer Vision (далее CV), как Optical Character Recognition (сокращённо — OCR).
В принципе, задача выглядела простой и очевидной даже на уровне начинающего специалиста, который только осваивает технологии CV. Но в реальной жизни всё оказалось намного интереснее и вариативнее. Во-первых, даже при наличии некоторого количества публикаций с описанием похожих решений не оказалось готового датасета, на котором эти решения можно было бы сравнить. Во-вторых, обладая достаточным количеством ресурсов, сбор и разметка данных всё равно потребовали значительной изобретательности.

Кроме того, на своей лестничной площадке мы видим всегда одни и те же счётчики, а разнообразие их видов в «дикой природе» оказалось гораздо шире! Поэтому мы решили, что будет интересно узнать о нашем пути практического решения задачи распознавания счётчиков (более строгое название, как подсказали наши коллеги, — приборов учёта. Поэтому далее будут встречаться оба этих термина, но речь будет идти об одном и том же).

Коротко об OCR
Оптическое распознавание символов — перевод печатных или рукописных символов с изображения в текст. В зависимости от задачи может применяться посимвольная детекция, модели, основанные на обработке изображения текста как последовательности (например, рекуррентные нейронные сети) и др.
Детали того, как эти подходы работают, многократно разобраны. Например, здесь отличная статья на эту тему https://habr.com/ru/company/mipt/blog/458190/.
В поисках готового решения (спойлер: его нет, ну или почти нет)
Задачи изобретать велосипед не было, поэтому мы начали её решение, апробировав несколько open-source-решений. По большинству из них уже есть обзоры в интернете, упомянем лишь наиболее популярные: Tesseract, PaddleOCR, EasyOCR и др. Также коллеги из Jet сделали отличный обзор того, как это всё работает из коробки. Наши эксперименты показали, что часть из этих библиотек не даёт должного качества даже с дообучением, другие были неудобны в использовании.
Среди закрытых фреймворков мы пробовали SmartIdReader (можно подробно почитать здесь) и Tao Toolkit. В нашей задаче мы не стали их использовать из-за закрытости кода и невозможности тонко настраивать предобработку датасета обоих фреймворков.
В результате к «изобретению велосипеда» пришлось всё-таки приступить.
Сбор датасета или время собирать камни
Когда мы поняли, что без собственных моделей нам не обойтись, возникла проблема сбора датасета, необходимого для их обучения. Набор проблем, возникающих в этой связи, стандартный: сначала сложности со сбором данных, а далее с их разметкой. Пришлось искать компромисс с размером датасета и качеством работы моделей. Исходя из полученного опыта, мы можем сказать, что для начала работы требуется не менее 1000 фотографий. С увеличением сложности задачи эта цифра растёт. В нашем случае сложность с распознаванием счётчиков заключалась ещё и в том, что просто считать цифры недостаточно для успеха, нужно, чтобы CV-модель понимала, какая часть изображения содержит нужные нам данные.
Мы запросили фотографии — примеры счётчиков с наших объектов ― у коллег из департамента недвижимости и эксплуатации. Получив данные, мы, мягко говоря, были несколько удивлены: никому в голову не приходило, что видов счётчиков настолько много, что почти нет двух одинаковых. Посмотрите сами:

Путь к решению задачи по мере накопления данных и увеличения вариативности становился всё тернистее, и сама задача стала быстро напоминать «снежный ком». Оперативно получить достаточное количество примеров изображений и сделать их разметку оказалось крайне затруднительно, так как никто в наших филиалах не мог сказать, какая именно у них модель счётчика. Поэтому мы принялись собирать датасет из открытых источников. В сети нам удалось найти и идентифицировать около 1,5 тыс. фотографий. Большая часть из них была получена с общедоступного датасета на Kaggle. При этом мы также сделали небольшой скрипт для сбора данных из других открытых источников (то есть под эту задачу пришлось создать свой собственный краулер).
После обогащений датасета данными, полученными из интернета, стало понятно, что всё-таки не хватает значительной части изображений счётчиков, разновидностей которых у нас в компании великое множество и которые специфичны. Подход со сбором данных «в папочках» и по почте не дал нужных результатов. Неожиданно полезным и эффективным оказался telegram-бот, специально разработанный под эту задачу. С его помощью оказалось удобно не только собирать изображения счётчиков, но и интерактивно оценивать качество работы разрабатываемых моделей. Это существенно ускорило весь процесс.
Нельзя сказать, что разработка telegram-бота не представляла проблем. Особенно долго мы разбирались с выстраиванием логики обработки множества сообщений от одного пользователя. Помимо сбора данных от конечных пользователей, мы попытались использовать их для разметки данных. Но наша «краудсорс»-гипотеза не подтвердилась. В связи с большим количеством ошибок данные пришлось размечать заново, а процесс разметки постоянно перерабатывать. Оказалось, что нужный результат будет получен быстрее и качественнее, когда весь процесс разметки всё-таки возьмёт на себя специализированная команда.
В результате нам удалось добиться простого и интуитивного взаимодействия человека с ботом: пользователь отправляет одну или несколько фотографий в личном сообщении боту, а в ответ на каждую получает распознанные показания счётчика.
Работало это примерно так:

Как итог — команде разработчиков и разметчиков в короткие сроки (практически за пару месяцев) удалось собрать несколько тысяч фотографий аналоговых и цифровых счётчиков (про происхождение видов чуть ниже), чего вполне хватило для решения задачи. Использование telegram-бота и исходный датасет с Kaggle сильно сократили наше время, затраченное на сбор данных и разметку.
В результате все метрики работы пайплайна были получены примерно на 10% фотографий собранного датасета.
Пайплайн моделей
Став уже экспертами в «счётчиковедении», мы выписали все возможные проблемы, которые, скорее всего, не смогли бы решить, просто наращивая слои будущей нейронной сети:
Определение типа счётчика
Как мы уже отметили ранее, счётчики можно разделить на аналоговые и цифровые. Основное отличие в том, как представлен разделитель дробной части показаний прибора на циферблате. Из-за этого подход к распознанию отличается, и одну модель затруднительно применить к разным кейсам.
Решение проблемы оказалось очевидным — сгодилось вполне легковесное решение ― мы остановились на mobilenetv3. Точность (accuracy) модели составила 0,99.
Поиск циферблата счётчика на изображении
Ещё одно затруднение — счётчики нередко бывают повёрнуты довольно странным образом (часть из них, видимо, везут прямиком из Австралии). Вдобавок сам фотографирующий не всегда держит телефон строго вертикально, а некоторые приборы будто специально прячут подальше от глаз. Всё это создаёт проблему правильно определить позиционирование циферблата для последующей его обработки.

В ходе экспериментов были апробированы разные подходы и архитектуры: детекции yolov5 и detectnet_v2, сегментация Unet, FPN, DeepLabv3. Детекция не подошла из-за того, что по полученному bounding-box’у невозможно определить ориентацию циферблата. С сегментацией получилось лучше: определив контур изображения циферблата, потом достаточно легко восстановить его ориентацию (например, применив серию алгоритмов обработки изображения, имплементированных в opencv — наиболее популярном фреймворке для работы с изображениями). Среди моделей сегментации мы получали сопоставимую точность для разных архитектур, но остановились на Unet++, которая выделяется за счёт более высокой скорости обучения и работы модели.
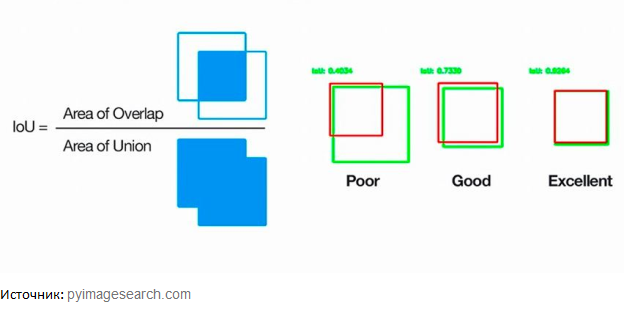
Основной метрикой оценки качества был Intersection-over-Union (IoU). Коэффициент характеризует долю верно классифицированных пикселей, но при этом в знаменателе исключает часть изображения, которая верно распознана как «отсутствие циферблата». У лучшей модели на тесте для аналоговых счётчиков получается 0,917, а для цифровых — 0,949, чего оказалось более чем достаточно для решения нашей задачи.

Ещё одной проблемой оказалось наличие на фото более одного счётчика. В этом случае мы немного упростили жизнь, решив, что в качестве целевого определяется тот, который занимает большую площадь. Решение не идеальное, но на данном этапе оно нас устраивает.
Проверка правильности разворота области циферблата
После разворота области циферблата совершенно нет уверенности, что показания не окажутся перевёрнуты на 180 градусов. Для исключения таких ситуаций мы протестировали разные методы:
обучение отдельной модели, определяющей, перевёрнут счётчик или нет;
добавление аугментации — поворота изображения во время обучения;
поиск признаков, указывающих на правильное расположение цифр. Наиболее очевидный — цвет цифр или обводки цифр справа отличается от цифр слева от разделителя. Это неприменимо в случае монотонных счётчиков, а также для фотографий плохого качества;
надежда, что количество «австралийских» счётчиков мало и этим можно пренебречь.
Конечно, нам хотелось поскорее отправить решение в работу, и по душе пришёлся последний вариант. Но жестокая реальность показала, что таких кейсов оказалось значительное количество. Из оставшихся вариантов лучше всего точность нашего пайплайна подняло встраивание дополнительной модели. Для русификации «австралийских» счётчиков использовали также mobilenetv3. По уже обработанной цифровой зоне она определяет, перевёрнуто изображение показаний или нет. Точность (accuracy) классификатора также оказалась высока и составила 0,99.
Основная OCR-модель
Для аналоговых счётчиков эксперименты с детекцией оказались неудачными, так как модель сильно переобучалась на «0», потому что в исходной выборке большинство показаний счётчиков имело нули в первых нескольких позициях. Видимо, счётчики не так долго работают, чтобы выйти на высокие порядки значений до их замены. Из-за этого число нулей в датасете значительно превышало количество других цифр, что приводило к переобучению на «0» (ну вот — родился новый термин). Также детектор не позволял решить проблему с выделением дробной части показаний.
Здесь тоже попробовали несколько подходов. Лучший результат получился с использованием LSTM-моделей. Данная архитектура достаточно распространена в индустрии и также хорошо себя показала при решении другой задачи ― распознавании автомобильных номеров, но об этом поговорим в следующий раз ;)
Проблеме переобучения хочется выделить отдельный блок рассказа, так как мы столкнулись с новыми сложностями. Даже двукратное увеличение обучающей выборки сильно не улучшило ситуацию. «Серебряной пулей» здесь оказалась кастомная аугментация.
Суть подхода в том, что мы брали цифры с разных счётчиков и случайным образом замешивали их, создавая тем самым совершенно новое изображение циферблата. При этом почему-то попарное разбиение (когда мы вырезаем две подряд идущие цифры) давало значительно больший прирост, чем одиночное. Также псевдослучайным образом мы заменяли нули, если с них начинались значения показаний счётчиков.

При добавлении анализа позиции разделителя дробной части в разметку пришлось немного изменить концепцию. Наличие коктейля «разноцветных» изображений цифр критично влияло на модель определения разделителя дробной части. Так как во многих счётчиках выделение цветом используется для обозначения дробной части счётчика.
Поэтому вместо нарезания и перемешивания цифр из изображений разных счётчиков использовали цифры из одного, но перед разделителем (цифру перед запятой оставляли неизменной для сохранения целостности разделителя). Если разделитель отсутствовал, перемешивались все цифры.
Как выяснилось, это был последний перевал, который отделял нас от цели!
Несмотря на множество прикладных проблем, с которыми мы столкнулись, итоговый пайплайн выдаёт весьма высокое качество: точность (считается как доля верно распознанных изображений) при отсутствии разделителя — 0,913, с разделителем — 0,839 (для целой части — 0,95).
Определение положения разделителя на аналоговых счётчиках
Как мы отметили выше, отдельной проблемой оказалось выделение разделителя дробной части показаний на циферблате. На фото аналоговых счётчиков можно увидеть, что дробная часть отделяется различными способами: может быть явно нарисованная запятая, смена цвета цифр, фона цифр или даже цвета обрамляющей рамки и др.

Решить данную проблему с использованием ранее описанных подходов оказалось не так просто. Алгоритмический подход определения разделителя не дал нужный результат. Мы попробовали добавить в модель OCR условную «,», которая показывала место отделения дробной части от целой.
Первые эксперименты показали, что модель переобучается на количество цифр и часто ставит разделитель там, где его не должно быть. Мы назначили модели ещё одно «пенальти» — за ошибочное размещение разделителя была введена вторая функция потерь, значение которой суммировалось с первой. Изначальной идеей было использовать перекрёстную энтропию (отсутствие или наличие разделителя вообще), но в итоге использовали среднеквадратичное отклонение, где за единицу измерения принимался номер позиции разделителя. Если разделителя не было, его позиция принималась за -1. Точность модели поднялась на 8,85%, для запуска опытной эксплуатации этого оказалось достаточно.
На цифровых счётчиках ситуация в некоторой степени иная: основная проблема в том, что из-за наличия засветок изображения на фотографии разделитель вообще сложно найти, даже с вполне неплохим естественным зрением.
Использование наших результатов
Если вы решили попробовать пройти по пути распознавания показаний счётчиков вслед за нами (возможно, тропа заросла, и мы не заметили, что кто-то здесь прошёл до нас), вот пара практических моментов.
Модель мы запускаем на docker-compose в виртуальной среде. Конкретно в нашем случае необходимости использования GPU не возникло, так как пиковая нагрузка невелика, а время отклика модели на одну фотографию составляет в среднем вполне приемлемые 500-1200 ms, что нашего бизнес-пользователя вполне устроило. Возможно, в вашем случае всё будет не так, будем рады видеть описание ваших подходов в комментариях.
Для написания Telegram-бота мы использовали библиотеку telebot, которая получает фотографию (или группу фотографий) от пользователя и передаёт их на модель, запущенную как flask-приложение в синхронном режиме.
В процессе работы flask-приложение сохраняет поступающие фотографии в s3-хранилище для дальнейшего дообучения и повышения качества модели.
Заключение
Надеюсь, вам было интересно узнать, как можно подойти к решению бизнес-задачи с использованием CV. В пике над проектом работало три человека, при этом в общей сложности на разработку (с учётом сбора и разметки данных) ушло около 6 человеко-месяцев (отнюдь не мифических).
Мы с ребятами работаем над множеством других проектов, ориентированных на решение различных задач прикладного характера. Если такой формат интересен ― пишите в комментариях, расскажем о других историях. Например, о распознавании автомобильных номеров с камеры, установленной на движущемся автомобиле (как выяснилось, стандартные подходы, обогащённые тряской и самыми странными ракурсами изображений, работают не очень).
В настоящее время мы постоянно дорабатываем решение по счётчикам. В тестовом режиме вы можете опробовать его работу, постучавшись к @SberVodomerBot в Telegram. Здесь мы опубликовали только часть, специализирующуюся на «аналоговых» счётчиках.



