Однажды в Ак Барс Банке был разработан сервис подсказок оператору контакт-центра Neurobot. Он брал входящие запросы от пользователей и искал в базе максимально подходящие ответы. Ещё Neurobot предоставлял возможность операторам контакт-центра самим заводить сценарии для бота. Боты срабатывали по триггеру – вхождению ключевых слов из заранее заданного списка с учетом препроцессинга.
Однако со временем стало понятно, что операторы подсказками пользуются нечасто, а мини-боты на ключевых словах могут покрыть лишь малое число тем. Бот фактически выполнял функцию информирования клиентов по нескольким популярным темам. Но в нём не было полноценного флоу общения с пользователями, автозавершения диалогов и отчётности.
Кроме того, система представляла собой монолит, написанный на джанго, и ее было сложно поддерживать, поэтому возникла потребность полностью переделать эту систему.
Обновление
Было решено внедрить бота, который будет принимать звонки, приветствовать информировать и консультировать клиентов. Он помог бы снять нагрузку на операторов за счет автоматизации части диалогов.
Обращения поступают по двум каналам — голосом и в чате. Голос — это примерно три тысячи обращений в сутки, а в чате около 800 пользователей в день, поэтому в час-пик ожидание ответа от оператора доходило до 10-15 минут.
На голосовом канале распознавание и синтез речи производится отдельным сервисом, благодаря этому бот работает только с текстом и подходит и для текстового, и для голосового чатов.
Что должен уметь новый бот
Есть несколько основных функций.
Определить тему разговора. Поэтому сначала мы создали классификатор, который распознаёт 80 различных классов, включающих в себя практически все вопросы, связанные с продуктами и услугами банка, и на их основе выделяет тему сообщения.

Если бот определяет тему, но пока не умеет с ней работать или получает вопрос, на который не знает ответа, то разговор переключается на оператора. Ниже приведен пример общения по теме списка страховых компаний.
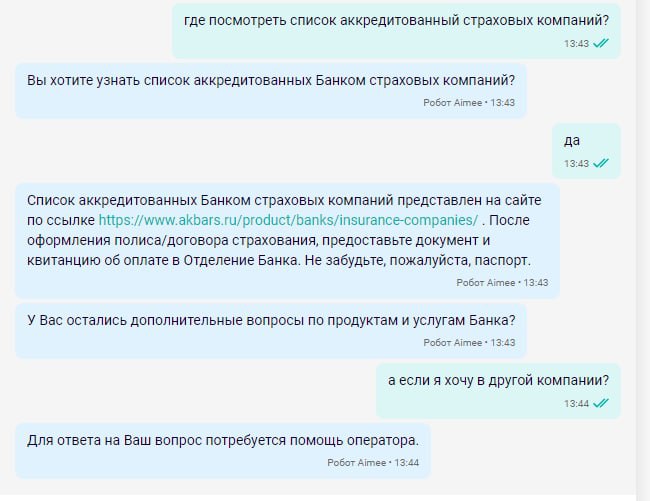
Зато это позволяет открывать перед оператором статью по заданной теме. Это ускоряет поиск оператором информации, а клиент быстрее получает ответ.
Определить, какой клиент пишет — потенциальный или действующий. Определение типа клиента зависит от его запроса. Как мы определяем, какой клиент пишет: во всем перечне классов есть те, которые относятся к потенциальным клиентам – клиентам банка, желающим приобрести продукт или услугу («Оформить кредит», «Заказать карту» и т.д.), а также относящиеся к действующим клиентам – клиентам, которые уже пользуются данным продуктом или услугой («Дата платежа по кредиту», «Дата начисления процентов по вкладу» и т.д.). Таким образом, классификатор на основе темы определяет тип клиента.
Отправить ответ. Оркестратор переадресует сообщения пользователей на умения. Умения определяют тематику сообщения. Если тема определена с высокой уверенностью (выше определенного уровня), то ответ этого умения отправляется обратно пользователю.
Основной метрикой успешности системы в целевой схеме был определен процент автоматизации – доля диалогов, которые завершились без участия оператора.
Какие сложности
При реализации мы столкнулись со следующими сложностями:
Есть данные из чата, но нет данных голоса.
Классов для классификации достаточно много — поскольку много тем.
Классы специфичны. Например, «Бонусные баллы» и «Кешбэк» — разные темы, и в них часто путаются даже сами пользователи. К тому же, есть продукты, которые уникальны только для Ак Барс Банка.
Есть похожие классы. Например, график платежей по кредиту и график платежей по ипотеке.
Для некоторых подтем данных мало.
Форма запросов в чате и голосе отличаются. В чате клиенты строят свои запросы не так, как при звонке на горячую линию. В чате клиенты пишут длинные сообщения. Очень часто в одном сообщении могут быть освещены несколько проблем и тем. Например, вопрос про карту:
Здравствуйте. Моя кредитная карта в личном кабинете имеет статус «не активна». Ранее этой картой пользовался несколько лет. В сентябре этого года по ней возникла просрочка. Два дня назад со мной связывался кредитный специалист, чтобы решить проблему просрочки просили внести очередной платеж. Так как статус карты не активна перевод с другой карты на эту невозможен. Пополнение через банкомат тоже. Как мне пополнить?
Или вопрос о питании в школе:
Здравствуйте. Я хотела заплатить за питание в школе (для всех учащихся вместе, а не только для своего ребенка). Раньше заплатила в банке от своего имени. Говорят, что можно заплатить в ЛК. Захожу в отдел образование, нашла свою школу. Но там спрашивает КБК. А в квитанции такого не нашла. Что туда нужно писать? И не указать там ничего, чтобы было понятно, что я оплатила для всех учащихся школы? Квитанцию сейчас буду прилагать. |
О карте и бонусных милях:
Доброе утро. Я заказал карту «Мир» в приложении. У меня вопрос: на данный момент у меня есть карта ак барс генерейшн, с бонусной программой «мили», после выпуска карты «Мир», я хочу также оставить бонусную программу «мили». Теперь бонусы по карте «Мир» также будут копиться в одном месте, плюсоваться с теми же бонусами что были раньше? |
Поскольку в чате данные уже были, мы решили обучить один классификатор и попробовать использовать его и для чата, и для голоса.
Разметка и набор данных
Так как подход, основанный на ключевых словах и ручных правилах для такого числа классов и данных уже не работает, даже потому, что просто такую систему было бы сложно поддерживать, то в качестве алгоритма обучения мы сразу попробовали использовать предобученную языковую модель. Мы выбрали мультиязычный BERT из библиотеки huggingface и дообучили её на наших данных.
За месяц для каждого из 80 классов мы собрали от 50 до 300 примеров. Сбалансировать выборку мы решили за счет аугментации, то есть за счет увеличения выборки данных для обучения через модификацию существующих данных. В нашем случае мы использовали замену, пропуск и перестановку слов. После аугментации доля синтезированных запросов в некоторых классах достигала 50-70%.
При оценке модели мы выявили множество ложных срабатываний для тех классов, которые были аугментированы. Предполагаем, что это произошло из-за искажения смысла фразы клиента за счет некорректных перестановок и пропусков слов.

Например, «лимит при доллара», который получился из «лимит при обмене доллара» после пропуска слова «обмене».
Или «есть лимиты на конвертацию валюты в личном валюта» — пропуск «ли» и лишнее «валюта» в конце.
Таким образом, синтезированные сообщения стали неправдоподобными. Модель плохо выучила синтаксис таких запросов и классифицировала их как OOD (Out Of Domain). После всех экспериментов получили accuracy 65-70%. Затем решили понизить долю аугментированных данных (оставить максимум 10-20%), либо вовсе убрать такие сообщения из классов.
Итоговая accuracy модели на таком датасете составила 92% на контрольной выборке. Это нас устроило, поэтому мы решили использовать эту модель.
Вывод в продакшн и смена модели
При выводе в продакшн появились сложности, так как для использования классификатора на простом сервере на Python было необходимо больше ресурсов. Поэтому мы решили попробовать усеченную модель BERT — distillBERT. После обучения она весила в 3 раза меньше полноразмерной BERT, работала быстро и при этом продолжала показывать такую же точность.
Читаем логи
Примерно через неделю после запуска мы сняли логи и проанализировали статистику обращений. Результаты оказались неожиданными.
На голосовом канале клиенты формулируют запросы кратко и просто, например «Оформить карту», «Открыть вклад», «Вопрос по кредиту» и другие подобные запросы. С такими обращениями бот справляется отлично и отдаёт правильные и точные ответы. Но не всё так гладко.
Иногда клиенты ограничиваются одним словом, например, «карта», «ипотека», «вклад», имея в виду, что хотят узнать остаток по кредиту, определить график по ипотеке или узнать процент по вкладу.

В таких случаях бот неверно классифицировал запрос пользователя и определял их как потенциальных клиентов. Затем предлагал им оформление продукта (карты, кредита, вклада). Это произошло из-за того, что в обучающей выборке для классов потенциальных клиентов были сообщения вроде «хотел бы узнать про кредиты (ипотеки, вклады, карты)», где явно не написано, что именно хотел бы узнать клиент, но по смыслу очень похоже, что это потенциальные клиенты.
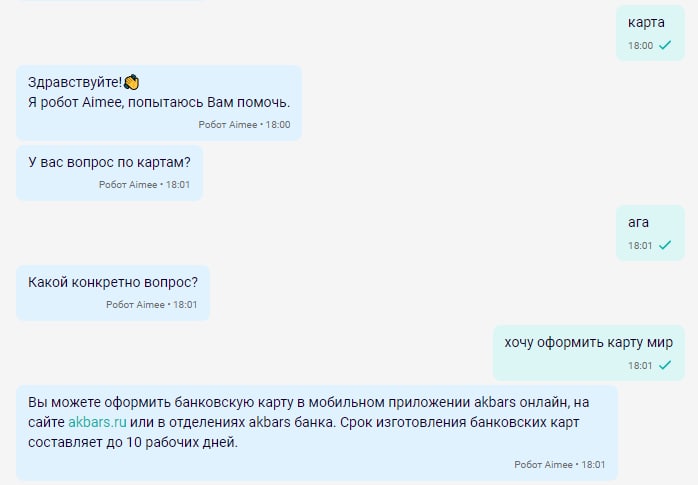
Однако обучившись на таких сообщениях, бот начал определять простые фразы, типа «вопрос по кредиту (ипотеке, вкладу, карте)», тоже как потенциальных клиентов. Поэтому мы научили бота уточнять вопросы в сомнительных ситуациях, например:
О чём спрашивают клиенты
Параллельно мы запустили этот классификатор в чат и сравнили статистику обращений. Оказалось, что основные темы вопросов в голосовом и текстовом чате отличаются. Например, голосом чаще спрашивают про установку пин-кода, курсы валют, баланс карты и режим работы офисов:

А в чате много вопросов о проведении платежей и о работе приложения Ак Барс Онлайн:

При этом одинаково часто спрашивают про карты в целом, например, про перевыпуск. А также про зачисление субсидий и оформление потребительского кредита.
Проблемы в режиме чата
Самой неожиданной проблемой оказалось то, что в режиме текстового чата бот дает результаты хуже, чем при распознавании голоса. Пользователи пишут длинные сообщения, иногда в них бывает сразу несколько вопросов, поэтому классификатор пропускает некоторые вопросы или срабатывает ложно.
Мы предположили, что длинные сообщения появляются из-за того, что пользователи не понимают, что общаются с роботом. Мы решили добавить в приветствии фразу об этом, но было опасение, что многие клиенты будут просить перевести их на диалог с оператором.
Чтобы проверить, так ли это, мы запустили тест на неделю, сняли статистику и выяснили, что всего 3% пользователей попросили перевести их на оператора после приветствия бота. Таким образом, нам удалось увеличить охват, т.е. бот стал чаще понимать намерение клиента, и это привело к повышению процента автоматизации.
Еще одна проблема, которая выявилась в чате. Когда клиенты отвечают отказом на предложение банка оформить кредит, наоборот, часто срабатывало умение по оформлению потребительского кредита:
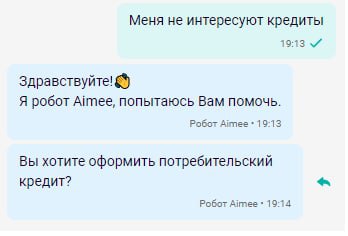
Из примера видно что клиент обозначил свою позицию по кредиту, а бот его переспрашивает о намерении оформить. Поэтому мы решили добавить класс, который «ловит» отказы.
Почему диалог переходит на оператора
На данный момент процент диалогов без переводов на оператора доходит до 18% (в среднем за неделю 16%) в чате и 31% (в среднем за неделю 23%) на голосе. Мы посмотрели, в каких случаях диалог часто переходит на оператора (кроме тех 3% случаев, когда клиент просит перевести на оператора в самом начале разговора). Вот несколько примеров:
Многие темы, определяемые ботом, еще не роботизированы.
Бот рассказывает клиенту, как совершить операцию в приложении, а эти функции приложения иногда могут не работать.
Клиенты не хотят следовать инструкциям бота, а хотят совершить операцию прямо в чате.
Некоторые темы не могут быть роботизированы (по соображениям безопасности или архитектуры), и только оператор может решить вопрос.
Бот не умеет распознавать скриншоты с ошибками от пользователя и переводит на оператора.
Пользователи просят перевести на оператора, если тема определилась неверно.
К тому же, наш бот не досаждает клиенту просьбами перефразировать вопрос, тем самым стараясь оградить его от оператора, а сразу переводит на него при возникновении недопониманий.
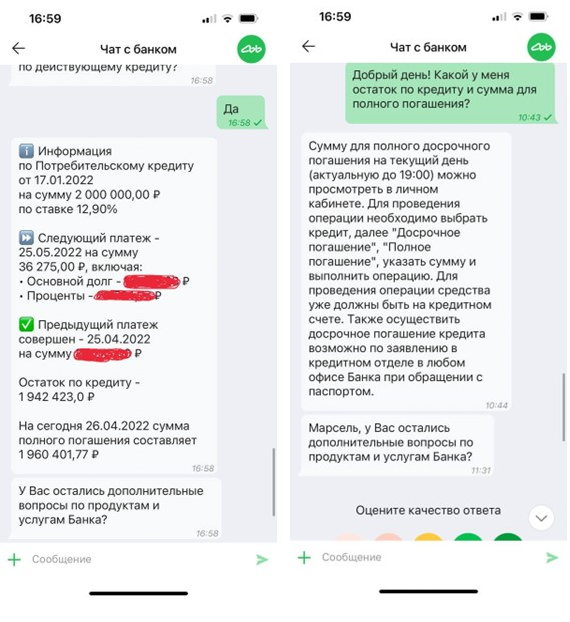
Наша цель — минимизировать такие ответы клиентам и стараться роботизировать процессы на стороне бота. Таким образом, степень доверия пользователей к боту должна повыситься. Для этого достаточно сравнить два примера, как отвечают бот и оператор на одинаковый вопрос про действующий кредит (слева ответ бота, справа ответ оператора):
Как мы собираем статистику
Статистика позволяет бизнесу отслеживать популярные запросы пользователей, быть в курсе проблем, с которыми сталкиваются клиенты банка.
Мы используем BI-инструмент Qlik Sense, куда подключаем таблицы из MongoDB, где, в свою очередь, сохраняются диалоги бота с пользователями, идентификаторы тем и подтем, которые определил бот, score ответа, флаг перевода на оператора и т.д.
Мы видим статистику запросов тем/подтем в разрезе каналов (чат или голос), количество диалогов, сколько из них были переведены на оператора и по какой причине. Из этих цифр вычисляем, сколько диалогов было обработано ботом, и выводим долю автоматизации.
У нас также есть возможность следить за точностью классификатора в чате, поскольку у операторов есть инструмент правки темы/подтемы, которую определил бот.
Далее, мы оцениваем, насколько повлияла наша новая фича (новые скиллы или решения на основе пользовательского исследования и пр.) на процент автоматизации. Также мы отслеживаем момент устаревания модели, если точность классификации упала.
Что еще нужно сделать
Для повышения степени автоматизации планируется расширить список навыков бота. На данный момент в чате роботизировано 33 умения, но и этого недостаточно. Это примерно треть всех существующих тем. Также добавить виджеты в виде кнопок. Текст кнопок будет всегда классифицироваться правильно.
В следующих статьях расскажем о новых результатах. А пока напишите — что вас больше всего раздражает в чат-ботах?



