
В первой части рассказа по мотивам выступления Дмитрия Стогова из Zend Technologies на HighLoad++ мы разбирались во внутреннем устройстве PHP. Детально и из первых уст узнали, какие изменениях в базовых структурах данных позволили ускорить PHP 7 более чем в два раза. На этом можно было бы и остановиться, но уже в версии 7.1 разработчики пошли существенно дальше, так как идей по оптимизации у них было еще много.
Накопленный опыт работы над JIT до семёрки теперь можно интерпретировать, смотря на результаты в 7.0 без JIT и на результаты HHVM с JIT. В PHP 7.1 было решено c JIT не работать, а опять обратиться к интерпретатору. Если раньше оптимизации касались интрепретатора, то в этой статье посмотрим на оптимизацию байт-кода, с использованием вывода типов, который реализовали для нашего JIT.
Под катом Дмитрий Стогов покажет, как это все работает, на простом примере.
Ниже байт-код, в который компилирует функцию стандартный компилятор PHP. Он однопроходный — быстрый и тупой, но способный сделать свою работу на каждом HTTP-запросе заново (если не подключен OPcache).

С приходом OPcache мы стали его оптимизировать. Некоторые методы оптимизации уже давно встроены в OPcache, например, методы щелевой оптимизации — когда мы смотрим на код как бы через глазок, ищем знакомые паттерны, и заменяем их с помощью эвристик. Эти методы продолжают использоваться и в 7.0. Например, у нас есть две операции: сложение и присваивание.

Они могут быть объединены в одну операцию compound assignment, которая выполняет сложение непосредственно над результатом:

Он может быть не скалярным значением и должен быть удален. Для этого используется следующая за ним инструкция

В конце — два оператора
В цикле осталось всего четыре инструкции. Кажется, что дальше нечего оптимизировать, но не для нас.
Посмотрите на код
Но человек, просто посмотрев на код PHP, увидит что переменная

Для этого нужно вывести типы, а чтобы ввести типы надо сначала построить формальное представление потоков данных, понятное компьютеру. Но начнем мы с построения Control Flow Graph — графа зависимости по управлению. Первоначально мы разбиваем код на basic-блоки — набор инструкций с одним входом и одним выходом. Поэтому мы режем код в тех местах, на которых происходит переход, то есть метки L0, L1. Мы также режем его после операторов условного и безусловного перехода, и потом соединяем дугами, которые показывают зависимости по управлению.

Так у нас получился CFG.
Ну а теперь нам нужна зависимость по данным. Для этого мы используем Static Single Assignment Form — популярное представление в мире оптимизирующих компиляторов. Оно подразумевает, что значение каждой переменной может быть присвоено только один раз.

Для каждой переменной мы добавляем индекс, или номер реинкарнации. В каждом месте, где происходит присваивание мы ставим новый индекс, а там, где мы их используем — пока знаки вопроса, потому что не везде он пока известен. Например, в инструкции
Для решения этой проблемы SSA вводит псевдо-функцию Phi, которая по необходимости вставляется в начало basic->block-а, берет всевозможные индексы одной переменной, пришедшие в basic-block из разных мест, и создает новую реинкарнацию переменной. Именно такие переменные потом и используются для устранения неоднозначности.

Заменив таким образом все знаки вопроса мы и построим SSA.
Теперь выводим типы — как будто пытаемся выполнить этот код непосредственно по управлению.

В первом блоке идет присваивание переменным значений констант — нулей, и мы точно знаем, что эти переменные будут типа long. Дальше — функция Phi. На вход приходит long, а значения других переменных, пришедших по другим веткам, мы пока не знаем.

Считаем, что на выходе phi() у нас будет long.

Распространяем дальше. Приходим к конкретным функциям, например,

Эти значения опять попадают в функцию Phi, происходит объединение множеств возможных типов пришедших по разным веткам. Ну и так далее продолжаем распространение, пока не придем к fixed point и все не устаканится.

Мы получили возможное множество значений типов в каждой точке программы. Это уже хорошо. Компьютер уже знает что
В инструкции
Производится этот вывод диапазонов похожим, но чуть более сложным образом. В результате получаем фиксированный диапазон переменных

Скомбинировав эти два результата, мы можем точно сказать, что double переменная

Все что мы получили это еще не оптимизация, это информация для оптимизации! Рассмотрим инструкцию

Для операций пре-инкремент мы точно знаем, что операнд всегда long, и что переполнения произойти не может. Используем высокоспециализированный обработчик для этой инструкции, который будет выполнять только необходимые действия без всяких проверок.

Теперь сравнение переменной в конце цикла. Мы знаем, что значение переменной будет только long — можно сразу проверить это значение, сравнив его с сотней. Если раньше мы записывали результат проверки во временную переменную, а потом еще раз проверяли временную переменную на значение true/false, теперь это можно сделать с помощью одной инструкции, то есть упростить.

Результат байт-кода по сравнению с оригиналом.

В цикле осталось всего 3 инструкции, и две из них высокоспециализированные. В результате код справа работает в 3 раза быстрее, оригинала.
Любой обработчик обхода в PHP — это просто С-функция. Слева стандартный обработчик, а наверху справа — высокоспециализированный. Левый проверяет: тип операнда, не произошел ли overflow, не произошел ли exception. Правый просто добавляет единицу и всё. Он транслируется в 4 машинные инструкции. Если бы мы пошли дальше и делали JIT, то нам бы была нужна только однократная инструкция

Мы продолжаем повышать скорость PHP ветки 7 без JIT. PHP 7.1 опять будет на 60% быстрее на характерных синтетических тестах, но на реальных приложениях выигрыша это практически не дает — всего 1-2% на WordPress. Это не особо интересно. С августа 2016, когда ветка 7.1 была заморожена для существенных изменений, мы снова начали трудиться над JIT для PHP 7.2 или скорее PHP 8.
В новой попытке мы используем для генерации кода DynAsm, который разработан Майком Полом для LuaJIT-2. Он хорош тем, что генерирует код очень быстро: то, что в версии JIT на LLVM компилировалось минуты, сейчас происходит за 0,1-0,2 с. Уже сегодня ускорение на bench.php на JIT в 75 раз быстрее чем PHP 5.
На реальных приложениях ускорения нет, и это для нас следующий вызов. Отчасти, мы получили оптимальный код, но скомпилировав слишком много PHP скриптов, засорили кэш процессора, так что быстрее работать он не стал. Да и не скорость кода была узким местом в реальных приложениях…
Возможно, DynAsm можно применять для компиляции только определенных функций, которые будут выбираться либо программистом, либо эвристиками, основанными на счетчиках — сколько раз функция была вызвана, сколько раз в ней повторяются циклы и т.д.
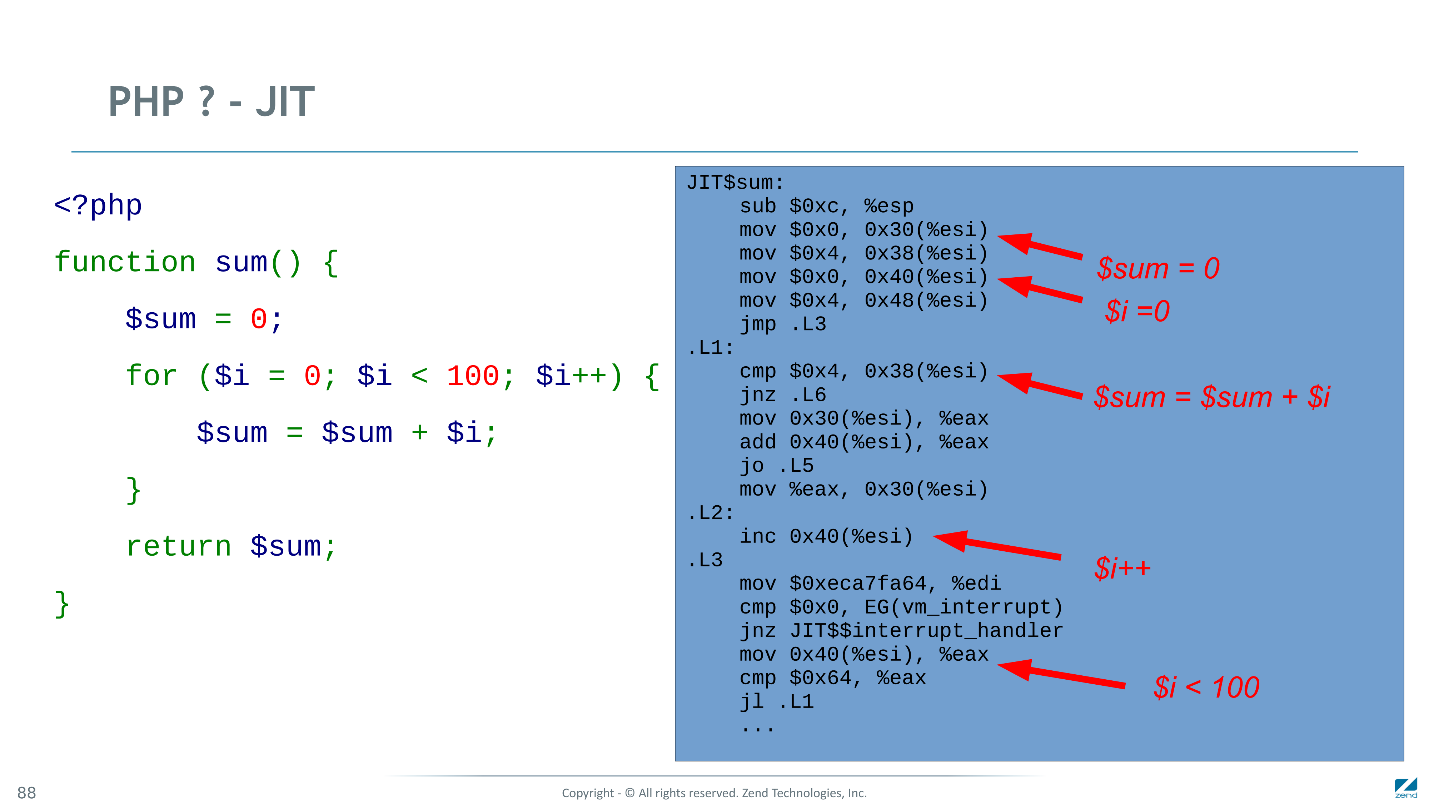
Ниже машинный код, который генерирует наш JIT все для того же примера. Многие инструкции скомпилированы оптимально: инкремент — в одну инструкцию CPU, инициализация переменной константам — в две. Там, где типы не вывелись, приходится возиться чуть больше.
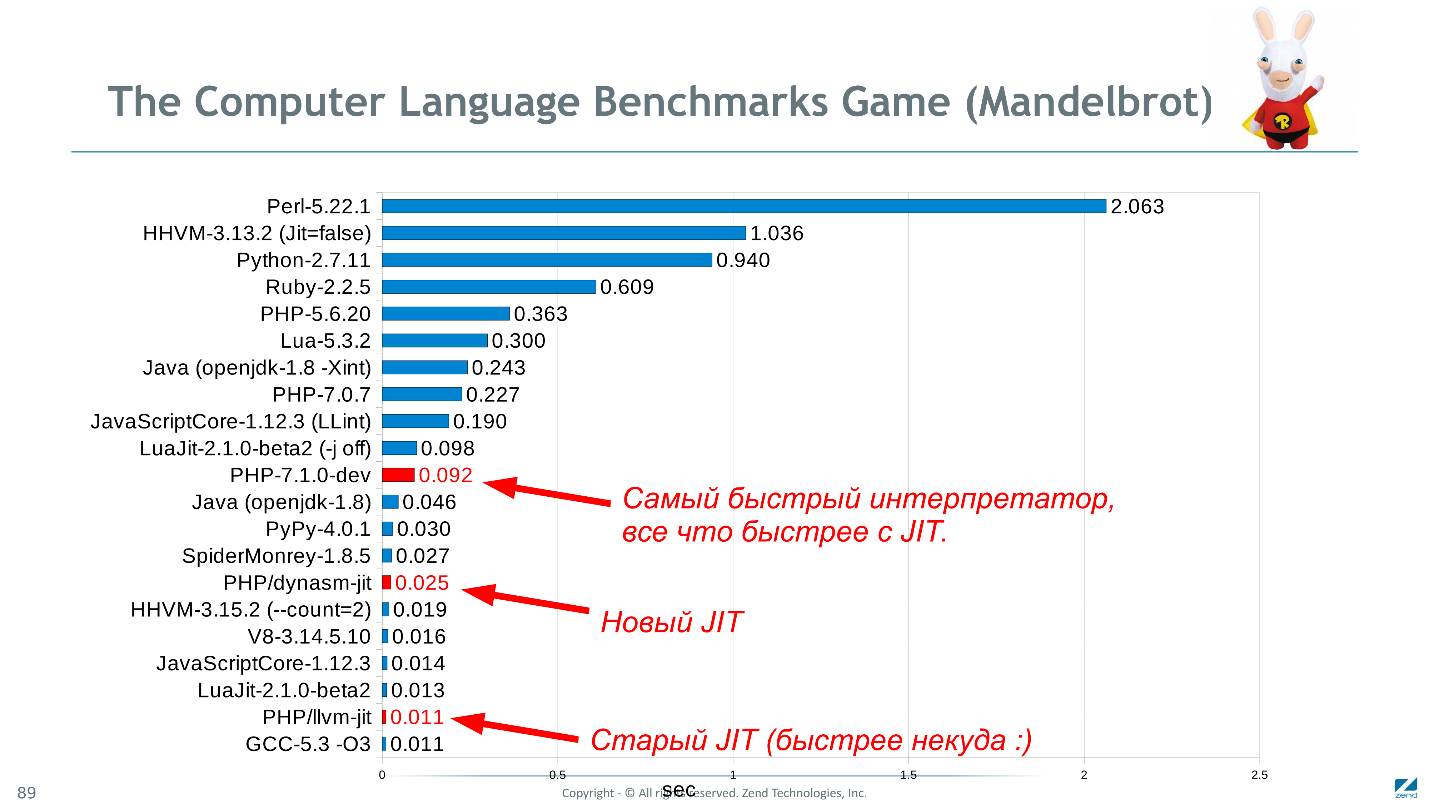
Возвращаясь к заглавной картинке, PHP в сравнении с подобными языками в тесте Mandelbrot показывает очень даже неплохие результаты (правда, данные актуальны на конец 2016 года).
Возможно Mandelbrot — не лучший тест. Он вычислительный, но зато простой и реализован на всех языках одинаково. Неплохо было бы узнать, с какой скоростью заработал бы Wordpress на С++, но вряд ли найдется чудак готовый переписать его просто чтобы проверить, да еще повторить все извраты PHP-ного кода. Если есть идеи по более адекватному набору бенчмарков — предлагайте.
Накопленный опыт работы над JIT до семёрки теперь можно интерпретировать, смотря на результаты в 7.0 без JIT и на результаты HHVM с JIT. В PHP 7.1 было решено c JIT не работать, а опять обратиться к интерпретатору. Если раньше оптимизации касались интрепретатора, то в этой статье посмотрим на оптимизацию байт-кода, с использованием вывода типов, который реализовали для нашего JIT.
Под катом Дмитрий Стогов покажет, как это все работает, на простом примере.
Оптимизация байт-кода
Ниже байт-код, в который компилирует функцию стандартный компилятор PHP. Он однопроходный — быстрый и тупой, но способный сделать свою работу на каждом HTTP-запросе заново (если не подключен OPcache).
Оптимизации OPcache
С приходом OPcache мы стали его оптимизировать. Некоторые методы оптимизации уже давно встроены в OPcache, например, методы щелевой оптимизации — когда мы смотрим на код как бы через глазок, ищем знакомые паттерны, и заменяем их с помощью эвристик. Эти методы продолжают использоваться и в 7.0. Например, у нас есть две операции: сложение и присваивание.
Они могут быть объединены в одну операцию compound assignment, которая выполняет сложение непосредственно над результатом:
ASSIGN_ADD $sum, $i. Другой пример пост-инкремент переменной, которая теоретически может вернуть какой-то результат. Он может быть не скалярным значением и должен быть удален. Для этого используется следующая за ним инструкция
FREE. Но если его изменить на пре-инкремент, то инструкции FREE не потребуется.В конце — два оператора
RETURN: первый — прямое отражение оператора RETURN в исходном тексте, а второй добавился тупым компилятором по закрывающей скобке. Этот код никогда не будет достигнут и его можно удалить. В цикле осталось всего четыре инструкции. Кажется, что дальше нечего оптимизировать, но не для нас.
Посмотрите на код
$i++ и соответствующую ей инструкцию — пре-инкремент PRE_INC. Каждый раз, когда она выполняется:- нужно проверить, какой тип переменной пришел;
is_longли это;- выполнить инкремент;
- проверить, не произошло ли переполнение;
- перейти на следующий;
- возможно, проверить исключение.
Но человек, просто посмотрев на код PHP, увидит что переменная
$i лежит в диапазоне от 0 до 100, и никакого переполнения быть не может, проверок типов не нужно, и никаких исключений тоже быть не может. В PHP 7.1 мы попытались научить компилятор понимать это.Оптимизация Control Flow Graph
Для этого нужно вывести типы, а чтобы ввести типы надо сначала построить формальное представление потоков данных, понятное компьютеру. Но начнем мы с построения Control Flow Graph — графа зависимости по управлению. Первоначально мы разбиваем код на basic-блоки — набор инструкций с одним входом и одним выходом. Поэтому мы режем код в тех местах, на которых происходит переход, то есть метки L0, L1. Мы также режем его после операторов условного и безусловного перехода, и потом соединяем дугами, которые показывают зависимости по управлению.
Так у нас получился CFG.
Оптимизация Static Single Assignment Form
Ну а теперь нам нужна зависимость по данным. Для этого мы используем Static Single Assignment Form — популярное представление в мире оптимизирующих компиляторов. Оно подразумевает, что значение каждой переменной может быть присвоено только один раз.
Для каждой переменной мы добавляем индекс, или номер реинкарнации. В каждом месте, где происходит присваивание мы ставим новый индекс, а там, где мы их используем — пока знаки вопроса, потому что не везде он пока известен. Например, в инструкции
IS_SMALLER $i может прийти как из блока L0 с номером 4, так и из первого блока с номером 2. Для решения этой проблемы SSA вводит псевдо-функцию Phi, которая по необходимости вставляется в начало basic->block-а, берет всевозможные индексы одной переменной, пришедшие в basic-block из разных мест, и создает новую реинкарнацию переменной. Именно такие переменные потом и используются для устранения неоднозначности.
Заменив таким образом все знаки вопроса мы и построим SSA.
Оптимизация по типам
Теперь выводим типы — как будто пытаемся выполнить этот код непосредственно по управлению.
В первом блоке идет присваивание переменным значений констант — нулей, и мы точно знаем, что эти переменные будут типа long. Дальше — функция Phi. На вход приходит long, а значения других переменных, пришедших по другим веткам, мы пока не знаем.
Считаем, что на выходе phi() у нас будет long.
Распространяем дальше. Приходим к конкретным функциям, например,
ASSIGN_ADD и PRE_INC. Складываем два long. В результате может получиться либо long, либо double, если произойдет переполнение.Эти значения опять попадают в функцию Phi, происходит объединение множеств возможных типов пришедших по разным веткам. Ну и так далее продолжаем распространение, пока не придем к fixed point и все не устаканится.
Мы получили возможное множество значений типов в каждой точке программы. Это уже хорошо. Компьютер уже знает что
$i может быть только long или double, и может исключить часть ненужных проверок. Но мы-то знаем что и double $i быть не может. А как мы знаем? А мы видим условие которое ограничивает рост $i в цикле до возможного переполнения. Научим и компьютер видеть это.Оптимизация Range Propagation
В инструкции
PRE_INC мы так и не узнали, что i может быть только целым — стоит long или double. Происходит это потому, что мы не пытались вывести возможные диапазоны. Тогда бы мы могли ответить на вопрос, произойдет или не произойдет переполнение. Производится этот вывод диапазонов похожим, но чуть более сложным образом. В результате получаем фиксированный диапазон переменных
$i с индексами 2, 4, 6 7, и теперь можем уверенно сказать что инкремент $i не приведет к переполнению. Скомбинировав эти два результата, мы можем точно сказать, что double переменная
$i никогда стать не сможет. Все что мы получили это еще не оптимизация, это информация для оптимизации! Рассмотрим инструкцию
ASSIGN_ADD. В общем виде старое значение суммы, которое пришло к этой инструкции, могло быть, например, объектом. Тогда, после сложения, старое значение должно было быть удалено. Но в нашем случае мы точно знаем, что там long или double, то есть скалярное значение. Никакого уничтожения не требуется, мы можем заменить ASSIGN_ADD на ADD — инструкцию попроще. ADD использует переменную sum в качестве и аргумента и значения. Для операций пре-инкремент мы точно знаем, что операнд всегда long, и что переполнения произойти не может. Используем высокоспециализированный обработчик для этой инструкции, который будет выполнять только необходимые действия без всяких проверок.
Теперь сравнение переменной в конце цикла. Мы знаем, что значение переменной будет только long — можно сразу проверить это значение, сравнив его с сотней. Если раньше мы записывали результат проверки во временную переменную, а потом еще раз проверяли временную переменную на значение true/false, теперь это можно сделать с помощью одной инструкции, то есть упростить.
Результат байт-кода по сравнению с оригиналом.
В цикле осталось всего 3 инструкции, и две из них высокоспециализированные. В результате код справа работает в 3 раза быстрее, оригинала.
Высокоспециализированные обработчики
Любой обработчик обхода в PHP — это просто С-функция. Слева стандартный обработчик, а наверху справа — высокоспециализированный. Левый проверяет: тип операнда, не произошел ли overflow, не произошел ли exception. Правый просто добавляет единицу и всё. Он транслируется в 4 машинные инструкции. Если бы мы пошли дальше и делали JIT, то нам бы была нужна только однократная инструкция
incl. Что дальше?
Мы продолжаем повышать скорость PHP ветки 7 без JIT. PHP 7.1 опять будет на 60% быстрее на характерных синтетических тестах, но на реальных приложениях выигрыша это практически не дает — всего 1-2% на WordPress. Это не особо интересно. С августа 2016, когда ветка 7.1 была заморожена для существенных изменений, мы снова начали трудиться над JIT для PHP 7.2 или скорее PHP 8.
В новой попытке мы используем для генерации кода DynAsm, который разработан Майком Полом для LuaJIT-2. Он хорош тем, что генерирует код очень быстро: то, что в версии JIT на LLVM компилировалось минуты, сейчас происходит за 0,1-0,2 с. Уже сегодня ускорение на bench.php на JIT в 75 раз быстрее чем PHP 5.
На реальных приложениях ускорения нет, и это для нас следующий вызов. Отчасти, мы получили оптимальный код, но скомпилировав слишком много PHP скриптов, засорили кэш процессора, так что быстрее работать он не стал. Да и не скорость кода была узким местом в реальных приложениях…
Возможно, DynAsm можно применять для компиляции только определенных функций, которые будут выбираться либо программистом, либо эвристиками, основанными на счетчиках — сколько раз функция была вызвана, сколько раз в ней повторяются циклы и т.д.
Ниже машинный код, который генерирует наш JIT все для того же примера. Многие инструкции скомпилированы оптимально: инкремент — в одну инструкцию CPU, инициализация переменной константам — в две. Там, где типы не вывелись, приходится возиться чуть больше.
Возвращаясь к заглавной картинке, PHP в сравнении с подобными языками в тесте Mandelbrot показывает очень даже неплохие результаты (правда, данные актуальны на конец 2016 года).
Возможно Mandelbrot — не лучший тест. Он вычислительный, но зато простой и реализован на всех языках одинаково. Неплохо было бы узнать, с какой скоростью заработал бы Wordpress на С++, но вряд ли найдется чудак готовый переписать его просто чтобы проверить, да еще повторить все извраты PHP-ного кода. Если есть идеи по более адекватному набору бенчмарков — предлагайте.
Встретимся на PHP Russia 17 мая, обсудим перспективы и развитие экосистемы и опыт использования PHP для действительно сложных и крутых проектов. Уже с нами:
- Никита Попов, один из самых видных разработчиков ядра PHP, расскажет что нас ждет, в грядущем релизе PHP 7.4.
- Дмитрий Стогов расскажет про грандиозные планы в PHP 8.
- Антон Титов, автор сервера приложений RoadRunner, выступит с темой «Разработка гибридных PHP/Go приложений используя RoadRunner».
Конечно, это далеко не все. Да и Call for Papers еще на закрыт, до 1 апреля ждём заявки от тех, кто умеет применять современные подходы и лучшие практики, чтобы реализовать классные сервисы на PHP. Не бойтесь конкуренции с именитыми спикерами — мы ищем опыт использования того, что они делают, в реальных проектах и поможем показать пользу ваших кейсов.



