Привет, меня зовут Кирилл и я инженер, который превозмогал ковидные времена вместе с компанией JUG Ru Group. Мы делаем технические конференции, и в пандемию сделали собственный сайт для проведения онлайн-конференций. Тогда нам понадобились качественные видеозвонки на WebRTC, чтобы подключать через браузер спикеров из любой точки планеты.
Варианты «просто застримить Zoom или захватить Jitsi» нам не подошли. Стало ясно, что нужно делать своё решение, пусть и на основе чужого SDK. В результате перебрали разные варианты, накопили опыт. А ещё из-за вопросов вроде этого создали целую конференцию VideoTech, чтобы послушать других знающих людей.
И теперь хочу поделиться нашим опытом с Хабром, поговорив про WebRTC в целом и про конкретные реализации: P2P, Voximplant SDK, SDK VK Звонков.
Оглавление
Предыстория
P2P
VoxImplant SDK
SDK VK Звонков
Вместо заключения
Предыстория
Мы с 2013-го проводим конференции для программистов и сочувствующих. Но пока они проходили в офлайне, сами мы были не IT-компанией, а ивент-компанией (с отделом разработки).
Поскольку мы хотим делать лучшие конференции в мире, инвестировали в людей и оборудование, закрывая каждый год в ноль. Нам нравится делать конференции всё лучше, и на результаты можно посмотреть на наших YouTube-каналах [6] — увидеть, куда идут деньги, потраченные на камеры, свет, команды. Но в то же время были понятные психологические и финансовые барьеры делать что-то совершенно новое. Всё новое делалось очень аккуратно, взвешенно — вследствие чего медленно. И тут пришёл COVID-19.
— Кто является двигателем цифровой трансформации в вашей компании – CEO, CIO, CTO?
— COVID-19.
Мы быстро поняли, что если резко не поменяемся, то деньги в лавке скоро закончатся. И тут случился переход в онлайн. Нам очень повезло, что делали это не с нуля: наши не очень приоритетные задачи по развитию отдела разработки, внутренним системами и прочим активностям резко стали самыми важными.
Уже понятно, где тут видео и к чему я веду. Мы тогда сформулировали требования к платформе для проведения конференций, проанализировали существующие решения и не нашли ничего, что бы нас устроило. Пришлось делать свою.
Пайплайн видео в вакууме
Давайте попробуем представить видеотракт и понять, о чём мы уже говорили на Хабре, а о чём поговорим сегодня. Упрощенно он выглядит так:
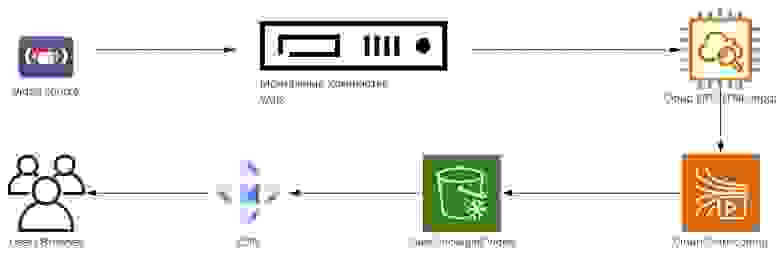
Мы получаем откуда-то сигнал (из нашей собственной студии или удалённый), затем монтируем у нас в пультовой, отправляем в облако, там транскодируем и в итоге доставляем до пользователя через наш сайт.
Ранее уже писали на Хабре о разных этапах этого пути:
Разработать видеоплатформу за 90 дней
Съемочная площадка в офисе — практичный способ не налажать с трансляцией
Пультовая всевластия
Что сделать, чтобы ваша онлайн-трансляция не развалилась
Сосредоточимся сейчас на первом этапе: источниках видео, из которых у нас составляется конечная картинка эфира в монтажном софте vMix.
")
Мы используем в основном следующие источники видео:
Видео участников/спикеров из WebRTC-звонка
NDI
Видео с платы захвата
Видео с камеры из студии (SDI + PCI плата для принятия сигнала)
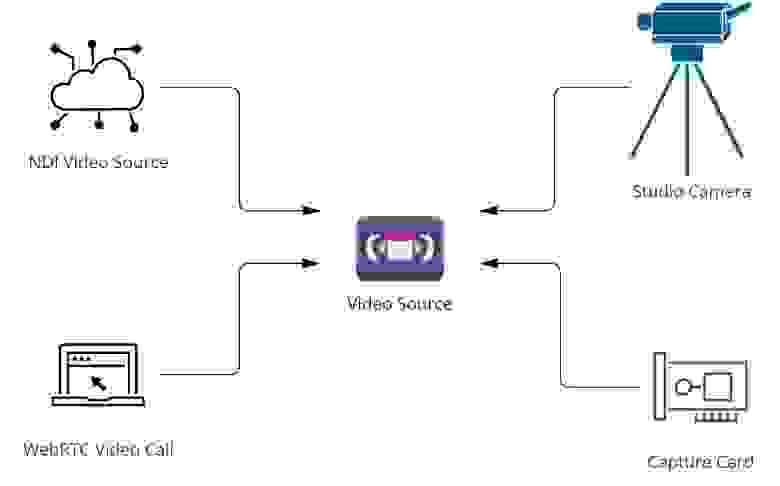
Сегодня поговорим про WebRTC-часть: про всё остальное частично уже рассказывали, а вот история наших изысканий при выводе участников видеозвонков в эфир интересная. Особенно с учётом того, что эти изыскания привели к использованию полученного решения в качестве корпоративной звонилки внутри компании.
Решение назвали Speaker Room. Ну а как ещё организаторы конференций могут назвать WebRTC-звонилку?
У нас маленькая и занятая команда разработки. Поэтому хотелось сделать эксперимент минимальными усилиями и в дальнейшем тоже поддерживать его как можно меньшими силами. Логично в этом случае использовать какой-то существующий сервис. Требование было одно — работать должно в браузере, ведь мы ой как не хотим заставлять людей что-то ставить на свои рабочие и личные ноутбуки.
И тут пандемия уже начала играть нам на руку: WebRTC как стандарт и реализация в браузерах (особенно в Chrome) стал развиваться семимильными шагами. Моё первое знакомство с этой технологией случилось давно при записи подкаста (то ли Разбор Полётов, то ли Two Dev One Ops), где захотели созвониться (только звук) и локально отписывать все дорожки, чтобы потом можно было удобно сводить и работать с ними. Если в двух словах, с тех пор с WebRTC всё стало сильно лучше: как минимум спецификация зарелизилась.
P2P
Первая идея человека, смотрящего на WebRTC: его ведь можно использовать в P2P-режиме и экономить на серверах, почему нам так не сделать? И мы стали разбираться с этим вариантом.
Проблемы начали всплывать достаточно быстро. Есть много примеров того, как сделать P2P-звонок 1-1, но сложность возникает, когда нужно жонглировать большим количеством людей в звонке. В нашем случае для докладов нужен был звонок на 4-5 человек (спикер, эксперт, ведущий, ассистент и технические пользователи).
Давайте посмотрим, что нужно молодому энтузиасту, чтобы сделать P2P-звонок:
Соединение — одна штука от каждого участника к оставшимся участникам. Это есть в браузере: RTCPeerConnection.
Познакомиться с браузерным API Media Devices для получения списка устройств, данных с этих устройств и шаринга экрана.
Реализовать так называемый сигналинг: сначала кажется, что это супер-просто, но есть и нюансы.
STUN/TURN-сервера для стабильной работы. STUN нужен при установке соединений между пользователями по взаимно доступным адресам (грубо говоря, «подробнее смотри по ссылке»). TURN, в свою очередь, полностью пропускает трафик через себя, если прямое соединение установить не удалось. И если первые — это не такая уж большая проблема, то вот вторые — это постоянно функционирующая единица, требующая внимания, так как используются, если не удалось соединиться напрямую. По сути, это relay всего трафика через TURN-сервер.
Давайте кратенько пройдёмся по каждому пункту и рассмотрим интересные подводные камни.
1. RTCPeerConnection
С ним всё просто: есть спецификация, есть последовательность действий. Если всё делаем правильно, то за нас проходит процесс NAT traversal. Полезный вводный доклад про то, как устанавливается соединение и все этапы, уже сделал Антон Квятковский — называется ICE-cold connection.
Грубо говоря, нам нужно получить минимальное количество данных для установки соединения, а потом настроить его для отправки и принятия видео/аудио данных. Тут можно сделать отсылку к пункту про сигналинг, потому что именно через него этой информацией мы и обмениваемся. А вот выбрать из двух вариантов — подготовить всю информацию и организовать соединение, или установить минимально возможное, а потом настраивать его добавляя детали — уже ваша задача. Процесс установки соединения описан на MDN.
Напишу со стороны PeerConnection выжимку того, что будет необходимо сделать:
Caller transition:
new RTCPeerConnection(): "stable"setLocalDescription(offer): "have-local-offer"setRemoteDescription(answer): "stable"
Callee transition:
new RTCPeerConnection(): "stable"setRemoteDescription(offer): "have-remote-offer"setLocalDescription(answer): "stable"
То есть два человека должны обменяться предложениями и ответами на них.
В реальности нужно следить за последовательностью этого процесса, так как если вы меняете отправляемые Media (например, сменили камеру), то необходимо сгенерировать новое предложение (SDP) и отправить его. Но если в данный момент получатель занимается обработкой старого или чем то ещё — будет неприятная ошибка, фатальность которой будет зависеть от браузера и версии.
Разбираясь с этим API, мы нарисовали примерно такую схему:
Под спойлером, а то она крупная
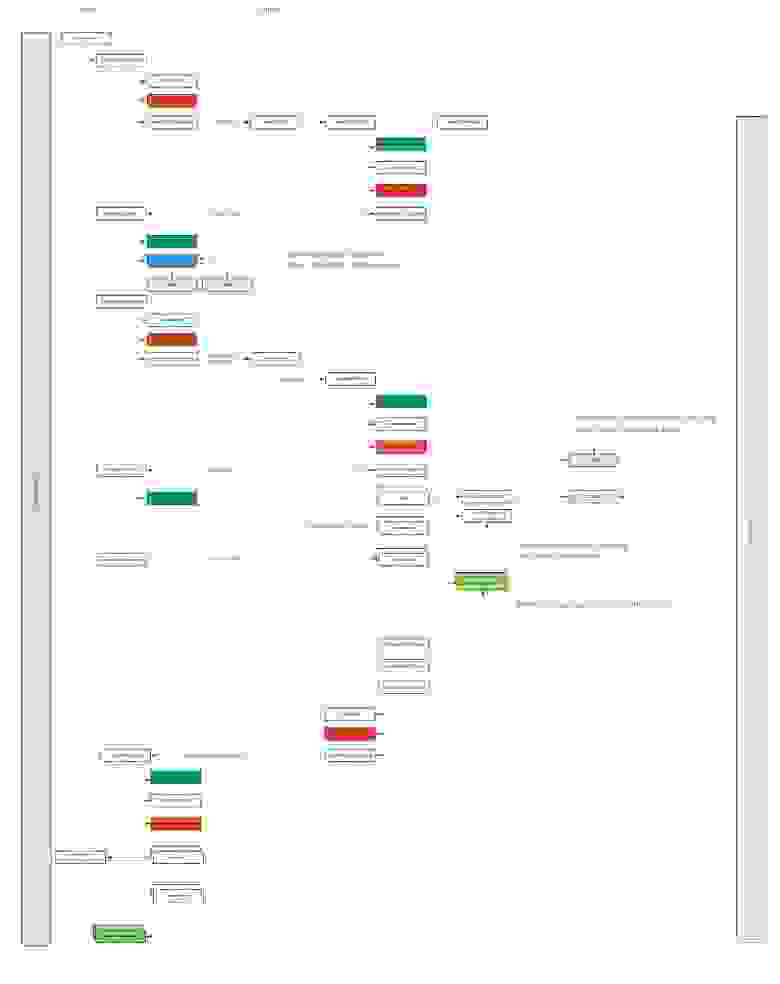
Она не претендует на полную истинность, но возможно, поможет вам разобраться с концептуальными вещами в привязке к терминологии, которая есть в API WebRTC браузеров.
2. Media Devices API
С девайсами тоже на первый взгляд всё несложно:
Выбрали нужный
Получили его MediaStream
Видео отправили в PeerConnection. С аудио сделали тоже самое. Конечно, не всё так просто: см. выше про то, что нужно заново отправить SDP с новой информацией о Media в видеосессии.
Основной нюанс выбора девайсов заключается в следующих вещах:
Эксклюзивность доступа к устройству на некоторых устройствах (например, на Windows у камеры по умолчанию доступ эксклюзивен). Необходимо обрабатывать ошибки доступа и его получения. В том числе для шаринга экрана.
Результат может вас удивить с точки зрения функциональных требований к получаемому Media. Например, вы хотите видео конкретного качества и запрашиваете его с камеры — тут вам помогут Media Constraints.
Но результат может быть не таким, как вы просили. Например, запрашиваем такое видео:getUserMedia({ audio: true, video: { width: { ideal: 1280 }, height: { ideal: 720 } } })
Не раз получалось так, что видео забиралось с камеры меньше, чем по факту. Конечно, всё зависит от качества камеры, но различные дешёвые камеры могут отдавать референсный FullHD только после того, как попробовать забрать с них видео конкретного разрешения, то есть без ideal. Я не беру в расчёт совсем жуткие устройства, которые ведут себя совсем странно, но намекаю, что получающий устройства код в идеале должен проверять полученный результат (если вы не хотите сюрпризов в видео неожиданного aspect ratio или меньшего качества видео, чем хотелось).
3. Сигналинг
Сделать сам по себе сигналинг очень просто. Но вот сделать это надёжно — другое дело. WebRTC API в браузере не помогает сделать это корректно, расставляя ловушки в местах, где вы не можете консистентно обновить текущие состояние соединения (пресловутые renegotiation-процессы). Грубо говоря, с помощью сигналинга мы обмениваемся следующей информацией:
Кандидатами для создания соединений
Информацией о Media пользователей
Дополнительной информацией для поддержания актуального состояния звонка
Райан Джесперсен уже делал заход на эту тему на нашей конференции VideoTech с докладом It's time to WHIP WebRTC into shape, где он отмечал важность некоторой референсной реализации сигналинга и стандарта. Сейчас эта инициатива имеет более чёткие очертания в виде WebRTC-HTTP ingestion protocol (WHIP). Там можно почитать о создании WebRTC сессий и обмене всей необходимой информации для этого.
Доклад Райана советую посмотреть, он интересен своими примерами и отсылками к коду, хотя мешает плохое качество связи со спикером: разумеется, по иронии судьбы именно на докладах про WebRTC звонки сыпятся :) Райан там извиняется за качество своего интернета, но положа руку на сердце, соединение через океан — это всегда некоторая непредсказуемость.
Также на русском можно почитать хорошую статью от команды VK Как это устроено: видеоконференции ВКонтакте на безлимитное число участников [14], где также хорошо систематизирован опыт реализации групповых видеозвонков.
4. STUN/TURN-сервера
С ними более прозаично. Для тестов мы использовали coturn, и особых проблем с ним не было. Можно также использовать и публичные, если уровень вашей паранойи позволяет.
Время считать
Вскоре после получения рабочего P2P-прототипа, понимания принципов работы и всей вытекающей сложности, было решено смотреть не на P2P-решения. Давайте поймём, почему.
Возьмём наше требование 4-5 (пусть будет 5) человек в звонке. В P2P-схеме, каждый должен связываться с каждым. Получается, что у каждого человека:
Четыре соединения с другими
В каждом соединении он отправляет и принимает видео + аудио конкретного участника
Выходит, если мы кодируем видео с битрейтом в 2 мегабита, и все клиенты делают так же, то входящий и исходящий трафик будет линейно масштабироваться с количеством участников, для каждого участника общий трафик получается 10 мегабит входящего и 10 исходящего трафика, и каждый клиент будет держать 4 соединения. А при этом:
Каналы у людей, как правило, не симметричные
Отправлять видео сразу 4 клиентам уже достаточно тяжело
С каналом всё понятно, отправку хочется минимизировать. Это можно сделать, ловко играясь с информацией: например, отправлять видео не всем, а только тем, кто смотрит. То же самое можно делать и с приёмом. Но вы уже должны представить количество оркестрации, которое придётся взять на себя.
А вот с отправкой видео интереснее. Операция декодирования видео проходит легче для CPU/GPU, чем кодирование. Когда мы делаем новое соединение к новому клиенту, мы кодируем с параметрами, которые передали в соответствующий трансивер. А клиенты все разные: кто-то не может закодировать или раскодировать h264 (привет, Яндекс.Браузер), для кого-то тяжело VP9 (привет, старые CPU).
Поэтому в этой схеме много нюансов — а ведь хочется, чтобы было качественно, быстро и более-менее совместимо между всеми. А качественно, быстро, совместимо да ещё и масштабируемо можно сделать с помощью SFU- или MCU-схем вместо P2P. Хорошо бы ещё добавить Simulcast и транскодирование на сервере.
В этот момент голова начинает лопаться, и ты, вооружившись новыми знаниями и вводными, начинаешь искать готовые решения и оценивать их.
Voximplant SDK: как мы провели VideoTech и что поняли
Выше я уже ссылался на доклады с нашей конференции VideoTech (немного нарушив хронологию: когда мы рассматривали вариант P2P-звонков, её ещё просто не существовало).
Мы создали эту конференцию из-за того, что нам самим такая и понадобилась. При переходе в онлайн мы много разбирались с технологиями видео и стриминга, увидели, что для других людей актуальны те же вопросы, и создали мероприятие, позволяющее обменяться опытом. В том числе и узнать больше о WebRTC-решениях.
Но сначала саму конференцию (и другие наши мероприятия того сезона) требовалось провести с помощью какого-то решения. От P2P мы уже отказались — что тогда?
После изысканий мы выбрали не погружаться в написание полностью своего решения, а найти готовый сервис для звонков — Voximplant. То есть взять не просто готовый SFU, а именно SaaS-решение, чтобы не заморачиваться с инфраструктурой.
С помощью Voximplant SDK собрали первую версию нашего Speaker Room. А на VideoTech уже опробовали его, получили фидбек и сверили часы с другими решениями (об одном из них, VK Звонках, речь ещё пойдёт ниже).
Время Voximplant SDK. Выбор и использование
Пришло время сделать что-то рабочее, боевое, решить бизнес-задачу. Вдохновившись VDO.Ninja, мы решили делать подобную схему для уже активно использовавшегося у нас vMix. Хотелки были такими:
План-минимум:
Участники должны спокойно общаться между собой с минимальной задержкой
Возможность забирать звук и видео каждого участника звонка отдельно
Иметь статичные адреса для видеопользователей в рамках конференции
План-максимум:
Управление видео пользователей: выбирать кому и чьё входящее видео включить/выключить
Выбирать качество входящего/исходящего видео участника
Тесты готовых сервисов типа Twilio не показали сильной разницы в качестве. Ценовые различия на наших объёмах тоже не оказались существенными, у нас довольно узкоспециализированный случай.
Но Voximplant зацепил своей гибкостью. Ребята сделали сервис с интересными возможностями кастомизации процесса звонка и управления им. Да ещё и хорошо документированным. И мы решили использовать это по полной для синхронизации состояния пользователей в звонке с нашим бэкендом, для управления им через админку.
Киллер-фича Voximplant для нас — это возможность писать код на стороне бэкенда медиасервера и отсылать различную информацию куда вам угодно. Например, по websocket.
Вот так в нашем случае выглядят загруженные скрипты в админке:
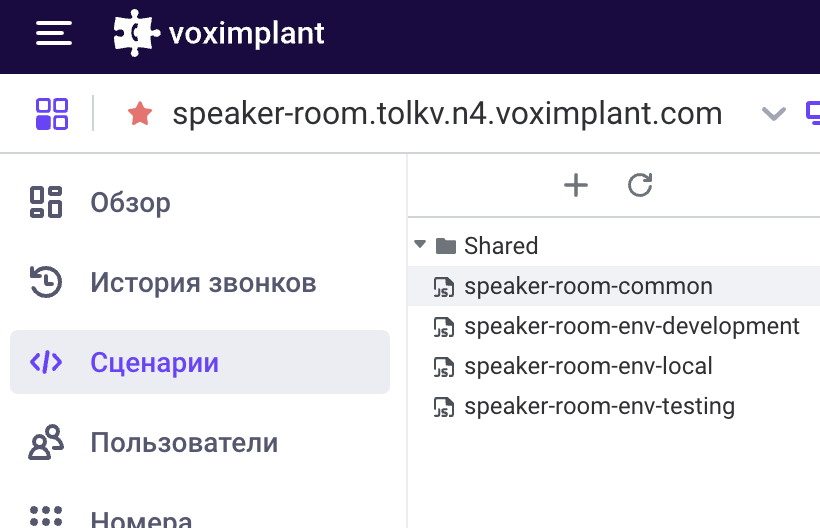
Тут загружаются кастомизации под нужную среду и основной код звонка. Этот код можно загружать даже из CI/CD через HTTP API (хоть и кривовато). Но в целом это даёт возможность писать код на чём угодно, что компилируется в итоге в JavaScript (да-да, serverless-функции VoxEngine пишутся на JS).
Далее мы получаем некоторый набор соглашений по управлению звонком. Например, так можно подключить нужные модули
require(Modules.Conference);
require(Modules.WebSocket);
require(Modules.StreamingAgent);Мы активно используем WebSocket для отправки данных к нам на сервер. В который отправляем данные по разным событиям, например, при старте звонка:
VoxEngine.addEventListener(AppEvents.CallAlerting, onCallAlerting);В остальном скрипт VoxEngine — это обычный NodeJS-код с некоторыми ограничениями (например, по количеству одновременных setTimeout). Это открывает огромные возможности по интеграции и автоматизации. А также бескрайние просторы для того, чтобы выстрелить себе в ногу, так как это всегда обратная сторона огромных возможностей. Много звонков у нас упало попросту из-за тех или иных ошибок в коде (call of … undefined). Со временем мы написали небольшой тестовый фреймворк, чтобы тестировать VoxEngine-скрипт в базовых сценариях, но хотелось бы такого из коробки.
Сейчас в случае VoxEngine ощущение идеального рецепта использования такое:
Пишем на TypeScript и компилируем в JS
Проверяем тестами, эмулирующими работу звонка
Деплоим с помощью HTTP API
Voximplant SDK — плюсы и минусы
Важно помнить, что плюсы и минусы зачастую субъективны, и будут таковыми только для конкретной системы, а в других сценариях всё может отличаться. И конкретно наш сценарий для Voximplant довольно нетипичный. Так что мы не претендуем на абсолютную объективность, а говорим только о своём опыте.
Давайте попробуем понять, что мы в итоге получили. Взглянем на схему:
")
Ключевым тут является то, что когда звонок создаётся на стороне Voximplant, устанавливается соединение с нашим сервером: один звонок — одно соединение. Через это соединение передаётся вся метаинформация по звонку, а также могут быть посланы команды Voximplant Media Server (SFU) в отношении какого-либо пользователя или целого звонка, например:
Закончить звонок принудительно для всех
Переключить качество входящего видео к участнику звонка Х
Бан участника Х
Инициировать функции стриминга на внешние ресурсы
Запускать ASR или синтез/проигрывание аудиодорожек
И так далее, что вам ещё взбредёт в голову
Нам взбрело в голову следующее (смотри требования в начале статьи):
Во-первых, забирать видео конкретного участника для специальных клиентов, которые мы заводим через webview в vMix (в котором это, кстати, работает не очень-то и здорово по сравнению с OBS, но это заслуживает отдельного исследования и статьи).
")
Затем привели в порядок и приделали изменение качества входящего видео (min/medium/max):
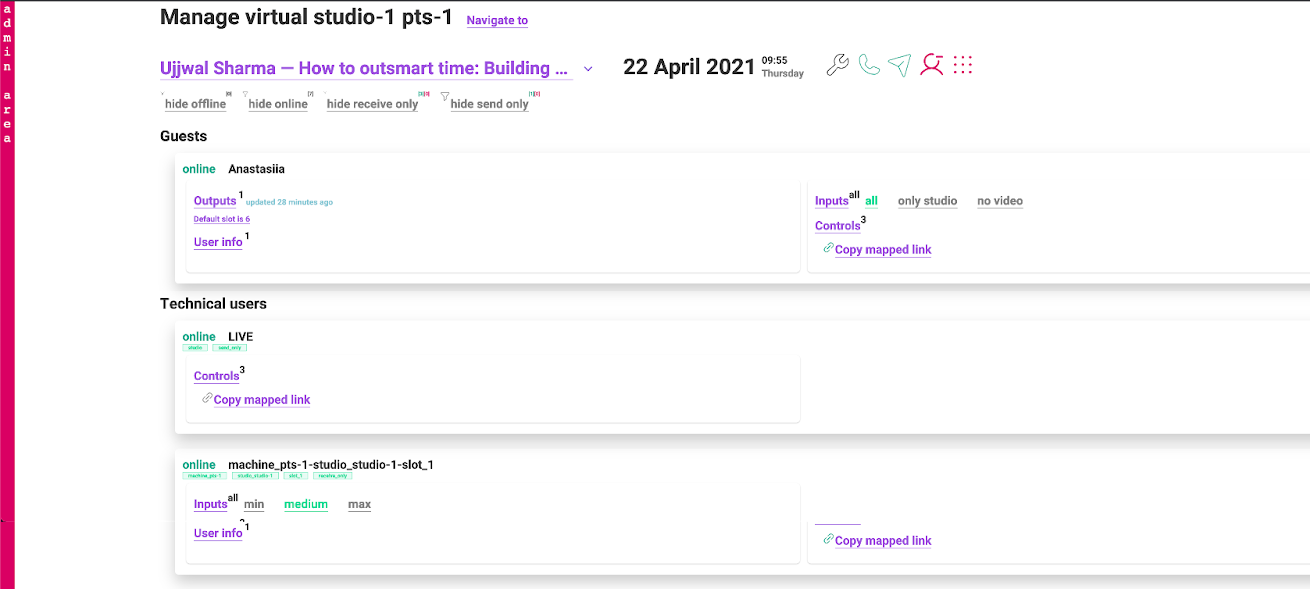
И тут вы спросите: зачем нам переключать вручную качество? В хорошем случае, конечно, не нужно, это делают эвристики, подстраивая качество автоматически. Мы снимаем WebRTC-статистику и выводим её видеоинженеру, контролирующему звонок, участники которого выходят в эфир. В ранних версиях эта информация была в том числе прямо в звонке:
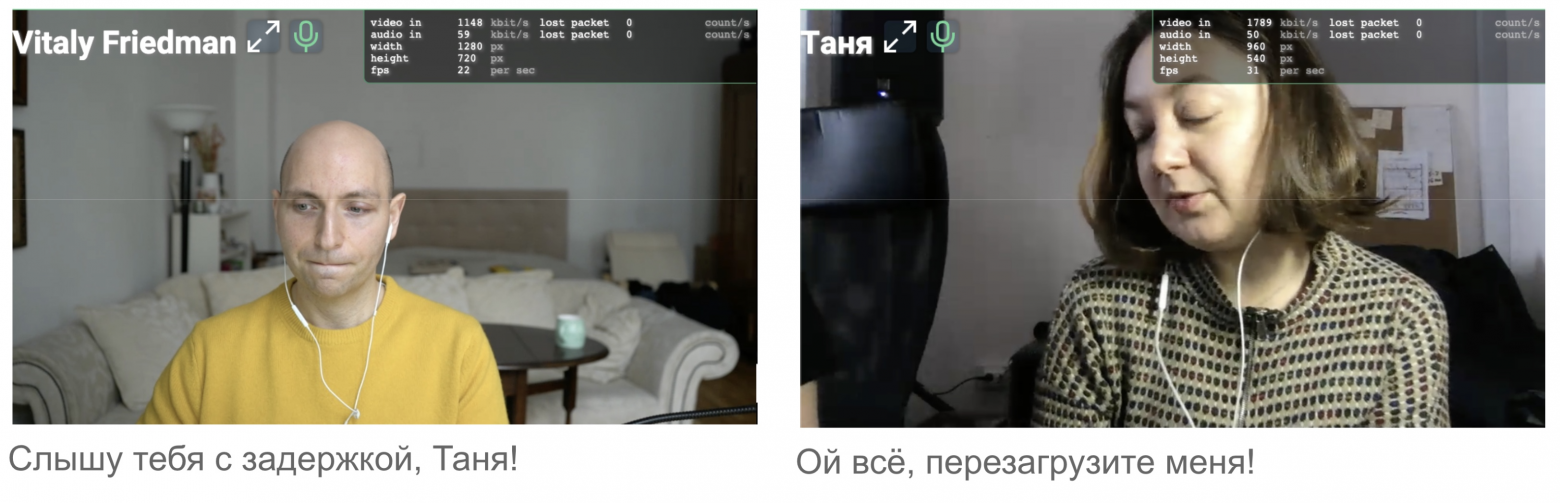
И тут мы столкнулись с основной проблемой при использовании Voximplant — плавающие и порой длительные рассинхроны звука и видео. Грубо описывая ситуацию: дело в том, что видео и аудио имеют разные битрейты, и когда начинаются потери или просто канал деградирует, видео начинает тормозить. По идее, видео должно деградировать до более низких разрешений, но порой это происходило слишком поздно и мы видели неприятные рассинхроны, которые убирались ручным переключением качества (в большинстве случаев).
Должен признать, что ребята из Voximplant неоднократно улучшали ситуацию после нашего фидбека. Улучшали эстиматор на SFU-сервере, который как раз и отвечает за качество отсылаемого видео. Также стоит отметить, что тогда для нас приоткрыли бета-версию с поддержкой simulcast, которую мы и использовали. За что спасибо @irbisadm
Современный WebRTC также считает некоторый прогноз по оставшейся доступной ширине канала клиента и отправляет в виде метрик (возможно, использует как-то ещё, но таких гарантий нет, и всё зависит от реализации). Так что фиксы Voximplant касались не только серверной части, но и SDK.
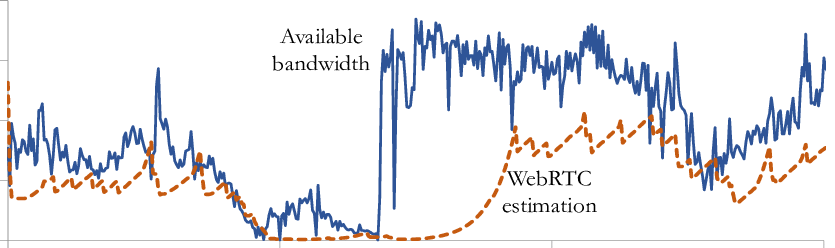
На иллюстрации — пример работы WebRTC эстиматора на примере Jitsi. Читать подробнее на researchgate [11]
В итоге мы имеем так называемый simulcast и видим в outbound-метриках людей примерно следующее:
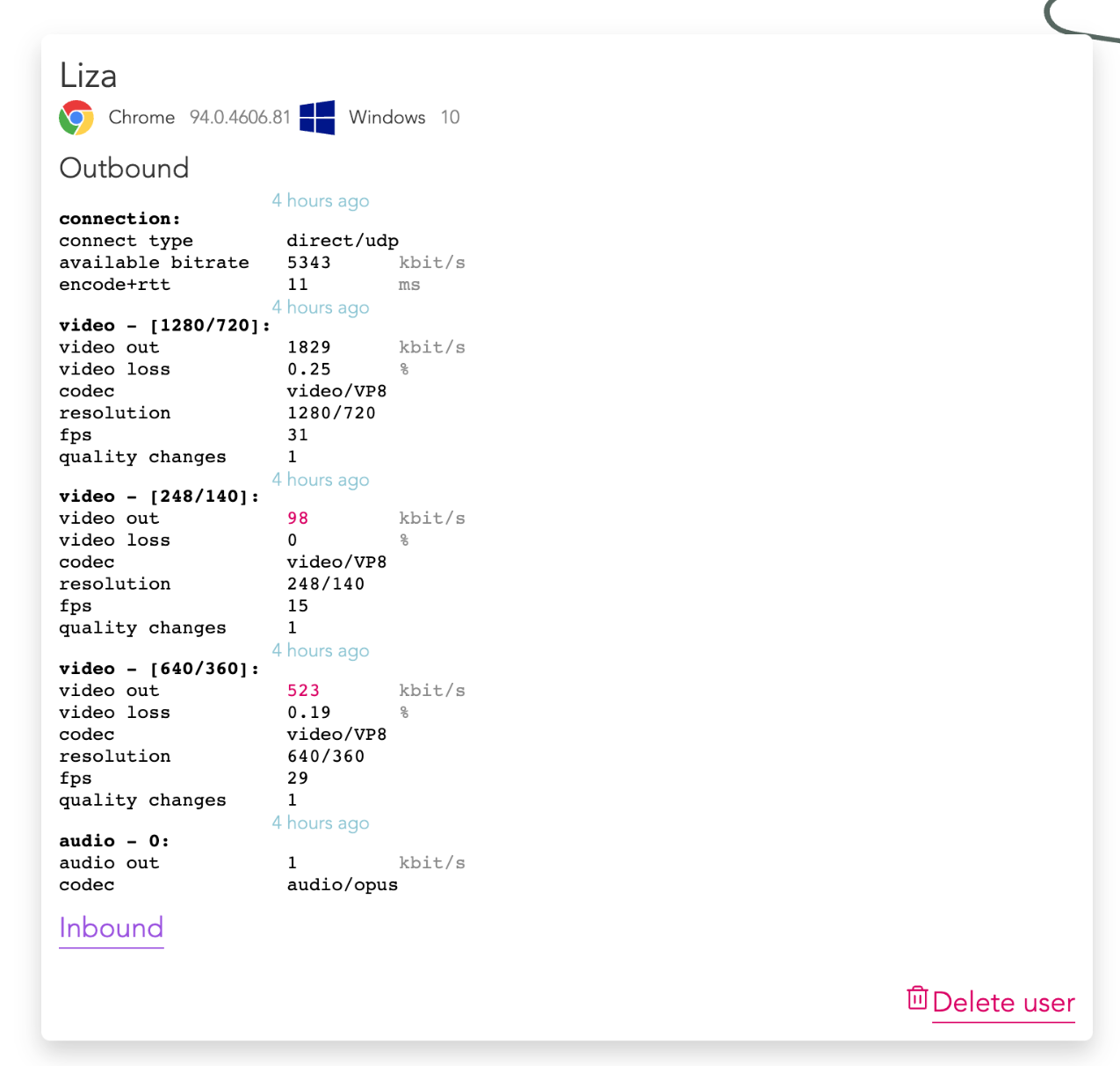
Видно, что клиент отправляет три разрешения: 720p, 360p, 140p. То есть в данном случае simulcast — это факт отправки видео в трёх разрешениях на SFU-сервер, который, в свою очередь, выбирает наиболее подходящее разрешение из предоставленных, исходя из качества канала каждого участника. Кодирование в три разрешения заставляет CPU потрудиться. Возможно, тут вы скажете: зачем кодировать всегда в три?! Действительно, если нет клиентов, которые готовы брать одно из разрешений — можно его не кодировать. Но на тот момент это ещё не было реализовано. Сейчас же это базовая функциональность, экономящая CPU клиента.
Тем не менее, ручное переключение всё ещё оставалось с нами. В том числе по причине перегрузок CPU, узнавать о которых в браузере можно только по косвенным признакам, если вы не Google Meet (например, по приращению времени забора метрик с PeerConnection - RTCPeerConnection.getStats()).
Зачем же нужен simulcast? Давайте разберём одну особенность SFU-медиасервера Voximplant: как и многие SFU-сервера, он всего лишь пересылает данные. Он не меняет видео или аудио, максимально быстро и с наименьшими затратами пересылает медиа участников звонка. Возникают компромиссы. Если у вас 1080p-камера, вероятно, вы хотите отправить максимально «хорошую картинку». Но готовы ли её принять остальные участники звонка? А что, если их много?

В этом случае у нас один участник, который хочет 720p (например, у него такой монитор), и нет никакого смысла кодировать и пересылать для него видео более высокого качества.
Но если у нас появляется второй участник звонка, который хочет уже 360p:
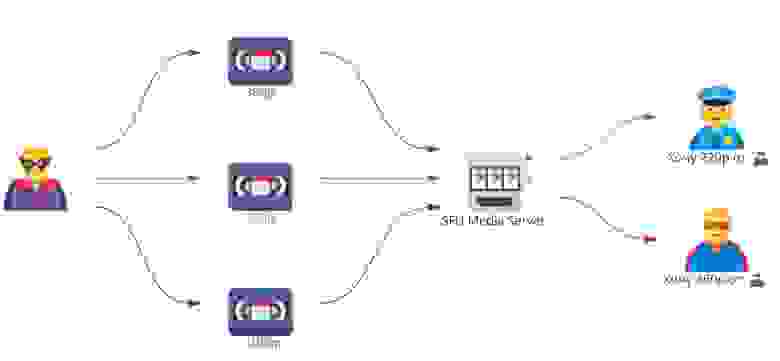
В этом случае особенность нашего SFU-сервера играет злую шутку. Нашему клиенту необходимо будет кодировать в два разрешения — 360p и 720p одновременно. Если прибавится клиент, который захочет ещё и 1080p, то нужно будет ещё и третий поток кодировать в 1080p. То есть простота и скорость нашего сервера компенсируются сложностью и дополнительной нагрузкой по кодированию видео на клиенте.
Ещё один неприятный эффект такого подхода: если кодек, которым участник кодирует видео, не совместим со списком кодеков, которые может раскодировать другой участник, то тоже возникнет проблема. SDK Voximplant в таких случаях может даже заставить клиента изменить кодек и кодировать чем-то более распространенным.
Резюме по Voximplant
Мы многое попробовали и впечатлились возможностями интеграций Voximplant. Видно, что сервис сфокусирован на различной автоматизации телефонии и организации колл-центров. Интеграционные вещи делать просто и приятно, очень редко сталкиваешься с чем-то, чего нельзя сделать. Когда мы сталкивались, команда Voximplant оперативно создавала/приоткрывала новые API в экспериментальном режиме. Наш кейс с массовым звонком и техническими участниками, которые получают видео/аудио выбранного человека из звонка, нестандартный для Voximplant. Тем не менее, за год работы с их SDK мы ощутили прогресс его развития, пройдя несколько минорных версий. Сейчас очень ждём версию 5, в которой, надеюсь, будет учтена и наша обратная связь :)
Пришло время нашей конференции VideoTech 2021, доклады на которой нам самим было интересно послушать, ведь теперь у нас были видеосервисы: доставка видео до участников на нашем сайте live.jugru.org и сервис видеосвязи Speaker Room, через который мы выводили докладчиков в эфир.
Само собой, на этой конференции выступили ребята из Voximplant с интересным докладом про WebRTC-метрики [12]. А также там были ребята из VK, которые рассказали про своё решение VK Звонки.
В нём нас очень привлекла кастомная реализации демонстрации экрана через WebRTC Data Channel. Привлекла, так как на тот момент с Voximplant мы имели типичные проблемы шаринга экрана через WebRTC: мыло, заморочки с текстом (нужны хинты, чтобы делать фокус на статичный текст при кодировании видео), деградация по качеству видео, а не по FPS (долгая подстройка), ограничения по качеству.
И тут мы подумали: а что нам мешает попробовать параллельно сразу двух провайдеров для звонков? В VK создали SDK, куда разработчики VK Звонков упаковали все свои решения для безлимитных видеоконференций из сервиса звонков ВКонтакте. С помощью этого SDK сторонние компании могут интегрировать функцию звонков в свой продукт и использовать те же технологии, которые работают в VK Звонках.
Про его использование подробно написал ниже в соответствующем разделе. Но прежде чем повести речь о совмещении двух вариантов, нужно написать о том, как мы используем SDK в нашем коде и какие там есть абстракции.
Текущие абстракции звонка и новое SDK
Мы разрабатываем Speaker Room на Next.js (считай, React). При этом часть Speaker Room — наш собственный внутренний SDK, который мы используем и в других своих проектах с видеосвязью, и нам важно, чтобы внешний SDK хорошо сочетался с нашим переиспользуемым кодом.
В ходе тестирования различных SDK для звонков в виде npm-модулей я понял, что многие из них не готовы работать с SSR-рендерингом. Даже при попытке простого импорта любого класса многие SDK просто выкидывают ошибку, так как при импорте произошла попытка обращения к глобальной переменной window. С этим одинаково нездорово как в Voximplant, так и в VK Calls SDK.
Кроме этой проблемы с SSR, ещё давал о себе знать объём: бандлы с внешними SDK «толстенькие», а страницы хочется по возможности облегчать. Поэтому мы решили разделять, и минимальный набор по работе с локальными устройствами выделили в отдельный модуль. А сами SDK (Voximplant/VK Calls) подключаются на специальных страницах, на которых нет SSR и которые просто синхронизируются с независимым от них выбором устройств.
voximplant-websdk@4.6.2-2444 | 353.8kB (minified) | 76.8kB (minified+gzipped) |
@vkontakte/calls-sdk@2.6.1 | 376.3 (minified) | 95.9 (minified+gzipped) |
Также мы с самого начала активно используем Mobx, так как приходится хранить достаточно много метаинформации по звонку и управлять ей. С Mobx лично для меня это происходит достаточно удобно и всегда можно удобно расширять уже существующие сторы, моделируя отдельные части звонка.
Теперь взглянем на компоненты и как выглядит подключение к звонку.
Оборачиваем компонент:
export const VideoConferencePage = withCallManager(VideoConferenceComponent, {
environment: environmentName,
sdk: {
voximplant: {
credentials: publicConfiguration.voxCredentials,
}
}
});Нужно лишь передать конфигурацию для Voximplant-аккаунта и некоторые данные для поддержки Flow авторизации Voximplant.
После чего достаточно получить сам звонок с помощью React Hook:
const call = useVideoCall({
conferenceId,
currentUserId: store.authenticatedUserId,
currentUserDisplayName: displayName ?? 'Stranger',
…
});Теперь у нас есть объект call, из которого мы можем извлекать информацию для отображения на странице или управления различными функциями звонка.
Также нужно не забывать про инструменты для работы с пользовательскими устройствами, отделённые от основной SDK. Они нам понадобятся для загрузки дефолтных настроек выбранных устройств и для получения разрешений для доступа к устройствам:
const devices = useDevices();
useEffect(() => {
devices
.requestAccess()
.then(() => devices.requestDevices())
.then(() => devices.loadDefaultDevices())
.then(() =>
Promise.all([
devices.enableOutputVideo(),
devices.unmuteOutputAudio()
])
);
}, []);Устройство намеренно не делают ничего по умолчанию, так как в разных случаях нужны разные дефолты. Привёл пример одной из настроек. Объект, получаемый из хука useDevices, напрямую связан со звонком, меняя устройства пользователя в нём — мы будем видеть соответствующие изменения в звонке (если не отключили это).
С устройствами есть свои детали: например, лучше давать пользователю фидбек о том, что происходит в данный момент. Оказалось что это не так просто, так как даже смена камеры не происходит моментально. Например такие флаги отображают, что камера или микрофон в процессе смены (во время этого процесса не стоит инициировать повторные запросы к устройствам):
get outputVideoInFlight(): boolean;
get outputAudioInFlight(): boolean;Я уже не говорю о том, что всё может закончиться ошибкой и её классификация — это отдельный геморрой. Но не будем заострять внимание на этом, ведь выбор и проверка устройств может быть темой отдельной статьи.
И остался ещё один важный компонент — адаптер для медиаучастников. Это некоторая сущность, которая отвечает за отображение контента. Очень пригодилась, когда подключали второй SDK от VK Звонков. В SDK Voximplant есть очень похожая, по сути, из неё и взяли идею.
Время SDK VK Звонков. Переход, использование, плюсы и минусы
Абстракции налеплены, рабочая версия есть. Время рискнуть ради 4K-шаринга экрана.
Основным вопросом было, насколько сложно будет повторить функции администрирования, которые с Voximplant SDK мы ловко закрывали загрузкой кода, управляющего звонком на стороне Voximplant. Ну и, конечно, насколько придётся переписать имеющийся фронт, как сильно «потекут абстракции».
Посмотрев доклад Вадима Горбачёва «VK Звонки: выходя за лимиты браузера», мы вооружились знаниями оттуда, подключили npm-модуль @vkontakte/calls-sdk и погнали.
По сравнению с предыдущим вариантом в первый момент бросилась в глаза куда меньшая зрелость SDK для публичного использования. Но, конечно, глупо сравнивать это в лоб, поскольку мы подключились к VK Calls SDK ещё на этапе тестового запуска вовне, новым пользователям этого SDK будет уже попроще. А вот нам после обилия задокументированных возможностей в Voximplant SDK было сложно, даже сам адрес документации нам понадобилось ещё найти (но мы нашли). Однако по всем остальным вопросам команда VK оперативно давала ответы и даже вносила исправления.
Сами SDK у VK Звонков и Voximplant на данном этапе похожи. Есть глобальные объекты, предоставляющие доступ к различным функциям видеоконференций. Единственное серьёзное отличие — необходимость конфигурировать Voxengine-скрипт для Voximplant SDK, то есть получаются два места с кодом. Такой компромисс между сложностью и гибкостью. С точки зрения базовых функций звонков, SDK похожи: везде нужно инициировать, вызвать некоторое API, согласовать передаваемые ID пользователей, которые могут быть анонимны, но идентификатор им всё равно нужен, все типы для TypeScript идут в комплекте, всё обычно.
А вот дальше интереснее, так как VK предоставляет возможность запросить для каждого входящего видео, какое разрешение мы хотим получить. То есть, если вы рендерите плитку чьего-то лица через SDK в элементе размером 160х90 пикселей, можно попросить у SDK именно этот размер видео.
И вот тут происходит магия, так как VK на сервере в реальном времени транскодирует видео — это прямо киллер-фича. Их SFU-медиасервер не просто пересылает медиа участников звонка, но способен на лету подобрать нужное разрешение, исходя из метрик соединения WebRTC и запрашиваемого качества, и организовать транскодинг видео для какого-то клиента (подробнее в докладе Ивана Григорьева).
Таким образом, проблемы совместимости по кодекам и сложный процесс договорённости между всеми участниками звонка уходит на второй план. Все затраты переложены на серверную сторону. Понятно, что тут есть оптимизации и не любое запрашиваемое разрешение вам выдадут, что транскодеры будут шариться между разными клиентами. Но это всё нюансы, о которых, мы надеемся, VK когда-нибудь также расскажет. Такого решения я пока ни у кого не видел.
Что касается реализации, в текущие абстракции мы добавили метод preferMediaSize, куда передаём текущий размер элемента, в котором отображаем видео. Обновляем через него же, например, если уменьшили размер окна браузера — можно запрашивать видео меньшего разрешения, чтобы экономить ресурсы железа участников.

Давайте возьмём наш звонок, найдём нужное CallMedia и попробуем воспользоваться возможностью VK SDK (в тестовом звонке у меня 3 участника, я уже нашёл CallMedia одного из них, и оно лежит первым):
const media = call.callMedias[0].raw.getVideoTracks()[0].getSettings()И видим следующий вывод:
deviceId: "video-pat-1"
frameRate: 26.463061780164303
height: 720
resizeMode: "none"
width: 1280То есть в данный момент нам приходит максимальное разрешение с моей 720p-камеры.
Попробуем захотеть странного и опробуем следующие варианты:
media.preferMediaSize({width: 360, height: 180})
media.preferMediaSize({width: 185, height: 180})Теперь заглянем в chrome://webrtc-internals и найдём нужную секцию с InboundVideoStats:

Видео действительно меняется после вызова методов updateDisplayLayout на стороне SDK. Выглядит очень классно, можно удобно адаптировать размеры видео под конкретные разрешения. При этом слать можно даже странные разрешения — SDK берёт эту работу на себя, округляя странные до тех, что соответствуют соотношению сторон входящего видео.
Поигравшись, мы вспомнили, что ключевой фичей был качественный шаринг экрана. Его реализация не заняла много времени, так как в целом все флаги были в нашем промежуточном объекте devices из хука useDevices(), а они уже, в свою очередь, связывались с конкретной реализации объекта Call. Поэтому перейдём к результатам.
Итак, шарим экран. Получаем нужный MediaStream и смотрим, что за видео к нам прилетело, с помощью MediaStream API:
mediaStream.getVideoTracks()[0].getSettings() // only chromeСтранно, но мы видим разрешение не 4K, хоть и довольно высокое. В чём же дело? Оказывается, на данный момент Chrome не выдаёт большее разрешение, поэтому оно такое странное — что-то между FHD и 2K. Но это всё равно выглядит очень достойно.

Трюки с изменением размера видео шаринга уже не проходят, так как шаринг в SDK VK Звонков — это особенная штука. Особенность заключается в том, что ребята пошли своим путём для большего контроля за кодированием видео, и упаковали шаринг экрана в DataChannel, взяв кодирование на себя. И тут у нас уже есть анонс доклада, где про это расскажут подробно: Что еще можно делать с видео в браузере [15].
Лично я жду кровавых подробностей о том, как ребята это реализовали и какие там были сложности. Для нас же это позволило избежать эвристик подстройки качества видео из стандартной реализации WebRTC. Хорошо видно, когда на экране много текста, хорошо оптимизировано под показ презентаций и кода (что как раз наш случай). Шаринг экрана деградирует только по FPS, но качество не проседает.
Проблемы перехода
Конечно, не обошлось и без проблем. В целом внедрение поддержки второго SDK прошло относительно гладко, но некоторые вещи пришлось выровнять — например, подстройку качества видео. В Voximplant это делалось со стороны сервера, поэтому такие запросы заворачиваются на наш бекенд и уже через него посылается сигнал в соединение с соответствующим медиасервером Voxengine. Для VK соответственно пришлось реализовать недостающую логику по управлению звонком и сбором информации на стороне нашего бэкенда.
В какой-то момент мы натолкнулись на интересную особенность, важную для наших требований по забору видео и аудио конкретного участника для вывод его в эфир: звук в VK Звонках работает по модели MCU.
![Нагло стыренная картинка из доклада Вадима Горбачёва [13]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/343/dfc/55d/343dfc55d5324ebd5954b53d308ac7a0.png "Нагло стыренная картинка из доклада Вадима Горбачёва [13]")
Что значит модель MCU: весь звук для вас собирает сервер, и в браузер будет приходить один поток (сумма всех голосов участников минус звук конкретного участника, к которому пришло). Но у нас в звонках участвует «технический» пользователь, который ничего не говорит, а лишь получает видео и аудио одного человека. Почему это проблема? Когда мы выводим в эфир сразу несколько человек из звонка, поскольку все может доходить с немного разной задержкой, звук «плывёт». Идеально тут было не получать сумму голосов, а звук только одного человека. Звучит как нерешаемая проблема для сторонней компании.

Но мы вспомнили про ребят с VideoTech и описали проблему. У них ушло не так много времени, чтобы сделать нам эту фичу — назвали её observer mode. Проблема была решена буквально за пару недель.
На этом приключения не закончились. Тут вступает в игру звукорежиссёр! Человек пришёл со словами «что это за ужас, вертаем всё назад». И он был прав. Были эффекты звука (скрежеты, проглатывания гласных, и так далее). Это всё было эффектом быстрого фикса, но тут разработчики из VK опять оперативно помогли и решили проблему после некоторого разбирательства и диагностики с нашей стороны.
Казалось бы, вот он — happy end. Но как можно что-то сделать и не попробовать подогфудить? Мы такое любим, поэтому стали использовать решение для своих корпоративных созвонов. И тут люди начали жаловаться. Как выглядели жалобы:
Тяжело понимать речь других участников
Невозможно слушать поэзию на синкапах маркетинга
Не хватает кнопки «выйти»
..

С третьего пункта пошли не очень важные для SDK вещи. Давайте остановимся и посмотрим на первые два пункта. Не так давно @alatobol рассказывал, как они в видеозвонках воевали с пылесосами: Нейросети против пылесоса, или Как мы убрали лишний шум в звонках ВКонтакте. Но острый слух нашего звукорежиссёра было не обмануть, Марина сразу сказала, что вместе с пылесосами из звонков улетучилась и поэзия вместе с шипящими звуками. В нашей компании эти эффекты разделили на две группы и назвали
Фифекты фикции — проблемы с шипящими
Эффекты сосисочной — проблемы со «свистящими» звуками
Это уже более тонкая подстройка звукового тракта, но мы умеем замучать партнёров тестами и фактами. Звукорежиссёр Марина записала трек про храм Тхаба-Ерды, где рассказала интересные факты про него через разные микрофоны и разными настройками шумодава VK Calls SDK. Попутно научилась воспроизводить эту запись для повторения теста с помощью blackhole с ноутбука, а потом и с помощью playwright-теста, который эмулировал работу одновременно говорящих людей (5-10).
С этим мы в очередной раз обратились к ребятам из VK, и они включили дампы наших звонков, в которые мы запустили эти тесты. Полученные данные можно уже было анализировать где угодно, хоть в Audacity или Audition. И придираться, так сказать, уже к картинкам. Вот пример:
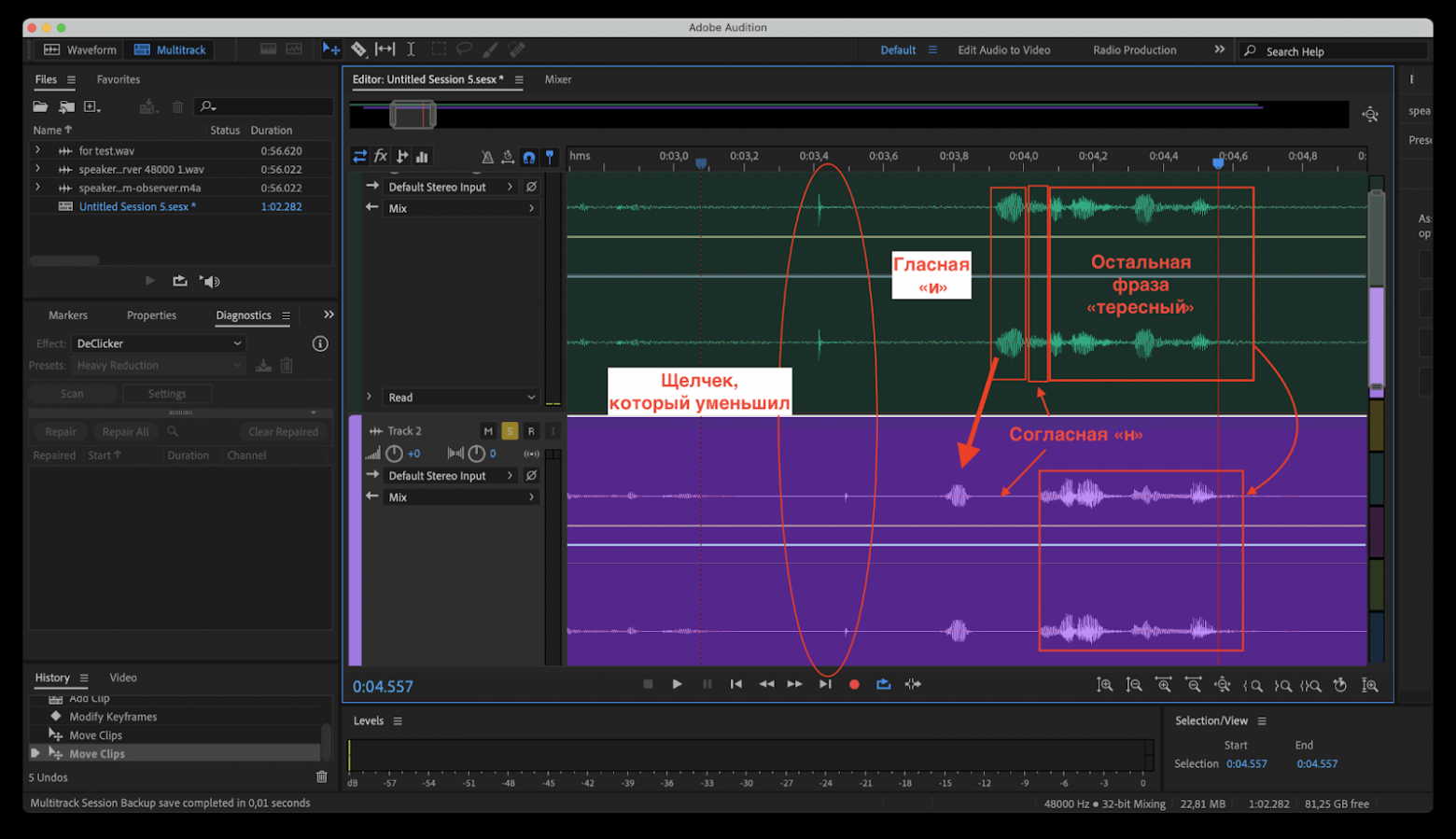
Судя по всему, вся команда звонков VK теперь знает, где находится самый старый христианский храм на территории России. Но помимо этих знаний, команда настроила процессы тестирования аудиотракта и частично решила проблемы «фифектов фикции» и «сосисочной». Про эту работу как раз можно будет послушать на следующем VideoTech: Как в VK Звонках работают над качеством звука [16].
В заключение
Что в итоге? Опробовав разные варианты, мы пока что остановились на SDK VK Звонков. Этой осенью проводим сезон из 10 конференций, и там в продакшне везде будет это решение — посмотрим, как текущая система покажет себя «в бою».
А одной из этих конференций снова станет VideoTech, где будут новые доклады от VK, и от Voximplant. Так что узнаем там про видеосвязь ещё больше. А если для вас был актуален этот пост, то на конференции и вы тоже наверняка найдёте полезное для себя (на сайте уже есть описания ряда докладов).
Если остались вопросы, смело задавайте их в комментариях. Надеюсь, наш опыт кому-то пригодится. А наша история на этом не заканчивается: будем и сами искать точки улучшения, и следить за дальнейшими улучшениями внешних SDK.
Ссылки из текста
Статья про организацию студий/пультовых – Пультовая всевластия
Упомянутая конференция про видео – VideoTech 2021
Съемочная площадка в офисе — практичный способ не налажать с трансляцией
Что сделать, чтобы ваша онлайн-трансляция не развалилась
Как мы делали сайт онлайн-трансляций за 3 месяца
Материалы со всех наших конференций на YouTube
It's time to WHIP WebRTC into shape
WebRTC-HTTP ingestion protocol (WHIP)
Делаем SFU-сервер из libwebrtc своими руками
Видеозвонки без ограничений VK — доклад про серверную часть от Ивана Григорьева
A Scalable WebRTC-Based Framework forRemote Video Collaboration Applications
Как подружиться со статистикой WebRTC и сэкономить тысячи часов отладки
VK Звонки: выходя за лимиты браузера
Как это устроено: видеоконференции ВКонтакте на безлимитное число участников
Про шаринг экрана через DataChannel с кастомным кодированием/декодированием от команды VK - Что еще можно делать с видео в браузере
Как в VK Звонках работают над качеством звука
Страничка VK Звонки – официальный лендинг от команды VK



