
Всем привет! Меня зовут Роман Халкечев, я руковожу отделом аналитики в Яндекс.Еде. Одно из ключевых направлений этого сервиса — логистика. Эффективность алгоритмов логистики во многом и определяет само существование сервисов доставки. Сегодня я расскажу читателям Хабра о нашем новом алгоритме, который помог курьерам сократить время простоя. Вы узнаете, из чего складывается время ожидания доставки заказа и зачем мы считали скорость приготовления килограмма условной еды. Но обо всём по порядку.
Яндекс.Еда представляет собой маркетплейс: на сервисе есть спрос и есть предложение. Спрос — это заказы пользователей. Предложение — курьеры. Разумеется, под предложением мы также понимаем рестораны, но в контексте этого поста остановимся именно на курьерах. Главная задача сервиса — поддерживать баланс: тогда будут счастливы и пользователи (они быстро получат еду), и курьерские службы (заказов хватит всем курьерам). Чтобы сохранять баланс и переживать локальный рост или падение спроса, нам необходимо повышать эффективность доставки. Под эффективностью мы понимаем оборачиваемость — среднее число заказов, которые курьер успевает доставить за час. Чем выше этот показатель, тем эффективнее работает доставка в целом.
Анализируем данные: на что уходит время?
Чтобы понять, как растить оборачиваемость, нужно более глубоко разобраться в том, как работает доставка. В этом нам помогут данные: мы посчитаем среднее время, которое необходимо курьеру для доставки заказа. Эту метрику — время от пользовательского клика до получения заказа — мы называем click to eat. Чем ниже CTE, тем больше заказов в час получится доставлять. Понятно, что при CTE > 30 минут больше двух заказов в час точно не доставить. Разве только если разносить несколько заказов одновременно — но об этом поговорим в следующий раз.

В зависимости от региона и времени года средний CTE лежит в промежутке от 30 до 38 минут. Чем больше заказов и чем лучше погода, тем меньше CTE, и наоборот. Давайте разберёмся, на что у курьера уходит это время.
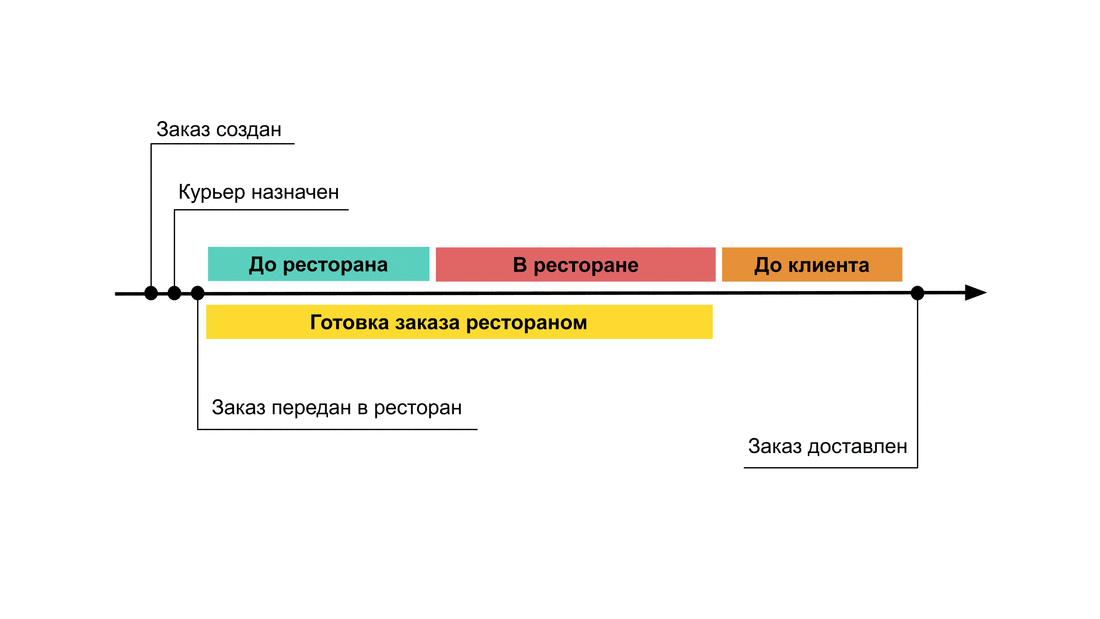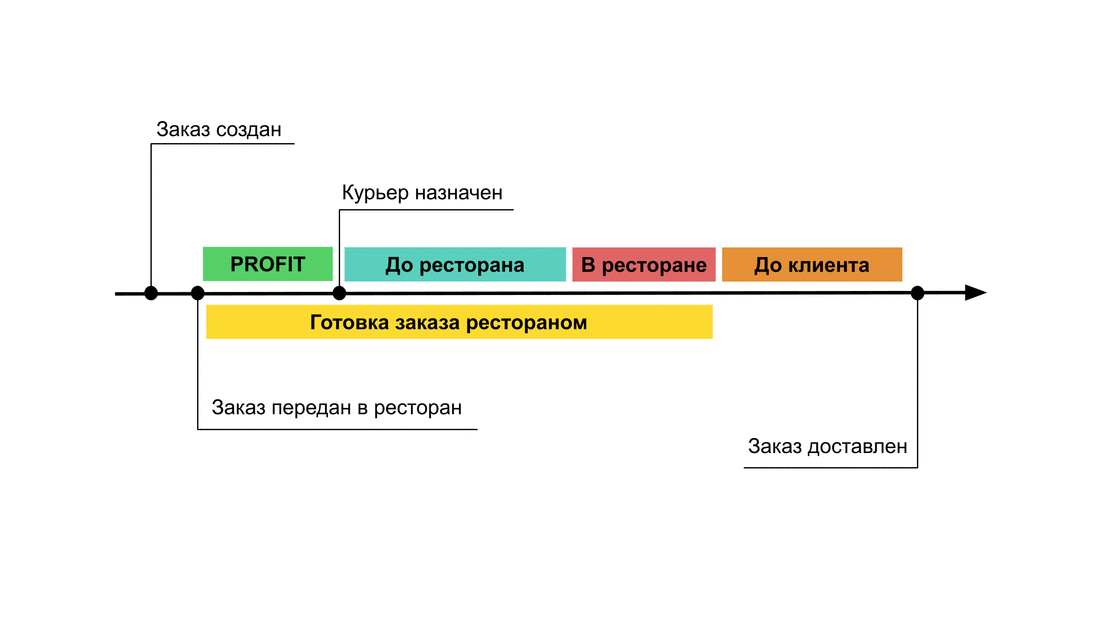
Во время заказа курьеры могут пребывать в нескольких состояниях:
— получил заказ, направляюсь в ресторан;
— прибыл в ресторан, жду, пока еду приготовят;
— получил еду, направляюсь к клиенту;
— прибыл к клиенту, передаю еду.
Чтобы понять, на что курьер тратит больше всего времени, рассмотрим график распределения времени по курьерским статусам. Ниже — пример такого графика для одного из городов присутствия Яндекс.Еды.

Как видно, ещё осенью 2019 года около 45% времени — 15–18 минут — курьеры проводили у ресторана в ожидании, пока блюда приготовят (!), хотя могли бы потратить это время на что-то более полезное. А происходило это из-за схемы назначения: мы получали заказ от клиента, сразу же искали курьера (ближайшего к ресторану) и в тот же момент отправляли его в ресторан. В итоге курьеры приходили рано и больше 15 минут ждали, пока заведение приготовит заказ.
Новый алгоритм назначения курьеров
Чтобы улучшить ситуацию и снизить время, которое курьеры проводят в бесполезном ожидании, мы решили разработать и внедрить новый алгоритм назначения. Основная идея: попробовать назначать курьеров не сразу при создании заказа, а позже — так, чтобы курьер прибывал в ресторан и всего через несколько минут забирал готовые блюда. У курьеров появится больше свободного времени, которое можно потратить с пользой: на доставку других заказов. А это позитивно скажется на оборачиваемости, сделает доставку эффективнее, позволит переживать локальные всплески спроса (при эффективной доставке нужно меньше курьеров, чтобы вывезти пик спроса) и обеспечит курьеров большим числом заказов.
Звучит классно, но почти сразу стало понятно, что для внедрения нового алгоритма нужно преодолеть много сложностей, продумать много нюансов, а также предусмотреть ряд краевых случаев.
Определение времени приготовления
Чтобы приводить курьеров в ресторан к концу приготовления, нужно понимать, когда ресторан, собственно, заканчивает готовить еду. Для первой версии мы взяли эвристику на основе исторических данных и веса корзины (в килограммах!) и считали, что у каждого ресторана есть своё среднее время приготовления.
После мы обучили модель предсказывать время приготовления каждого конкретного заказа. С учётом его характеристик, ресторана и времени суток. Я думаю, что описание этой модели заслуживает отдельного поста. Здесь же я приведу картинку с распределением ошибок модели и первоначальной эвристики.

Видно, что модель справляется с предсказанием лучше эвристики. Мы отнормировали предсказания модели так, чтобы зафиксировать долю опозданий на 10 минут и более в рамках SLA, и выкатили её в продакшен.
Определение времени назначения
Окей, предположим, теперь мы знаем, когда каждый заказ будет готов. Следующий вопрос: в какой момент делать назначение?
Можно воспользоваться какой-нибудь простой стратегией. Например, начинать искать курьера за 10 минут до конца приготовления. Но такой подход довольно рискованный. А вдруг мы не найдём курьера, который успеет добраться в ресторан за 10 минут? А что, если в этом районе вообще нет курьеров? В таком случае мы примем заказ, ресторан его приготовит — а мы не сможем доставить. Причём сообщим об этом клиенту не сразу, а через 15–20 минут, а то и больше, если заказ крупный. Пострадают в итоге все: клиент, ресторан и мы сами.
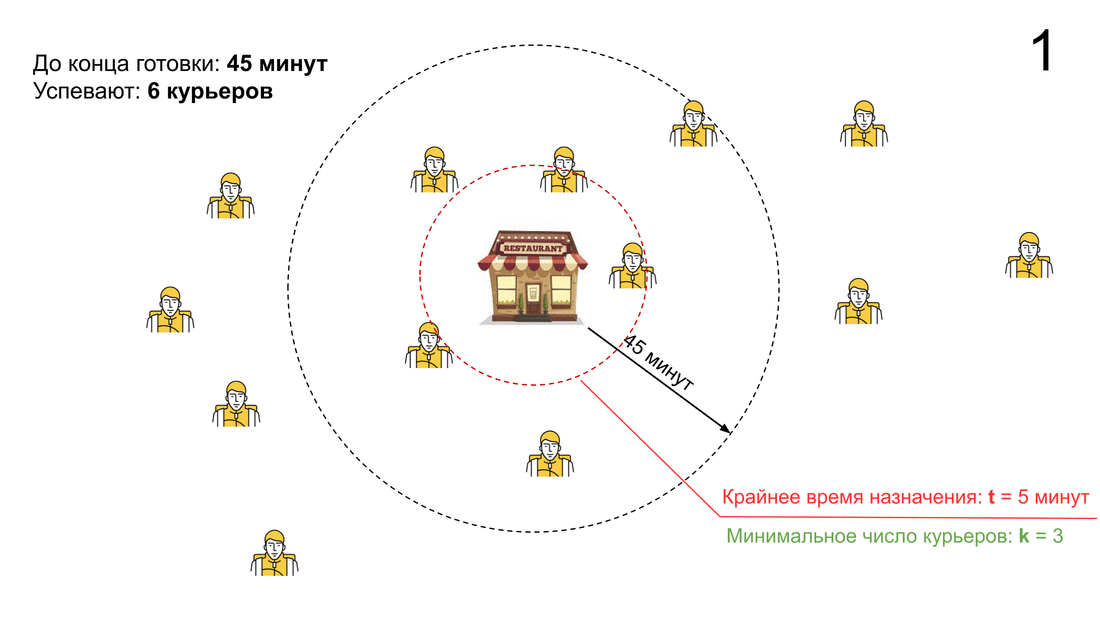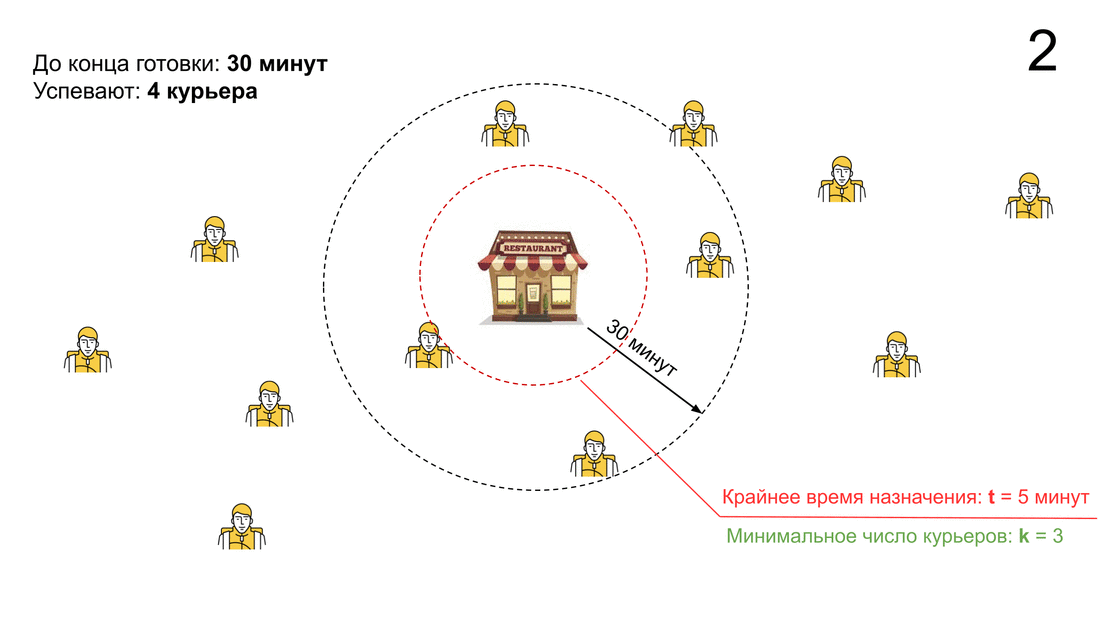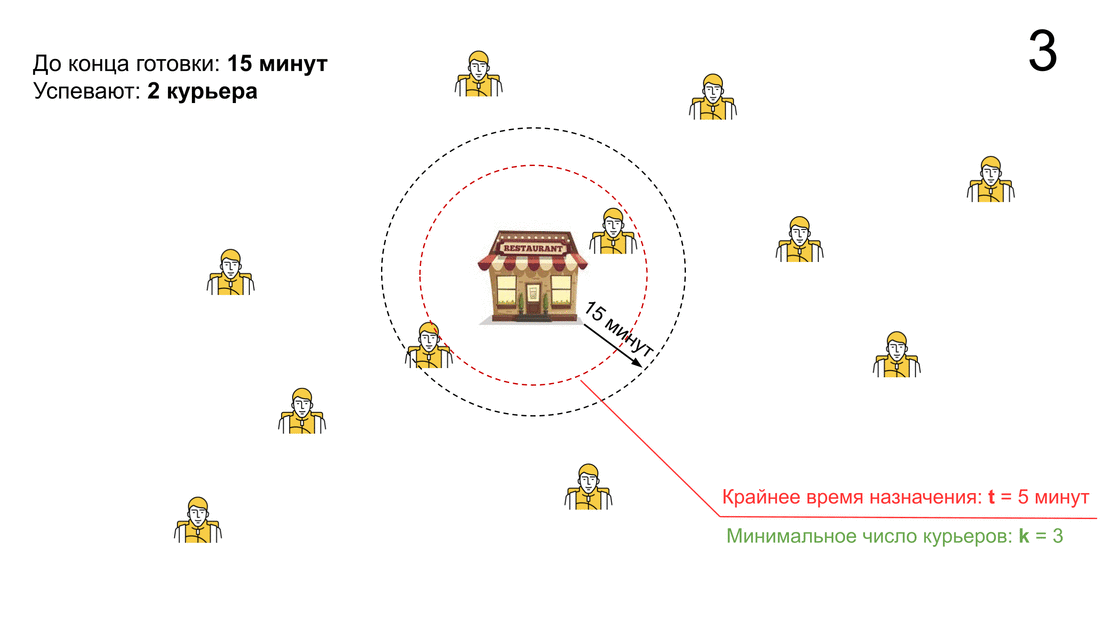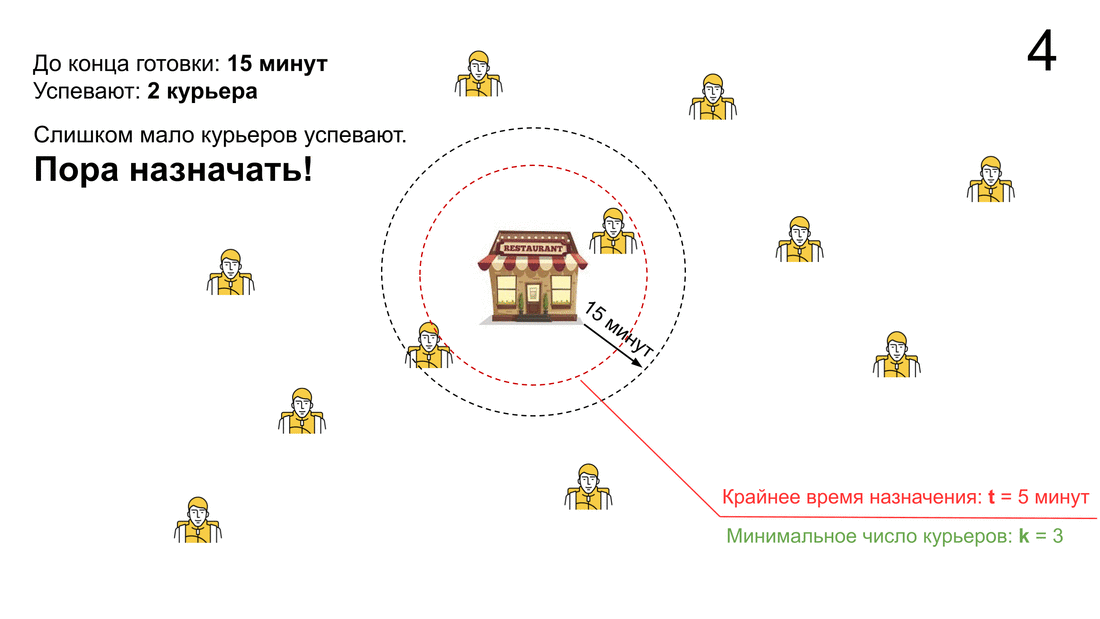
Чтобы свести к минимуму такие ситуации, мы придумали два критерия. Если они выполняются — начинаем искать курьера. Работает это так: мы принимаем заказ, а дальше каждую минуту запускаем ряд проверок, как бы спрашивая себя, можем ли мы отложить поиск курьера. Если ответ «да» — т. е. проверка пройдена — ничего не происходит, в противном случае мы начинаем поиск и назначаем курьера на заказ.
Сами критерии начала поиска очень простые:
— Либо до конца приготовления мало времени (время меньше порога t).
— Либо в окрестностях ресторана мало курьеров (количество тех, кто успеет к концу приготовления, меньше параметра k).
Кроме того, мы смотрим на состояние сервиса при создании заказа и можем заказ не принять. Это происходит, если курьеров резко не хватает либо если успевающих (или хотя бы не сильно опаздывающих) курьеров просто нет.
Внедрение и результат
Внедрение нового алгоритма осложнялось тем, что поиск и назначение курьеров — это фича с сетевым эффектом, а значит, нельзя просто так взять и провести честный А/B-эксперимент. С тех пор мы научились продвинутой технике проведения таких экспериментов, которую называют switch back (и о которой, надеюсь, расскажем в будущем). Но тогда мы просто обложили все части сервиса большим количеством метрик и начали постепенно раскатывать алгоритм с очень аккуратными настройками.
Нам было важно высвободить время курьеров, при этом не понизить качество сервиса: чтобы не выросли доля отмен и опозданий, а также среднее время, через которое мы отменяем заказ.
Классные новости заключаются в том, что это сработало! Осенью мы начали раскатку в одном из городов присутствия — и вот так изменилось распределение среднего времени на заказ:
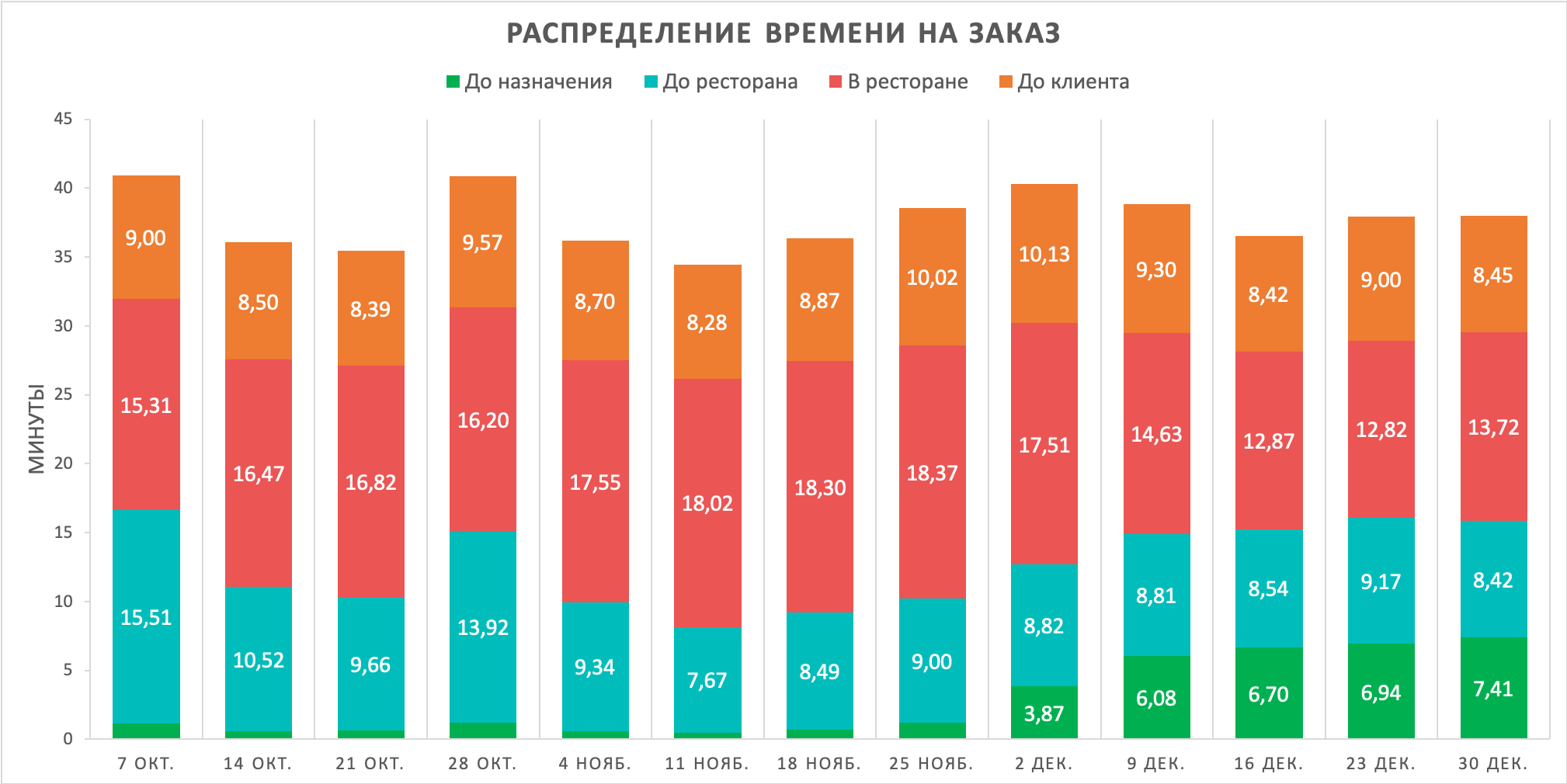
Как видно из графика выше, время в ресторане сократилось — мы высвободили больше 7 минут на заказ (см. зелёную часть — «До назначения»)! Причём и это ещё не предел — сейчас курьеры ожидают приготовления меньше 10 минут. И такой эффект сохранился, когда мы выкатили новый алгоритм на все города.
При этом доля отмен и опозданий осталась прежней, а оборачиваемость выросла. Отмечу, что эти метрики довольно высокоуровневые и на них влияет большое число факторов, поэтому без честного эксперимента оценить реальный эффект от внедрения сложно. Для того чтобы убедиться, что всё в порядке, мы внимательно изучили множество других метрик. Был риск, что так как мы начали назначать курьеров позднее, то в срезе отменённых заказов выросло время до отмены, что плохо повлияло бы на впечатления пользователей. Поэтому мы отдельно рассмотрели график медианы времени с момента заказа до отмены по причине «Не найден курьер».
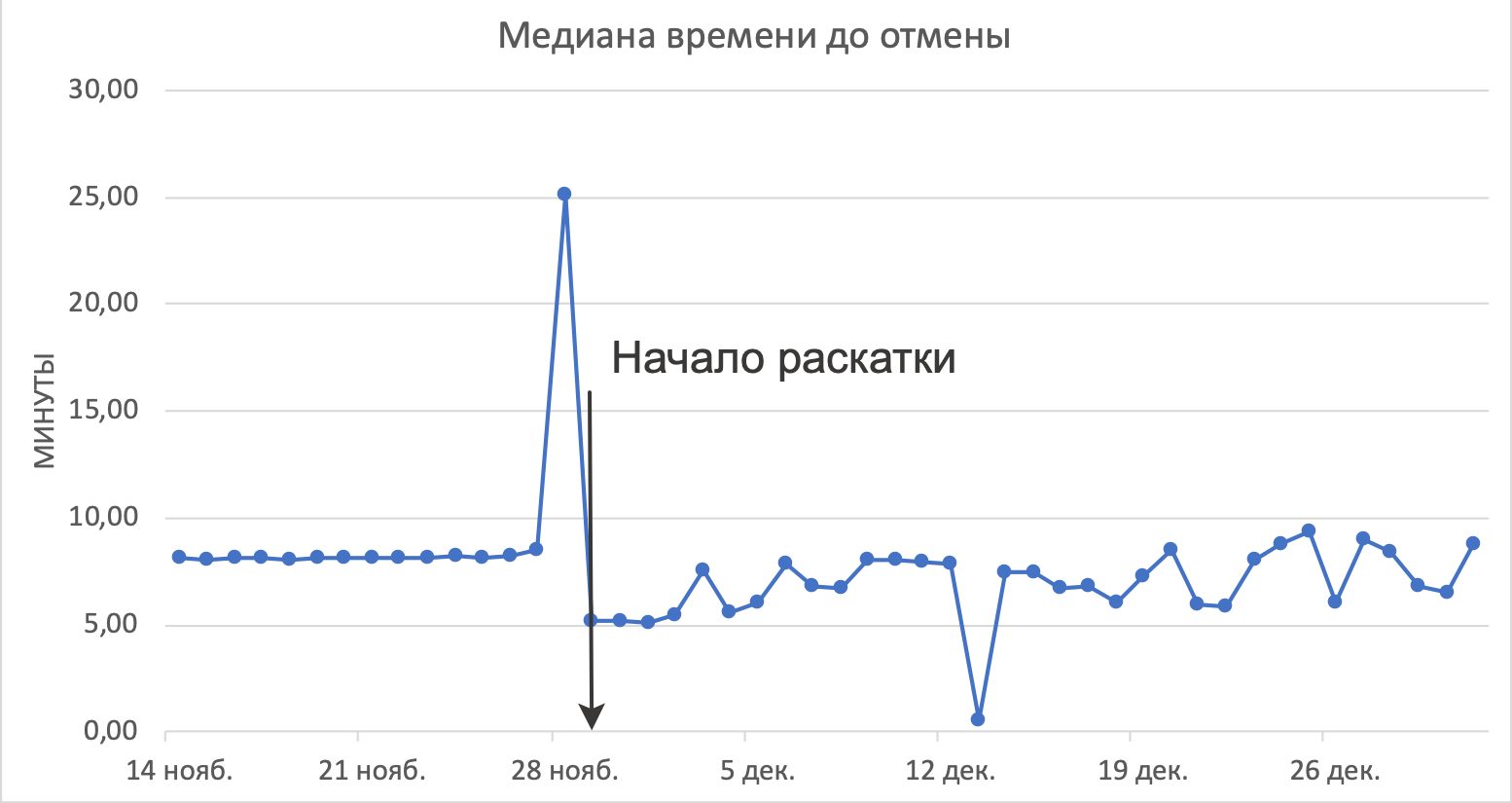
Видно, что после внедрения мы не стали позже отменять заказы, а в этом был основной риск отложенного назначения. График стал выглядеть иначе, потому что раньше мы пытались найти курьера в первые 8 минут после создания заказа, а если не получалось — отменяли заказ. Теперь же у нас работает многоуровневая схема проверок, о которой я писал выше и которая может приводить к отмене заказов, если курьеров не хватает.
Спасибо за внимание! С удовольствием отвечу на ваши вопросы.


