Изображения играют важную роль в продаже авторских туров. Когда стартап в сфере туризма, маркетплейс авторских туров YouTravel.me начал обрабатывать 2,5 млн запросов на картинки и отдавать 50 GB в сутки, команда разработки задумалась, как хранить изображения, чтобы они не теряли качество, и при этом не тратить космические бюджеты. CTO проекта Иван Михеев рассказывает, как сделали свой ресайзер для картинок и в 2 раза сократили косты.
YouTravel.me — международный маркетплейс авторских туров от независимых гидов. Путешествия — это всегда про эмоции и впечатления, поэтому в таком продукте ключевую роль играют не рациональные аргументы, а картинки, которые ярче слов описывают опыт, который ты в итоге получишь в поездке.
Нам нужно было хранить все изображения и оперативно отдавать их клиенту, чтобы скорость получения и качество картинки не падали. Плюс надо было адаптировать их под разное количество устройств и витрин. Учитывая, что мы работаем на международном рынке, мы должны это делать для пользователей по всему миру.
Мы задумались о новом способе для хранения и передачи изображений, потому что:
Стало приходить 50GB трафика в сутки.
Увеличилась нагрузка до 2,5 млн запросов.
Мы тратили $400 в месяц на стороннее SaaS решение, которое позволяло нам изменять картинки на лету и распределять их через content delivery network (CDN).
Такое решение обходилось нам довольно дорого, поэтому мы задумались, есть ли варианты дешевле.
Сравнили Cloudinary, Imagekit и Uploadcare, и увидели, что некоторые из сервисов строят свой продукт на базе AWS или его аналогов. Чтобы сравнение получилось более точным, мы взяли 1GB как общую единицу измерения. В таблице мы указали, сколько стоит гигабайт пропускной способности и общую сумму за месяц за 1 500GB с учётом доплат.

Мы решили разобраться, как работают CDN платформы. Схема была довольно простой — хранилище и Lambda функции, которые сжимают, изменяют размер и передают изображения пользователю.
Сравнив все варианты, мы решили детальнее изучить Amazon CloudFront, ведь по сути нам из всех сервисов нужен было только CDN и их Image API, которое позволяет конвертировать изображения на лету. Чтобы не платить комиссию сторонним платформам, мы решили сами сделать такое решение, которое бы позволило нам самостоятельно и быстро обрабатывать картинки. Кроме того, у нас был грант от Amazon на $5000, который нам позволил провести этот эксперимент почти бесплатно.
Задача оказалась проще и быстрее, чем мы сами думали, ниже делимся кусочком кода. План действий был таким:
Создать S3 storage для измененных картинок.
Создать CDN Distribution.
Написать Lambda функцию.
Создание S3-хранилища
Сначала нам нужно создать хранилище S3. Для этого в главном меню консоли переходим к S3 сервису и нажимаем на кнопку “Create bucket”.
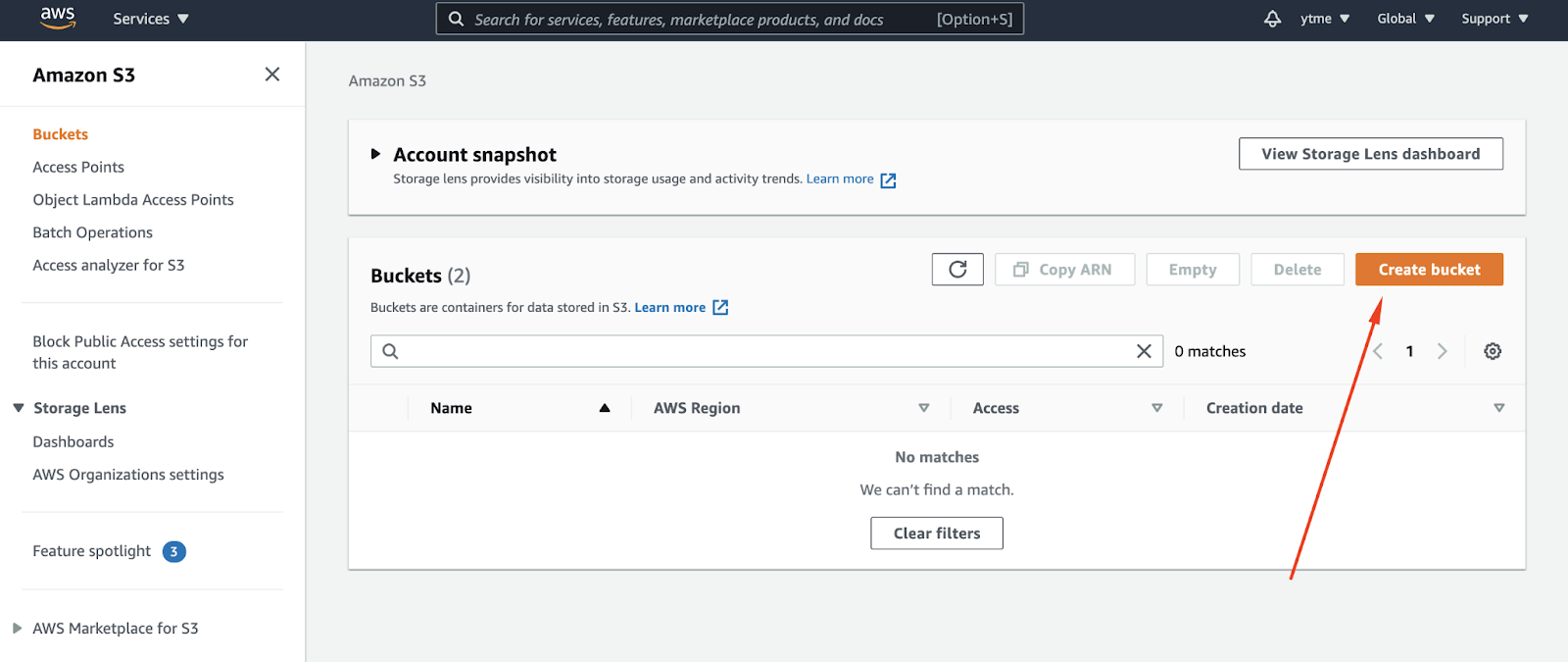
2. На следующем экране указываем имя(1) этого хранилища и регион(2), в котором оно будет развернуто.

3. Если все сделано правильно, в списке появится созданное нами хранилище.

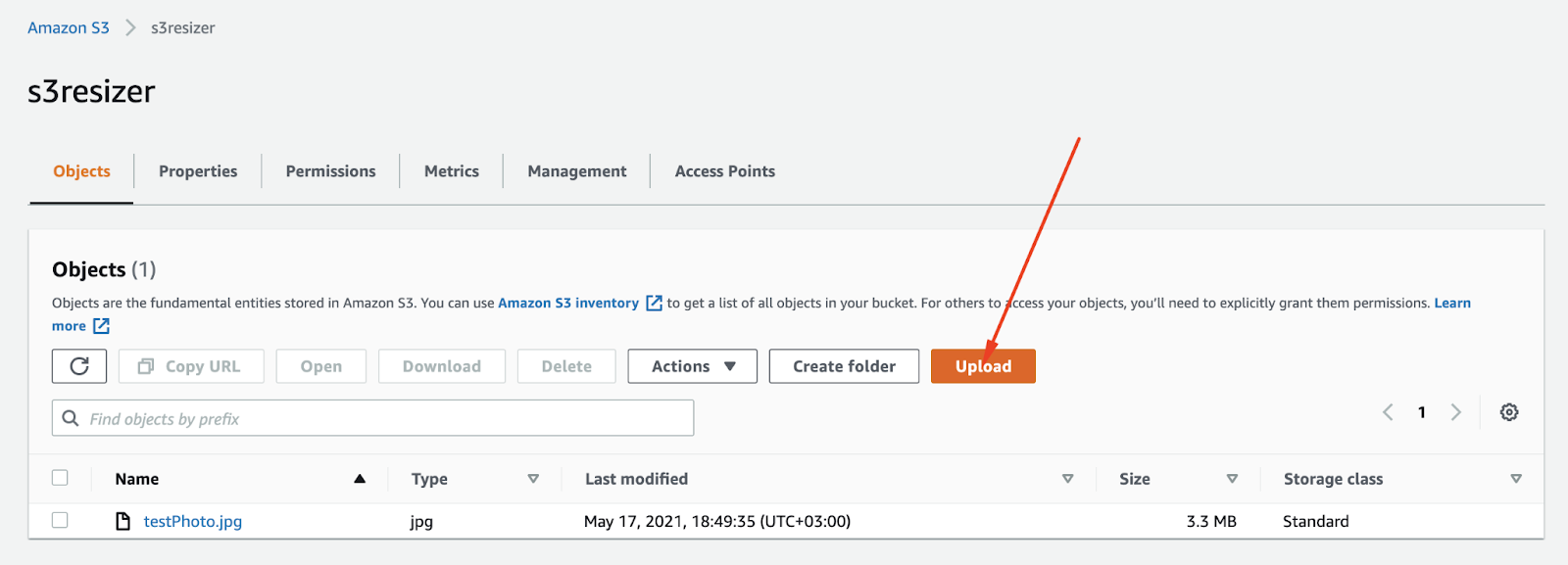
4. Дальше для тестирования загружаем в него любое случайное изображение. Оно нам пригодится на следующих этапах.
Создание точки распределения CloudFront
Первым делом нужно создать Origin Access Identity(OAI), чтобы мы могли выдать созданной точке CDN доступ к S3 хранилищу. Для этого нужно перейти к сервису CloudFront и выбрать слева в меню(1) Origin access identity.
Далее на экране настроек нажать на кнопку “Create Origin Access Identity”.

2. После этого нажимаем Create Distribution, создаём точку распределения контента.

3. Выбираем способ доставки контента и нажимаем Get Started.

4. Указываем базовые настройки как на скриншоте:
Выбираем созданное S3-хранилище из списка.
Указываем Restrict Bucket Access, потому что мы создали закрытое хранилище и выбираем созданную нами политику OAI.
Разрешаем автоматически прописать политики в настройки S3.

5. Настраиваем заголовки, которые при запросе будут передаваться на S3.

6. Также очень важно выбрать необходимый Price Class. Если вам не нужно активно обслуживать клиентов из Индии, Африки и Азии, то вам достаточно выбрать U.S, Canada and Europe. Тогда каждый Gb данных вам обойдется всего в 0.085$.

7. Теперь возвращаемся в S3-хранилище, которое мы создали на первом шаге, и убеждаемся, что политика прописалась корректно.

8. Переходим в список точек распределения и ждём около минуты, пока сервис не развернется.

9. Чтобы проверить работоспособность сервиса, достаточно перейти на указанный в колонке Domain Name адрес: http://%cloud-font-id%.cloudfront.net/testPhoto.jpg. Теперь у вас есть работающий CDN.
10. Также, если необходимо, вы можете настроить свой домен, установить SSL сертификат и включить необходимое вам логирование. Это оставим вам в качестве самостоятельной работы.
Создание Lambda-функции
Ключевой частью системы является Lambda функция. Она как раз отвечает за обработку изображения. Поясним принцип работы CloudFront и Lambda@Edge.
AWS Lambda позволяет запускать код без выделения серверов и управления ими. Вы платите только за потраченное время вычислений — плата не взимается, когда ваш код не работает. Лямбда масштабируется автоматически и обеспечивает высокую доступность. Lambda@Edge расширяет возможности Lambda до предела, позволяя запускать код в нескольких местах AWS ближе к зрителю.
Для каждого поведения кеша в раздаче Amazon CloudFront можно добавить до четырех триггеров, которые вызывают выполнение функции Lambda, если появляется одно или несколько из событий CloudFront:

Принцип работы CloudFront. Источник - https://aws.amazon.com/ru/blogs/networking-and-content-delivery/resizing-images-with-amazon-cloudfront-lambdaedge-aws-cdn-blog/
Запрос CloudFront Viewer — функция выполняется, когда CloudFront получает запрос от средства просмотра, и перед проверкой наличия запрошенного объекта в пограничном кеше.
CloudFront Origin Request — функция выполняется только тогда, когда CloudFront пересылает запрос вашему источнику. Когда запрошенный объект находится в пограничном кеше, функция не выполняется.
Ответ CloudFront от источника — функция выполняется после того, как CloudFront получает ответ от источника и до кэширования объекта в ответе.
Ответ CloudFront Viewer — функция выполняется до того, как запрошенный объект возвращается, в программу просмотра. Функция выполняется независимо от того, находится ли объект уже в краевом кеше.
Механизм работы наших Lambda простой: мы будем передавать параметры обработки изображений прямо в URL — https://domain.ltd/tr:w-XXX,h-XXX/path/to/image.jpg. Для этого наши шаги будут следующими:
Создаем функцию обработчик для Viewer-request. Её задача — принять заголовки браузера и понять, принимает ли он webp или ему нужно отдавать jpg/png и скорректировать строку запроса соответствующим образом.
В этом случае мы добавляем в начале запроса папку с именем формата /webp/tr:w-XXX,h-XXX/path/to/image.jpg либо /original/tr:w-XXX,h-XXX/path/to/image.jpg
Можно обойтись без нее и просто проксировать заголовок accept, но тогда он будет являться частью cache ключа, и кеширование будет неэффективно, так как вариантов значений заголовка может быть много.
2. Далее мы создаем функцию origin-response. Она работает так:
Мы смотрим, есть ли эта картинка на S3, которую мы получили благодаря полученному коду ответа от S3.
Если картинка есть, мы ничего не делаем, и просто позволяем CloudFront ее закешировать.
Если картинки на S3 нет, то нам необходимо ее создать.
Так как в качестве ресурса мы используем внешний web сервер, мы делаем http запрос за картинкой, обрабатываем её в соответствии с настройками (сжимаем, изменяем размер). В качестве хранилища также можно использовать этот же bucket S3, тогда вместо http запроса вам нужно будет сделать внутренний запрос за картинкой через AWS SDK.
После этого обработанную картинку сохраняем в S3 уже по новому пути и отдаём её в CloudFront.
В следующий раз, когда кеш картинки потеряет актуальность, в S3 уже будет лежать нужная нам картинка, и весь алгоритм завершится на пункте b.
Мы разместили наш код Lambda-функций на GitHub. Делимся им с вами, чтобы вы могли применить его в своих экспериментах. Его можно взять и сразу запустить в продакшене. Мы не настаиваем, что наш код будет самым оптимальным решением для вашего случая. Лучшего протестировать, понять, как работает наше решение, и потом уже осознанно реализовать свое.
Прежде чем приступим к созданию нашей функции, поясним несколько основных частей функции origin-response:
exports.handler — это основная функция, которая и будет выполняться сервисом Lambda@Edge.
В первую очередь внутри этого обработчика мы получаем оригинальный путь до файла. Этим занимается класс ImageRequest. Он же отвечает за то, чтобы понять, какие трансформации необходимо произвести и в каком формате нужно отдать файл (webp либо в формате оригинала)
Далее функция проверяет наличие файла на S3 — это делается просто путем определения кода ответа от origin сервера.
Если S3 ответило нам кодом 404 или 403, значит файл не найден и нужно его создать. Для этого мы отправляем запрос на наш сервер по HTTP. Скачиваем картинку, делаем необходимые трансформации через sharp библиотеку и сохраняем все на S3.
Если файл найден, то мы завершаем выполнение функции и отдаём тот ответ, который и планировал отдать S3.
Сам код мы снабдили дополнительными комментариями.
Давайте теперь создадим эти функции, чтобы моментально делать ресайз:
Заходим в IAM и создайте роль, которая позволит Lambda функции считывать и писать данные в S3, а так же способна исполнятся.

Источник - https://signin.aws.amazon.com/signin?redirect_uri=https%3A%2F%2Fconsole.aws.amazon.com%2Fiam%2Fhome%3Fregion%3Dus-east-1%26state%3DhashArgs%2523%252Froles%26isauthcode%3Dtrue&client_id=arn%3Aaws%3Aiam%3A%3A015428540659%3Auser%2Fiam&forceMobileApp=0&code_challenge=8nOwvrW1w-0ptic1774Ujk3iUCE-rnU1MOUN8nsXYuE&code_challenge_method=SHA-256
2. Добавляем политики AmazonS3FullAccess, AWSLambdaExecute.
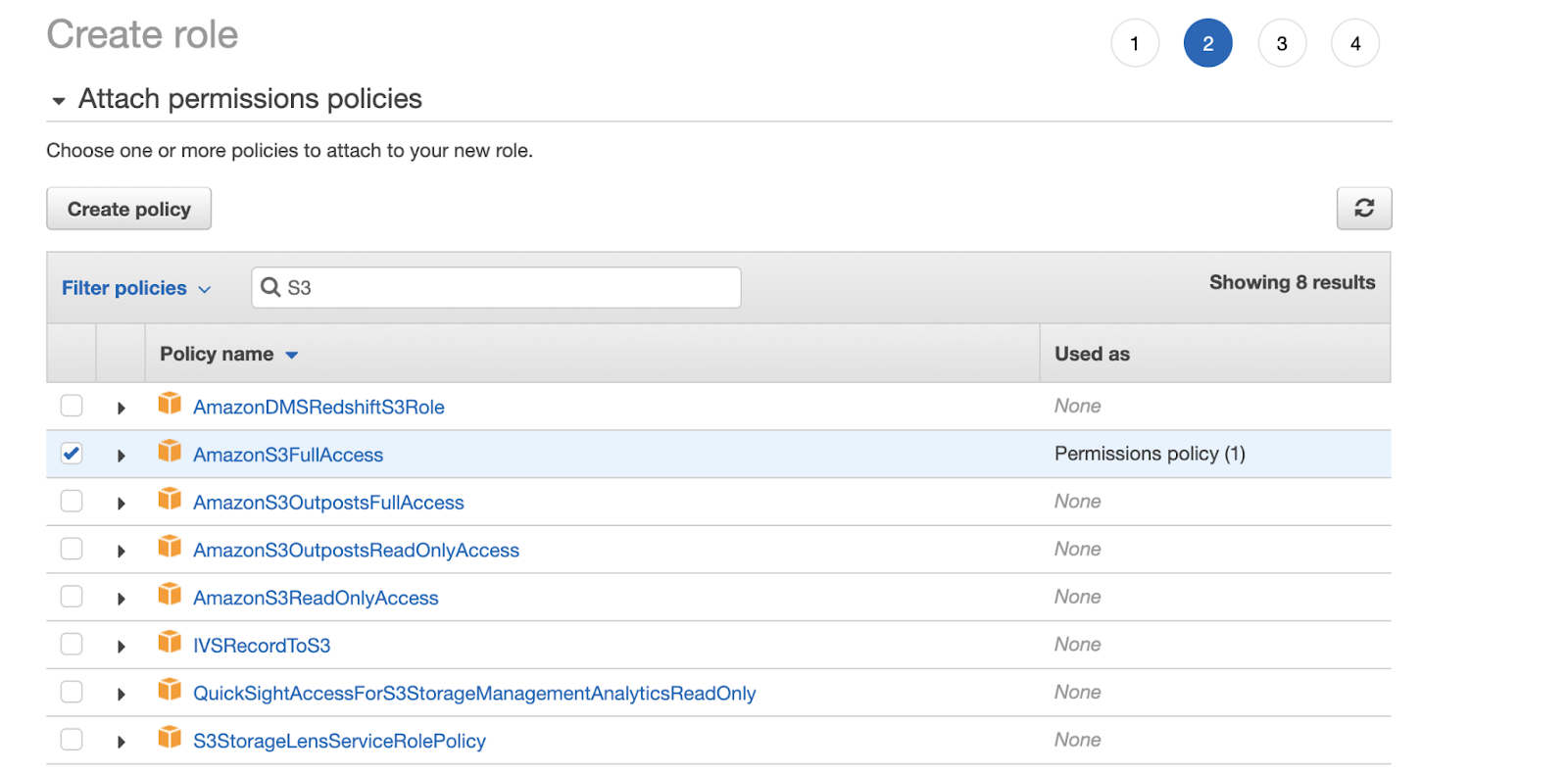
3. На последнем шаге указываем имя.
4. Создаём две функции для viewer-request и origin-response, выбираем вариант from scratch и указываем там роль, которую создали в п.3.

5. Дальше необходимо подготовить код к загрузке.
6. Нам понадобится установленный Docker, чтобы собрать sharp с поддержкой libvips
7. Скачиваем репозиторий.
8. Выполняем скрипт build.sh.
9. Заливаем код в соответствующие функции.

10. Проверяем по ссылке.
Чтобы тестировать ваши функции локально, достаточно воспользоваться:
AWS CLI и AWC SAM
cd lambda/origin-response
sam local invoke -e s3-event.json
Так, немного разобравшись, мы сэкономили почти 200$ ежемесячно без потери качества и скорости для пользователя. На работу и тестирования мы потратили неделю. Мы пользуемся этим решением с марта, и оно показывает себя довольно стабильно: картинки отдаются быстро и без потери качества.




