
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
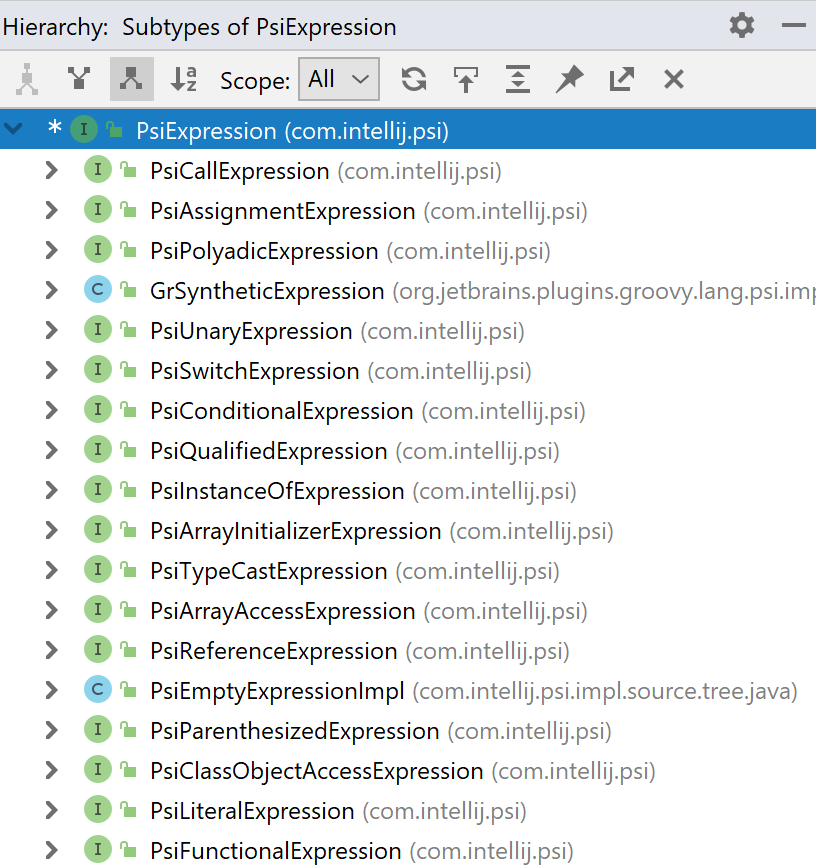 Важной возможностью любой IDE является поиск и навигация по коду. Один из часто используемых вариантов поиска на языке Java — поиск всех реализаций данного интерфейса. Часто такая функция называется иерархией типов (Type Hierarchy) и выглядит как на картинке справа.
Важной возможностью любой IDE является поиск и навигация по коду. Один из часто используемых вариантов поиска на языке Java — поиск всех реализаций данного интерфейса. Часто такая функция называется иерархией типов (Type Hierarchy) и выглядит как на картинке справа.
Перебирать все классы проекта при вызове этой функции — неэффективно. Можно сохранить в индекс полную иерархию классов во время компиляции, так как компилятор все равно ее строит. Мы это делаем, если компиляция запускается самой IDE, а не делегируется, например, в Gradle. Но это работает, только если после компиляции в модуле ничего не менялось. А в общем случае исходники — самый актуальный источник информации, и индексы строятся по исходникам.
Поиск непосредственных наследников — несложная задача, если мы не имеем дело с функциональным интерфейсом. При поиске реализаций интерфейса Foo надо найти все классы, где есть implements Foo, и интерфейсы, где есть extends Foo, а также анонимные классы вида new Foo(...) {...}. Для этого достаточно заранее построить синтаксическое дерево каждого файла проекта, найти соответствующие конструкции и добавить их в индекс.
Конечно, тут есть небольшая тонкость: возможно, вы ищете интерфейс com.example.goodcompany.Foo, а где-то на самом деле используется org.example.evilcompany.Foo. Можно ли заранее положить в индекс полное имя родительского интерфейса? С этим имеются сложности. К примеру, файл, где интерфейс используется, может выглядеть так:
// MyFoo.java
import org.example.foo.*;
import org.example.bar.*;
import org.example.evilcompany.*;
class MyFoo implements Foo {...}Глядя только на файл, мы не можем понять, какое же настоящее полное имя Foo. Придется посмотреть на содержимое нескольких пакетов. А каждый пакет может быть определен в нескольких местах (к примеру, в нескольких jar-файлах). Индексирование сильно затянется, если при анализе данного файла нам придется делать полноценное разрешение символа. Но основная проблема даже не в этом, а в том, что индекс, построенный по файлу MyFoo.java, будет зависеть не только от него, но и от других файлов. Ведь мы можем перенести описание интерфейса Foo, к примеру, из пакета org.example.foo в пакет org.example.bar, и ничего не менять в файле MyFoo.java, и при этом полное имя Foo изменится.
Индексы в IntelliJ IDEA зависят только от содержимого одного файла. С одной стороны, это очень удобно: индекс, относящийся к определенному файлу, становится недействительным, когда меняется этот файл. С другой стороны, это накладывает большие ограничения на то, что можно поместить в индекс. Например, не позволяет надежно сохранять в индексе полные имена родительских классов. Но, в принципе, это и не так страшно. При запросе иерархии типов мы можем найти всё, что подходит по короткому имени, а потом уже для этих файлов выполнить честное разрешение символа и определить, действительно ли он нам подходит. В большинстве случаев лишних символов окажется не очень много и такая проверка будет довольно быстрой.
 Ситуация сильно меняется, когда класс, наследников которого мы ищем, является функциональным интерфейсом. Тогда помимо явных и анонимных наследников у нас появляются лямбда-выражения и ссылки на методы. Что же теперь положить в индекс, и что вычислять непосредственно при поиске?
Ситуация сильно меняется, когда класс, наследников которого мы ищем, является функциональным интерфейсом. Тогда помимо явных и анонимных наследников у нас появляются лямбда-выражения и ссылки на методы. Что же теперь положить в индекс, и что вычислять непосредственно при поиске?
Предположим, у нас есть функциональный интерфейс:
@FunctionalInterface
public interface StringConsumer {
void consume(String s);
}В коде встречаются разные лямбда-выражения. Например:
() -> {} // точно не подходит: нет параметров
(a, b) -> a + b // точно не подходит: два параметра
s -> {
return list.add(s); // точно не подходит: возвращаем значение
}
s -> list.add(s); // может и подходитТо есть быстро мы можем отфильтровать только те лямбды, у которых неподходящее количество параметров либо очевидно неподходящий возвращаемый тип, например void против не-void. Определить возвращаемый тип более точно обычно нельзя. Скажем, в лямбде s -> list.add(s) для этого надо выполнить разрешение символов list и add, а, возможно, и запустить полноценную процедуру вывода типов. Все это долго и потребует завязки на содержимое других файлов.
Нам повезет, если наш функциональный интерфейс принимает пять аргументов. Но если он принимает всего один аргумент, такой фильтр оставит огромное число лишних лямбд. Еще хуже со ссылками на методы. В принципе, по внешнему виду любой ссылки на метод никак нельзя сказать, подходит она или нет.
Возможно, стоит посмотреть вокруг лямбды, чтобы что-то понять? Да, иногда это работает. Например:
// объявление локальной переменной или поля другого типа
Predicate<String> p = s -> list.add(s);
// возврат из метода другого типа
IntPredicate getPredicate() {
return s -> list.add(s);
}
// присваивание локальной переменной другого типа
SomeType fn;
fn = s -> list.add(s);
// приведение к другому типу
foo((SomeFunctionalType)(s -> list.add(s)));
// объявление массива другого типа
Foo[] myLambdas = {s -> list.add(s), s -> list.remove(s)};Во всех этих случаях короткое имя соответствующего функционального интерфейса можно выяснить из текущего файла и положить в индекс рядом с функциональным выражением, будь то лямбда или ссылка на метод. К сожалению, в реальных проектах этими случаями покрывается очень малая доля всех лямбд. В подавляющем большинстве случаев лямбда используется как аргумент метода:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));Какая из этих трех лямбд может иметь тип StringConsumer? Программисту ясно, что никакая. Потому что очевидно, что здесь у нас цепочка Stream API, а там только функциональные интерфейсы из стандартной библиотеки, нашего типа там быть не может.
Однако IDE не должна давать себя обмануть, она обязана выдать точный ответ. Что если list — это совсем не java.util.List, а list.stream() возвращает вовсе не java.util.stream.Stream? Для этого надо резолвить символ list, что, как мы знаем, невозможно надежно сделать только на основе содержимого текущего файла. Да и даже если мы это установили, поиск не должен закладываться на реализацию стандартной библиотеки. Может, мы конкретно в этом проекте подменили класс java.util.List на свой собственный? Поиск обязан на это отреагировать. Ну и, разумеется, лямбды используются не только в стандартных стримах, есть и много других методов, куда они передаются.
В итоге получается, что мы у индекса можем запросить список всех Java-файлов, где используются лямбды с нужным числом параметров и допустимым возвращаемым типом (на самом деле мы отслеживаем только четыре варианта: void, не-void, boolean и любой). А дальше что? Для каждого из этих файлов строить полное дерево PSI (это вроде дерева разбора, но с разрешением символов, выводом типов и другими умными штуками) и честно выполнять вывод типа для лямбды? Тогда в большом проекте вы не дождетесь списка всех реализаций интерфейса, даже если их будет всего две.
Получается, нам надо проделать следующие шаги:
- Спросить у индекса (дешево)
- Построить PSI (дорого)
- Вывести тип лямбды (очень дорого)
В Java версии 8 и старше вывод типа — безумно дорогая операция. В сложной цепочке вызовов у вас может быть множество подстановочных generic-параметров, значения которых надо выяснить с помощью зубодробительной процедуры, описанной в главе 18 спецификации. Это можно делать в фоне для текущего редактируемого файла, но выполнять это для тысяч неоткрытых файлов будет тяжело.
Здесь, впрочем, можно немного срезать угол: в большинстве случаев нам не нужен окончательный тип. Если только лямбда не передается в метод, принимающий в этом месте generic-параметр, мы можем избавиться от последнего шага подстановки параметров. Скажем, если мы вывели тип лямбды java.util.function.Function<T, R>, мы можем не вычислять значения подстановочных параметров T и R: и так ясно, выдавать ее в результат поиска или нет. Хотя это не сработает при вызове метода вроде такого:
static <T> void doSmth(Class<T> aClass, T value) {}Этот метод можно вызвать вот так: doSmth(Runnable.class, () -> {}). Тогда тип лямбды выведется как T, и подставлять все равно придется. Но это редкий случай. Поэтому тут сэкономить получается, но не больше 10%. Кардинально проблема не решается.
Другая идея: если точный вывод типов сложный, то давайте сделаем приблизительный вывод. Пусть он работает только на стертых типах классов и не делает редукцию набора ограничений, как написано в спецификации, а просто идет по цепочке вызовов. Пока стертый тип не включает generic-параметров, то все хорошо. К примеру, возьмем стрим из примера выше и определим, реализует ли последняя лямбда наш StringConsumer:
- Переменная
list→ типjava.util.List - Метод
List.stream()→ типjava.util.stream.Stream - Метод
Stream.filter(...)→ типjava.util.stream.Stream, на аргументыfilterдаже не смотрим, какая разница - Метод
Stream.map(...)→ типjava.util.stream.Stream, аналогично - Метод
Stream.forEach(...)→ есть такой метод, его параметр имеет типConsumer, который, очевидно, неStringConsumer.
Прекрасно, обошлись без полноценного вывода типов. С таким простым подходом, впрочем, легко напороться на перегруженные методы. Если мы полностью вывод типов не запускаем, то выбрать правильный перегруженный вариант нельзя. Хотя нет, иногда можно, если число параметров методов различается. Например:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));Здесь мы можем легко понять, что
- Методов
CompletableFuture.supplyAsyncимеется два, но один принимает один аргумент, а второй — два, поэтому выбираем тот, который принимает два. Он возвращаетCompletableFuture. - Методов
thenRunAsyncтоже два, и из них можно аналогичным образом выбрать тот, который принимает один аргумент. Соответствующий параметр имеет типRunnable, значит это неStringConsumer.
Если же несколько методов принимают одинаковое количество параметров, либо некоторые имеют переменное число параметров и тоже выглядят подходящими, то придется отслеживать все варианты. Но часто это тоже не страшно. Например:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));new StringBuilder()очевидно создаетjava.lang.StringBuilder. Для конструкторов мы все-таки разрешаем ссылку, но сложный вывод типов здесь не требуется. Даже если бы былоnew Foo<>(x, y, z), мы не выводим значения типовых параметров, нам интересен толькоFoo.- Методов
StringBuilder.append, принимающих один аргумент, очень много, но все они возвращают типjava.lang.StringBuilder, поэтому нам неважно, какого там типаfooиbar. - Метод
StringBuilder.charsодин и возвращаетjava.util.stream.IntStream. - Метод
IntStream.forEachодин и принимает типIntConsumer.
Даже если где-то остается несколько вариантов, можно отслеживать их все. Например, тип лямбды, переданной в ForkJoinPool.getInstance().submit(...), может быть Runnable или Callable, но если мы ищем что-то третье, то все еще можем отбросить эту лямбду.
Неприятная ситуация возникает, когда метод возвращает generic-параметр. Тогда процедура ломается и приходится запускать полный вывод типов. Впрочем, один случай мы поддержали. Он хорошо проявляется на моей библиотеке StreamEx, в которой есть абстрактный класс AbstractStreamEx<T, S extends AbstractStreamEx<T, S>>, содержащий методы вроде S filter(Predicate<? super T> predicate). Обычно люди работают с конкретным классом StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>>. В данном случае можно выполнить подстановку параметра типа и узнать, что S = StreamEx.
Отлично, мы во многих случаях избавились от очень дорогого вывода типов. Но мы ничего не сделали с построением PSI. Как-то обидно делать синтаксический разбор файла на пятьсот строк только ради того, чтобы выяснить, что лямбда в строке 480 не подходит под наш запрос. Вернемся к нашему стриму:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));Если list — это локальная переменная, параметр метода или поле в текущем классе, то уже на этапе индексирования мы можем найти ее объявление и установить, что короткое имя типа —
List. Соответственно, в индекс для последней лямбды мы можем положить следующую информацию:
Тип сей лямбды есть тип параметра методаforEachот одного аргумента, вызванного на результате методаmapот одного аргумента, вызванного на результате методаfilterот одного аргумента, вызванного на результате методаstreamот нуля аргументов, вызванного у объекта типаList.
Вся эта информация доступна по текущему файлу, а значит может быть размещена в индексе. Во время поиска мы запрашиваем у индекса такую информацию обо всех лямбдах и пытаемся восстановить тип лямбды без построения PSI. Для начала придется выполнить глобальный поиск классов с коротким именем List. Конечно, мы найдем не только java.util.List, а еще java.awt.List или что-нибудь из кода пользовательского проекта. Дальше мы подадим все эти классы в ту же процедуру неточного разрешения типов, которой мы пользовались раньше. Часто лишние классы сами быстро отфильтруются. Например, в java.awt.List нет метода stream, поэтому дальше он исключается. Но даже если что-то лишнее будет с нами до конца и мы найдем несколько кандидатов на тип нашей лямбды, неплохие шансы, что все они не подойдут под поисковый запрос, и мы все равно избежим построения полного PSI.
Возможны варианты, что глобальный поиск окажется слишком дорог (в проекте много классов List), либо начало цепочки не разрешается в контексте одного файла (скажем, это поле родительского класса), либо где-то цепочка прервется, потому что метод возвращает generic-параметр. Тогда мы сразу не сдаемся и пытаемся снова начать с глобального поиска на следующем методе цепочки. Например, для цепочки map.get(key).updateAndGet(a -> a * 2) в индекс легла следующая инструкция:
Тип сей лямбды есть тип единственного параметра методаupdateAndGet, вызванного на результате методаgetс одним параметром, вызванного на объекте типаMap.
Пусть нам повезло и в проекте всего один тип Map — java.util.Map. У него действительно есть метод get(Object), но, к сожалению, он возвращает generic-параметр V. Тогда мы бросаем цепочку и ищем глобально метод updateAndGet с одним параметром (с помощью индекса, конечно). О чудо, таких методов всего три в проекте, в классах AtomicInteger, AtomicLong и AtomicReference с параметром типа IntUnaryOperator, LongUnaryOperator и UnaryOperator, соответственно. Если мы ищем любой другой тип, то мы выяснили, что данная лямбда не подходит и PSI можно не строить.
Удивительно, что это яркий пример фичи, которая со временем сама начинает работать медленнее. К примеру, вы ищете реализации функционального интерфейса, их всего три штуки в проекте, а IntelliJ IDEA их ищет десять секунд. А вы прекрасно помните, что три года назад их было тоже три, вы их тоже искали, но тогда среда выдавала ответ за две секунды на этой же машине. И проект у вас хоть и огромный, но за три года вырос, может, процентов на пять. Конечно, вы начинаете справедливо негодовать, чего там эти разработчики напортили, что IDE стала так жутко тормозить. Руки бы поотрывать этим горе-программистам.
А мы, может быть, вообще ничего не меняли. Может быть поиск работает так же, как три года назад. Просто три года назад вы только перешли на Java 8, и у вас в проекте было, скажем, всего сто лямбд. А теперь ваши коллеги превратили анонимные классы в лямбды, стали активно использовать стримы или подключили какую-нибудь реактивную библиотеку, в результате лямбд стало не сто, а десять тысяч. И теперь, чтобы откопать три нужные лямбды, IDE надо перерыть в сто раз больше.
Я сказал «может быть», потому что, естественно, мы время от времени возвращаемся к этому поиску и пытаемся его ускорить. Но тут приходится грести даже не против течения, а вверх по водопаду. Мы стараемся, но количество лямбд в проектах растет очень быстро.




