
Разработка любого достаточно серьезного софта, будь то калькулятор матриц или ИИ беспилотного автомобиля, — это всегда какая-то своя предметная область, определенные технологии, алгоритмы и структуры данных, архитектура кода, процесс разработки и еще много разных умных терминов из мира IT.
В этой статье представлено одно из решений в мире высокой производительности и распределенных систем. Под катом вы найдёте описание всего лишь небольшого ряда задач и проблем, с которыми мы столкнулись, а также некоторые интересные алгоритмы, подходы к построению архитектуры системы, методы оптимизации запросов, ну и немного о процессе разработки и тестирования решения на базе Tarantool — платформы in-memory вычислений с гибкой схемой данных для эффективного создания высоконагруженных приложений.
Постановка задачи
В одном банке появилась задача ускорить выполнение запросов к Автоматизированной Банковской Системе (АБС).
Задача ставилась следующим образом. Имеется база данных АБС, к которой часто обращаются приложения-потребители, нагружают ее и получают большие задержки, средняя величина которых достигает 600 мс. Требуется разгрузить БД АБС. Для этого решили перевести часть запросов на кеш, способный выдавать задержки до 200 мс на 90-ом перцентиле (то есть не менее 90 % запросов к кешу должны выполняться быстрее 200 мс) при нагрузке в 1500 запросов в секунду. Запросы могут быть произвольные. Один запрос может содержать выгрузку многочисленных объектов и несколько JOIN-ов данных из разных таблиц. Количество объектов, предполагаемых для хранения в кеше, измеряется миллионами, поэтому одного инстанса кеша недостаточно, требуется распределенное хранение.
Выбор пал на in-memory БД Tarantool, а точнее на распределенное решение на его базе — Tarantool Data Grid (TDG, статья на Хабре), которое уже показало свою эффективность при разработке распределенных приложений. Коробочное решение с многочисленными реализованными механизмами, облегчающими разработку и позволяющими удовлетворить требованиям информационной безопасности, делает TDG очень удобным инструментом для реализации поставленной задачи.

Была принята следующая модель организации работы кеша: при первом запуске кеш заполняется данными из реплики БД АБС, после чего непрерывно отслеживает и применяет все изменения в базе. Такая организация была выбрана потому, что она удобна при работе кеша не с основной БД АБС, а с ее репликой, что позволяет избежать дополнительной нагрузки на основную БД. Недостатком такой схемы является то, что приложениям-потребителям необходимо отслеживать актуальность данных в кеше и время отставания реплики от основной БД, чтобы при необходимости обращаться напрямую к основной БД для гарантированного получения актуальных данных.
Основная сложность, которая возникает в указанной задаче, — это реализация синхронизации данных, включающей в себя:
- первоначальный импорт данных из реплики БД АБС в TDG;
- отслеживание изменений в реплике БД АБС и поддержка данных в TDG в актуальном состоянии.
Кроме того, необходимо обеспечить высокую производительно кеша, то есть обеспечить выполнение указанных SLA.
Архитектура решения
Синхронизатор
Чтобы разделить нагрузку на внешние запросы к TDG и на выгрузку данных из БД АБС, решили разработать отдельный компонент — синхронизатор данных. Он реализует всю логику по выгрузке данных из БД АБС, отслеживанию изменений в них и импорту в TDG. Для обеспечения быстрого импорта данных в TDG, а также масштабирования и отказоустойчивости синхронизатор разрабатывался как распределенное приложение, реализующее шаблон producer-consumer. Продюсер формирует идентификаторы объектов и кладет их в очередь (которая у каждого продюсера своя), консьюмеры берут идентификаторы из очереди, производят выборку объектов и отправляют их в TDG.
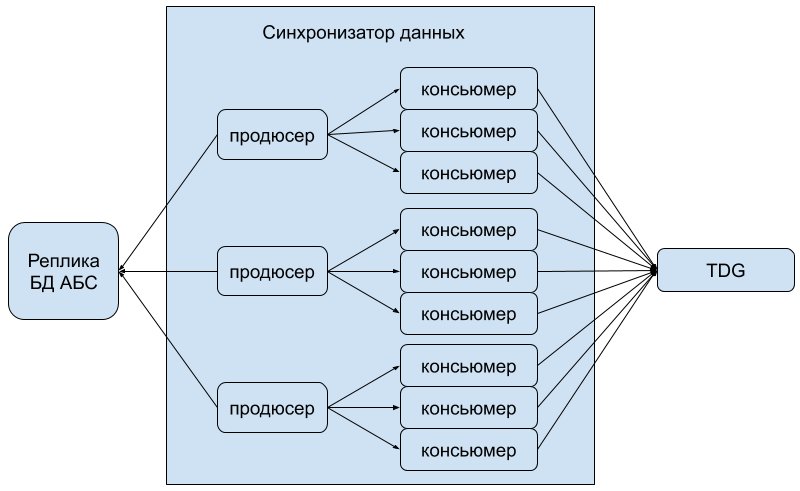
TDG
TDG, в свою очередь, также является распределенным решением. Систему можно гибко сконфигурировать, собрав ее как конструктор из компонентов, каждому из которых может быть назначена одна из предопределенных ролей. Для наших целей было достаточно создавать компоненты двух ролей: connector и storage. Connector предоставляет интерфейс для работы с внешним миром. В проекте используется graphql как для запросов от приложений-потребителей, так и от синхронизатора. Storage хранит данные, для их распределения по storage-ам используется шардинг. Можно использовать, например, nginx, чтобы распределять нагрузку между connector-ами, которые, в свою очередь, будут формировать запросы к storage-ам для выполнения нужных операций над данными.

Стоит отметить, что TDG позволяет гибко реализовывать обработчики запросов на языке Lua, предоставляя API для выполнения необходимых действий (например, map/reduce). Эта возможность позволила нам в дальнейшем оптимизировать запросы, основываясь на структуре самих запросов и модели данных.
Обеспечение актуальности данных
Синхронизатор должен обеспечивать выполнение двух задач:
- первоначальный импорт данных из БД АБС в TDG;
- синхронизацию операций создания/обновления/удаления элементов.
Первоначальный импорт необходим при первом запуске кеша, а также при сложных обновлениях модели данных. Также он может быть необходим, например, если данные берутся в кеш из реплики БД АБС и произошел hard reset реплики (то есть ее по какой-то причине дропнули, и инициализировали новую с мастера): в этом случае нет гарантии, что были учтены все обновления данных с момента отключения реплики и до ее перезапуска.
Для отслеживания обновлений можно использовать два механизма:
- Триггеры на целевых таблицах в реплике БД АБС, которые будут срабатывать на любые изменения, касающиеся объектов кеша.
- Специальные таблицы, в которые будут складываться объекты, готовые к отправке в кеш, с указанием временной метки последнего обновления.
В первом случае триггеры складывают измененные/удаленные объекты в отдельные таблицы, которые периодически проверяются и очищаются синхронизатором.
Во втором случае на стороне АБС должен быть реализован механизм наполнения таблиц; это могут быть хранимые процедуры или ПО, которые каким-то образом (например, периодическими запусками) отслеживают изменения в данных, формируют необходимые измененные/удаленные объекты и складывают их в эти таблицы.
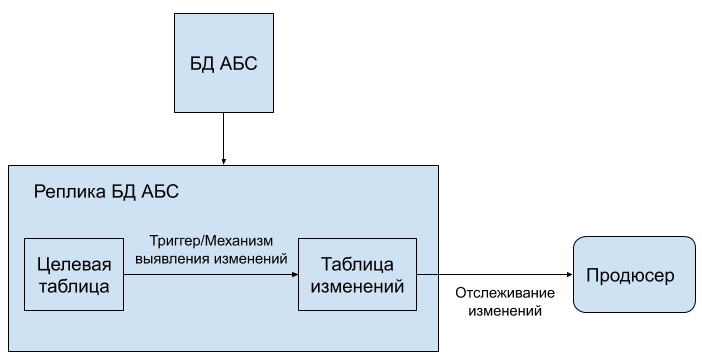
Продюсер в обоих случаях периодически выполняет запросы к таблицам, в которые складываются измененные данные, определяя идентификаторы вновь созданных/измененных/удаленных объектов. Эти идентификаторы затем передаются консьюмерам, которые формируют готовые объекты и отправляют их в TDG.
Борьба с состояниями гонки
При использовании шаблона producer-consumer могут возникать состояния гонки при обновлении данных. Представим, что какой-то объект обновился два раза с коротким интервалом между обновлениями, причем изменения были подхвачены разными консьюмерами. Из-за проблем с сетью консьюмер, который сформировал более раннюю версию объекта, может отправить ее в TDG позже другого консьюмера, в результате чего в кеше будет лежать некорректный, устаревший объект.
Для разрешения такой гонки в TDG используется версионирование объектов на основе временной метки обновления объекта. К каждому объекту в кеше добавляется поле с его версией, равной времени его последнего обновления. Когда объект формируется путем выполнения SQL-запроса в БД АБС, к результату добавляется временная метка, которая берется из самой БД. То есть у объекта, сформированного раньше, временная метка всегда будет меньше, чем у объекта, сформированного позднее (при условии линейности времени самой БД).

В TDG работает механизм, при котором объект с более поздней версией перезапишет объект с более ранней версией, но не наоборот. Такое же правило действует и при удалении: элемент физически не удаляется из TDG, а помечается как удаленный, с сохранением временной метки удаления. Таким образом решаются и состояния гонки при конфликтах обновления/удаления.
Версионирование объектов позволяет решить еще одну проблему, возникающую при вынужденном реимпорте данных. Предположим, что по некоторой причине произошло пересоздание реплики БД АБС. В основной БД АБС могли произойти изменения в момент пересоздания, которые уже не получится отследить с помощью триггеров. В этом случае запускается реимпорт данных, и объекты с новыми версиями перезаписывают объекты с устаревшими версиями. Однако некоторые объекты могли быть удалены, пока реплика пересоздавалась. Такие объекты можно удалить из кеша после того, как закончится реимпорт, удалив все элементы, версия которых не обновилась, то есть ее значение меньше временной метки начала реимпорта.
Отказоустойчивость
Одной из наиболее важных характеристик распределенной системы является возможность сохранять работоспособность при сбое любого из ее элементов. Тут следует руководствоваться правилом построения надежной системы из ненадежных компонентов: всегда стоит предполагать, что любой узел — инстанс базы данных, сервер, продюсер или консьюмер — может по той или иной причине прервать работу (это, конечно, не означает, что можно игнорировать такие падения).
Напомним, что как в синхронизаторе, так и в TDG имеются узлы двух типов. Консьюмеры в синхронизаторе и connector-ы в TDG являются узлами, не хранящими состояния. Если при большом количестве таких узлов возникают единичные отказы, то запросы будут направляться на другие узлы того же типа, что не приведет к существенной деградации работы системы, поэтому придумывать какие-то другие механизмы отказоустойчивости не требуется. Чтобы избежать полного отказа системы при падении физических серверов, следует иметь запас компонентов одного типа на разных серверах.
В TDG можно при конфигурировании топологии кластера создавать реплики для инстансов базы данных (storage-ей), что позволит не терять данные при сбоях. При этом рекомендуется размещать storage-и и их реплики на разных серверах для отработки случаев отказа одного из них.
Рассмотрим теперь, как реализуется механизм отказоустойчивости для продюсеров синхронизатора. Для каждого продюсера всегда запускается дублирующий продюсер-слейв. На реплике БД АБС создается вспомогательная таблица, которую периодически обновляет продюсер-мастер. Если в течение некоторого времени таблица не обновлялась, это замечает продюсер-слейв и перехватывает инициативу, становясь мастером. В таблицах БД АБС также можно хранить внутреннее состояние текущего продюсера-мастера, например, прошла ли первоначальная загрузка данных или на каком этапе она находится. При переключении новый мастер восстанавливает состояние и продолжает работу предшественника.
Высокая производительность на больших запросах
Tarantool является in-memory базой данных, позволяющей достичь большой производительности (несколько примеров: статья 1, статья 2, статья 3). Реальная производительность, обычно вычисляемая в количестве обрабатываемых запросов в секунду, зависит от многих факторов. Например, если мы хотим одним запросом вытащить всё содержимое базы из миллионов элементов, да еще и в структурированном виде, то вряд ли получится достичь миллиона таких запросов в секунду. В таких случаях ради получения требуемой производительности требуется проведение аналитических исследований для изменения структуры запросов и их оптимизации.
Оптимизация модели данных
Одной из особенностей решения является то, что модель данных кеша отличается от реляционной модели БД АБС. С одной стороны, можно полностью копировать все данные основной БД в кеш без изменения их структуры, что приведет к лишнему дублированию и фактически полному копированию запросов со всеми JOIN-ами реляционных объектов. В этом случае вряд ли удастся получить существенный выигрыш в скорости работы кеша относительно БД АБС. С другой стороны, в идеале для получения минимальной задержки в кеше должны храниться объекты «в готовом виде», возвращаемые по запросам без проведения каких-либо JOIN-ов. Такие объекты можно получить путем выполнения сложных SQL-запросов к БД АБС и кешированием результатов этих запросов в TDG.
Предположим, нужно получить высокую производительность на нескольких известных запросах. В нашем случае это были запросы со следующей упрощенной структурой:
- первый запрос: получить базовую информацию по картам некоторого клиента;
- второй запрос: получить полную информацию по указанной карте.
Пусть приложения-потребители запрашивают карты некоторого клиента (запросы первого типа). У этого клиента заведено, например, 20 карт. Если все они хранятся в кеше одним объектом, то ответ на запрос можно получить очень быстро (учитывая, что кеш — in-memory БД). Однако если изменятся данные по одной из карт, то придется полностью обновлять весь объект кеша.

Таким образом, необходимо найти баланс при разработке модели данных кеша, вставляя «полуготовые» объекты для более быстрого получения итоговых ответов на запросы. Как лучше всего сформировать такую модель — вопрос аналитики; нужно принять во внимание много факторов, таких как требования к максимальной задержке ответа, простоту реализации, структуру данных и запросов и т. п.
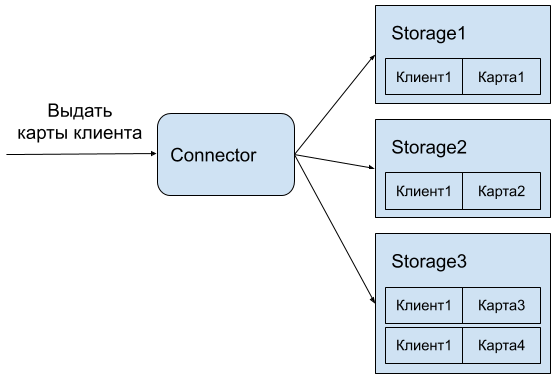
В нашем случае была выбрана модель хранения карт как отдельных объектов. После проведения денормализации вся информация размещалась в 3-4 таблицах (спейсах в терминологии Tarantool) из более чем десятка таблиц в БД АБС.
Однако денормализованная модель всё еще требует проведения JOIN-ов при выполнении запросов. Учитывая, что данные в TDG распределяются с помощью шардирования, каждый JOIN может привести к сбору кусочков объекта со всего кластера. Например, для упомянутого выше запроса карты клиента могут храниться на разных узлах кластера, и выполнение JOIN-а этих карт может занять много времени из-за большого количества сетевых обращений (особенно при большой нагрузке), что приведет к увеличению итоговых задержек получения ответа.
Отметим, что проведенная оптимизация позволила ускорить выполнение запросов до 200-300 мс для 90-го перцентиля при 1500 запросов в секунду (оценивалось на запросах поиска карт клиента), что еще не является достаточным для выполнения поставленной задачи. Стоит отметить, что запросы второго типа (получение информации по карте) выполнялись быстрее и показывали задержки в 20-30 мс при тех же условиях.
Оптимизация распределенных запросов
Продолжим рассматривать приведенный пример запроса «получить карты по клиенту». Как уже было упомянуто выше, в TDG имеется много storage-ей, и по умолчанию карты клиента будут разбросаны по распределенной системе. Сбор карт со всего кластера может занять существенное время, особенно при большой нагрузке на сеть. Логично было бы разместить все карты одного клиента на одном storage-е.
Распределение данных по storage-ам в TDG производится с помощью шардирования по первичному индексу или его части. Чтобы карты одного клиента попали на один storage, достаточно добавить в первичный индекс карт идентификатор клиента (изначально первичный индекс — поле идентификатора карты) и шардировать только по этому идентификатору. При выполнении запроса достаточно сделать один «заход» на storage по входному идентификатору и забрать оттуда все карты.

Такая оптимизация локального размещения карт позволяет существенно ускорить выполнение запросов указанного типа. В нашем случае ускорение было где-то на порядок: с >200 мс до 20-30 мс для 90-го перцентиля при 1500 запросов в секунду, если рассматривать только запросы поиска карт клиента. Стоит отметить, что данных в каждом запросе возвращалось действительно много: размер ответа на один запрос достигал нескольких сотен килобайт. Производительность запросов второго типа (выдача полной информации по карте) при этом осталась неизменной и достигала тех же 20-30 мс.
Описанная оптимизация возможна не всегда и налагает некоторые дополнительные ограничения. Первым важным моментом является необходимость отслеживания изменения идентификатора клиента у карты. Если у карты меняется владелец, то мы получаем объект с новым значением первичного индекса (напомню, что после оптимизации у нас имеется первичный индекс из двух полей, один из которых — идентификатор клиента). В этом случае необходимо дополнительно удалить предыдущий объект, так как TDG это уже не сделает за нас.
Также стоит отметить, что оптимизация была проделана исходя из конкретных особенностей запроса. Мы смогли ускорить один запрос, однако разных типов запросов может быть много, и в общем случае может оказаться невозможным ускорить все из них. Кроме того, при ускорении одних запросов другие могут, наоборот, замедлиться. Нужно искать баланс между требованиями к производительности различных запросов и возможностью их оптимизации. В общем случае, когда запросы изначально неизвестны или сильно различаются, проводить такие оптимизации не стоит.
Разработка
Разработка распределенной системы — задача непростая. Кроме необходимости высокой производительности и наличия механизмов масштабирования и отказоустойчивости, обычно имеется большой список функциональных требований, и не следует также забывать об удобстве эксплуатации.
Для обеспечения корректной работы функциональности мы все возникающие варианты использования покрывали тестами. В основном это были, конечно, интеграционные тесты, так как такие проверки требовали совместной работы различных элементов распределенной системы (БД АБС, синхронизатор, TDG). Тут не обойтись без современных средств автоматизации тестирования, таких как Docker, Pytest, continuous integration (CI) и т.п.
Кроме функциональных требований тесты очень помогают проверить и различные механизмы корректной работы распределенной системы. Например, надо убедиться, что смена продюсера-лидера происходит корректно — пишем тест. Если может возникнуть состояние гонки — пишем тест. Для проверки разрешения состояния гонок можно, например, описать репродюсер возникновения такого состояния и запустить его в небольшом цикле. При наличии CI этот цикл будет воспроизводиться достаточно часто, чтобы убедиться, что гонка не возникает.
Важным моментом является отсутствие flacky-тестов — которые «иногда падают» на CI. Их наличие зачастую показывает, что есть некоторые проблемы в тех или иных реализациях механизмов корректной работы распределенной системы, или, например, существует некоторое, пока не выявленное состояние гонки. Все такие тесты внимательно изучались, а причины их падения исправлялись.
Итого на таком, казалось бы, небольшом проекте сейчас более 200 интеграционных тестов.
Для удобства эксплуатации в системе реализовано большое число метрик. Это и низкоуровневые метрики, такие как количество используемой памяти, установленных соединений, объектов в БД, размеры очередей и т.п., так и более высокоуровневые, такие как гистограммы времени выполнения запросов на разных уровнях (запросы к БД АБС, запросы к TDG), количество выполненных запросов в секунду и т. п. Кстати, в Tarantool имеется Lua-модуль metrics, который позволяет собирать метрики в формате, пригодном для Prometheus, с последующим отображением графиков в Grafana. Практика показала, что все собираемые метрики могут быть важны для разбора инцидентов и исследования свойств работы системы.
Кроме метрик может быть полезно создавать конечные точки, которые, например, по HTTP-запросу выдают текущее состояние работы какого-нибудь компонента системы. Например, очень полезной является конечная точка, выдающая текущего продюсера-лидера.
Еще одним средством, позволяющим исследовать проблемы производительности, является трассировка запросов. В TDG имеется встроенная поддержка OpenTracing, которая активно использовалась при оптимизации запросов.
Выводы
Tarantool Data Grid позволяет «из коробки» сконфигурировать и настроить распределенный кеш и реализовать достаточно сложную логику его работы. Чтобы получить максимальную производительность, может потребоваться оптимизация запросов с учетом их особенностей на уровне архитектуры системы и модели данных.
В статье большое внимание уделено разработке синхронизатора — распределенной системы, обеспечивающей импорт и актуализацию данных в кеше. Масштабирование, отказоустойчивость, удобство эксплуатации, возникновение состояний гонок — вот ряд рассмотренных механизмов и проблем, которые могут возникнуть при построении подобных систем.
Из-за сложности разработки особое внимание уделялось тестированию как для функциональных требований, так и для корректной отработки различных механизмов работы распределенной системы. Добавление метрик и конечных точек, возвращающих состояние системы, позволили улучшить её сопровождаемость, а трассировка запросов позволила найти узкие места и улучшить производительность.
Ссылки
- Скачать Tarantool можно на официальном сайте.
- Получить помощь можно в Telegram-чате.
- Почитать, как Альфа-Банк сделал ядро инвестиционного бизнеса.




