В 2019 году в ОТР появился новый центр по работе с искусственным интеллектом (ЦИИ). Изначально он создавался как некий эксперимент по работе с новыми технологиями. Однако довольно скоро получил первую боевую задачу по автоматизации технической поддержки пользователей ГИИС «Электронный бюджет». Об этапах внедрения ИИ рассказали технический директор компании ОТР Анатолий Безрядин и сотрудники ЦИИ, принимавшие участие в амбициозном проекте.
Обращения в техподдержку представляют собой сложные технические заявки со множеством переменных — раздел, подсистема, нормативная документация, счёт и так далее. В некоторых случаях текст заявки мог составлять до 20 строк текста. Понять контекст подобной заявки порой сложно даже человеку, а для ИИ это и вовсе может стать неразрешимой задачей.
К списку трудностей добавились сжатые сроки для выполнения задачи, а также ограничения по используемым программным решениям. Так как мы работаем с государственными заказчиками, то можем использовать либо собственные наработки, либо open-source-решения.
Выбор типа нейронных сетей
Решение задачи по обработке обращений в техническую поддержку ГИИС «Электронный бюджет» мы начали с выбора подходящего типа нейронной сети. В качестве критериев выбрали скорость обучения, возможность масштабирования и качество обработки текста. Выбирали из четырёх вариантов.
Нейронные сети прямого распространения. Этот тип характеризуется передачей информации от входа к выходу. За счёт простоты и прямолинейности показывает высокую скорость обучения и хороший уровень масштабирования. Он подходит для прогнозирования и кластеризации, но качество обработки текста оказалось на низком уровне.
Рекуррентные нейронные сети. В этом типе нейросетей связи между элементами образуют направленную последовательность. Особенность заключается в возможности обрабатывать серию событий во времени или в пространственной цепочке. За счёт усложнённой структуры снижается скорость обучения, но зато сохраняется возможность масштабирования. Рекуррентные нейронные сети используют для распознавания речи, а также текста. Однако наши тесты показали, что качество обработки текстовых обращений в техподдержку не отвечало требованиям.
Градиентный бустинг. Техника машинного обучения, которая строит модель предсказаний с помощью нескольких предсказывающих моделей. В градиентном бустинге обычно используются деревья решений. Этот тип хорошо масштабируется и достаточно гибкий в плане использования. Например, его применяют для ранжирования выдачи поисковых систем. Скорость обучения и качество обработки текстов оказались не на высоте.
Свёрточные нейронные сети. Был разработан специально для эффективного распознавания изображений с помощью матриц. Требует гораздо меньшего количества настраиваемых весов, что ускоряет процесс обучения и развёртывания нейросети. Отличается хорошими показателями масштабируемости и высоким качеством обработки текста.
Свёрточные нейросети отвечали заданным требованиям. Выбор был остановлен именно на них.
Но для работы нейросеть нужно обучить, а также преобразовать текст обращений пользователя к специалистам техподдержки в цифры. Тут возникает проблема выбора предобученной модели. Мы сравнивали шесть, как нам казалось, подходящих моделей:
логистическая регрессия;
решающие деревья;
метод опорных векторов;
рекуррентные нейронные сети;
модели типа GPT;
модели типа BERT.
Первые три модели не могли проводить анализ последовательности и сложных областей, обладали низкой точностью и не умели переносить знания между доменами. От них мы отказались ещё на предварительном этапе обсуждений.

Необходимую точность показывали только модели типа GPT и BERT. Но у первой была низкая ресурсоэффективность, поэтому остановились на последней. К тому же модели типа BERT уже хорошо известны в отрасли и их использует, например, Google. Наличие развитого сообщество в перспективе позволяет оперативно решать возникающие вопросы.
Поиск подходящих библиотек
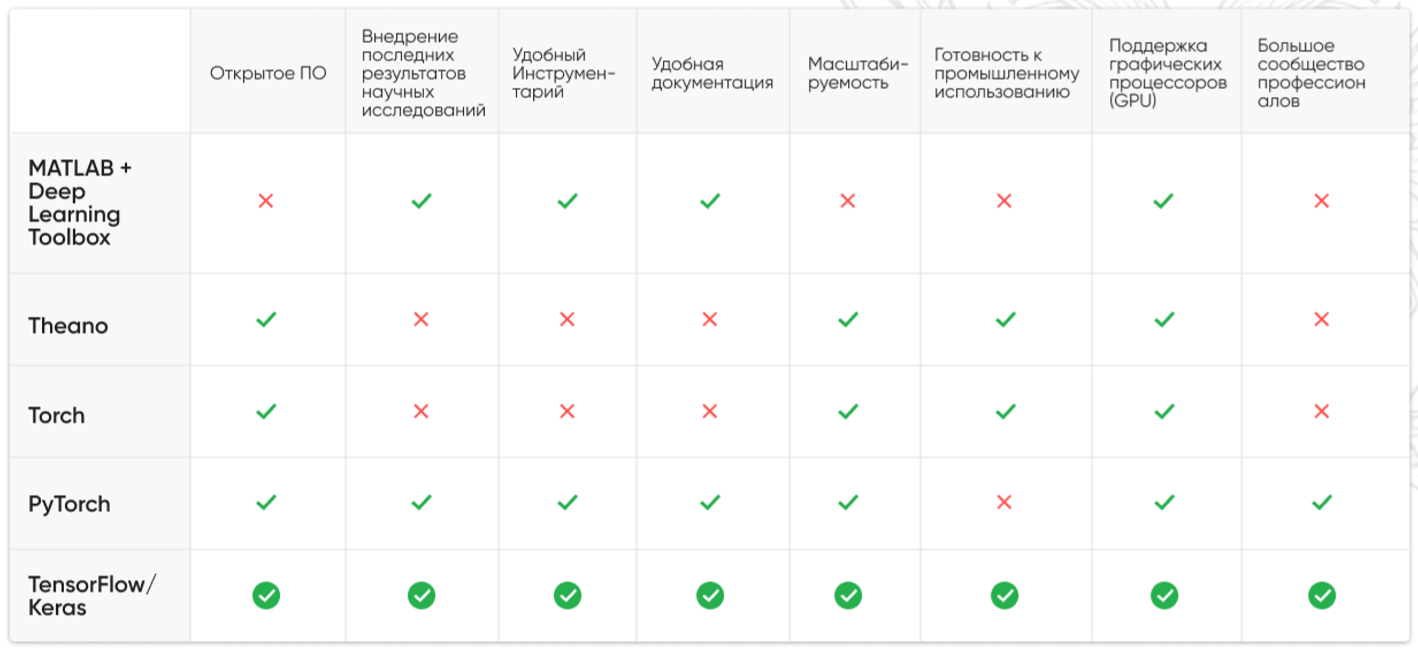
При поиске библиотеки для машинного обучения мы отталкивались от следующих критериев:
open-source-проект;
использование последних научных достижений;
удобный инструментарий и документация;
масштабируемость;
готовность к промышленному использованию;
поддержка графических процессоров;
большое сообщество профессионалов.
У нас получился такой список библиотек:
MATLAB + Deep Learning Toolbox;
Theano:
Torch;
PyTorch:
TensorFlow/Keras.
MATLAB — известный пакет прикладных программ для решения задач технических вычислений от The MathWorks. Изначально в нём не заложена функциональность по работе с нейронными сетями. Однако проблема решается надстройкой Deep Learning Toolbox. Она используется для проектирования, внедрения и предварительного обучения нейросетей.
Существенным минусом этого сочетания является закрытость кода. Особенность работы с госпроектами требует открытого кода, чтобы можно было убедиться в его безопасности. Кроме того, известно о проблемах с масштабируемостью и промышленным использованием.
Theano — библиотека для глубокого обучения и быстрых численных вычислений в Python. Её разработали в Монреальском институте алгоритмов обучения. Официально поддержка библиотеки закончена, но создатели поддерживают продукт для сохранения работоспособности.
К сожалению, Theano не предлагает удобной документации и инструментария. После отказа от развития библиотеки говорить о применении современных наработок в области нейросетей также не приходится.
Torch — библиотека для глубинного обучения нейронных сетей и научных расчётов. Создана группой энтузиастов на языке Lua. Она также применяется для проектов компьютерного зрения, обработки изображений и видеофайлов.
Как и в случае с Theano, библиотека Torch сейчас находится в полузаброшенном состоянии. Последние глобальные обновления кода были проведены четыре года назад. Недостатки её использования совпадают с предыдущим проектом.
PyTorch — библиотека для машинного и глубинного обучения от энтузиастов. Как понятно из названия, она создана на базе Torch. Однако написано уже на понятном для большинства разработчиков языке Python.
У PyTorch большое количество поклонников, она отличается полной документацией и удобным инструментарием, хорошо масштабируется. Но к промышленному использованию пока не готова.
TensorFlow — библиотека для машинного обучения, разработанная компанией Google. Она хорошо сочетается с надстройкой Keras, которая нацелена на оперативную работу с нейросетями глубинного обучения. Обе библиотеки регулярно обновляются и предлагают новые возможности для разработчиков.
Сочетание TensorFlow и Keras оказалось идеальным для решения нашей задачи. Они разработаны мировыми передовиками по работе с искусственным интеллектом, имеют понятную и богатую документацию, а также большое комьюнити разработчиков. Поэтому реализовывать проект мы начали с помощью инструментов Google.
ИИ в бою
Для работы с библиотеками Google TensorFlow и Keras у нас уже был готовый датасет из более чем миллиона обращений. Для узкоспециализированной системы — это большая цифра, которая равняется 10 годам работы службы технической поддержки.
После первоначальной настройки мы получили точность 75%. Для повышения точности удаляли шум в текстах. Для этого с помощью регулярных выражений находили определённые паттерны и избавлялись от них. Занимались оптимизацией архитектуры модели. Всё это позволило повысить точность до 85%.
ИИ ускорил работу с обращениями в службу технической поддержки ГИИС «Электронный бюджет». Пользователи оценили удобство и скорость реакции на запросы. Обслуживающие специалисты смогли сконцентрироваться на более сложных заявках по решению проблем.
Для центра по работе с искусственным интеллектом это была дебютная задача, с которой удалось эффективно справиться. Сейчас команда решает задачи по внедрению нейросетей и машинного обучения на других проектах, используя выработанный алгоритм.



")