
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Советов «как ускорить веб-приложение» в интернете немало. Но при попытке применить их на деле может вспоминаться мем «делойте хорошее а плохое не делойте». Ситуации очень различаются, и универсальные рецепты плохо подходят.
Поэтому на нашей конференции HolyJS Наталья Стусь поделилась тем, как выглядела работа над производительностью не в «вакууме», а конкретно в случае Авто.ру. Конечно, поскольку всё индивидуально, вы не сможете тут же сделать всё в своём проекте «точно так же». Но вот извлечь какие-то полезные принципы и понять, на что обратить внимание, вполне можно. Участникам конференции доклад понравился, и теперь для Хабра мы сделали его текстовую версию (а для тех, кто предпочитает видео, доступна запись).
Далее повествование — от лица Натальи.
Последние полтора года я занимаюсь перформансом проекта Авто.ру. И сегодня хочу рассказать о концепции, к которой я пришла за это время, — как работать над перформансом, как искать проблемы и находить решения. Сначала расскажу немного истории и про саму концепцию, потом приведу примеры, а в конце перечислю инструменты, которые я использовала.
Примерно полтора года назад мне пришла задача. Если измерить производительность сайта Авто.ру с помощью Lighthouse, то мы получим определенное число. Его надо улучшить, чтобы оно стало как можно ближе к 100.

Не очень понятная постановка задачи, да? А что мы обычно делаем, когда приходит непонятная задача? Идем в поисковик искать ответы на наши вопросы. Я нашла статью, в которой хорошо описаны все метрики и улучшения.
Там нашлось более 20 советов:

Какие-то у нас и так уже были внедрены. Какие-то были неприменимы к нашему проекту. Какие-то были немного странными: «уменьшите время ответа сервера» — ну спасибо, а как именно-то? Но все они довольно базовые и абстрактные, так что не сильно меня вдохновили.
Затем я решила посмотреть, как обстоят дела у других. Нашла в интернете несколько кейсов ребят из VK, Авито и других компаний. Но в основном там были описаны решения, которые подходят только под конкретные проекты. Одни ребята добавили скелетоны, и это сработало. Но у нас они уже давно есть. Кто-то перешел с одного фреймворка на другой. Окей, но мы свой фреймворк любим и уходить с него не хотим (ну и это очень дорого).
Тогда остается думать, экспериментировать, находить и устранять проблемы. За полтора года хаотичного поиска проблем я смогла составить концепцию, с помощью которой можно совершенствовать перфоманс приложений.
Основная идея — идти не от метрик, как это советуют обычно в статьях, а от того, как работает само приложение. Декомпозировав его работу, вы сможете разбираться отдельно с каждым конкретным этапом.
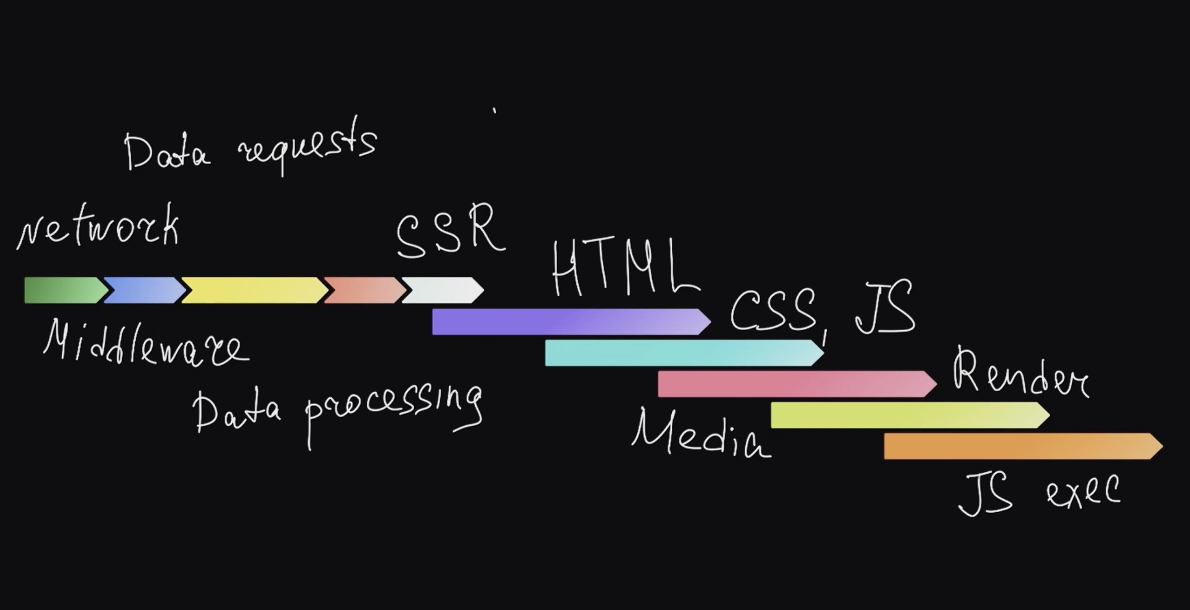
На Авто.ру у нас получилась примерно такая схема из этапов, которые проходят в нашем приложении от момента запроса пользователя до завершения рендеринга:
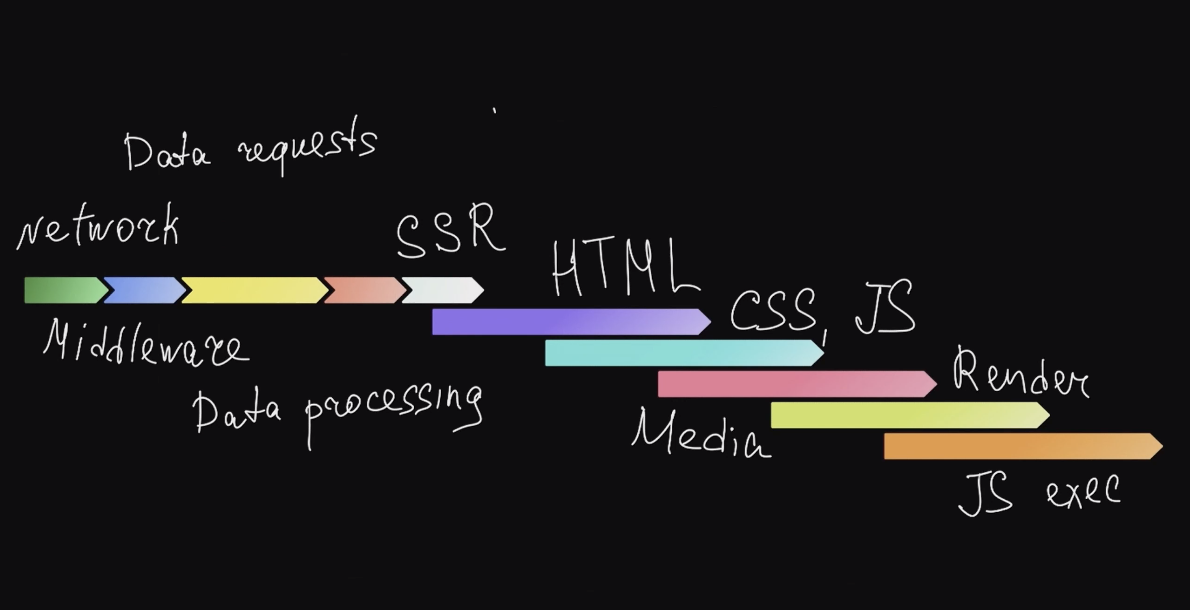
Серверная часть — это сеть, middleware, запрос данных, обработка данных и SSR. А на клиентской части скачиваются HTML, CSS, JS, рендерятся картинки, выполняется JS. Это относительная схема — в клиентской части всё не именно так накладывается друг на друга. Ну и у каждого проекта схема будет своя.
На этой схеме можно понять, где появляются Web Vitals — основные метрики жизнеспособности нашего сайта:
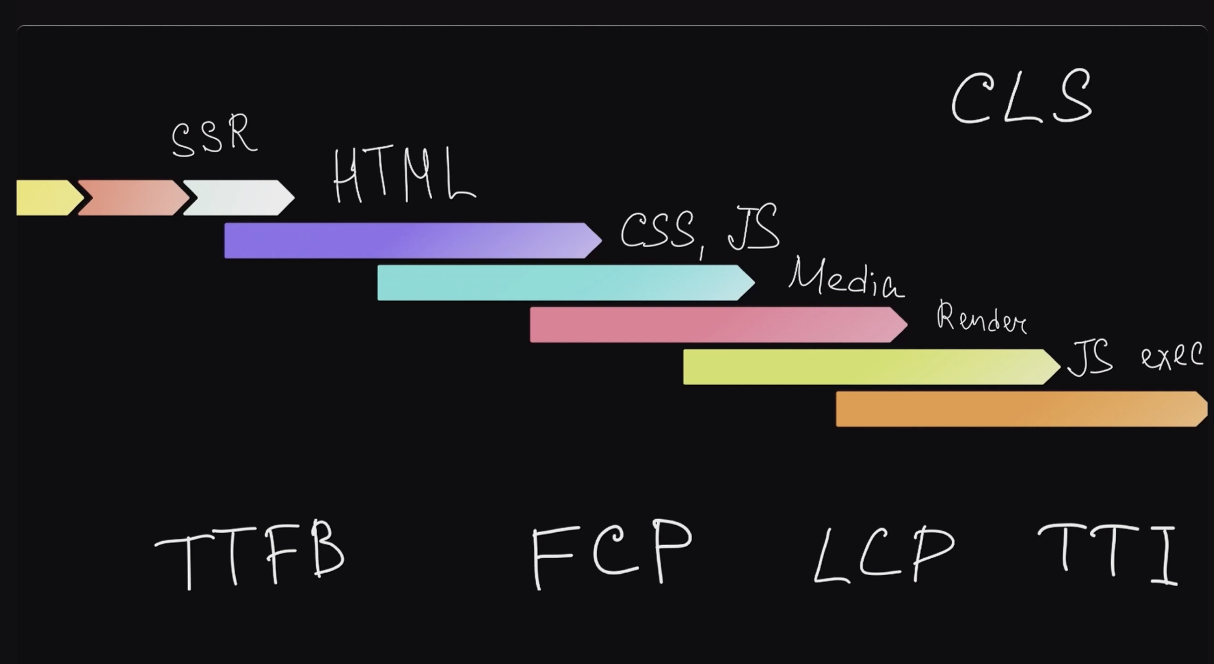
Где-то в конце отработки серверной части появляется метрика Time to First Byte (TTFB) — когда пользователь начинает получать данные от нашего сервера.
В начале рендеринга появляется метрика First Contentful Paint (FCP) — когда на экране у пользователя появляется что-то значимое (текст, иконки и т.д.)
Largest Contentful Paint (LCP) — это когда пользователь уже видит большой кусок текста, большое видео или что-то другое, за чем он, скорее всего, и пришел на вашу страницу.
Time to Interactive (TTI) — время, за которое пользователь может начать взаимодействовать с вашим приложением: нажимать кнопочки, вводить текст и т.д.
Отдельно стоит метрика Cumulative Layout Shift (CLS) — это не время, а параметр, который показывает, насколько отрисовавшийся контент смещается в процессе дальнейшего рендеринга. Это может приводить к визуальным неудобствам или мискликам.
Пример замеров одной из наших страниц:
Расскажу, как работать с этой схемой. Мы будем смотреть на каждый этап работы приложения и задавать разные вопросы, например: «можно ли этого не делать?», «можно ли это сделать раньше или позже?» или «можно ли сократить этот запрос?».
Первый этап — сеть. Но поскольку это не совсем зона ответственности фронтенд-приложения, мы пропустим этот этап и перейдем к следующему.
Middleware

Если у фронтенд-приложения есть серверная часть, то ещё до начала сбора данных для страницы там могут быть задействованы middleware-составляющие.
Как оценить время их работы? Можно всё залогировать, а можно сделать трейсы — это более удобная визуализация. Я покажу на примере одной из страниц Авто.ру, как выглядит трейс:
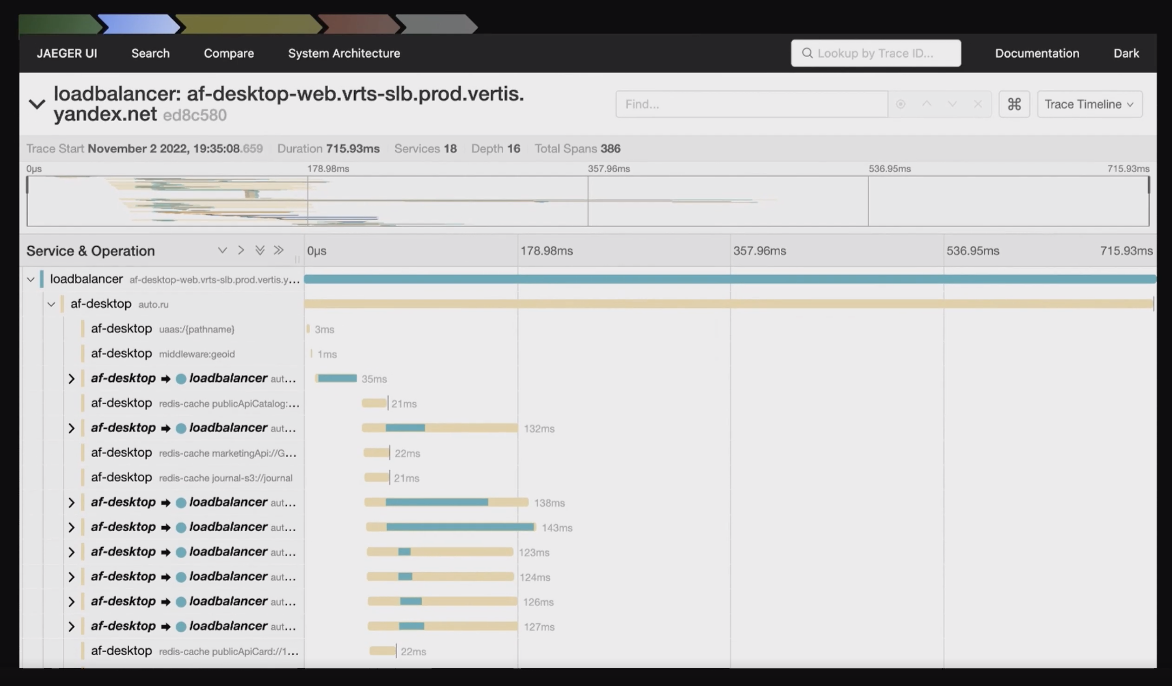
Здесь вся серверная часть для одной из страниц Авто.ру представлена в виде таких трейсиков, видно время выполнения каждого элемента. В данном случае это трейс страницы листинга объявлений на Авто.ру. Наш листинг – это страница с результатами поиска по объявлениям:
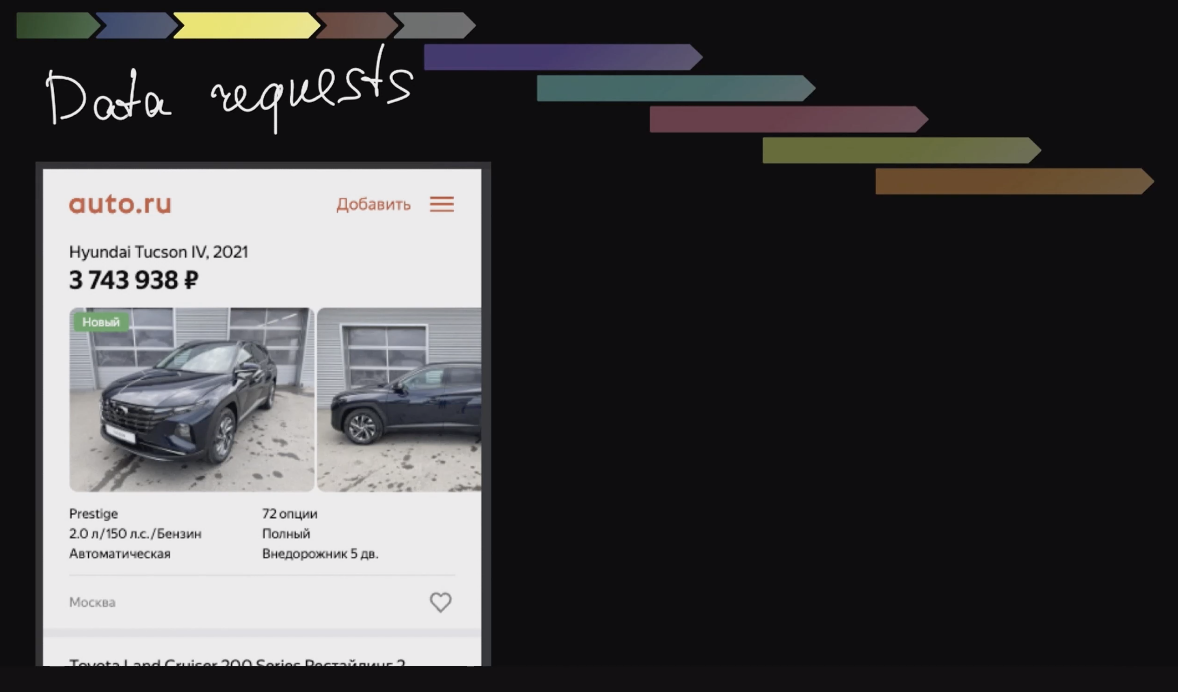
Чтобы нарисовать ее, надо сделать много разных запросов, что видно по трейсам. И в числе прочего для этой страницы есть трейс middleware:

Здесь видно, что запрос выполняется очень быстро и оптимизировать особо нечего. Однако эта штука блокирует всю дальнейшую серверную часть, и если вы увидите, что у вас Middleware выполняются достаточно долго, то можно покопаться и посмотреть, что там происходит.
Запросы данных

Теперь перейдем к запросам данных. В нашем случае эта часть очень объемная и самая долгая, потому что у нас много данных собирается по разным сервисам, бэкендам, эндпоинтам. Что я предлагаю сделать? Взять трейс или лог и посмотреть на самые длинные спаны. Но неплохо посмотреть и на более короткие — как минимум, если вы увидите, что там есть что-то ненужное, то сможете это убрать и снизить нагрузку на сервер. А на какой-то другой странице они вам и перфоманс могут улучшить.

В моем случае я нашла интересную вещь:

Спан внизу за 393 миллисекунды — это запрос самих объявлений, которые мы показываем на странице листинга. Но еще есть спан на зловещие 666 миллисекунд. Я стала разбираться, что это такое, и выяснила, что этот запрос на вдвое большее число объявлений, чем мы отображаем на странице, он нужен для показа блока с другими конфигурациями данной машины. Мы поговорили с продакт менеджерами и поняли, что этот блок можно немного урезать, и в итоге смогли просто убрать долгий запрос. Получили неплохой прирост в скорости.
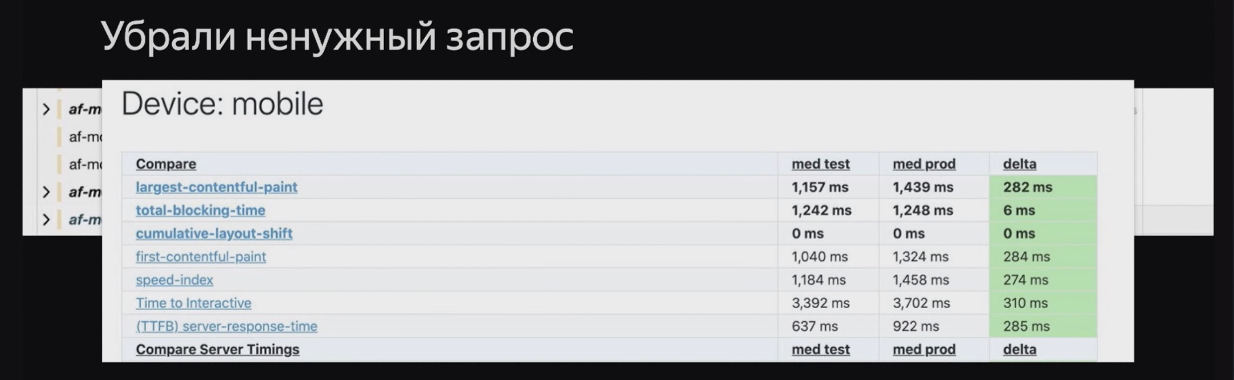
Это результаты тестов, где сравниваются две версии, — до изменений и после. Получилась довольно большая разница в 258 миллисекунд в TTFB. А вот так выглядел график запросов на пользователях (смотреть на синюю линию):
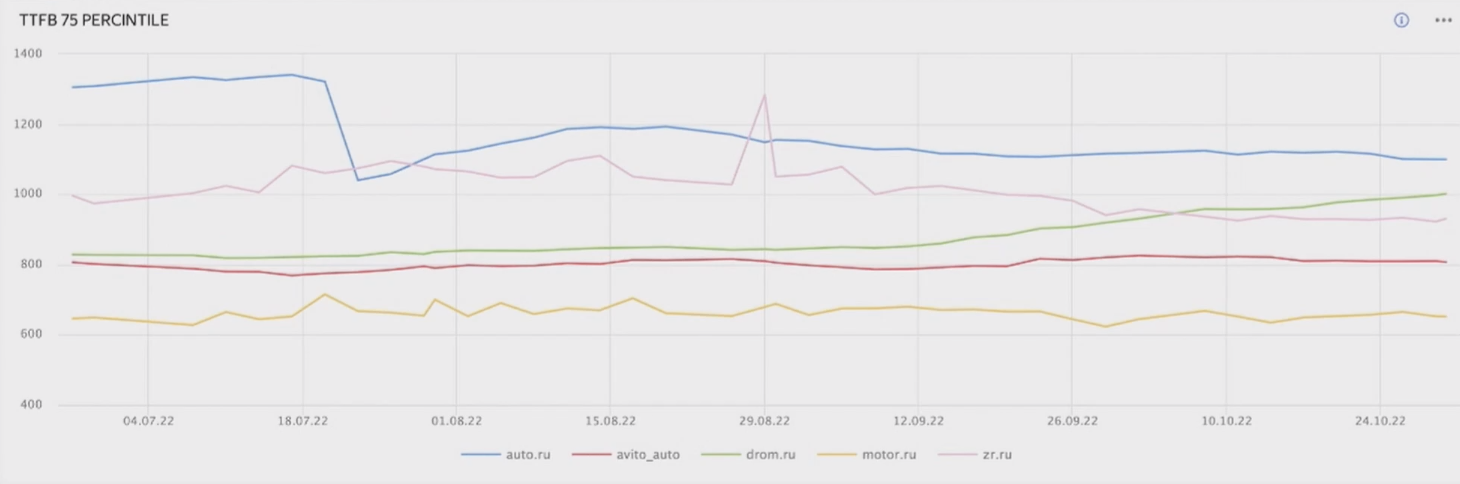
Но бывает и так, что мы убираем ненужный запрос, а график не меняется:
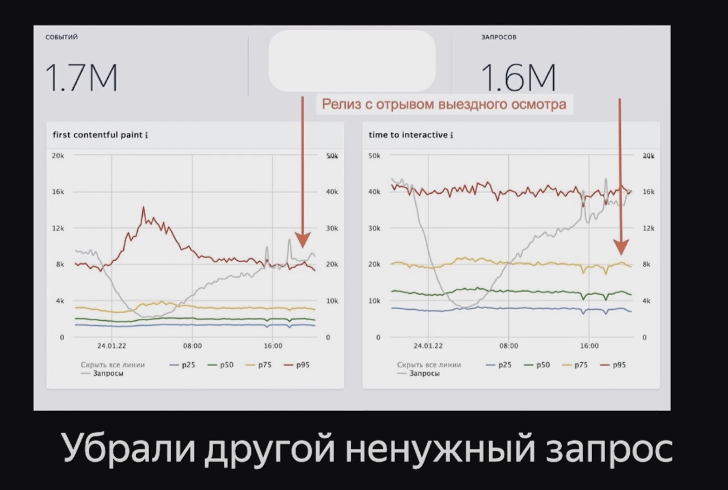
Или меняется совсем другой график
Интересные статьи
Интересные статьи

 не разросшееся приложение (Часть 1)")

 файла в 1С-Битрикс")