
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

За последнее десятилетие технология распознавания лиц сделала большой шаг вперёд — и в то же время стала предметом очень многих споров и обсуждений. В интернете можно найти огромное количество заметок и статей о том, как устроено распознавание лиц, зачем его внедряют и насколько хорошо или плохо оно работает. И, как это всегда и бывает, во всём этом объёме информации весьма непросто разобраться и отделить правду от досужих домыслов, особенно, если не обладать соответствующим бэкграундом. Скажем, один автор может утверждать, что сегодняшние нейросети умеют совершенно безошибочно определять нужного человека в большой толпе, другой — приводить примеры курьёзных ляпов искусственного интеллекта, а третий — раскрывать секретные способы гарантированно обмануть алгоритм распознавания.
А как же обстоят дела на практике? Чему вообще верить?
Мы, команда NtechLab, постараемся понятным языком рассказать, из чего на самом деле состоят самые современные алгоритмы распознавания лиц, с которыми каждый из нас сталкивается в повседневной жизни, порассуждаем, на что они способны и на что — пока нет, и попробуем ответить на вопросы о том, когда технология работает хорошо, а когда плохо, и от чего это зависит.
Как всё устроено
Что на входе, что на выходе
Погружаться в устройство системы распознавания лиц предлагаем постепенно. Для начала нам будет проще всего представлять её чёрным ящиком, который на вход принимает изображение (это может быть кадр из видео или фотография), а на выходе возвращает некоторый набор вещественных чисел, который «кодирует» лицо. Этот набор часто ещё называют «вектором признаков» (и он фактически является вектором) или «биометрическим шаблоном».
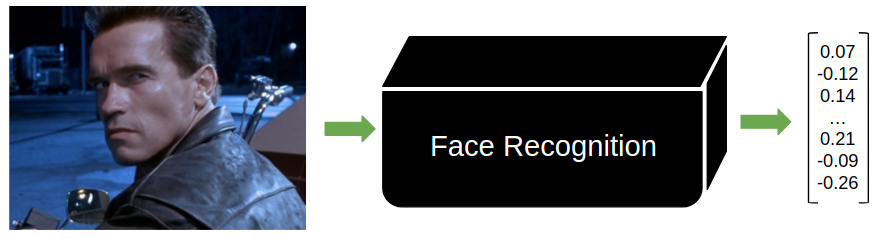
Размерность этого вектора у каждой системы может быть своя, обычно это некоторая степень двойки: 128, 256 или 512. Какой бы ни была размерность, норма вектора равна единице:
для вектора  будет справедливо
будет справедливо 
Это означает, что все возвращаемые системой векторы лежат на N-мерной гиперсфере, где N — размерность вектора. Представить себе такую гиперсферу довольно сложно, поэтому — опять-таки, для простоты — прибегнем к известному совету Джефри Хинтона о визуализации многомерного пространства:
To deal with hyper-planes in a 14-dimensional space, visualize a 3-D space and say “fourteen” to yourself very loudly. Everyone does it. (Когда вам предстоит иметь дело с гиперплоскостями в 14-мерном пространстве, представьте его себе трёхмерным и громко скажите: «Четырнадцать!» Все так поступают.)
Итак, пусть у нас есть привычная нам трёхмерная сфера и трёхмерные векторы на ней, которые, как мы помним, и есть закодированные лица:

Эти векторы обладают следующим свойством: если мы попробуем дважды закодировать одно и то же изображение лица, мы получим два одинаковых вектора — угол между ними будет равен нулю, а чем сильнее будут различаться лица, тем дальше друг от друга они будут лежать на сфере и тем больше будет угол между ними. Это означает, что для определения «похожести» двух лиц нам достаточно измерить угол между их векторами; удобнее всего в качестве меры схожести использовать косинус угла, а не сам угол (не забываем, что все вектора имеют норму, равную 1):

А для ещё большего удобства перепишем меру схожести таким образом, чтобы она изменялась на интервале [0; 1]:

Система распознавания лиц не может нам сказать, что на некоторой фотографии изображён условный Иванов И. И. (или наоборот, что на фото совсем не Иванов) — она работает по-другому. Мы можем взять реальное фото Иванова и при помощи системы построить для него вектор признаков. В дальнейшем этот вектор можно будет сопоставить с вектором исследуемого изображения и узнать меру их схожести.
Детектор
Теперь будем постепенно открывать чёрный ящик. Первым делом, получив на вход картинку, алгоритму нужно отыскать на ней лица людей. За это отвечает компонент, называемый детектором, и его задача — выделить области, в которых содержится нечто, напоминающее лицо.
До некоторых пор эту задачу решали методом Виолы — Джонса или при помощи HOG-детекторов, однако сегодня нейронные сети вытеснили их практически повсеместно — они точнее, менее чувствительны к ракурсу съёмки (наклонам, поворотам и тому подобному) и куда более стабильны в своих предсказаниях, чем классические методы. Даже скорость работы, которая традиционно считалась ключевым преимуществом «классики», сегодня перестала быть проблемой для нейросетей: с тем огромным объёмом доступных данных для обучения и развитием вычислительных ресурсов можно без проблем подобрать такой размер нейросети, который удовлетворит вашим запросам.
Нормализатор
Лица, которые возвращает детектор, всё ещё пребывают в своём естественном положении: как-то повёрнуты, как-то наклонены — а ещё они все, конечно, разного размера. Чтобы на следующих этапах нам было проще их обрабатывать и сравнивать, стоило бы привести их к некоторому универсальному виду. Эту задачу решает компонент системы, который называется нормализатором.
В идеале, мы хотели бы работать только с фронтальными изображениями лица, для чего, в свою очередь, необходимо уметь преобразовывать любое полученное системой, изображение к фронтальному типу, причём преобразовывать просто и быстро, не прибегая к 3D-реконструкции и прочему «ракетостроению». Разумеется, магии не существует, и легко привести любое лицо к фронтальному невозможно, однако мы всё ещё можем попытаться получить изображение, максимально приближённое к фронтальному, — насколько это возможно для имеющейся картинки. В нашем распоряжении имеются три инструмента:
scale: мы можем «приблизить» или «отдалить» лицо;
rotation: мы можем повернуть лицо на любой угол в плоскости изображения;
shift: мы можем сместить лицо на несколько пикселей влево или вправо, вверх или вниз.
Каждое из этих преобразований описывается матрицей 3×3. Перемножив все три матрицы, мы также получим матрицу 3×3 для суммарного преобразования — его необходимо применить к лицу для приведения к нужному нам виду:

Одним из способов определения преобразования может быть следующий: найти ключевые точки лица (центры глаз, кончик носа) и вычислить такую матрицу, в результате применения которой кончик носа окажется по центру изображения, а глаза выровняются на одном горизонтальном уровне. Способ довольно простой, однако, во-первых, он сильно зависит от качества детектирования ключевых точек, а во-вторых, нет гарантии, что описанные выше эвристики являются оптимальными для распознавания.
Альтернатива, как вы уже, вероятно, догадались — снова нейросеть. С её помощью мы можем предсказать итоговую матрицу преобразования напрямую, не отыскивая ключевые точки и не делая каких-либо предположений о расположении носа и глаз. Именно пример работы нейросетевого нормализатора показан на рисунке выше (точки мы нанесли просто для иллюстрации).
Экстрактор
Теперь, когда у нас есть нормализованное лицо, настало время строить вектор — этим занимается компонент, называемый экстрактором, основной элемент всей системы. Он принимает на вход картинки фиксированного разрешения — обычно 90–130 пикселей, такой размер позволяет соблюсти баланс между точностью работы алгоритма и его скоростью (картинка большего разрешения могла бы содержать больше полезной для распознавания информации, но и обработка её выпонялась бы дольше).
Экстракция вектора — завершающий этап пайплайна обработки лица, который можно схематически изобразить следующим образом:

Обучение экстрактора
Главное, чего мы ждём от хорошего экстрактора — чтобы он строил как можно более «близкие» векторы для схожих лиц и как можно более «далёкие» — для непохожих. Для этого экстрактор нужно обучить, а для обучения первым делом нам понадобится датасет — набор размеченных данных. Выглядеть он может примерно так:

То есть, у нас есть некоторое множество уникальных людей — «персон» (Персона k и Персона m — это разные люди, если m ≠ k ), и для каждой из них есть некоторое множество картинок. При этом мы точно знаем, на какой картинке какая персона.
Сколько персон нам нужно для обучения? И сколько фотографий для каждой персоны? Напрашивается очевидный ответ: чем больше, тем лучше. Самые крутые системы обучаются на датасетах в миллионы, а то и в десятки миллионов персон, а вот фотографий на каждую из них нам будет достаточно пяти–десяти (да и персона с единственной фотографией может оказаться полезной для обучения), но опять же: больше — лучше. В наши дни в интернете можно найти большое количество публичных датасетов, а иные исследователи собирают для обучения фотографии знаменитостей.
При формировании обучающей выборки следует принимать во внимание тот факт, что экстрактор (на самом деле, это справедливо для любой нейросети) всегда будет лучше работать на данных, похожих на те, на которых он учился. Если в нашем датасете будут только представители европеоидной расы, есть большой риск, что результаты для лиц азиатского типа или темнокожих рас нас разочаруют — а значит, нужно постараться сделать обучающую выборку как можно более разнообразной.
Часто задаваемые вопросы
На что похожи признаки, которые определяет нейросеть? Чем руководствуется алгоритм при построении вектора? Может ли вектор сам по себе что-то сказать нам о внешности человека? И — вишенкой на торте: на какие именно части лица обращает внимание алгоритм? Пожалуй, ни о чём другом нас не спрашивают так часто, как об этом. На самом деле, это всё очень хорошие вопросы, и они сильно интересуют не только обывателей, но и самих исследователей — разработчиков нейросетей.
Если попросить простого человека описать приметы некоторого лица, он наверняка назовёт разрез и цвет глаз, особенности причёски и растительности на лице, длину носа, изгиб бровей… Тренированный физиогномист (например, пограничник, который проверяет ваш паспорт в аэропорту, или криминалист, специализирующийся на портретной экспертизе) оценит расположение антропометрических точек и ключевые расстояния между ними. Так же и нейросеть: она, безусловно, «обращает внимание» на характерные особенности лица, однако нужно понимать, что каждое из чисел, составляющих вектор признаков, не отвечает за какую-то конкретную точку или черту лица. Мы не можем, взглянув на числовое представление вектора, указать, что вот этот его участок описывает глаза, а вот тот — форму носа. (Между тем, дальше в этой статье мы проиллюстрируем ряд экспериментов, которые раскроют, насколько сложно нейросети узнать человека, не видя, например, его глаз или рта).
Итак, для ручного анализа вектор непригоден. В то же время, существует немалое количество научных исследований, авторы которых пытаются восстановить внешность человека, располагая вектором признаков. Среди них упомянем работу учёных из Канады и США Vec2Face. Суть предлагаемого ими решения, если излагать её максимально упрощённо, такая: для генерации изображения из вектора признаков будем использовать специальным образом устроенную нейросеть, а датасет для её обучения получим, прогнав большое количество фотографий через экстрактор и сохранив полученные векторы.
Авторам удалось получить весьма приемлемый результат:

В самом нижнем ряду на иллюстрации показаны реальные фото, а над ними — картинки, которые удалось синтезировать из их векторов, используя разные методы восстановления. Посмотрите сами: изображения в третьем и четвёртом рядах довольно близки к реальности!
Однако нужно понимать, что применение описанного подхода на практике будет очень сильно затруднено. Во-первых, процесс разработки алгоритма восстановления достаточно сложен, требует серьёзных вычислительных ресурсов и значительных затрат времени. Во-вторых, для создания алгоритма исследователям потребуется неограниченный доступ к экстрактору — а от этого не так уж и сложно защититься. В-третьих, для каждого нового экстрактора нужно обучать модель восстановления заново, невозможно создать универсальный алгоритм, который будет способен «инвертировать» любой экстрактор. В-четвёртых (и, наверное, в самых главных), далеко не факт, что для какого-то конкретного экстрактора в принципе получится создать алгоритм восстановления хорошего качества.
Как всё работает на практике
В теории каждый элемент пайплайна хорошо обучен под свою задачу. Однако, когда мы начинаем объединять их в одну систему и применять к реальным данным, могут возникнуть некоторые непредвиденные проблемы.
Оцениваем качество изображения
Начнём с того, что наш детектор может ошибочно распознать лицо там, где его нет. Или распознать правильно, но изображение окажется плохого качества: очень маленького размера или повёрнутое под очень большим углом, или сильно смазанное, или очень тёмное, или всё это сразу. Тем не менее, раз лицо найдено, оно пройдёт весь пайплайн и получит вектор — вот только применить его будет нельзя. В случае с некачественным лицом вектор получается очень шумным и неточным, а при ложном срабатывании детектора он и вовсе не несёт какой-либо полезной информации, а значит, использовать такие векторы для сравнения нет никакого смысла.
Нам нужен какой-то механизм, который позволит передавать экстрактору только качественные картинки. В NtechLab мы используем дополнительную легковесную нейросеть — детектор качества, которая возвращает интегральный показатель в диапазоне [0; 1], позволяющий сделать вывод, насколько «хорошее» изображение выдал детектор. Если измеренный показатель качества будет ниже некоторого установленного порога, такое лицо будет отбраковано, а двигая этот порог, мы получаем возможность тонкой подстройки системы к фактическим условиям съёмки.

Помимо отсеивания мусорных картинок у детектора качества есть ещё одно применение. Когда нам нужно распознавать лица на видео, для каждого человека в поле зрения камеры мы получаем последовательность кадров — трек, который будет тем длиннее, чем дольше человек находится перед объективом. Чтобы оптимизировать работу системы, мы не будем строить вектор для каждого кадра, всякий раз запуская довольно «тяжёлый» экстрактор. Вместо этого при помощи нашей легковесной сетки выберем из всего трека лицо с наивысшим показателем качества — и вот уже из него извлечём единственный шаблон.
Здесь мы не будем останавливаться на том, как обучить хороший детектор качества — эта тема заслуживает отдельной большой статьи. Для иллюстрации дадим несколько примеров лиц и показатель качества, предсказанный детектором для каждого из них:

Работа в сложных условиях
Настало время экспериментов: предлагаем проверить, как поведёт себя система распознавания лиц в различных условиях. Для этого у нас есть небольшой тестовый датасет примерно на 2000 персон, для каждой персоны он содержит снимки, сделанные с поворотом или наклоном головы, с разным освещением, в очках, в медицинской маске и так далее. Мы будем сравнивать работу двух алгоритмов: разработанного нами и одну из лучших публично доступных реализаций — Insightface.
Положение головы
Оценим, как влияет на качество распознавания поворот головы. Для каждого человека из датасета мы посчитаем схожесть для двух его фотографий: фронтальной и с изменением положения головы в различных плоскостях.
Для начала рассмотрим повороты влево и вправо:

В первом ряду показаны пары картинок, которые сравниваются. Верхняя гистограмма — распределение схожестей для двух алгоритмов. В идеале хотелось бы, чтобы пик распределения был ближе к единице, ведь во всех сравниваемых парах — один и тот же человек. Нижняя гистограмма — распределение качества картинок, полученного детектором качества для фронтальных и повёрнутых лиц.
Давайте построим такие же гистограммы для отклонения головы назад:

...и вперёд:

Первое, что бросается в глаза: распределения схожестей у двух алгоритмов, проприетарного и публичного, сильно различаются. (Отметим, однако, что по одним этим гистограммам нельзя с уверенностью сказать, какой алгоритм лучше и насколько — об этом мы поговорим чуть позже).
Второй вывод: сценарии с наклонами вперёд–назад для обоих алгоритмов оказались сложнее, чем повороты влево–вправо. Отчасти это может быть связано с тем, что в тестовой выборке углы поворота в сторону невелики и лицо всегда видно почти полностью.
Также отметим, что качество картинки во всех рассмотренных здесь случаях оказалось приемлемым (предсказанный показатель — больше 0,5).
Освещение
А что насчёт темноты? Посмотрим, как алгоритмы ведут себя в условиях недостаточного освещения:

На этом примере хорошо заметно, насколько отличается восприятие картинки человеком и нейросетью: если человеку такое затемнение сильно мешает при распознавании, то для нейросети оно не столь критично. Качество картинок при этом тоже уменьшилось незначительно.
Элементы маскировки
Как повлияют на распознавание медицинские маски, солнечные очки и шапки?



Можно заметить, что наличие головного убора, который не закрывает лицо, практически никак не влияет на работу алгоритма. Объясняется это тем, что верхняя часть головы попросту не попадает в экстрактор, она отсекается ещё детектором и нормализатором, так как не нужна для распознавания. Значит, можно даже перекрашивать волосы в любой цвет — на распознавание нейросетью это мало повлияет.
Зато видно, что серьёзную сложность представляют медицинские маски — и это логично: маска закрывает большую часть лица. Однако, как видно из гистограммы, современным алгоритмам для распознавания вполне достаточно и оставшегося изображения.
Всё сразу
А что будет если, надеть всё сразу?

Вот где начинаются настоящие сложности! Даже сильный алгоритм теперь уже не так уверен. И, если мы обратим внимание на распределение качества картинок, заметим: большая часть изображений признаются нежелательными для распознавания.
Но не будем останавливаться и ещё сильнее усложним задачу, добавив освещение и поворот:

Для человека распознавание в таких условиях просто невозможно, а что же нейросеть?
Для неё всё тоже довольно печально. Во-первых, на более чем 10% изображений вообще не удалось найти лицо, то есть распознавание закончилось, так и не начавшись. Картинки, на которых лицо всё-таки обнаружилось, имеют настолько низкое качество (нижняя гистограмма), что адекватная работа алгоритма на них вряд ли возможна.
Оценка качества
Что ж, вот мы и победили современный искусственный интеллект в рамках нашего датасета! Осталось выяснить только одну деталь: насколько велика разница между проприетарным и публичным алгоритмом? Чтобы получить объективный ответ, первым делом нужно понять, как померить «качество» работы алгоритма.
(Всё, что будет изложено далее в этой главе, по сути является кратким пересказом нашей статьи четырёхлетней давности.)
В принципе, все возможные сценарии биометрического сопоставления можно свести к двум — верификации и идентификации:
верификация (она же сопоставление 1:1) представляет собой сравнение двух образцов для исследования их принадлежности одному и тому же человеку. Верификация, в частности, выполняется, когда вы пытаетесь разблокировать смартфон при помощи изображения лица — здесь биометрическая система отвечает на вопрос, достаточна ли высока её уверенность в том, что предъявленное изображение принадлежит владельцу устройства;
идентификация (она же поиск, она же сопоставление 1:N) подразумевает отбор из некоторого множества образцов-кандидатов тех, что предположительно принадлежат тому же человеку, что и представленный системе искомый образец. В качестве примера можно предложить систему контроля доступа, которая отпирает магнитный замок, когда «видит» на камере знакомое лицо.
В самом начале мы уже говорили, что биометрическая система не возвращает ответы вроде «да, это точно он» или «нет, это точно не он». Результатом сопоставления векторов будет показатель схожести, измеряемый на интервале [0; 1], и для его приведения к бинарному ответу «да/нет» нам нужно ввести пороговое значение. Если показатель схожести в результате некоторого сравнения окажется выше порога или равным ему, будем расценивать ответ системы как «да», а если ниже — как «нет».
Про показатель схожести нужно сделать несколько важных оговорок. Во-первых, нельзя принимать показатель схожести, который вернула система, за «качество» сопоставления. Нам приходилось сталкиваться с ситуациями, когда при сравнении нескольких систем заказчики говорили: «Система А оценила совпадение двух лиц на 0,78, а система Б — на 0,91, а раз это один и тот же человек, то система Б отработала лучше». Во-вторых, сам по себе показатель схожести не говорит вообще ни о чём. Например, у какой-то системы схожесть 0,78 может свидетельствовать об очень высокой уверенности в совпадении двух кандидатов, а другая может возвращать 0,85 при сравнении двух разных людей. В-третьих, нельзя трактовать схожесть как «совпадение» лиц — результат в 0,78 не означает, что «это один и тот же человек на 78%». Это просто число, которое должно интерпретироваться так или иначе в зависимости от выбранного порога.
Самым очевидным и самым наивным подходом к оценке качества алгоритма было бы измерение точности сопоставления (accuracy) — отношения случаев, когда система сработала верно, к общему количеству попыток сопоставления.
Accuracy = (Случаи, когда система сработала верно) / (Всего случаев)
В чём именно состоит его наивность и почему он недостаточно хорош? Давайте порассуждаем. Первое: даже умозрительно очень легко заключить, что, каким бы ни был установленный нами порог, всегда возможны только четыре исхода сравнения:
истинно-положительный (true match): вычисленный показатель схожести выше установленного порога, и оба сравниваемых образца фактически принадлежат одному и тому же человеку;
истинно-отрицательный (true non-match): вычисленный показатель схожести ниже установленного порога, и оба сравниваемых образца фактически принадлежат разным людям;
ложноотрицательный (ошибка первого рода, false non-match): вычисленный показатель схожести ниже установленного порога, в то время как оба сравниваемых образца фактически принадлежат одному и тому же человеку;
ложноположительный (ошибка второго рода, false match): вычисленный показатель схожести выше установленного порога, в то время как оба сравниваемых образца фактически принадлежат разным людям.
Второе: рассматривая accuracy в качестве единственной или главной метрики, затруднительно сделать вывод, какое количество ошибок допустила система. Допустим, мне всякий раз удавалось разблокировать мой собственный смартфон изображением лица (субъективная точность — 100%), но при этом скольким самозванцам и злоумышленникам удалось проделать с моим смартфоном то же самое?
Рассуждаем дальше: если мы опустим порог очень близко к нулю, то почти для любого кандидата мы всегда получим какое-то совпадение, но большинство из них будут ложными (будет много ошибок второго рода), а если поднимем его почти до единицы, получим только самые правильные совпадения, допустив при этом большое количество ошибок первого рода. Стало быть, увеличивая или уменьшая порог, мы можем получить более строгую или менее строгую систему. В случае со смартфоном большая строгость — это хорошо: пусть мне придётся сделать несколько попыток, но самозванцу разблокировать устройство будет очень сложно. И другое дело, когда мы пытаемся найти пропавшего без вести человека в огромном мегаполисе: пусть ложных совпадений будет и больше, зато мы точно не пропустим того, кого ищем.
Но как сравнить два алгоритма, если у одного порог настроен более строго, а у другого — менее? Прямое сопоставление метрик accuracy в этом случае оказывается совершенно бессмысленным! Выход прост: вместо того чтобы измерять частоту правильных сравнений, изучим, какова частота истинно-положительных результатов алгоритма при фиксированной частоте ошибок второго рода. Такая метрика обозначается как  , где:
, где:
 — true match rate, отношение числа истинно-положительных результатов к общему числу выполненных «позитивных» сравнений (когда оба сравниваемых образца фактически принадлежат одному и тому же человеку);
— true match rate, отношение числа истинно-положительных результатов к общему числу выполненных «позитивных» сравнений (когда оба сравниваемых образца фактически принадлежат одному и тому же человеку); — false match rate, отношение числа ошибок второго рода к общему числу выполненных «негативных» сравнений (когда сравниваемые образцы фактически принадлежат разным людям);
— false match rate, отношение числа ошибок второго рода к общему числу выполненных «негативных» сравнений (когда сравниваемые образцы фактически принадлежат разным людям); — фиксированное значение
— фиксированное значение  , при котором замеряется
, при котором замеряется  .
.
Чтобы рассчитать метрику, нам снова понадобятся тестовые данные в том же формате, что мы использовали при обучении. Важно понимать: в том же формате, но не те же самые; тестировать системы нужно на данных, полученных в тех условиях, в которых они будут эксплуатироваться (или максимально приближённых к ним).
Мы будем сопоставлять любые возможные пары изображений из датасета друг с другом и сохранять возвращаемый показатель схожести — при этом, так как датасет размечен, для каждого выполненного сравнения мы точно знаем, какой результат должен быть в действительности. Затем для каждого исследуемого алгоритма мы выберем такое значение показателя схожести  , при котором
, при котором  , и подсчитаем, какова частота истинно-положительных результатов при полученном пороге
, и подсчитаем, какова частота истинно-положительных результатов при полученном пороге  , то есть, как часто «позитивные» сравнения имеют схожесть больше, чем порог
, то есть, как часто «позитивные» сравнения имеют схожесть больше, чем порог  . Чем больше, тем лучше алгоритм.
. Чем больше, тем лучше алгоритм.
Вот, какие результаты мы получили для одного из алгоритмов NtechLab и уже упоминавшегося Insightface в разных сценариях сравнения (что и с чем сравнивали — в заголовках столбцов):
Описание теста | (повороты и освещение) vs (повороты и освещение) | (маска) vs (маска, повороты и освещение) | (фронтальное лицо) vs (маска, повороты и освещение) |
| 3e-6 | 3e-5 | 3e-5 |
NtechLab (private) | 98,03 | 92,54 | 92,24 |
Insightface (public) | 13,7 | 6,68 | 0,05 |

Заключение
Мы постарались простым языком рассказать, что из себя представляет технология распознавания лиц на данном этапе своего развития — надеемся, что на вопросы, поставленные в самом начале, каждый теперь может ответить самостоятельно. И о том, бывают ли идеальные системы, и о том, отчего случаются курьёзные ляпы, и даже о том, можно ли гарантированно обмануть алгоритм.
Будем очень рады, если наша статья окажется вам полезной!


