
Привет! Меня зовут Алексей Скоробогатый, я системный архитектор в Lamoda.
Недавно мы внесли большие изменения в нашу e-commerce платформу: перешли к событийной (events driven) архитектуре и добавили обработку данных в реальном времени. На этом примере я хочу поделиться опытом того, как мы реализуем эволюционный подход к изменению архитектуры.

Необходимость изменить архитектуру возникла из-за того, что в старой было невозможно реализовать задачу, которую поставил бизнес — настраиваемые персональные политики для кастомеров. С их помощью можно добавить элемент геймификации в онлайн-продажи, повысить мотивацию и вовлеченность покупателей.
Различные действия клиента — не только оформление заказа и выкуп определенного процента доставленных товаров, но даже комментарии к товару и другая активность на сайте — должны фиксироваться, анализироваться, и в результате клиенту присваивается некоторая категория. Категория влияет на бонусы, которые получает клиент: процент скидки, подарок в корзину, бесплатную доставку и др.
Причем нам требуется учитывать не только историю клиента, но и его поведение на сайте в реальном времени — и сразу же коммуницировать с ним, показывать его текущую категорию и подсказывать, как он может перемещаться из сегмента в сегмент. Это очень важно: чем быстрее мы будем собирать данные и подавать обратную связь для наших сервисов, тем лучше. Также бизнесу нужен инструментарий для гибкого управления этими категориями.
Как все работало до того, как мы задумались о внедрении слоя процессинга данных в реальном времени? В основном наша система состоит из микросервисов, но мы не отказались полностью и от монолитов с классической архитектурой — скорее, микросервисы были вторым слоем поверх уже существующего. Все данные сначала стекались в DWH.
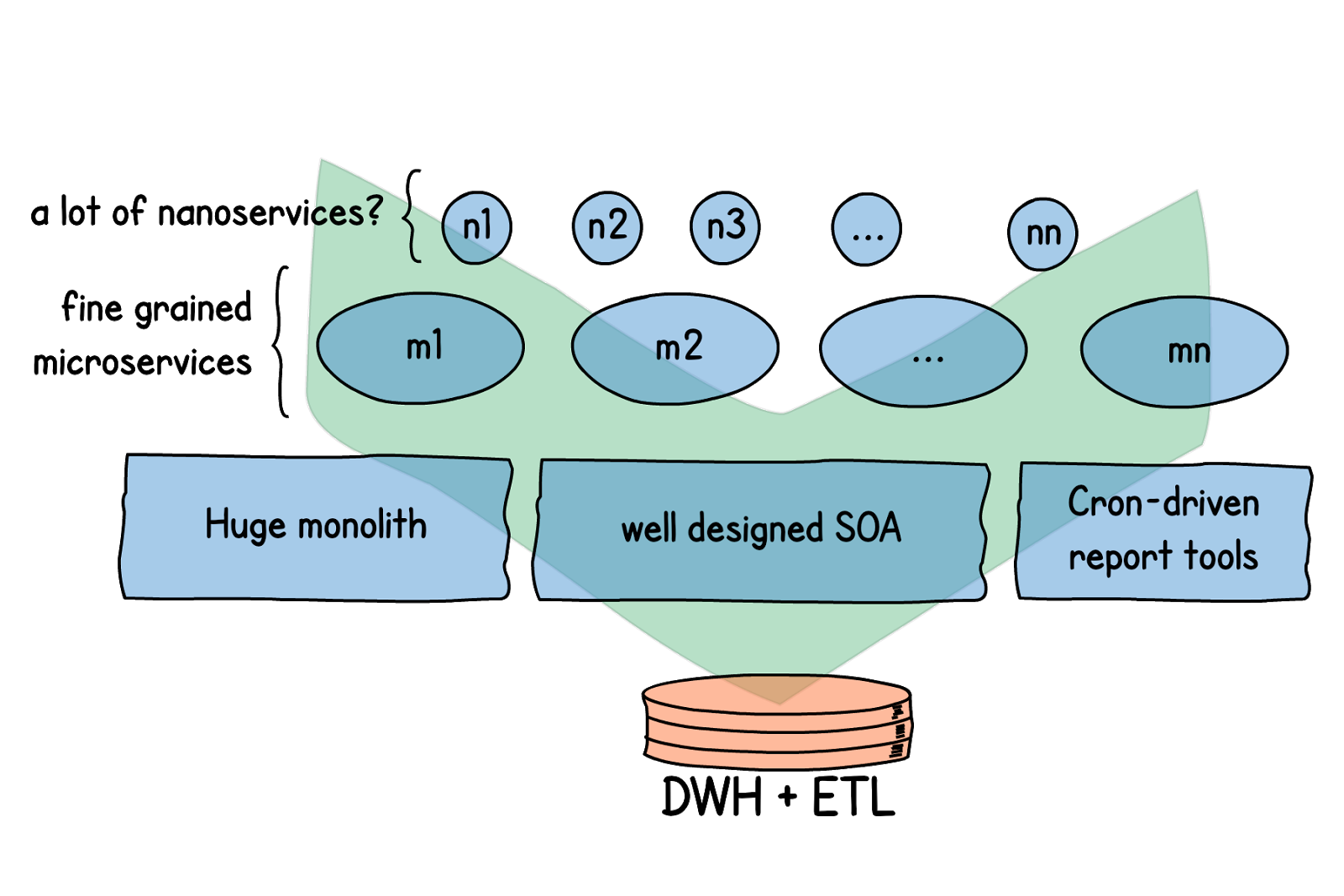
Затем производилась аналитика. Данные обрабатывались batch-операциями. Какие-то операции запускались раз в день, какие-то раз в неделю или еще реже — и результат их работы как обратная связь передавался в наши микросервисы.
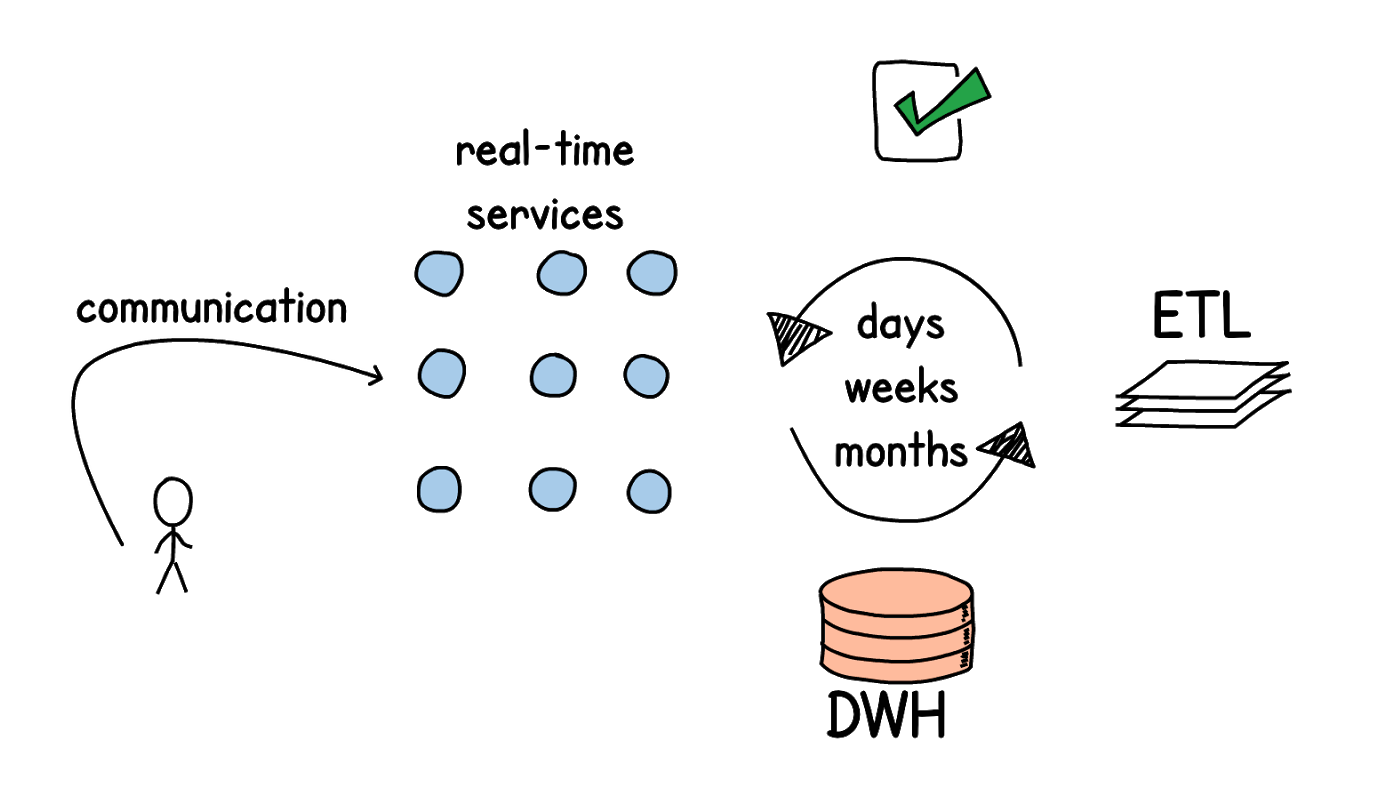
Как видите, обратной связи приходилось ждать долго, а для внедрения персональных политик нам нужна была коммуникация в реальном времени. В первую очередь нужен быстрый доступ к данным. Каждый сервис является мастером по каким-то данным, и их нужно получать быстро. В старом подходе это реализовывалось при помощи синхронных запросов по сети. Сервису-потребителю нужно было обратиться к мастер-сервису, либо к базе данных, куда заранее извлечены данные из него, и только потом можно было выполнять обработку. Но количество потребителей информации от каждого сервиса много, и их число с развитием бизнеса постоянно растет. Для сохранения производительности доступ к данным должен легко масштабироваться — а систему, основанную на синхронных запросах, отмасштабировать крайне сложно.
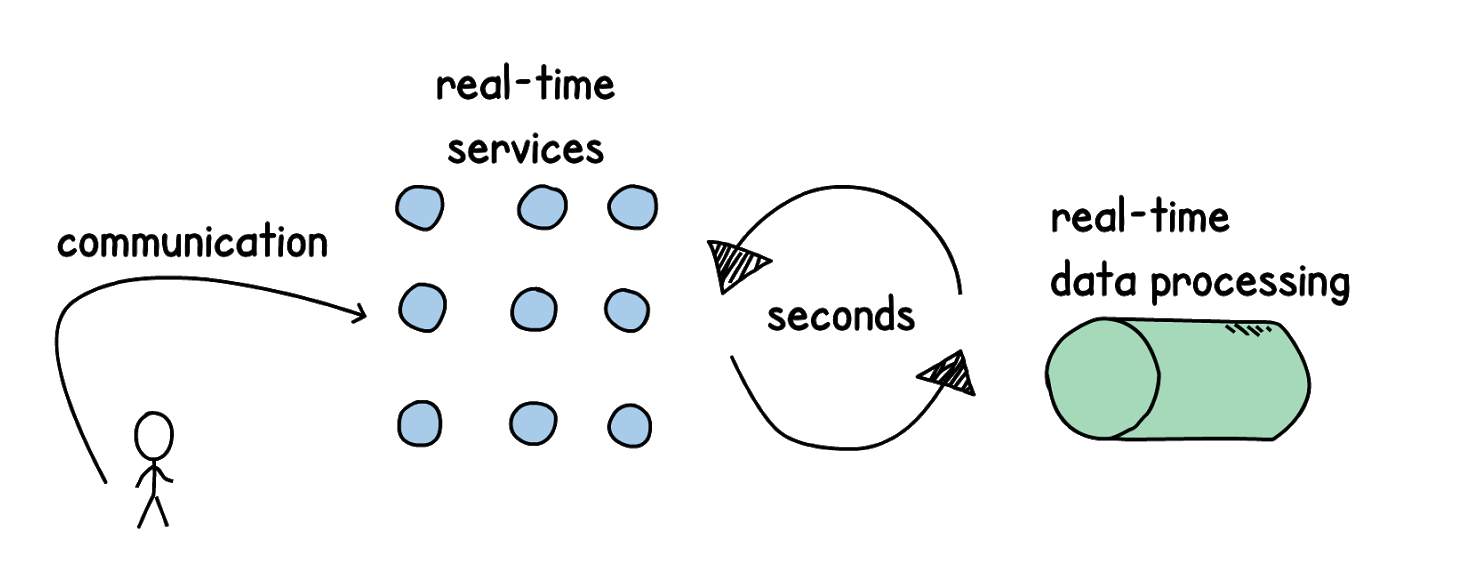
Мы хотели, чтобы наша картина изменилась. Чтобы появились real-time сервисы и слой обработки данных в реальном времени (ответ за несколько секунд — это гораздо лучше, чем batch-операции в течение дня). Подаем обратную связь к нашим сервисам, напрямую коммуницируем клиенту — условия бизнес-запроса удовлетворены.
Что конкретно нам нужно было сделать, чтобы запустить Real-time data processing?
Конечно же, на рынке есть много готовых решений. Сейчас, после того как мы реализовали все изменения, нам даже проще их оценить. Ведь в самом начале мы не до конца понимали, как и что хотим получить — многое из того, что я сказал выше, стало понятно уже где-то в середине проработки бизнес-задачи.
Какие готовые решения были? Kafka streams, на его базе вполне можно построить процессинг. Еще Apache Flink — на нем останавливаться не буду. Больше всего, как оказалось, нашим запросам по функциональности отвечает Apache Pulsar. У него есть Transformation layer, который неплохо подошел бы для нашего контекста.
Если мы решаем взять с рынка готовое решение, то сразу встает вопрос о том, как безболезненно интегрировать его в нашу архитектуру. Необходимы ресурсы на эксперименты. Команды разработки нужно научить взаимодействовать с этим новым компонентом. Главная сложность внедрения чужого готового решения — неизвестные неизвестные. Мы знаем функциональность, которую предоставляет эта система, мы примерно поэкспериментировали с тем, как она себя ведет. Но мы не знаем о тех подводных камнях, которые ждут нас в эксплуатации, если это действительно новые для нас технологии и экспертизы по ним еще нет.
В Lamoda мы стараемся максимально использовать “скучные технологии”, про этот подход можно почитать в статье Boring technology. Скучные эти технологии потому, что мы все о них знаем. И они приносят меньше всего тех самых неизвестных неизвестных.
В итоге для решения задачи с персональными политиками мы решили построить свой велосипед — использовать максимально те компоненты, которые у нас есть, и на их основе реализовать обработку данных в реальном времени.
Прежде чем строить непосредственно real-time data processing, нам нужно было сделать подготовительные изменения в системе.
Как мы это реализовали?
Мы стараемся придерживаться подхода DDD (Data Driven Development — подробнее об этом можно узнать из доклада моего коллеги). Для каждого сервиса мы определяем доменный контекст, и, исходя из этого, понимаем, какие данные будут передаваться в идущем от этого сервиса потоке. Данные собираются через шину событий (паттерн events-bus). Спецификации передачи данных описываем в Open API, а сами виды событий с описаниями перечислены в schema registry.
Коллектором данных (source of truth) в нашем случае стала Kafka.
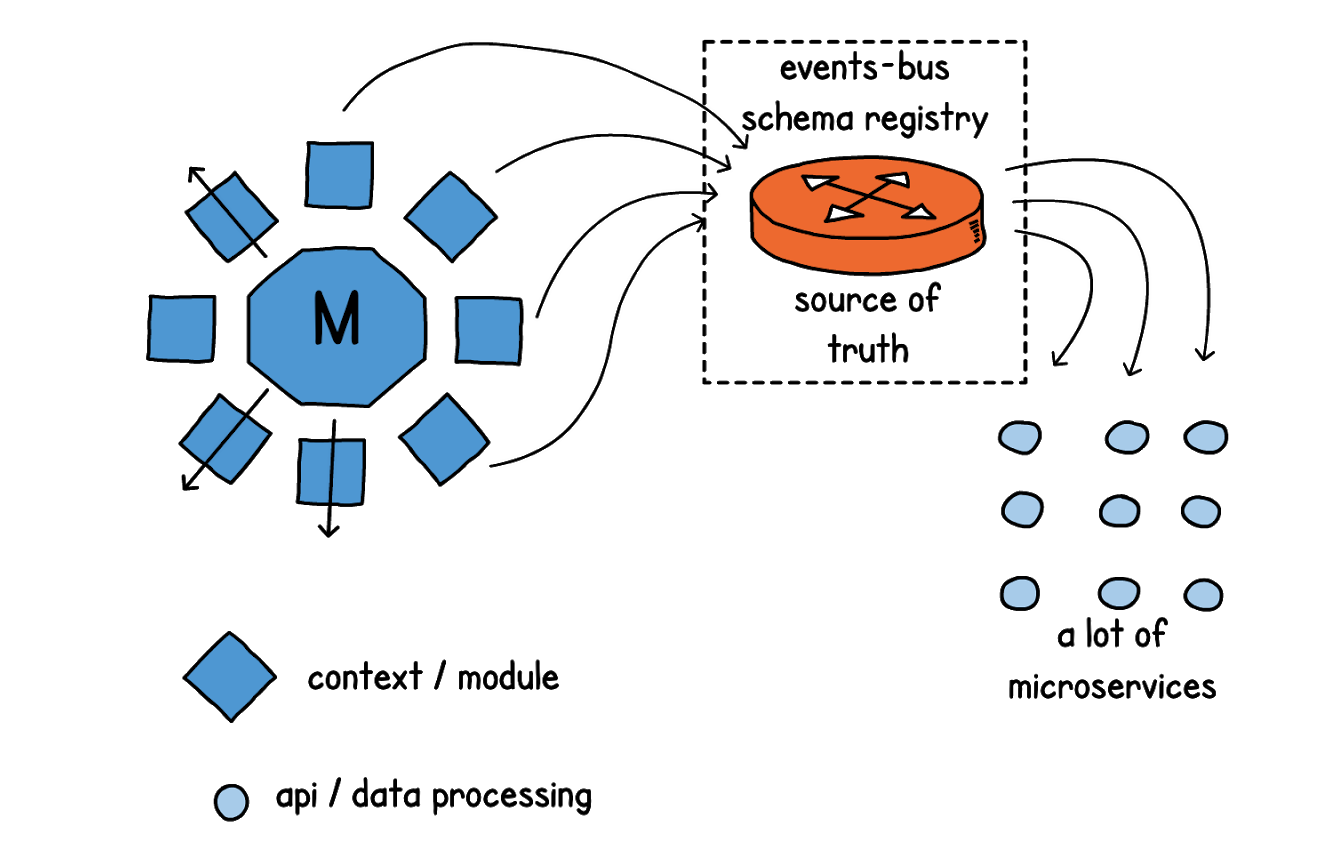
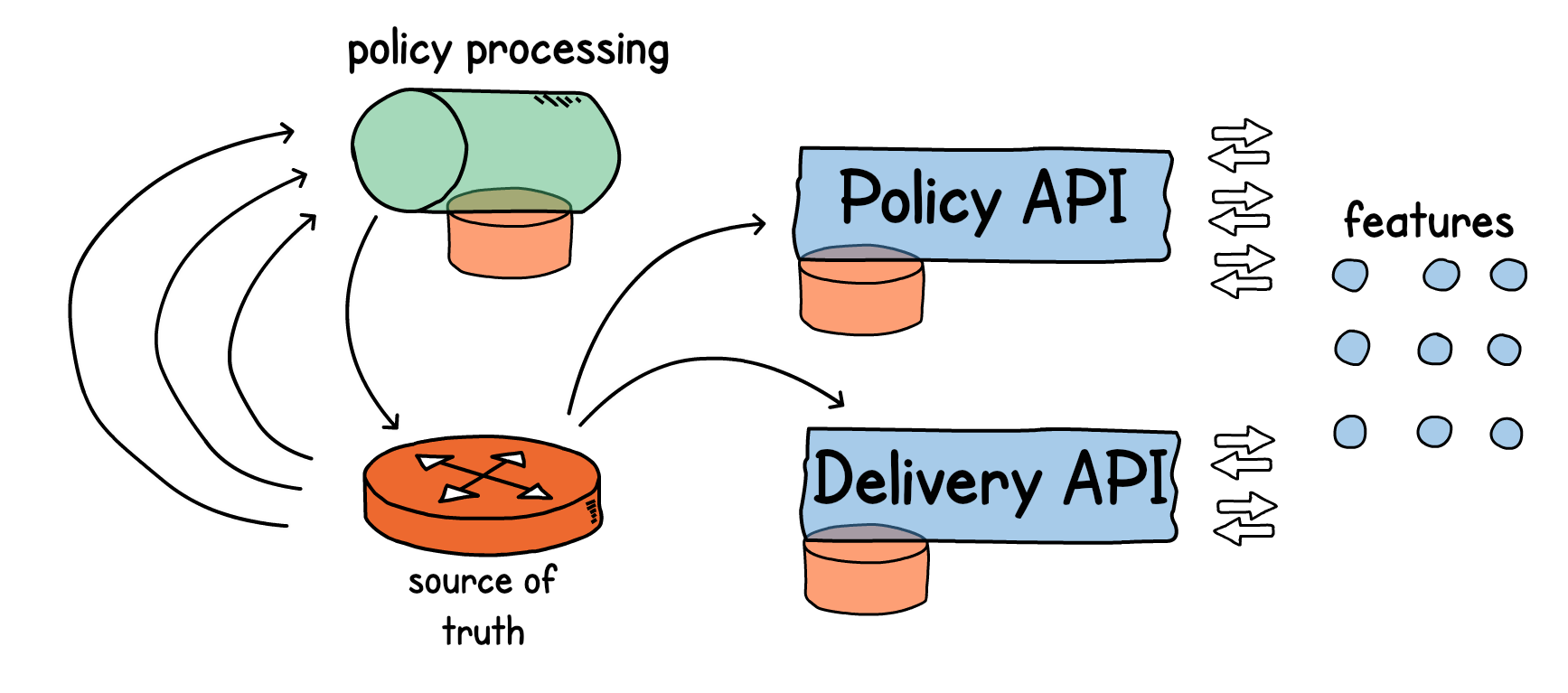
В результате архитектура нашей системы изменилась. Для всех наших сервисов мы определили контекст (данные, которые они в себе замыкают), и подключили к ним соответствующие дата-стримы. Теперь сервисы сами постоянно отправляют данные через стримы в шину событий. А когда сервису, наоборот, необходимо получить какие-то данные для процессинга, он не обращается напрямую к мастер-системе. Вместо этого он определяет, к какому контексту (домену) эти данные относятся, и затем подключается к соответствующему потоку данных через децентрализованное хранилище (source of truth). После чего производит необходимый процессинг, и уже в свою очередь делится данными через свой дата-стрим.
DWH также может забирать данные из source of truth.
На основе каких технологий мы все это реализовали?
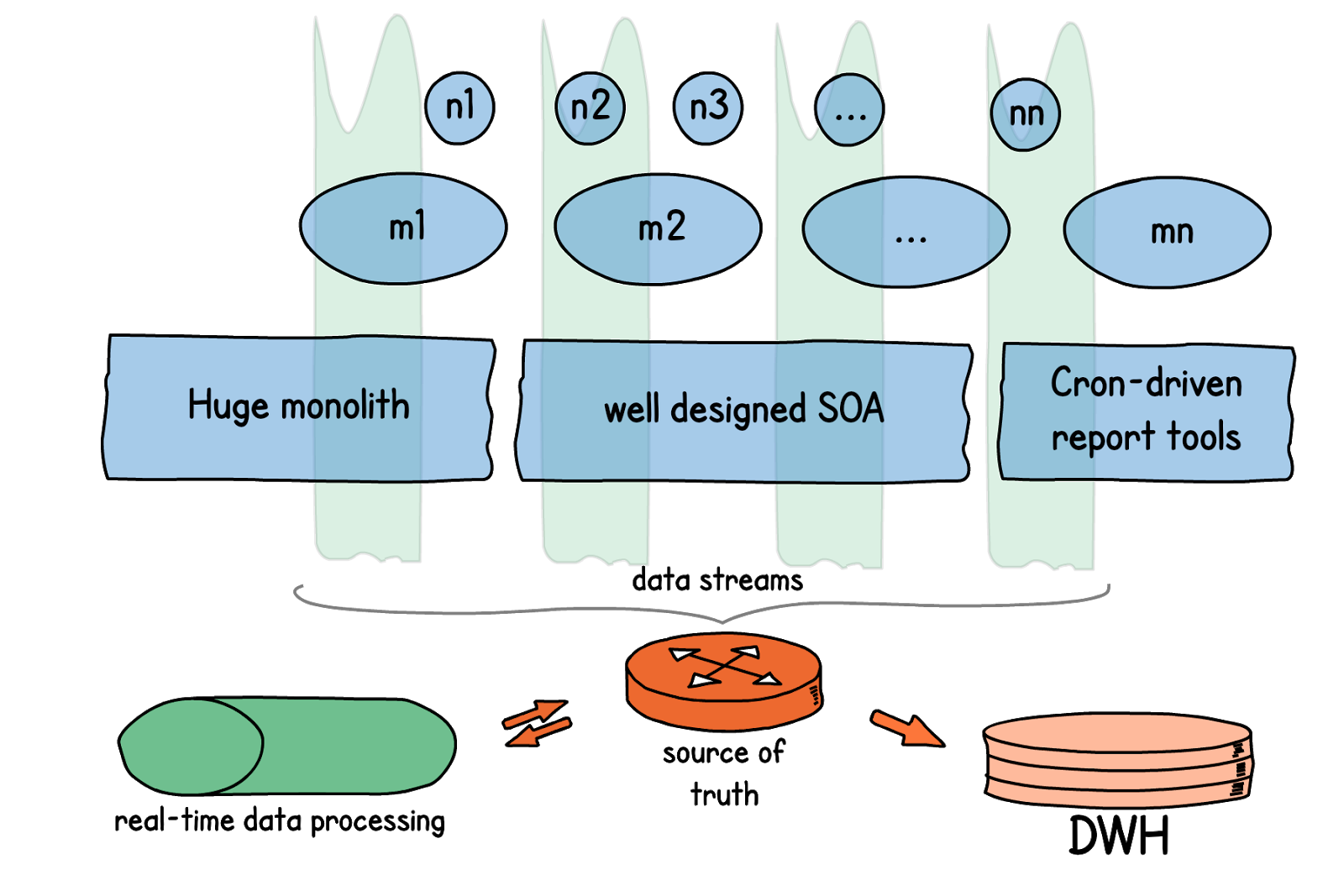
В качестве накопителя данных событий, source of truth, у нас работает Apache Kafka.
Data processing сервис мы сделали из апи-сервисов, используя Golang, при помощи которого мы строим свои микросервисы в e-commerce платформе.
Ну и для хранения стейта мы используем Postgres, как и для своих апи-сервисов.
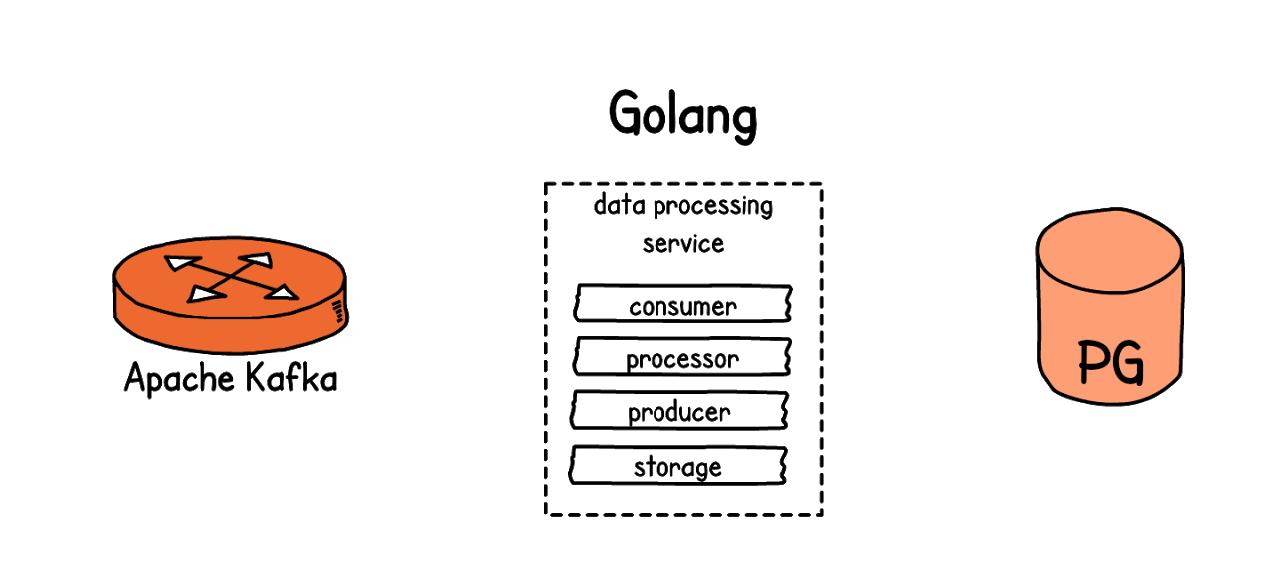
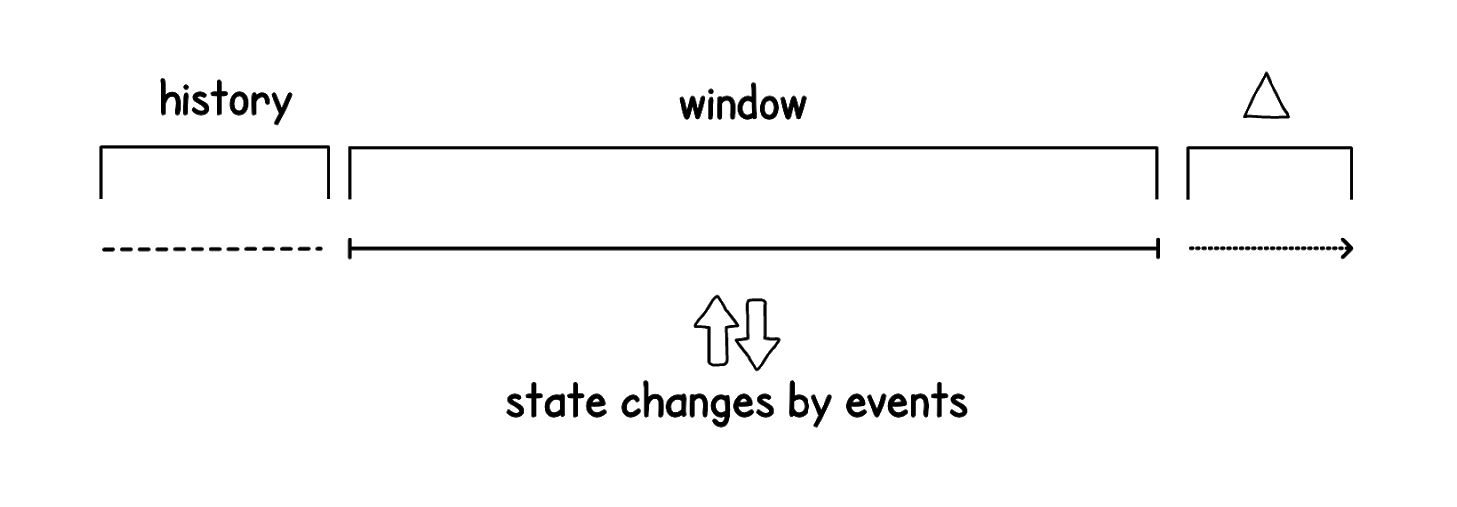
Еще одна важная вещь, которую мы добавили — задачи. События меняют состояние (state), но не запускают напрямую обработку данных процессорами. С каждым событием (event) связаны соответствующие ему задачи. Они могут выполняться сразу или отложенно во времени. За выполнением задач следят надсмотрщики — воркеры.
И уже исполнением задач занимаются процессоры. Чаще всего процессоры объединены в цепочки, в которых могут запускаться как последовательно, так и конкурентно. Процессоры трансформируют данные, из-за чего продуцируются новые события, и цикл повторяется.
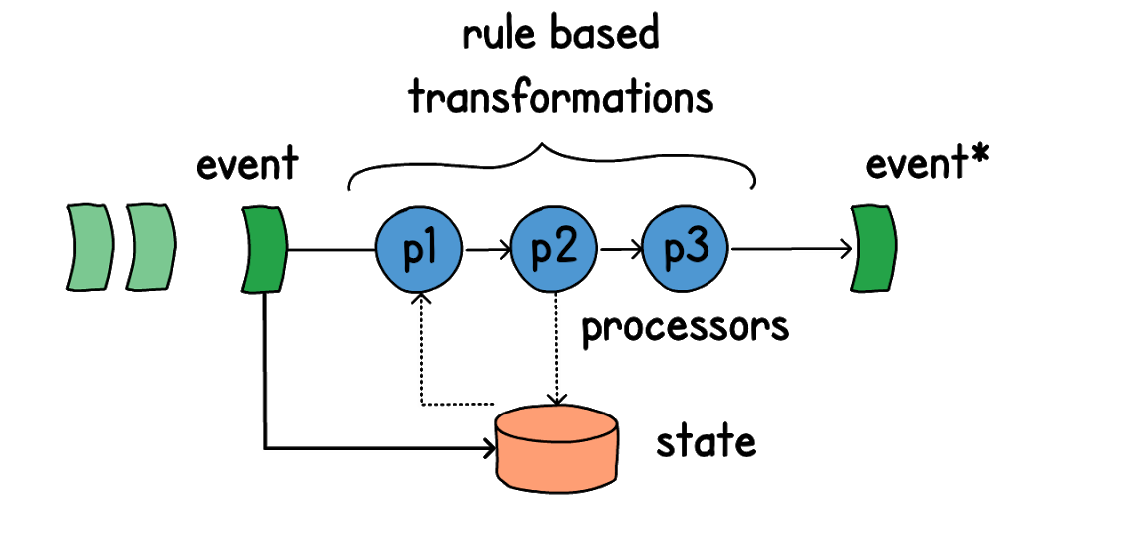
Архитектура, которую мы построили, позволяет не только в реальном времени реагировать на происходящие изменения, но и прогнозировать последствия событий, которые еще не произошли, но могут произойти в будущем. Поясню на примере: у нас на сайте есть корзина пользователя — это еще не созданный заказ, но мы знаем, из чего он состоит. И мы можем рассчитать и прокоммуницировать кастомеру, как изменится его процент скидки и другие бонусы, если он создаст этот заказ и полностью его выкупит. Для этого мы переиспользуем синхронно те же процессоры, что обсчитывают реальные события. Чем удобна наша архитектура — каждый процессор это обособленная функция, которая может работать как с событийной моделью, так и с синхронной. Мы берем стейт, добавляем к нему дельту (возможные изменения в будущем), прогоняем ту же цепочку процессоров, и в результате получаем новые данные.

Компонент, который мы построили — это один из будущих многих. Он решает конкретную бизнес-задачу с персонализацией. На данный момент он обрабатывает 700 тысяч событий в день, ставит около 2 миллионов задач (150 разных видов). Мы проверили нагрузочным тестированием: построенная нами система выдерживает скейлинг на Х10 нагрузки, чего нам пока вполне достаточно. Текущая нагрузка для коммуникации в реальном времени — порядка 450 RPS, и среднее время ответа — менее 10 миллисекунд.
Та часть системы, которую мы изменили, не работает обособленно — она входит в состав всей нашей платформы, которая работает как единое целое. Поэтому нам необходимо задумываться о том, как мы будем балансировать нагрузку при росте и масштабировании.
Наш сервис персонализации политик (Policy) собирает и обрабатывает данные, складывает их обратно в Kafka, передает в апишку — скорость ответа, как я сказал выше, сейчас 450 RPS.
Но также у нас есть сервис доставки (Delivery). Ему необходимы данные о кастомере, его скидках и бонусах, которые производит сервис персонализации. Но апишка доставки сама по себе очень нагружена в наших реалиях. Это 2000 RPS, и мы не можем себе позволить добавить туда синхронный поход в апишку какого-то еще сервиса.
Поэтому мы согласились для масштабирования на дупликацию контекста кастомера во все сервисы, где требуется персонализация. Каждый такой сервис сам хранит данные о клиенте (т.к. нельзя позволить синхронные обращения по API по сети). Обновления они получают также событийно.
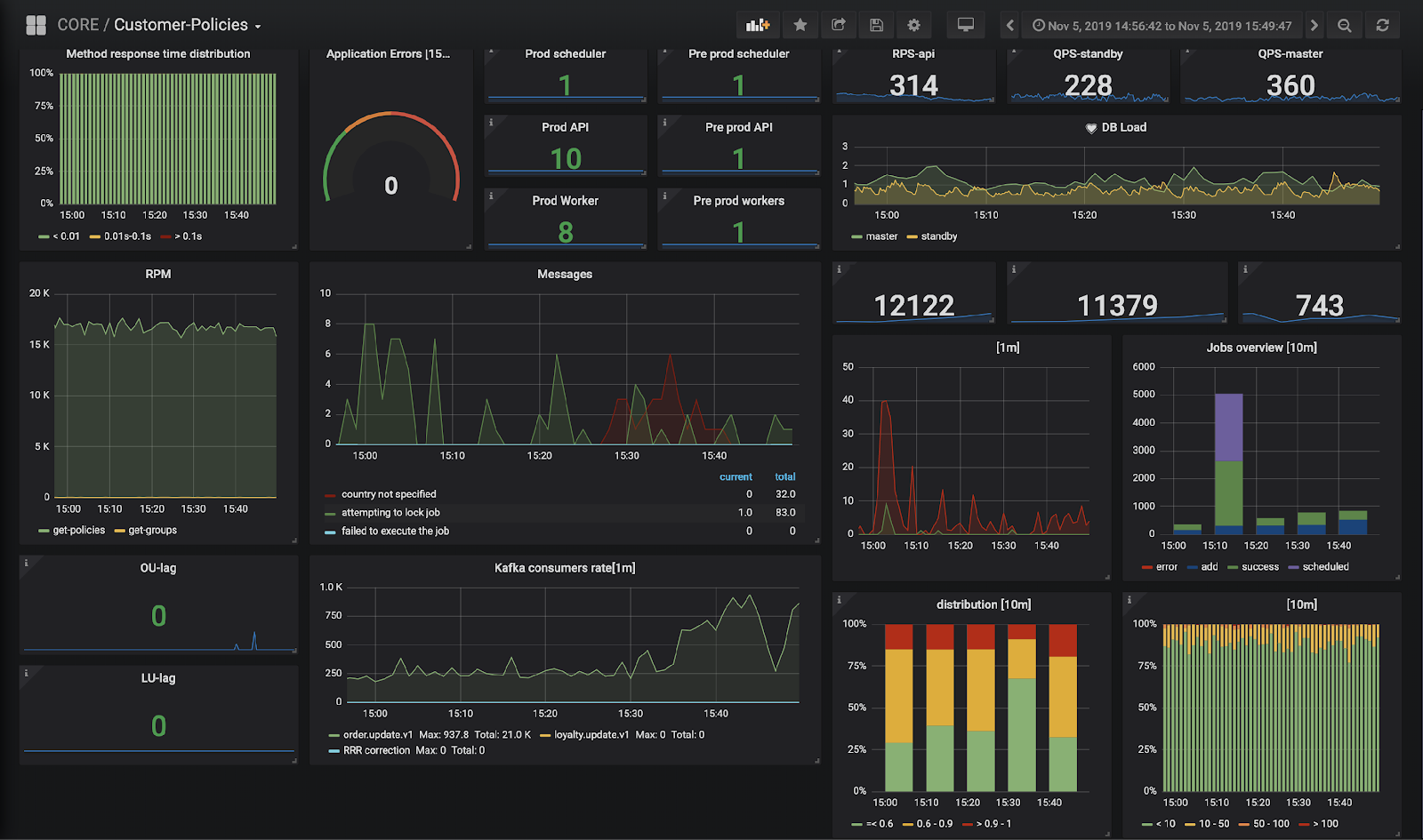
Выше я говорил, что слой трансформации должен быть прозрачным для нас, он очень критичный. Метрики обо всем, что происходит с данными, мы собираем через Prometheus, логи собираем в Elastic. С помощью Kibana+Grafana строим дашборды, а с помощью Icinga делаем алерты и рассылаем, когда что-нибудь сломалось. Так выглядит борда сервиса персональных политик — здесь как технические метрики, так и бизнес-метрики (которым я затер названия;) ). Если мы смотрим на дашборд и видим, что картинка изменилась, то можно примерно понять, в каком месте что-то пошло не так.
Нам нужна была обработка данных в реальном времени, и мы решили построить ее, максимально переиспользовав собственные инструменты. Что вышло в итоге?
Недавно мы внесли большие изменения в нашу e-commerce платформу: перешли к событийной (events driven) архитектуре и добавили обработку данных в реальном времени. На этом примере я хочу поделиться опытом того, как мы реализуем эволюционный подход к изменению архитектуры.
Запрос от бизнеса
Необходимость изменить архитектуру возникла из-за того, что в старой было невозможно реализовать задачу, которую поставил бизнес — настраиваемые персональные политики для кастомеров. С их помощью можно добавить элемент геймификации в онлайн-продажи, повысить мотивацию и вовлеченность покупателей.
Различные действия клиента — не только оформление заказа и выкуп определенного процента доставленных товаров, но даже комментарии к товару и другая активность на сайте — должны фиксироваться, анализироваться, и в результате клиенту присваивается некоторая категория. Категория влияет на бонусы, которые получает клиент: процент скидки, подарок в корзину, бесплатную доставку и др.
Причем нам требуется учитывать не только историю клиента, но и его поведение на сайте в реальном времени — и сразу же коммуницировать с ним, показывать его текущую категорию и подсказывать, как он может перемещаться из сегмента в сегмент. Это очень важно: чем быстрее мы будем собирать данные и подавать обратную связь для наших сервисов, тем лучше. Также бизнесу нужен инструментарий для гибкого управления этими категориями.
Почему нас перестала устраивать текущая архитектура?
Как все работало до того, как мы задумались о внедрении слоя процессинга данных в реальном времени? В основном наша система состоит из микросервисов, но мы не отказались полностью и от монолитов с классической архитектурой — скорее, микросервисы были вторым слоем поверх уже существующего. Все данные сначала стекались в DWH.
Затем производилась аналитика. Данные обрабатывались batch-операциями. Какие-то операции запускались раз в день, какие-то раз в неделю или еще реже — и результат их работы как обратная связь передавался в наши микросервисы.
Как видите, обратной связи приходилось ждать долго, а для внедрения персональных политик нам нужна была коммуникация в реальном времени. В первую очередь нужен быстрый доступ к данным. Каждый сервис является мастером по каким-то данным, и их нужно получать быстро. В старом подходе это реализовывалось при помощи синхронных запросов по сети. Сервису-потребителю нужно было обратиться к мастер-сервису, либо к базе данных, куда заранее извлечены данные из него, и только потом можно было выполнять обработку. Но количество потребителей информации от каждого сервиса много, и их число с развитием бизнеса постоянно растет. Для сохранения производительности доступ к данным должен легко масштабироваться — а систему, основанную на синхронных запросах, отмасштабировать крайне сложно.
Почему в прошлой архитектуре было невозможно реализовать запрос?
1. нет простого способа достать данные;
2. нет механизма обработки потоков данных;
3. рост глобальной сложности;
4. может пострадать производительность;
5. не хотим трогать legacy-подсистемы.
Какую архитектуру мы хотели построить?
Мы хотели, чтобы наша картина изменилась. Чтобы появились real-time сервисы и слой обработки данных в реальном времени (ответ за несколько секунд — это гораздо лучше, чем batch-операции в течение дня). Подаем обратную связь к нашим сервисам, напрямую коммуницируем клиенту — условия бизнес-запроса удовлетворены.
Что конкретно нам нужно было сделать, чтобы запустить Real-time data processing?
- Перейти от batch-обработки к событийной, чтобы каждое изменение по каждому событию мы пересчитывали, давали коммуникацию.
- Вместо синхронных запросов настроить дата-стримы и обрабатывать потоки.
- Создать слой трансформации данных, который обрабатывает потоки событий, в идеале настраиваемый без вмешательства разработки. Дать бизнесу какой-то инструментарий, чтобы вносить корректировки, изменения.
Свой велосипед или готовое решение?
Конечно же, на рынке есть много готовых решений. Сейчас, после того как мы реализовали все изменения, нам даже проще их оценить. Ведь в самом начале мы не до конца понимали, как и что хотим получить — многое из того, что я сказал выше, стало понятно уже где-то в середине проработки бизнес-задачи.
Какие готовые решения были? Kafka streams, на его базе вполне можно построить процессинг. Еще Apache Flink — на нем останавливаться не буду. Больше всего, как оказалось, нашим запросам по функциональности отвечает Apache Pulsar. У него есть Transformation layer, который неплохо подошел бы для нашего контекста.
Внедрение готового решения: неизвестные неизвестные
Если мы решаем взять с рынка готовое решение, то сразу встает вопрос о том, как безболезненно интегрировать его в нашу архитектуру. Необходимы ресурсы на эксперименты. Команды разработки нужно научить взаимодействовать с этим новым компонентом. Главная сложность внедрения чужого готового решения — неизвестные неизвестные. Мы знаем функциональность, которую предоставляет эта система, мы примерно поэкспериментировали с тем, как она себя ведет. Но мы не знаем о тех подводных камнях, которые ждут нас в эксплуатации, если это действительно новые для нас технологии и экспертизы по ним еще нет.
Скучные технологии
В Lamoda мы стараемся максимально использовать “скучные технологии”, про этот подход можно почитать в статье Boring technology. Скучные эти технологии потому, что мы все о них знаем. И они приносят меньше всего тех самых неизвестных неизвестных.
В итоге для решения задачи с персональными политиками мы решили построить свой велосипед — использовать максимально те компоненты, которые у нас есть, и на их основе реализовать обработку данных в реальном времени.
Проектирование событий: ставим данные на первое место
Прежде чем строить непосредственно real-time data processing, нам нужно было сделать подготовительные изменения в системе.
- Спроектировать события — определить доменный контекст и контракты передачи данных для каждого сервиса (то есть какие данные и каким образом мы будем передавать через дата-стримы).
- Сформировать потоки событий, научиться их собирать в едином месте — source of truth, распределенном транзакционном логе.
- Предоставить сервисам легкий доступ к потокам.
- Научиться передавать и обрабатывать события.
Как мы это реализовали?
Мы стараемся придерживаться подхода DDD (Data Driven Development — подробнее об этом можно узнать из доклада моего коллеги). Для каждого сервиса мы определяем доменный контекст, и, исходя из этого, понимаем, какие данные будут передаваться в идущем от этого сервиса потоке. Данные собираются через шину событий (паттерн events-bus). Спецификации передачи данных описываем в Open API, а сами виды событий с описаниями перечислены в schema registry.
Коллектором данных (source of truth) в нашем случае стала Kafka.
Наш “велосипед”: дата-стримы, source of truth и слой обработки данных
В результате архитектура нашей системы изменилась. Для всех наших сервисов мы определили контекст (данные, которые они в себе замыкают), и подключили к ним соответствующие дата-стримы. Теперь сервисы сами постоянно отправляют данные через стримы в шину событий. А когда сервису, наоборот, необходимо получить какие-то данные для процессинга, он не обращается напрямую к мастер-системе. Вместо этого он определяет, к какому контексту (домену) эти данные относятся, и затем подключается к соответствующему потоку данных через децентрализованное хранилище (source of truth). После чего производит необходимый процессинг, и уже в свою очередь делится данными через свой дата-стрим.
DWH также может забирать данные из source of truth.
На основе каких технологий мы все это реализовали?
В качестве накопителя данных событий, source of truth, у нас работает Apache Kafka.
Data processing сервис мы сделали из апи-сервисов, используя Golang, при помощи которого мы строим свои микросервисы в e-commerce платформе.
Ну и для хранения стейта мы используем Postgres, как и для своих апи-сервисов.
Еще одна важная вещь, которую мы добавили — задачи. События меняют состояние (state), но не запускают напрямую обработку данных процессорами. С каждым событием (event) связаны соответствующие ему задачи. Они могут выполняться сразу или отложенно во времени. За выполнением задач следят надсмотрщики — воркеры.
И уже исполнением задач занимаются процессоры. Чаще всего процессоры объединены в цепочки, в которых могут запускаться как последовательно, так и конкурентно. Процессоры трансформируют данные, из-за чего продуцируются новые события, и цикл повторяется.
Моделирование возможного будущего
Архитектура, которую мы построили, позволяет не только в реальном времени реагировать на происходящие изменения, но и прогнозировать последствия событий, которые еще не произошли, но могут произойти в будущем. Поясню на примере: у нас на сайте есть корзина пользователя — это еще не созданный заказ, но мы знаем, из чего он состоит. И мы можем рассчитать и прокоммуницировать кастомеру, как изменится его процент скидки и другие бонусы, если он создаст этот заказ и полностью его выкупит. Для этого мы переиспользуем синхронно те же процессоры, что обсчитывают реальные события. Чем удобна наша архитектура — каждый процессор это обособленная функция, которая может работать как с событийной моделью, так и с синхронной. Мы берем стейт, добавляем к нему дельту (возможные изменения в будущем), прогоняем ту же цепочку процессоров, и в результате получаем новые данные.
Перфоманс: меньше 10 миллисекунд на ответ
Компонент, который мы построили — это один из будущих многих. Он решает конкретную бизнес-задачу с персонализацией. На данный момент он обрабатывает 700 тысяч событий в день, ставит около 2 миллионов задач (150 разных видов). Мы проверили нагрузочным тестированием: построенная нами система выдерживает скейлинг на Х10 нагрузки, чего нам пока вполне достаточно. Текущая нагрузка для коммуникации в реальном времени — порядка 450 RPS, и среднее время ответа — менее 10 миллисекунд.
Балансирование нагрузки при росте и масштабировании
Та часть системы, которую мы изменили, не работает обособленно — она входит в состав всей нашей платформы, которая работает как единое целое. Поэтому нам необходимо задумываться о том, как мы будем балансировать нагрузку при росте и масштабировании.
Наш сервис персонализации политик (Policy) собирает и обрабатывает данные, складывает их обратно в Kafka, передает в апишку — скорость ответа, как я сказал выше, сейчас 450 RPS.
Но также у нас есть сервис доставки (Delivery). Ему необходимы данные о кастомере, его скидках и бонусах, которые производит сервис персонализации. Но апишка доставки сама по себе очень нагружена в наших реалиях. Это 2000 RPS, и мы не можем себе позволить добавить туда синхронный поход в апишку какого-то еще сервиса.
Поэтому мы согласились для масштабирования на дупликацию контекста кастомера во все сервисы, где требуется персонализация. Каждый такой сервис сам хранит данные о клиенте (т.к. нельзя позволить синхронные обращения по API по сети). Обновления они получают также событийно.
Мониторинг: Prometheus, дашборды и алерты через Icinga
Выше я говорил, что слой трансформации должен быть прозрачным для нас, он очень критичный. Метрики обо всем, что происходит с данными, мы собираем через Prometheus, логи собираем в Elastic. С помощью Kibana+Grafana строим дашборды, а с помощью Icinga делаем алерты и рассылаем, когда что-нибудь сломалось. Так выглядит борда сервиса персональных политик — здесь как технические метрики, так и бизнес-метрики (которым я затер названия;) ). Если мы смотрим на дашборд и видим, что картинка изменилась, то можно примерно понять, в каком месте что-то пошло не так.
Построить real-time data processing своими силами — возможно!
Нам нужна была обработка данных в реальном времени, и мы решили построить ее, максимально переиспользовав собственные инструменты. Что вышло в итоге?
- Работая маленькой командой из двух-трех человек, включая меня, мы получили MVP за три месяца.
- В процессе решения этой задачи мы изменили архитектуру нашей системы, поставив данные на первое место.
- Скорость обработки данных, которой мы достигли (менее 0,01 с на ответ), позволяет реализовать текущие запросы от бизнеса — и то, что мы построили, масштабируется достаточно, чтобы удовлетворить запросы ближайшего будущего.
- Командам разработчиков легко настраивать для новых сервисов передачу и обработку событий, потому что технологии им знакомы, а спецификации передачи данных описаны и едины для всей системы.



