
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет! Меня зовут Дима Офицеров, я продакт-менеджер клиентского сервиса ЮMoney. Моя команда разрабатывает собственное ПО для обслуживания пользователей, обучает искусственный интеллект в виде Манибота, работает над автоматизацией и оптимизацией процессов.
В статье расскажу о Data Science в клиентском сервисе и на примере покажу, что для работы с большим объёмом данных не всегда нужен многочисленный штат специалистов.

С чего мы начали
В 2020 году у нас в компании произошёл ребрендинг — мы стали ЮMoney. Было понятно, что в перспективе количество обращений в сервис возрастёт. Чтобы справиться с нагрузкой и качественно обрабатывать запросы пользователей, мы решили автоматизировать типовые действия операторов службы поддержки. Это позволило бы операторам концентрироваться исключительно на ответах пользователям и не отвлекаться на лишние действия с обработкой обращений, например, с поиском и выбором подходящего ответа или темы.
Разработали две нейросетевые модели:
Нейросеть для автоматической простановки тегов на обращения — нейросетевой классификатор тегов.
Нейросеть по подсказке ответов — виртуальный ассистент для операторов.
Что такое нейросетевой классификатор тегов и как он работает
Обращения, которые попадают в контакт-центр, разделяются по темам и попадают в очереди по правилам распределения — это автоматизированный процесс. На каждое обращение можно «наклеить» дополнительную метку в виде слова или сочетания слов — тег. С помощью тегов мы делим обращения на категории, что в дальнейшем помогает нам детализировано собирать статистику. Приведу пример:
Тег «Ошибка» присвоен обращению в ситуации, когда какой-то баг затрагивает многих пользователей и генерирует обращения в контакт-центр. Мы отслеживаем их количество через этот тег, собираем пул обращений, а затем отправляем массовую рассылку о том, что ситуация исправлена. Вместо того, чтобы обрабатывать каждое обращение вручную.
Операторы используют тег «Написали смежникам», когда не находят в базе знаний нужный ответ на вопрос пользователя и обращаются за помощью в другие подразделения. Через отслеживание этого тега мы измеряем количество таких писем, проверяем качество работы операторов, добавляем/меняем информацию в базе знаний.

Минус такого подхода в том, что сотрудник ставит тег вручную, а значит, тратит время на поиск нужной метки. Чтобы разгрузить операторов, мы решили это автоматизировать — с помощью нейросетевого классификатора.
За основу технического решения взяли модель Categorical Boosting для каждого существующего тега. Совокупность моделей предсказывает вероятность простановки определённого тега на основании событий в обращении.
Признаки для каждой модели мы отбирали на основании feature importance — важности признаков. Все признаки — категориальные переменные.
Feature importance — алгоритм, позволяющий определить, насколько сильно каждый из признаков влияет на конечное предсказание модели. Малозначительные признаки можно не включать в модель.
Это был наш первый опыт внедрения ML в собственный контакт-центр. Модель помогла автоматически проставить 22% тегов от всего объёма в 2023 году.
Что такое виртуальный ассистент для операторов
На основе опыта с нейросетевым классификатором тегов мы создали виртуального ассистента для операторов. Его работа основана на ранжировании шаблонов ответов.
Как это работает: нейросеть анализирует обращение и показывает три шаблона, которые с наиболее высокой долей вероятности подойдут для ответа пользователю. Оператор видит подсказку, выбирает шаблон и не тратит время на самостоятельный поиск ответа. Сокращается общее время работы над обращением.
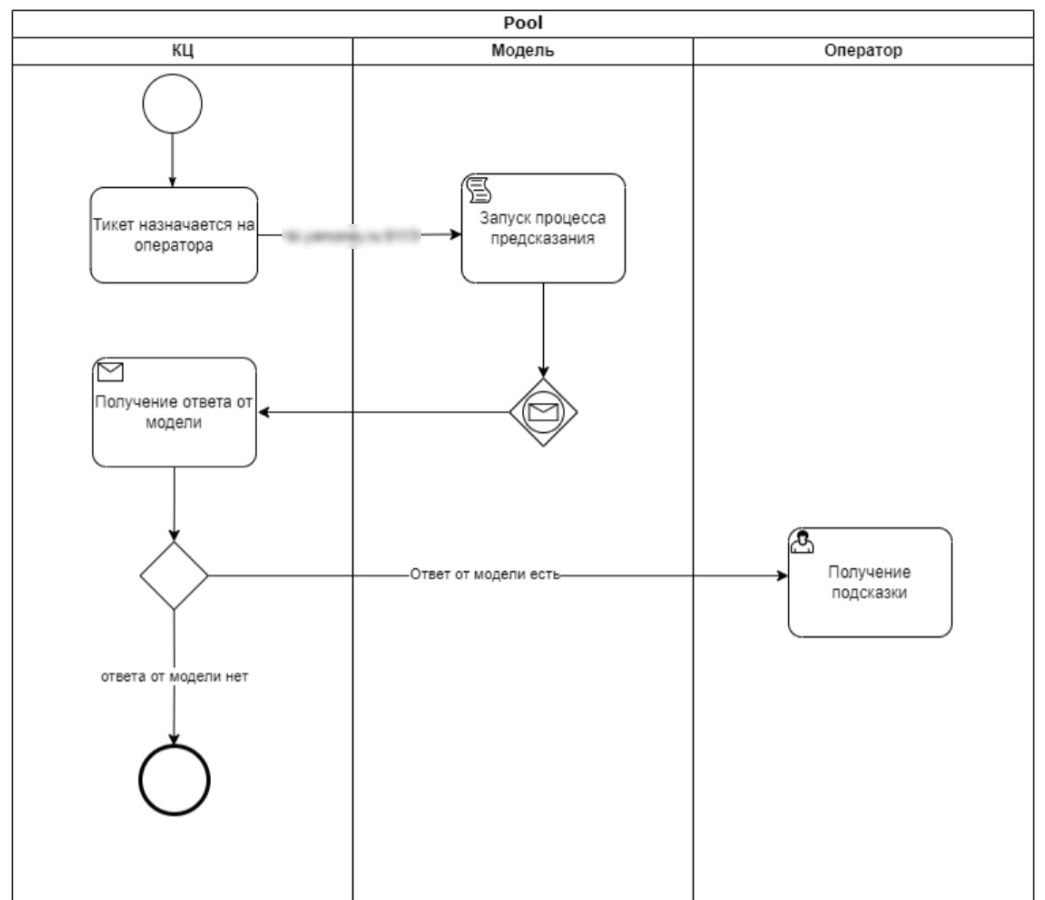
Мы обучали модель на исторических данных в виде входящих и исходящих сообщений. Разделили шаблоны на две категории: в одну положили те, которые операторы использовали в работе чаще всего, в другую — те, которые применялись редко. В процессе подготовки текстов удалили ненужные элементы, такие как даты, цифры и электронные адреса. Помимо текстовых данных, использовали категориальные и числовые.
Архитектура модели включает в себя комбинацию BERT от Sber Devices, параллельно работающего с one-hot MLP, и четырехслойного MLP, что обеспечивает высокую производительность без излишней сложности.
Для обучения и дообучения мы используем платформу ML Space, для версионирования моделей — ML Flow. Дообучение проводим раз в полгода, учитывая ограниченные ресурсы и необходимость накапливать дополнительные данные.

С августа по декабрь 2023 года при помощи виртуального ассистента мы ответили более чем на 50% обращений пользователей и сэкономили 396 человеко-часов.
Вывод
Нейросетевые модели помогают снизить нагрузку на операторов и сократить расходы бизнеса. Не для всех проектов по машинному обучению нужна большая команда — всё зависит от ваших целей и средств. Даже небольшие модели могут помочь — иногда бизнесу полезно использовать их для выполнения простых задач. Можно также натренировать и запустить много мелких моделей.
Задавайте вопросы в комментариях и подписывайтесь на наш блог, чтобы не пропустить новые материалы.




