https://plus3s.site - футбольная аналитика, как игра...
Для того, чтобы с помощью цифр получить информацию о происходящих на футбольном поле событиях, предлагаю оценить как влияет тот или иной показатель на результат матча, а потом выяснить по каким из показателей команда недорабатывает и как это исправить.
В виде тепловой карты представлено влияние основных признаков на забитые мячи команды. Забитые мячи олицетворяют результаты любого футбольного коллектива, хотя можно экспериментировать и с другими целевыми переменными. Признаки представлены только основные. Конечно, существуют и другие, и их очень-очень много.
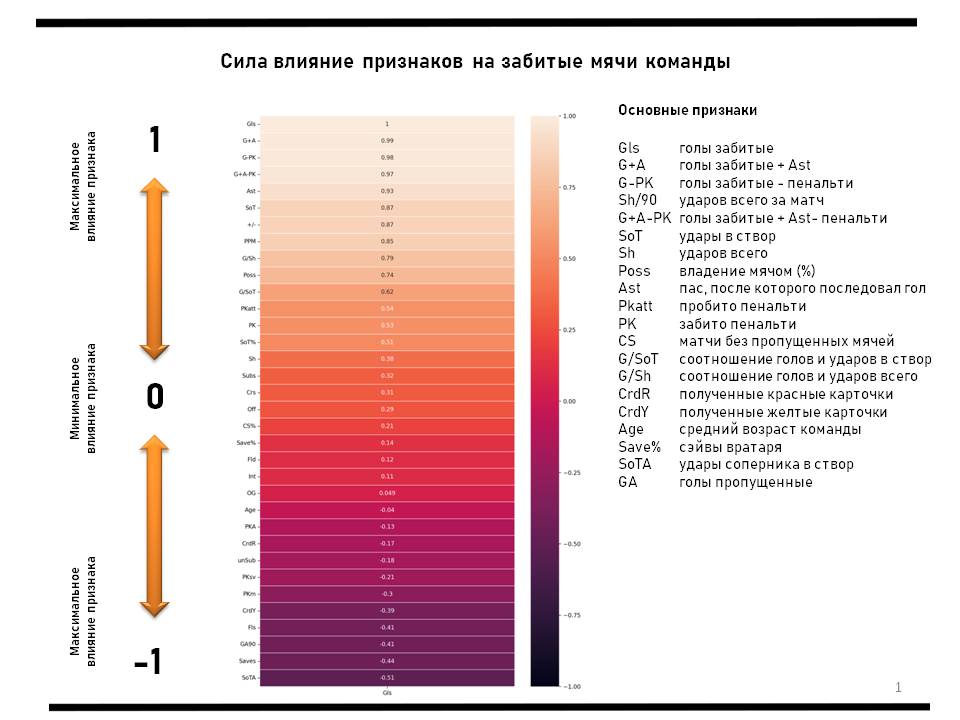
Тепловую карту мы можем составить при помощи питона, код представлен ниже. Для этого нам потребуются данные - датафрейм (df) и понимание того, какую целевую переменную мы будем исследовать (в данном случае - забитые мячи Gls). Как итог - представленная выше тепловая карта или, проще говоря, степень влияния всех основных признаков на целевую переменную.
# библиотеки, которые понадобятся
import pandas as pd
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sb
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# читаем файл с данными
df = pd.read_csv('*.csv')
# строим из данных тепловую карту
f, ax = plt.subplots(figsize=(18, 18), dpi=200)
plt.figure(figsize=(10, 68))
df.corr()[['Gls']].sort_values(by='Gls', ascending=False)
heatmap = sb.heatmap(df.corr()[['Gls']].sort_values(by='Gls', ascending=False), vmin=-1, vmax=1, annot=True,
cmap='rocket', linecolor='white', linewidths=0.7)
ax.invert_yaxis()
# сохраняем файл в текущей папке
heatmap.figure.savefig('correlation_Gls.png', dpi=200)Посмотрим описательную статистику. Для этого берем данные за несколько сезонов лиги. То, что представлено ниже, сделано на основе тех признаков, которые кажутся нам, и компьютеру конечно тоже, наиболее важными. В качестве примере - статистика по ударам в створ ворот (SoT).

Команда, для того, чтобы забивать от 1.7 до 2.43 мячей за матч, должна бить в створ ворот соперника в среднем 5.84 раза. А если, например, средний показатель за матч 5.2 удара в створ, но при этом команда забивает 2.0 мяча, то это значит, что по ударам в створ идет недоработка, а хорошего результата по забитым мячам команда добилась благодаря каким-то другим показателям. Следовательно, если подтянуть точность, то результат у команды будет лучше. Уловили смысл?..
Дарю небольшой, но полезный код для получения описательной статистики )
# разбиваем на равные интервалы
df_2['Gls'] = pd.qcut(df_2['Gls'], q=10)
# описательная статистика
df_m = df_2.groupby('Gls')['SoT'].describe()Теперь добавим еще визуализации и посмотрим что из себя представляют данные, с которыми мы работаем.

Цветные четырехугольники являются диапазоном наибольшего скопления наблюдений. Вертикальная линия в середине каждого наблюдения – наиболее справедливое, медианное значение. Ну и усики, указывающие на встречающиеся отклонения.
output, var2 = 'SoT', 'Gls'
fig, ax = plt.subplots(figsize=(14, 9))
sb.boxplot(x=var2, y=output, data=df_2)
plt.grid(linestyle="--")
ax.set(xlabel='голы забитые (в среднем за матч)', ylabel='SoT')
ax.figure.savefig('SoT.png', dpi=300)Таким образом, мы провели исследование только по одной целевой переменной – забитым мячам. В качество основного признака рассмотрели удары в створ ворот. Однако, команда может много забивать и быть по забитым мячам лидером, но при этом много пропускать и реально располагаться ближе к середине турнирной таблицы. Необходимо исследовать сразу несколько признаков в совокупности! Тогда у нас будет более четкое представление о том, за счет улучшения каких качеств игры команда может улучшить и свои результаты.
Представим, что аналогичным образом мы провели исследования и по таким показателям, как среднее число пасов, после которых последовали голы (Ast), владение мячом (Poss), удары соперника в створ ворот (SoTA) и сэйвы вратаря нашей команды (Save).
Все показатели в итоге должны иметь среднее за матч значение. Далее берем текущие в сезоне показатели анализируемой команды и сравниваем их со средними по лиге за несколько лет. Такую лепестковую диаграмму несложно построить в экселе.

Соответствие признаков забитым голам можно определить с помощью того же питона и регрессии.
Xg = np.array(df['SoT']) # значения признака
yg = np.array(df['Gls']) # значение целевой переменной
X_g = Xg.reshape(-1, 1)
# данные для определения соответствия (удары в створ)
# для каждого из чисел мы получим предсказание соответствия признака целевой переменной
X_Gpred = np.array([2.4, 2.5, 2.75, 3, 3.27, 3.5, 4, 4.25, 4.5, 4.75, 5, 5.25, 5.6, 5.9, 6.2, 6.4])
# полиномиальная регрессия
from sklearn.preprocessing import PolynomialFeatures
X_train, X_test, y_train, y_test = train_test_split(X_g, yg, test_size=0.5, random_state=20)
pr = LinearRegression()
quadratic = PolynomialFeatures(degree=1)
pr.fit(quadratic.fit_transform(X_train), y_train) # обучаем модель
y_pr = pr.predict(quadratic.fit_transform(X_Gpred.reshape(-1, 1))) # определяем соответствие признака целевой переменной
# получаем результат для каждого значения X_Gpred
print(f'полиномиальная регрессия \n {y_pr}')
# оценка качества
from sklearn.metrics import mean_squared_error
y = np.array([2.4, 2.5, 2.75, 3, 3.27, 3.5, 4, 4.25, 4.5, 4.75, 5, 5.25, 5.6, 5.9, 6.2, 6.4])
print('Среднеквадратическое отклонение для полиномиальной модели:', mean_squared_error(y, y_pr))ИТОГ:
Мы рассмотрели очевидные признаки… Да, если команда мало забивает или много пропускает это видно и без дополнительного анализа, но искусство футбольной аналитики состоит в том числе в том, чтобы подобрать признаки каждой команде! В итоге на основе анализа мы получим сведения о том, какие показатели команде необходимо улучшить…
Присоединяйтесь к plus3s.site!
Побед вам и преодоления трудностей! )




