
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Компаниям, которые используют Kubernetes и одновременно разрабатывают несколько продуктов, часто приходится решать вопрос с разделением сред разработки и организацией доступа к кластерам. Нужно, чтобы во время работы команды не мешали друг другу, а в идеале и вовсе не могли это сделать.
Меня зовут Михаил Сидоров, я разработчик в команде R&D СберТеха. Мы создаём Platform V — облачную платформу для разработки enterprise-приложений. Платформа создавалась как инструмент миграции с legacy на микросервисную архитектуру: она должна была организовать и упростить работу примерно 3000 команд разработки в Сбере.
За время разработки Platform V нам удалось изучить вопросы мультитенантности в Kubernetes-кластерах и создать собственное решение для организации мультитенантных кластеров. В этой статье расскажу об основных подходах, плюсах и минусах каждого паттерна, а во второй части подробно опишу наш собственный проект.

Что такое Multitenancy
Сначала определим, что такое мультитенантность (multitenancy). В общем случае мультитенантность — это предоставление изолированного доступа для арендаторов (tenant) к каким-то общим ресурсам. В случае мультитенантного Kubernetes тенант — это команда, отдельный разработчик или какой-то внешний клиент, а общий ресурс — кластер Kubernetes.
Существует два вида мультитенантности:
Soft multitenancy — частичная изоляция тенантов. Основная задача состоит в предотвращении случайного доступа к ресурсам другого тенанта. Этот вариант хорошо подходит тогда, когда мы полностью доверяем команде.
Hard multitenancy — полная изоляция тенантов друг от друга. Используется, когда мы хотим полностью исключить любое, даже преднамеренное воздействие на другой тенант.
Для организации мультитенантности в случае Kubernetes-кластеров нужно обеспечить изоляцию на трёх уровнях:
изоляция на уровне API — каждый тенант должен иметь доступ только к своим ресурсам;
сетевая изоляция — приложения одного тенанта не должны иметь сетевой доступ к приложениям другого;
изоляция на уровне воркеров — работа приложений одних тенантов не должна сказываться на работе других.
Дальше расскажу про отдельные подходы к изоляции. Отмечу, что в рамках статьи не буду рассматривать необходимость создания отдельных кластеров в целом, только вопрос целесообразности создания кластеров для изоляции сред для команд.
Отдельные кластеры — подойдут ли для изоляции

Самый простой способ организовать изоляцию для команд — создать отдельные кластеры.
Строго говоря, под наше определение мультитенантности Kubernetes такой подход не попадает, потому что между тенантами разделяется не сам Kubernetes, а низлежащая облачная инфраструктура.
Однако SIG-Multitenancy всё же считают этот паттерн моделью организации мультитенантности (Cluster-as-a-Service). И на первый взгляд он действительно позволяет обеспечить полную изоляцию и независимость сред: сразу «из коробки» получаем hard multitenancy.
С другой стороны, если команд много, есть риск столкнуться с cluster sprawl — разрастанием числа кластеров. И тогда сложность проблем будет расти пропорционально их количеству.
Какие минусы есть у этого подхода:
Для каждой новой команды придётся создавать отдельный кластер, а потом в каждый из них ставить и конфигурировать инфраструктурные компоненты: Ingress, cert-менеджер, мониторинг, логгирование, автоскейлинг и т.д.
Плохая утилизация ресурсов. Для каждого кластера понадобится свой контролплейн без возможности переиспользовать инфраструктурные компоненты. Утилизация воркеров тоже будет ниже, чем если бы мы запускали все приложения в одном кластере.
Сложность администрирования. Каждый кластер нужно будет по отдельности поддерживать, обновлять, мониторить и логгировать. Если кластеров тысячи, это становится серьёзной проблемой.
Консистентность ресурсов. В большом количестве кластеров сложно поддерживать консистентность политик, секретов, инфраструктурных компонентов и ресурсов.
У подхода с отдельными кластерами нет особенных конструктивных сложностей или доработок. Основная проблема — администрирование, но и её можно решить, если воспользоваться дополнительными инструментами. Например, для развёртывания и операций с кластерами можно использовать managed-решения (EKS, GKE), cluster-api и такие проекты, как Gardener в связке с Terraform. Его же можно использовать для установки инфраструктурных компонентов и поддержания их консистентности.
Но отдельные кластеры всё равно нельзя назвать эффективным подходом. Паттерн неизбежно связан с оверхедом по ресурсам, и превышение может быть очень существенным, особенно если команде нужно запустить не так много микросервисов. Одним словом, здесь нет конструктивных сложностей и доработок, только проблемы с администрированием, которые, тем не менее, можно решить. Однако оверхед по ресурсам может быть очень существенным, особенно если команде нужно запустить всего парочку микросервисов. Поэтому для решения проблемы изоляции команд такой подход может быть крайне неэффективным.
Мультитенантный кластер

В этом варианте мы разделяем один кластер между несколькими командами.
В отличие от подхода с выделением отдельных кластеров, вариантов организации мультитенантности в кластерах существует множество. Мы рассмотрим несколько самых распространённых и начнём с простого, который использует уже встроенные в Kubernetes объекты.
Нативная мультитенантность
Основной способ сделать Kubernetes мультитенантным без дополнительных расширений — организовать изоляцию через неймспейсы.
Выделим три роли: администратор кластера, администратор неймспейса (команды) и пользователь (член команды).
Администратор, имеющий полные права в кластере, задаёт права на создание объектов через Role или ClusterRole и привязывает их внутри определённого неймспейса к администратору команды через RoleBinding. Администратор команды даёт необходимые права на взаимодействия с объектами членам своей команды (для этого необходимо дать права на создание RoleBinding).
Например, это можно сделать с помощью дефолтной роли admin:
Allows admin access, intended to be granted within a namespace using a RoleBinding.If used in a RoleBinding, allows read/write access to most resources in a namespace, including the ability to create roles and role bindings within the namespace.
$ kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=bob --namespace=tenant-alphaВ целом этого уже почти достаточно для soft multitenancy: администратор команды сможет давать права на управление объектами только внутри своего неймспейса, но не сможет создать другой неймспейс.
Для обеспечения сетевой изоляции можно ограничить взаимодействие между неймспейсами через NetworkPolicies, дав, например, доступ только к общим инфраструктурным сервисам. Например так:
---
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy
metadata:
name: default-deny-all namespace: tenant-alpha
spec:
podSelector: {} policyTypes:
Ingress
Egress
---
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy
metadata:
name: allow-internet namespace: tenant-alpha
spec:
egress:
to:
- ipBlock:
cidr: 0.0.0.0/0 Осталось позаботиться о том, чтобы ворклоады пользователей не мешали друг другу на нодах. Нужно, чтобы они не могли забрать себе слишком много ресурсов кластера. Это решается через ResourceQuotas. С помощью объекта ResourceQuota можно задать лимиты по определённым ресурсам внутри неймспейса, например задать суммарное потребление CPU, RAM или максимальное число подов:
apiVersion: v1
kind: ResourceQuota metadata:
name: pods spec:
hard:
cpu: "100" memory: 20Gi pods: "100"$ kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=bob --namespace=tenant-alphaЕсть ещё один полезный инструмент, который позволяет задавать приоритет подам — это PriorityClasses. Например, если у тенанта есть какой-то не очень важный ворклоад, ему можно поставить PriorityClass с низким приоритетом. Когда на ноде закончатся ресурсы и туда зашедулятся поды с более высоким приоритетом, наш под будет «выселен» с ноды (evicted) и отправится ждать своей очереди на шедулинг. Но зачем кому-то пользоваться более низким приоритетом, если может произойти «выселение»? Всё очень просто: на разные приоритеты можно задать разные квоты ресурсов!
Вот так выглядит объект ResourceQuota с использованием PriorityClass:
apiVersion: v1
kind: ResourceQuota metadata:
name: pods-high spec:
hard:
cpu: "4" memory: 8Gi pods: "10" scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass values: ["high"]Если тенант не задаст реквесты или лимиты к своим подам и на ноду зашедулятся поды других тенантов, может случиться OOMKill (Out-Of-Memory Kill). Чтобы исключить такие ситуации, нужно создать LimitRange, тогда для всех подов без указанных лимитов будут указываться лимиты из него.
Если мы сначала создадим такой LimitRange:
apiVersion: v1 kind: LimitRange metadata:
name: mem-limit-range spec:
limits:
- default: memory: 512Mi defaultRequest: memory: 256Mi type: ContainerА затем создадим под:
apiVersion:
v1 kind:
Pod metadata:
name: default-mem-demo spec:
containers:
- name: default-mem-То спека созданного пода будет выглядеть следующим образом:
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr resources:
limits:
memory: 512Mi requests: memory: 256MiКроме того, с помощью LimitRange можно задавать минимальные и максимальные допустимые значения для ресурсов:
apiVersion: v1 kind: LimitRange metadata:
name: cpu-min-max-demo-lr spec:
limits:
- max:
cpu: "800m" min:
cpu: "200m" type: Теперь для получения hard multitenancy нужно только предотвратить возможность эскалации привилегий. Для этого можно использовать sandbox-контейнеры, системы микровиртуализации — gVisor, Firecracker — или выделенные ноды для тенантов.
Чтобы организовать выделенные ноды, нужно гарантировать, что на определённые ноды будут шедулиться только поды определённого тенанта. Это можно сделать, используя Taints/Tolerations + Node Affinity. В нашем случае вместо полноценного NodeAffinity хватит nodeSelector-а.
Рассмотрим на примере:
Пусть у нас есть тенант A и нода node-a.
Тогда, чтобы нода стала выделенной для тенанта, достаточно повесить на неё taint:
kubectl taint nodes node-a tenant=A:NoExecuteИ лейбл:
kubectl label nodes node-a tenant=AА на все поды тенанта вешать toleration и nodeSelector:
apiVersion: v1 kind: Pod metadata: name: ... spec: containers:
...
tolerations:
- key: "tenant" operator: "Equal" value: "alpha"
effect: "NoExecute"
nodeSelector: tenant: Благодаря nodeSelector все поды данного тенанта будут шедулиться только на ноды с соответствующим лейблом. А taint будет гарантировать, что никакие другие поды, кроме подов тенанта c соответствующим toleration, зашедулиться на них не смогут. Это особенно полезно, когда нужно убедиться в том, что инфраструктурные компоненты вне определённого тенанта не окажутся на одной ноде с его ворклоадом, если для них не указан соответствующий toleration.
Условно вот так шедулинг будет выглядеть, если не использовать ничего:
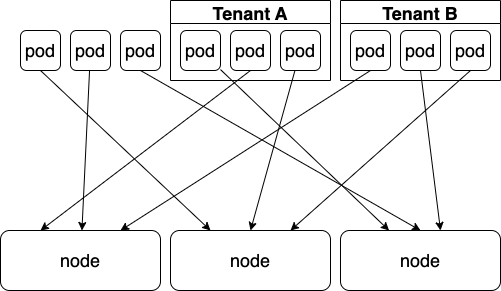
А вот так, если использовать только nodeSelector:

Этого уже может быть достаточно, поскольку поды, не относящиеся к тенантам, вероятно, относятся к инфраструктуре, и мы их контролируем. Но гарантированно избежать мисконфигураций можно, если добавить toleration:

При этом nodeSelector и toleration должны оказаться на КАЖДОМ поде КАЖДОГО тенанта. Если тенант сможет создать под со своим nodeSelector, то, подделав toleration, он сможет оказаться и на «чужой» ноде.
В такой ситуации на помощь приходят mutating webhooks. Достаточно менять спеку пода при каждом запросе на создание, добавляя туда необходимый селектор. Например, можно использовать уже готовый PodNodeSelector.
Важно отметить ещё один момент. Предположим, мы уверены, что тенант не собирается намеренно вредить другим тенантам, и хотим обойтись soft multitenancy. Даже в этом случае без дополнительных ограничений не обойтись, и вот почему.
Допустим, у нас есть два тенанта — A и B. Тенант A хочет запустить какую-то требовательную к IOPS базу данных. При этом у нас есть всего один медленный StorageClass, а на воркерах — быстрые NVME-диски. Тенант вполне разумно решил замаунтить в под hostPath — то есть какую-то папку на воркере — по некоему пути/data. То же самое решил сделать и тенант B. Мы это действие не запрещали, оно кажется разумным, но, скорее всего, данные будут перезаписаны и испорчены.
Поэтому даже в случае soft multitenancy стоит использовать PodSecurityPolicy (deprecated) или PodSecurityStandart, которые ограничат параметры запуска контейнеров, связанные с безопасностью. Например, чтобы запретить использование hostPath, при создании неймспейса можно добавить к нему следующие лейблы, которые позволят применить в неймспейсе PodSecurityStandart baseline:
apiVersion: v1 kind: Namespace metadata:
name: my-baseline-namespace labels:
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: latest pod-security.kubernetes.io/warn: После этого базовая мультитенантность готова. Выглядит, конечно, намного сложнее, чем нарезка отдельного кластера…
Но это только начало!
Hierarchical Namespaces
А что, если команде понадобится не один, а несколько неймспейсов? Или команда сама захочет создавать неймспейсы для своих задач?
Решить эту проблему можно по-разному. Например, использовать Hierarchical Namespace Controller (далее HNC). Между прочим, проект создан SIG-Multitenancy, а значит должен подходить для реализации мультитенантности. По крайней мере в теории…
Давайте теперь посмотрим, как это работает на практике.
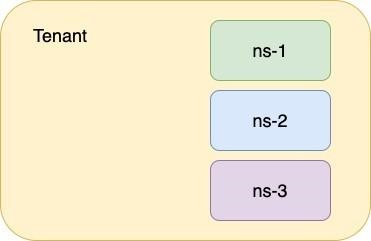
HNC добавляет возможность создавать иерархию неймспейсов. У неймспейса могут быть свои дочерние неймспейсы. Весь RBAC по дефолту наравне с любыми другими объектами в соответствии с их настройками будет наследоваться из родительского. А проблема создания неймспейсов тенантами решится путём введения нового объекта — Subnamespace. Тенанты могут создавать их, а контроллер уже нарежет реальные неймспейсы. При этом неймспейсы будут иметь древовидную структуру.

В ns-1 и ns-2 будет скопирован весь RBAC из ns-root, а в ns-3 — из ns-root и ns-1.
Посмотрим простой пример использования.
Создадим какой-то неймспейс (parent) и роль, разрешающую создание любых необходимых объектов и subnamespaceanchor.hnc.x-k8s.io в данном неймспейсе. Привяжем роль к админу команды. Теперь, несмотря на то, что прав на создание неймспейсов у него по-прежнему нет, он может создать вложенный неймспейс следующим образом:
kubectl hns create child -n parent (используем плагин HNC для kubectl)Контроллер создаст новый неймспейс и скопирует в него весь RBAC из родительского неймспейса:
$ kubectl hns treeparent # Output:
parent
└── childПри этом под капотом плагин просто создаст следующий объект:
apiVersion: hnc.x-k8s.io/v1alpha2
kind: SubnamespaceAnchor
metadata:
namespace: parent
name: childЭто объект из группы subnamespaceanchor.hnc.x-k8s.io, права на создание которого мы заранее выдали пользователю. Он в свою очередь будет подхвачен контроллером HNC, который создаст полноценный неймспейс и сделает его дочерним, после чего будет копировать туда все настроенные объекты.
По дефолту он копирует только RBAC, но можно настроить, например, копирование LimitRanges:
kubectl hns config set-resource limitranges --mode PropagateТеперь все LimitRanges, созданные в родительском кластере, будут копироваться в дочерние. То есть мы гарантируем, что в каждом кластере будет нужный нам LimitRanges, причём, поскольку роль также копируется, а доступа к LimitRanges админу команды мы не давали, он не сможет изменить это поведение.
С NetworkPolicies действует та же логика, только теперь нужно будет добавить лейбл селектор для неймспейсов, который будет наследоваться от корневого неймспейса.
А вот с ResourceQuota нас ждёт провал: поскольку объект просто копируется в свежесозданный неймспейс, для каждого дочернего неймспейса будет создаваться новая квота. Это может обернуться простой уязвимостью: закончились ресурсы — просто создай ещё один дочерний неймспейс, в котором будет свежая квота, и используй её дальше. Поэтому построить hard multitenancy, используя только HNC без дополнительных admission controller- ов, нельзя.
Capsule
Один из самых продвинутых проектов для реализации подхода Namespace-as-a-Service. В отличие от HNC, здесь появляется CRD Tenant, агрегирующий несколько неймспейсов.
Хорошее демо Capsule можно посмотреть здесь. Мы же сфокусируемся на том, какую изоляцию можно получить, используя Capsule.
Для этого рассмотрим спеку Tenant:
Самое главное здесь — указание админов тенанта. Можем задать сразу несколько:
owners:
- kind: User
name: bobТакже можно задать дополнительную метадату, которая будет добавляться к созданным тенантом неймспейсам, и максимальное количество неймспейсов для создания:
namespaceOptions:
quota: 3 additionalMetadata:
labels: capsule.clastix.io/tenant: gas
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: latest pod-security.kubernetes.io/warn: baseline
pod-security.kubernetes.io/warn-version: latestТаким образом решается проблема с созданием нескольких неймспейсов для тенанта. В созданных неймспейсах админ тенанта может создать RoleBinding для членов своей команды, сохранив при этом автономию. Для этого действия не нужен админ кластера, а дополнительная метадата может быть использована для PodSecurityStandart и для NetworkPolicies:
networkPolicies:
items:
egress:
to:
ipBlock:
cidr: 0.0.0.0/0 except:
- 192.168.0.0/12
ingress:
from:
namespaceSelector: matchLabels: capsule.clastix.io/tenant: gas
podSelector: {}
ipBlock:
cidr: 192.168.0.0/12
podSelector: {} policyTypes:Так же, как и в HNC, networkPolicies будут копироваться в каждый созданный тенантом неймспейс. Благодаря лейблу, который мы указали при создании, можно сделать связность между неймспейсами. Это значит, что с сетевой изоляцией тоже всё в порядке.
LimitRanges:
limitRanges:
items:
- limits:
- max:
cpu: "1"
memory:
1Gi min:
cpu: И с ResourceQuota тоже всё ок:
resourceQuotas:
items:
hard:
limits.cpu: "8" limits.memory: 16Gi requests.cpu: "8" requests.memory: 16Gi scopes:
- NotTerminating
hard:
pods: "10"
hard:
requests.storage: 100GiПричём, в отличие от HNC, нет проблем с «тупым копированием». Вот цитата из спецификации CRD:
resourceQuotas <Object>
Specifies a list of ResourceQuota resources assigned to the Tenant. The assigned values are inherited by any namespace created in the Tenant. The Capsule operator aggregates ResourceQuota at Tenant level, so that the hard quota is never crossed for the given Tenant. This permits the Tenant owner to consume resources in the Tenant regardless of the namespace. Optional.Круто!
И даже есть добавлялка нод селекторов для изолированных нод. Вот её описание:
nodeSelector <map[string]string>
Specifies the label to control the placement of pods on a given pool of worker nodes. All namesapces created within the Tenant will have the node selector annotation. This annotation tells the Kubernetes scheduler to
place pods on the nodes having the selector label. Optional. А вот как её можно применить:
yaml
nodeSelector:
kubernetes.io/os: linux
tenant: alphaНе хватает разве что toleration-ов.
Зато помимо этого можно задавать регулярки для hostnames Ingress, разрешённые Storage-классы и Ingress-классы (можно тоже регулярками), разрешённые Registry и т. д.
Некоторые проблемы всё же остаются. Например, нет доступа к cluster-scoped-ресурсам.
Допустим, мы хотим посмотреть список наших неймспейсов, созданных через Capsule:
$ kubectl get namespaces
Error from server (Forbidden): namespaces is forbidden:
User "alice" cannot list resource "namespaces" in API group "" at the cluster scopeНеймспейсы создать можем, а посмотреть, что создали — нет... Или всё-таки можем?
Оказывается, для Capsule есть proxy-сервер, который можно поставить перед kube-api и отправлять запросы на него. Сервер в свою очередь вернёт список cluster-scoped-ресурсов, к которым у тенанта есть доступ. Выглядит это так (картинка из документации):

На данном этапе поддерживаются:
неймспейсы;
Storage-классы;
Ingress-классы;
Priority-классы.
Honorable mentions: Rancher
Самый юзер-френдли проект из списка, позволяющий организовать soft multitenancy. Rancher — это целая экосистема для менеджмента Kubernetes с возможностью управления большим количеством кластеров. Не буду глубоко вдаваться в подробности его реализации, отмечу только, что в нём присутствует CRD Project, по факту являющийся аналогом Tenant в Capsule:

Админ проекта также может распоряжаться правами пользователей:

Можно осуществлять сетевую изоляцию, приводить в действие PodSecurityPolicies на уровне проекта, задавать LimitRanges:

Можно задать ResourceQuotas не только для отдельных неймспейсов, но и для всего проекта:

А ещё здесь есть часть «фишек» из HNC, которых нет в Capsule. Например, возможность делать project-scoped-секреты, когда секрет копируется во все неймспейсы проекта. Есть свой аналог proxy-сервера. И вообще ранчер сделал свои Projects задолго до появления Capsule. И несмотря на это стоит учитывать, что Capsule гораздо более гибкий и позволяет максимально близко приблизиться к полной изоляции, не затрачивая больших усилий.
Заключение
Сейчас организовать Namespace-as-a-Service проще, чем пару лет назад, когда пришлось бы с нуля писать инструменты, которые позволили бы применить множество политик. Но несмотря на то, что Capsule или Rancher упрощают организацию soft multitenancy в кластерах, они по-прежнему слабо подходят для кейсов, когда нужна именно hard multitenancy. Вот почему:
1. Ошибки в конфигурации.
Вся изоляция так или иначе идёт на уровне admission контроллеров, network policies, RBAC и т. д. Любое упущение приведёт к потенциальным уязвимостям, а компрометация одного неймспейса — к компрометации всего кластера.
2. Урезанные права.
Даже с учётом того, что большая часть юзкейсов уже покрывается Capsule, будут возникать ограничения при использовании cluster-scoped-ресурсов. Не получится использовать собственные CRD, контроллеры и операторы из-за риска повлиять на других пользователей. С ростом популярности cloud-native-приложений с этими ограничениями придётся сталкиваться всё чаще.
3. Централизованный control plane.
Поскольку все среды находятся в одном кластере, нагрузка на control plane и общие контроллеры растёт. Чем активнее их использует одна команда, тем вероятнее, что от этого пострадает работоспособность другой. Это неминуемо ведёт к необходимости введения различных квот и лимитов, требующих в свою очередь внедрения дополнительных admission controller-ов.
Кажется, что оптимального решения для hard multitenancy нет, но это не так. В этом случае лучше всего подходят виртуальные кластеры или, в терминологии авторов HNC, Control-planes-as-a-Service.
Именно их мы использовали при создании собственного подхода к организации мультитенантности. Подробно о сервисе и о том, как мы объединили ключевые характеристики основных паттернов, чтобы создать свой, расскажу во второй части статьи. А пока — спасибо за внимание и до встречи!




