
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Если бы у data science существовал собственный зал славы, отдельную его часть нужно было бы посвятить разметке. Памятник отвечающим за разметку выглядел бы как атлант, держащий огромный камень, символизирующий их тяжелый и скрупулезный труд. Собственной стелы заслужила бы и база данных изображений ImageNet. За девять лет её контрибьюторы вручную разметили более 14 миллионов изображений. Даже представлять этот труд утомительно.
Хотя разметка и не является особо интеллектуальным трудом, она всё равно остаётся серьёзной проблемой. Разметка — неотъемлемый этап предварительной обработки данных для контролируемого обучения. Для этого стиля обучения моделей используются исторические данных с заранее заданными целевыми атрибутами (значениями). Алгоритм может находить целевые атрибуты, только если их указал человек.
Занимающиеся разметкой люди должны быть чрезвычайно внимательны, поскольку каждая ошибка или неточность отрицательно влияет на качество датасета и на общую производительность прогнозирующей модели.
Как получить высококачественный размеченный набор данных и не поседеть в процессе работы? Главной трудностью являются выбор ответственных за разметку, оценка необходимого для неё времени и подбор наиболее подходящих инструментов.
Мы вкратце описали разметку в статье про общую структуру проекта машинного обучения. Сегодня мы поговорим о методологиях, техниках и инструментах разметки.
Методологии разметки
Выбор методологии зависит от сложности задачи и данных для обучения, количества людей в команде data science, финансовых и временных ресурсов, которые компания может выделить на реализацию проекта.
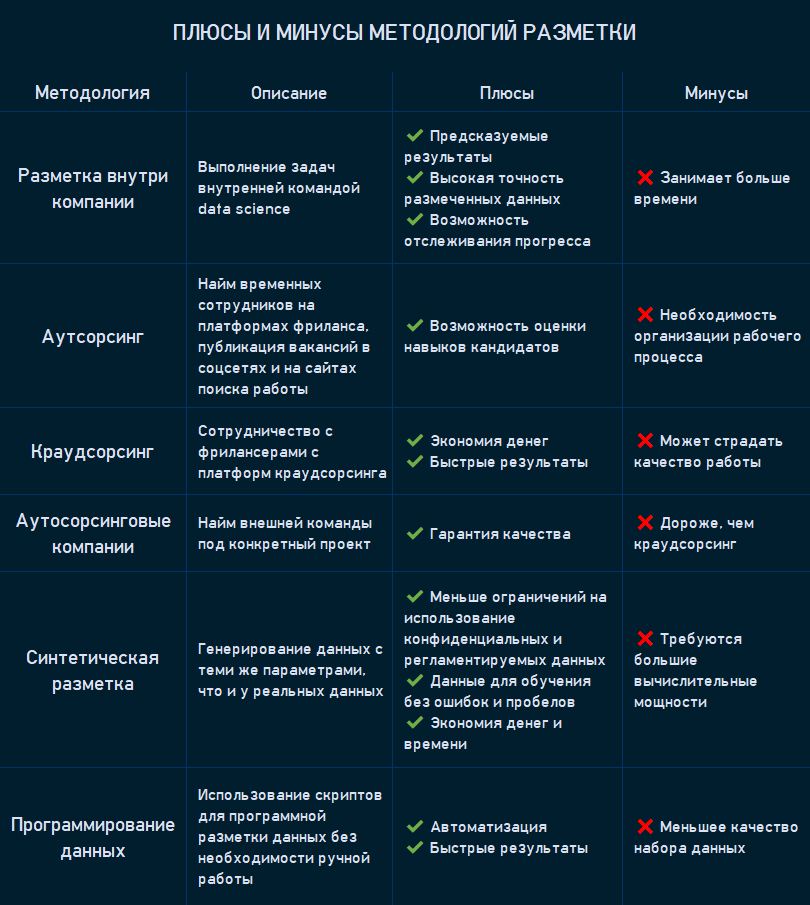
Разметка внутри компании
Как гласит старая поговорка, «хочешь, чтобы дело было сделано хорошо, сделай его сам». Она отражает одну из основных причин выполнения разметки внутри компании. Поэтому когда вам нужно обеспечить максимально возможную точность разметки и иметь возможность следить за процессом, передайте эту задачу своей команде. Хотя внутренняя разметка гораздо медленнее других методик, описанных ниже, это отличный выбор, если у вашей компании достаточно человеческих, временных и финансовых ресурсов.
Допустим, вашей команде нужно выполнить анализ тональности текста. Анализ тональности текста отзывов о компании в социальных сетях и в разделах обсуждений на технических сайтах позволяет бизнесам оценивать свою репутацию и экспертизу в сравнении с конкурентами. Также это даёт возможность исследования тенденций отрасли для выработки стратегии развития.
Для построения адекватной модели необходимо собрать и разметить как минимум 90 тысяч отзывов. Если считать, что для разметки одного комментария сотруднику понадобится 30 секунд, при средней 8-часовой дневной смене ему нужно потратить 750 часов или почти 94 смены, иными словами, три месяца. Учитывая, что медианная ставка за час работы для data scientist-а в США составляет 36,27 доллара, разметка будет стоить вам 27202,5 доллара.
Можно упростить разметку, автоматизировав её полуконтролируемым обучением. Для этого стиля обучения используются и размеченные, и неразмеченные данные. Часть набора данных (допустим, 2000 отзывов) можно разметить для обучения модели классификации. Затем эта многоклассовая модель обучается на оставшейся части неразмеченных данных для поиска целевых значений — положительной, отрицательной и нейтральной тональности.
Для реализации проектов в различных отраслях, например, в финансовой, космической, медицинской или энергетической, обычно требуется оценка данных специалистами. Команды data science консультируются со специалистами отрасли о принципах разметки. В некоторых случаях специалисты размечают наборы данных самостоятельно.
Для нидерландского стартапа Sleep.ai компания Altexsoft разработала приложение DoIGrind, предназначенное для диагностики и мониторинга бруксизма. Бруксизм — это самопроизвольное скрежетание зубами или сжимание челюстей во время сна или бодрствования. Приложение основано на алгоритме классификации шума, обученного на наборе данных, состоящем из более 6 тысяч аудиосэмплов. Для поиска записей, связанных со звуками скрежетания зубами, клиент сам прослушал сэмплы и сопоставил их с атрибутами. Распознавание этих специфических звуков необходимо для извлечения атрибутов.
Преимущества
Предсказуемо хорошие результаты и контроль за процессом. Если вы доверяете своим сотрудникам, то не будете покупать кота в мешке. Data scientist-ы и другие специалисты компании заинтересованы в максимально качественном результате, потому что именно они будут работать с размеченным набором данных. Также вы можете контролировать производительность команды, чтобы убедиться, что она укладывается в график проекта.
Недостатки
Это медленный процесс. Чем выше качество разметки, тем больше времени она занимает. Вашей команде data science потребуется дополнительное время для правильной разметки, а оно обычно становится ограниченным ресурсом.
Краудсорсинг
Зачем тратить лишнее время на найм людей, если можно сразу взяться за дело при помощи краудсорсинговой платформы?
Amazon Mechanical Turk (MTurk) — одна из ведущих платформ, предоставляющих услуги рабочей силы на заказ. Клиенты регистрируются на ней как заказчики и создают свои проекты как один или несколько HIT (Human Intelligence Task) на веб-сайте Mechanical Turk Requester. Сайт предоставляет пользователям простой интерфейс для создания задач разметки. Представители MTurk заявляют, что благодаря обширному сообществу работников сервиса разметка тысяч изображений вместо дней или недель занимает всего несколько часов.
Ещё на одной международной онлайн-площадке, Clickworker, есть более одного миллиона работников, готовых к выполнению задач разметки изображений или видео, а также оценки тональности текста. Первые этапы рабочего процесса похожи на этапы в MTurk. Этапы обработки задач и их распределения отличаются. Зарегистрированные заказчики размещают свои заказы с заранее выбранными спецификациями и запросами, а команда платформы создаёт решение и публикует требуемый набор навыков на платформе заказов для фрилансеров, после чего начинается магия.
Преимущества
Быстрые результаты. Краудсорсинг — разумный выбор для больших проектов, но с простыми наборами данных. Например, задачи категоризации изображений легковых автомобилей для проектов компьютерного зрения не потребуют много времени и могут выполняться работниками с обычным уровнем знаний. Скорости также можно добиться, разбив проект на микрозадачи, чтобы фрилансеры могли работать над ними одновременно. Именно так организует рабочий процесс Clickworker. Клиенты MTurk сами должны разбивать проекты на этапы.
Доступность по цене. Заказ выполнения задач разметки на этих платформах не будет стоить вам целого состояния. Например, Amazon Mechanical Turk позволяет задавать награду за каждую задачу, что даёт заказчикам свободу выбора. Например, при награде в 0,05 доллара за каждый HIT и одном изображении на странице вы сможете разметить 2000 изображений за 100 долларов. Учитывая комиссию в 20% за HIT, состоящие из девяти или менее задач, окончательная сумма за малый набор данных будет равна 120 долларам.
Недостатки
Использование посторонних людей для разметки данных может сэкономить вам время и деньги, однако краудсорсинг имеет свои недостатки, и главным из них является риск получения некачественного набора данных.
Неодинаковое качество размеченных данных. Люди, повседневный заработок которых зависит от количества завершённых задач, стремясь выполнить как можно больше работы, могут не следовать рекомендациям по задаче. Иногда ошибки в аннотациях могут быть связаны с языковым барьером.
Для решения этой проблемы и обеспечения максимально возможного качества услуг работников платформы краудсорсинга используют инструменты контроля качества. Онлайн-площадки проверяют навыки работников при помощи тестов и обучения, мониторинга оценок репутации, предоставляют статистику, отзывы заказчиков, аудиты, а также позволяют предварительно обсуждать требования к результатам. Также клиенты могут заказать выполнение конкретной задачи у нескольких работников и проверить его перед отправкой платежа.
Вы как заказчик должны убедиться, что с вашей стороны всё в порядке. Представители платформ рекомендуют давать чёткие и понятные инструкции к задачам, использовать короткие вопросы и списки пунктов, а также предоставлять примеры хорошо и плохо выполненных задач. Если в вашей задаче разметки необходимо рисовать ограничивающие прямоугольники, то можно снабдить правила разметки иллюстрациями.

Понятная иллюстрация того, как надо и не надо выполнять разметку изображений
Необходимо указать требования к формату и сообщить фрилансерам, если вы хотите, чтобы они использовали конкретные инструменты или методики. Также для повышения точности аннотаций можно попросить работников пройти квалификационный тест.
Аутсорсинг конкретным людям
Одним из способов ускорения разметки является поиск фрилансеров на одном из множества веб-сайтов, занимающихся рекрутингом и фрилансом, или же в социальных сетях.
Фрилансеры с разным уровнем образования регистрируются на платформе UpWork. Вы можете рекламировать свои задачи или искать профессионалов, фильтруя их по уровню навыков, местоположению, почасовой ставке, успешности выполняемых работ, общему заработку, уровню английского и другим параметрам.
Если вы хотите публиковать объявления о работе в социальных сетях, то первым делом в голову приходит сайт LinkedIn с его 500 миллионами ползователей. Рекламу работы можно публиковать на странице компании или в соответствующих группах. Благодаря репостам, лайкам и комментариям вашу вакансию увидит больше заинтересованных пользователей.
Посты в Facebook, Instagram и Twitter тоже могут помочь быстрее найти команду специалистов.
Преимущества
Вы знаете, кого нанимаете. Чтобы убедиться, что претенденты сделают работу правильно, можно проверить их навыки при помощи тестов. Учитывая, что при аутсорсинге вы нанимаете команду малого или среднего размера, у вас будет возможность контролировать её работу.
Недостатки
Необходимо будет организовать рабочий процесс. Вам потребуется создать шаблон задачи и обеспечить его интуитивную понятность. Например, если вы работаете с данными в виде изображений, то можно использовать Supervising-UI, обеспечивающий веб-интерфейс для задач разметки. Этот сервис позволяет создавать задачи, в которых требуются множественные метки. Для обеспечения защиты данных разработчики рекомендуют использовать Supervising-UI в локальной сети.
Если вы не хотите создавать собственный интерфейс заданий, предоставьте специалистам-аутсорсерам предпочитаемый вами инструмент разметки. Подробнее мы поговорим об этом в разделе об инструментах.
Также вы отвечаете за составление подробных и чётких инструкций, чтобы работники-аутсорсеры понимали их и создавали правильные аннотации. Кроме того, вам потребуется дополнительное время на отправку и проверку завершённых задач.
Аутсорсинг компаниям
Вместо того, чтобы нанимать временных сотрудников или полагаться на краудсорсинг, вы можете обратиться к аутсорсинговым компаниям, специализирующимся на подготовке данных для обучения. Такие организации позиционируют себя как альтернативу платформам краудсорсинга. Компании делают упор на то, что их профессиональный коллектив обеспечивает высокое качество данных для обучения. Благодаря этому сотрудники заказчика могут сконцентрироваться на более сложных задачах. Поэтому сотрудничество с аутсорсинговыми компаниями похоже на временный найм внешней команды.
Аутсорсинговые компании наподобие CloudFactory, Mighty AI, LQA и DataPure в основном размечают наборы данных для обучения моделей компьютерного зрения. CrowdFlower и CapeStart также проводят анализ тональности. CrowdFlower позволяет анализировать текстовые, а также графические и видеофайлы. Кроме того, клиенты CrowdFlower могут выбрать использование более сложного способа анализа тональности. Заказчики могут задавать наводящие вопросы, чтобы понять, почему люди реагируют на продукт или сервис определённым образом.
Компании предлагают различные пакеты или тарифные планы услуг, однако большинство из них не указывает информацию о ценах без запроса. Цена тарифного плана обычно зависит от количества услуг или рабочих часов, сложности задачи или размера набора данных.
CloudFactory позволяет рассчитывать цену услуг в соответствии с количеством рабочих часов
Преимущества
Высококачественные результаты. Компании заявляют, что их клиенты получают качественно размеченные данные.
Недостатки
Это дороже, чем краудсорсинг. Хотя большинство компаний не указывает стоимость услуг, пример ценообразования CloudFactory даёт нам понять, что их услуги чуть дороже, чем использование платформ краудсорсинга. Например, разметка 90000 отзывов (если цена за каждую задачу составляет 0,05 доллара) на платформе краудсорсинга стоила бы 4500 долларов. Найм профессиональной команды из 7-17 сотрудников, не включая руководителя, может стоить 5165–5200 долларов.
Выясните, выполняют ли сотрудники компании нужные вам виды задач разметки. Если для выполнения проекта необходимо наличие специалистов в какой-то сфере, то убедитесь, что компания нанимает людей, определяющих принципы разметки и устраняющих ошибки по ходу работы.
Синтетическая разметка
Эта методология заключается в генерации данных, имитирующих реальные данные с точки зрения выбранных пользователем необходимых параметров. Синтетические данные создаются генеративной моделью, обученной и валидированной на настоящем наборе данных.
Существует три типа генеративных моделей: Generative Adversarial Networks (GAN), Autoregressive models (AR) и Variational Autoencoders (VAE).
Generative Adversarial Networks. Модели GAN используют генеративные и дискриминативные сети во фреймворке игры с нулевой суммой. Этот фреймворк представляет собой соревнование, в котором генеративная сеть создаёт сэмплы данных, а дискриминативная сеть (обученная на реальных данных) пытается определить, реальны они (взяты из распределения настоящих данных) или сгенерированы (взяты из распределения модели). Игра продолжается до тех пор, пока генеративная модель не получит достаточно обратной связи для воссоздания изображений, неотличимых от реальных.
Autoregressive models. AR-модели генерируют переменные на основании линейного сочетания предыдущих значений переменных. В случае генерации изображений AR создают отдельные пиксели на основе предыдущих пикселей, расположенных сверху и слева от них.
Variational Autoencoders. VAE создают новые сэмплы данных из входящих данных при помощи методов кодирования и декодирования.
Синтетические данные используются в различных сферах. Их можно применять для обучения нейросетей — модели используются для задач распознавания объектов. В таких проектах специалистам необходимо подготавливать большие наборы данных, состоящие из текстовых, графических, звуковых или видеофайлов. Чем сложнее задача, тем крупнее сеть и набор данных для обучения. Если за короткий промежуток времени необходимо выполнить огромный объём работы, разумным решением становится генерация размеченного набора данных.
Например, работающие в финтехе data scientist-ы используют синтетический набор данных транзакций для тестирования эффективности существующих систем распознавания мошенничества и разработки более совершенных систем. Также сгенерированные наборы медицинских данных позволяют специалистам проводить исследования, не подвергая опасности тайну информации о здоровье пациентов.
Преимущества
Экономия денег и времени. Эта техника упрощает и ускоряет разметку. Синтетические данные быстро генерируются, подстраиваются под конкретную задачу, модифицируются для совершенствования модели и самого обучения.
Использование неконфиденциальных данных. Data scientist-ам не нужно запрашивать разрешение на использование таких данных.
Недостатки
Необходимость высокопроизводительных вычислительных мощностей. Для рендеринга и дальнейшего обучения моделей при такой методике требуются большие вычислительные ресурсы. Одним из вариантов решения проблемы является аренда облачных сервисов Amazon Web Services (AWS), Google Cloud Platform, Microsoft Azure, IBM Cloud, Oracle или других платформ. Можно пойти другим путём и получить дополнительные вычислительные ресурсы на децентрализованных платформах наподобие SONM.
Проблемы с качеством данных. Синтетические данные могут не полностью соответствовать реальным данным. Поэтому обученная на этих данных модель может потребовать дальнейшего улучшения посредством обучения на реальных данных по мере их доступности.
Программирование данных
Описанные ранее методологии и инструменты требуют человеческого участия. Однако data scientist-ы из проекта Snorkel разработали новый подход к созданию данных для обучения и для управления ими, устраняющий необходимость разметки вручную.
Эта методология, называемая программированием данных (data programming) заключается в написании функций разметки — скриптов, программно размечающих данные. Разработчики признают, что получающаяся разметка может быть менее точной, чем при ручном процессе, однако сгенерированный программой «шумный» набор данных можно применять для слабого контроля (weak supervision) высококачественных готовых моделей (например, создаваемых в TensorFlow или в других библиотеках).
Полученный при помощи функций разметки набор данных можно использовать для генеративных моделей обучения. Сделанные генеративной моделью предсказания используются для обучения дискриминативной модели при помощи описанного выше фреймворка игры с нулевой суммой.
Итак, «шумный» набор данных можно подчистить генеративной моделью и использовать для обучения дискриминативной модели.
Преимущества
Меньшая потребность в разметке вручную. Использование скриптов и движка анализа данных позволяет автоматизировать разметку.
Недостатки
Меньшая точность разметки. Может страдать качество программно размеченного набора данных.
Инструменты для разметки данных
Существует широкий ассортимент готовых браузерных и десктопных инструментов разметки. Если их функциональность соответствует вашим потребностям, то можно не заниматься затратным по времени и финансам процессом разработки ПО, подобрав наиболее подходящее готовое решение.
Некоторые из инструментов имеют и бесплатные, и платные версии. Бесплатная версия обычно содержит простейшие функции аннотирования и определённый уровень настройки интерфейсов, однако ограничивает количество форматов экспорта и изображений, которые можно обработать за фиксированный период времени. В платную версию разработчики могут включать дополнительные возможности: API, повышенный уровень удобства, дополнительные настройки и так далее.
Разметка изображений и видео
Начнём с одних из самых распространённых инструментов, предназначенных для упрощения и ускорения выполнения задач компьютерного зрения.
Annotorious. Annotorious — это бесплатный веб-инструмент для аннотирования и разметки с лицензией MIT. Он позволяет добавлять к изображениям на веб-сайте текстовые комментарии и рисунки. Инструмент можно легко интегрировать при помощи всего пары дополнительных строк кода. В разделе Demos можно узнать о функциях инструмента и выполнить различные задачи аннотирования.

Демо, в котором пользователь может выбрать прямоугольный фрагмент, растянув рамку и сохранив её на изображении
Демо Just the Basics демонстрирует основную функциональность — аннотирование изображений прямоугольными рамками. OpenLayers Annotation объясняет, как обрабатывать карты и изображения высокого разрешения с возможностью зума. При помощи беты функции OpenSeadragon пользователи также могут размечать такие изображения при помощи Annotorious в веб-приложении просмотра OpenSeadragon.
Разработчики работают над плагином Annotorious Selector Pack. В него будут включены такие функции разметки изображений, как выделение многоугольниками (разметка произвольной формы), выделение от руки, точками и Fancy Box. Инструмент Fancy Box позволяет затенять часть изображения, не попавшую в выделение.
Annotorious можно модифицировать и расширять при помощи множества плагинов, чтобы он соответствовал потребностям проекта.
Разработчики призывают пользователей оценивать и совершенствовать Annotorious, а затем делиться своими находками с сообществом.
LabelMe. LabelMe — ещё один открытый онлайн-инструмент. Его разработчики пишут, что это ПО должно помогать пользователям в создании баз данных изображений для исследований в сфере компьютерного зрения.
Когда мы говорим об онлайн-инструменте, то обычно подразумеваем работу на десктопе. Однако разработчики LabelMe рассчитывают охватить и мобильных пользователей, создав приложение с тем же названием. Оно есть в App store, для использования требуется регистрация.
Функциональность инструмента представлена двумя галереями — Labels и Detectors. Первая используется для сбора, сохранения и разметки изображений. Вторая позволяет детекторам объектов обучения работать в реальном времени.
Также пользователи могут скачать панель инструментов MATLAB, спроектированную для работы с изображениями в публичном наборе данных LabelMe. Разработчики призывают пользователей делать свой вклад в набор данных, они говорят, что важна любая помощь.
Десктопная версия инструмента с размеченным изображением из набора данных
Sloth. Sloth — бесплатный инструмент с высокой степенью гибкости. Он позволяет выполнять разметку изображений и видео для исследований в области компьютерного зрения. Одной из популярных сфер применения Sloth является распознавание лиц, поэтому если вам нужно разработать ПО, отслеживающее и идентифицирующее человека с камер наблюдения или определяющее, появлялся ли он на записях ранее, это можно сделать при помощи Sloth.
Пользователи могут добавлять неограниченное количество меток к каждому изображению или кадру видео, а каждая метка является парой «ключ-значение». Возможность добавления множества пар «ключ-значение» позволяет обрабатывать файлы более детально. Например, пользователи могут добавить ключ «type», отличающий метки-точки от меток правого или левого глаза.
Sloth поддерживает различные инструменты выделения изображений, в том числе точки, прямоугольники и многоугольники. Разработчики считают своё ПО фреймворком и набором стандартных компонентов. Это позволяет пользователям настраивать эти компоненты и создавать инструменты разметки, соответствующие их конкретным требованиям.
VoTT. Visual Object Tagging Tool (VoTT) компании Microsoft позволяет обрабатывать изображения и видео. Разметка — один из этапов разработки модели, поддерживаемых VoTT. Этот инструмент также позволяет data scientist-ам обучать и валидировать модели распознавания объектов.
Пользователи создают аннотацию, например, добавляют несколько меток на файл (как и в Sloth) и выбирают между квадратными или прямоугольными рамками. Кроме того, ПО сохраняет метки при каждой смене изображения или кадра видео.

Есть и другие инструменты, стоящие вашего внимания, например, Labelbox, Alp’s Labeling Tool, Comma Coloring, imglab, Pixorize, VGG Image Annotator (VIA), Demon image annotation plugin, FastAnnotationTool, RectLabel и ViPER-GT.
Разметка текста
Такие инструменты упрощают процесс разметки для задач, относящихся к NLP, например, анализа тональности, связывания именованных сущностей, категоризации текста, синтаксического парсинга и разметки или разметки частей речи.
Упомянутый выше Labelbox можно использовать и для разметки текста. Кроме простейших вариантов разметки инструмент позволяет разрабатывать, устанавливать и поддерживать собственные интерфейсы разметки.
Stanford CoreNLP. Во многих случаях data scientist-ы бесплатно и добровольно делятся своими разработками и знаниями. Представители Stanford Natural Language Processing Group предлагают свободный интегрированный NLP-тулкит Stanford CoreNLP, позволяющий выполнять различные задачи предварительной обработки и анализа текстовых данных.
Bella. Стоит попробовать и bella — ещё один открытый инструмент, предназначенный для упрощения и ускорения разметки текстовых данных. Обычно если набор данных был размечен в файле CSV или электронных таблицах Google, перед обучением модели специалистам необходимо преобразовать их в подходящий формат. Функции и простой интерфейс Bella делают его хорошей заменой электронным таблицам и CSV файлам.
Важные особенности bella — графический интерфейс пользователя (GUI) и бэкенд для управления размеченными данными.
Пользователь создаёт и настраивает проект для каждого набора данных, который он хочет разметить. В параметрах проекта можно задать визуализацию объектов, типы меток (например, positive, neutral и negative), а также поддерживаемые инструментом теги (например, из твитов и отзывов в Facebook).
Tagtog. Tagtog — стартап, разрабатывающий одноимённый веб-инструмент для аннотирования и категоризации текста. Пользователь может выбрать один из трёх вариантов: аннотирование текста вручную, найм команды для разметки или использование моделей машинного обучения для автоматизированного аннотирования.

Редактор для ручного аннотирования текста с автоматически адаптивным интерфейсом
Пользоваться Tagtog могут и новички, и профессионалы data science, потому что он не требует умения писать код.
Dataturks. Dataturks — ещё один стартап, предоставляющий инструменты подготовки данных для обучения. При помощи его продуктов команды могут выполнять такие задачи, как разметка частей речи, разметка распознавания именованных сущностей, классификация текста, модерирование и суммирование. Dataturks позволяет организовать рабочий процесс «загрузки данных, приглашения сотрудников и разметки», позволяя своим клиентам забыть о работе с электронными таблицами Google и Excel, а также с файлами CSV.
Пользователи могут выбрать один из трёх тарифных планов. Первый бесплатен, но имеет ограниченные функции. Два других предназначены для маленьких и крупных команд.
Кроме текстовых данных, инструменты Dataturks позволяют размечать изображения, аудио и видео.
Специалисты также рекомендуют попробовать такие сервисы и инструменты, как brat и SUTDAnnotator.
Разметка аудио
Для обучения высокопроизводительных нейросетей распознавания звуков и классификации музыки вам потребуются эффективные и простые в использовании инструменты разметки.
Praat. Praat — популярное свободное ПО для разметки аудиофайлов. При помощи Praat можно указывать метки времени событий в аудиофайле и аннотировать эти метки текстовой разметкой в компактном и портируемом файле TextGrid. Этот инструмент позволяет работать и со звуковыми, и с текстовыми файлами одновременно, так как текстовые аннотации связаны с аудиофайлами. Data scientist Кристина Ю говорит, что текстовый файл также можно легко обрабатывать при помощи любых скриптов для эффективной пакетной обработки и модифицировать отдельно от аудиофайла.
Speechalyzer. Название инструмента Speechalyzer говорит само за себя. ПО предназначено для ручной обработки крупных наборов речевых данных. В качестве примера его высокой производительности разработчики демонстрируют, как они почти в реальном времени разметили несколько тысяч аудиофайлов.
EchoML. EchoML — ещё один инструмент для аннотирования аудиофайлов. Он позволяет пользователям визуализировать данные.
Так как существует множество инструментов для разметки всех типов данных, выбор подходящего для вашего проекта будет непростой задачей. Практикующие data scientist-ы рекомендуют учитывать такие факторы, как сложность настройки, скорость разметки и точность.
Заключение
Получение высококачественных размеченных данных — это преграда для разработки, становящаяся более серьёзной при усложнении создаваемых моделей.
Из-за широкого выбора доступных онлайн инструментов аннотирования основной проблемой для команды data science является выбор оптимального ПО для конкретного проекта с точки зрения функциональности и затрат.
Кроме методик ручной разметки data scientist-ы нашли новые способы, частично автоматизирующие процесс и снижающие потребность вмешательства человека. Мы считаем, что в ближайшем будущем основной тенденцией развития станет развитие подобных методологий.

