
Поговорим о способах ограничить число исходящих запросов в распределенном приложении. Это нужно, если внешний API не позволяет обращаться к нему тогда, когда вам вздумается.
Вводные
Для начала немного вводных. Есть наше приложение и есть некий внешний сервис. Например, какое-то банковское ПО, API для отслеживания почтовых отправлений, что угодно. При этом наше приложение не просто использует его, там куча очень важной для нас информации. Прибыль компании напрямую зависит от объема выгруженных оттуда данных. Мы понимаем, один сервер — это слишком мало и заводим себе пару десятков машин. Чтобы приложение масштабировалось лучше, делаем так: разбиваем весь объем на маленькие задачи и отправляем их в очередь. Каждый сервер извлекает их оттуда по одной. В таком сообщении указан, например, ID пользователя. Затем приложение скачивает данные для него и сохраняет их в базе. Большая и быстрая машина обработает много задач, маленькая и медленная — поменьше.
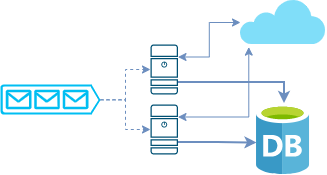
Создатели внешнего сервиса понимают, что, если не ограничивать наше взаимодействие, они начнут отказывать в обслуживании другим клиентам. Поэтому вводится лимит на запросы: теперь разрешено не более 1000 одновременных обращений к ним.
Немного подумав над условиями задачи находим решение — семафор. Он допускает, чтобы одновременно в критической секции было не более N потоков выполнения. Когда внутри скапливается предельное их количество — новые желающие ожидают на входе. Кто-то выходит значит кто-то ещё может войти.
Один семафор на машину
Делим лимит запросов на число доступных серверов (1000/20) и получаем по 50 конкурентных обращений на машину.
Простой семафор в .NET
private const int RequestsLimit = 50;
private static readonly SemaphoreSlim Throttler =
new SemaphoreSlim(RequestsLimit);
async Task<HttpResponseMessage> InvokeServiceAsync(HttpClient client)
{
try
{
await Throttler.WaitAsync().ConfigureAwait(false);
return await client.GetAsync("todos/1").ConfigureAwait(false);
}
finally
{
Throttler.Release();
}
}В .NET Core можно сделать типизированный HttpClient, получится очень в духе новых веяний, я не буду останавливаться на этом подробнее, но вы можете посмотреть сюда. Там и в целом такой подход раскрывается детальнее, чем я делаю это здесь.
Попробуем проанализировать то, что получилось.

В этой конфигурации будут возникать ситуации, когда одна машина свободна, а другие перегружены. Этого можно избежать, беря задачу в работу при условии, что на конкретном сервере число сообщений в обработке не достигло предела. Тогда возникнет другая проблема — как только задача выполнится занять её место будет некому, сперва потребуется получить новое сообщение из очереди. Можно постоянно держать систему слегка перегруженной — это приведет к тому, что некоторые задачи-неудачники долго будут висеть на входе в критическую секцию. В целом, у такого подхода есть потенциал, с ним можно достигнуть хорошей производительности с небольшим тюнингом и при определенных условиях.
Подведем ему некий итог:
Плюсы:
Простой код
Ресурсы машины используются эффективно
Минусы:
Не полностью утилизируется канал во внешний сервис
Один семафор на всех
Подумаем, в какую сторону двинуться теперь. Попробуем сделать семафор общим ресурсом для всех серверов. Так тоже без проблем не обойдется — будет нужно тратить время перед каждым запросом во внешнюю систему на обращение к сервису-throttler-у. Но администрировать такое, наверное, проще — за состоянием одного семафора легче следить, не надо подбирать лимит под каждую машину в отдельности. Как же сделать общий троттлер? Ну, конечно же в Redis.
С точки зрения пользователя Redis однопоточный (он так выглядит). Это круто, большая часть проблем с конкурентным доступом к нему сразу снимается.
В Redis нет готового семафора, но можно построить его на сортированных множествах.
Писать код для него будем на Lua. Интерпретатор Lua встроен в Redis, такие скрипты выполняются одним махом, атомарно. Мы могли бы без этого обойтись, но так код получится ещё сложнее, придется учитывать конкуренцию между серверами за отдельные команды.
Теперь подумаем, что писать. Учтём, что машина, взявшая блокировку, может никогда её не отпустить. Вдруг кто-то решит выключить рубильник или что-то пойдет не по плану в момент обновления нашего приложения. Учтём также, что у нас может быть несколько таких семафоров. Это пригодится, например, для разных внешних сервисов, API-ключей или если мы захотим выделить отдельный канал под приоритетные запросы.
Скрипт для Redis
--[[
KEYS[1] - Имя семафора
ARGV[1] - Время жизни блокировки
ARGV[2] - Идентификатор блокировки, чтобы её можно было возвратить
ARGV[3] - Доступный объем семафора
]]--
-- Будем использовать команды с недетерминированным результатом,
-- Redis-у важно знать заранее
redis.replicate_commands()
local unix_time = redis.call('TIME')[1]
-- Удаляем блокировки с истёкшим TTL
redis.call('ZREMRANGEBYSCORE', KEYS[1], '-inf', unix_time - ARGV[1])
-- Получаем число элементов в множестве
local count = redis.call('zcard', KEYS[1])
if count < tonumber(ARGV[3]) then
-- добавляем блокировку в множество, если есть место
-- время будет являться ключем сортировки (для последующий чистки записей)
redis.call('ZADD', KEYS[1], unix_time, ARGV[2])
-- Возвращаем число взятых блокировок (например, для логирования)
return count
end
return nilЧтобы освободить блокировку будем удалять элемент из сортированного множества. Это одна команда. Обойдемся без отдельного скрипта, многие клиенты в т.ч. и для .NET это умеют.
Подробнее о вариантах реализации блокировок с Redis и семафоров в частности можно посмотреть здесь.
Иногда внешний сервис ограничивает число обращений другим образом, например, разрешает делать не более 1000 запросов в минуту. В этом случае в Redis можно завести счётчик с фиксированным временем жизни.
В коде нашего приложения сделаем оболочку вокруг написанного скрипта, некий класс, экземпляр которого заменит семафор из первого варианта.
Код для приложения
public sealed class RedisSemaphore
{
private static readonly string AcquireScript = "...";
private static readonly int TimeToLiveInSeconds = 300;
private readonly Func<ConnectionMultiplexer> _redisFactory;
public RedisSemaphore(Func<ConnectionMultiplexer> redisFactory)
{
_redisFactory = redisFactory;
}
public async Task<LockHandler> AcquireAsync(string name, int limit)
{
var handler = new LockHandler(this, name);
do
{
var redisDb = _redisFactory().GetDatabase();
var rawResult = await redisDb
.ScriptEvaluateAsync(AcquireScript, new RedisKey[] { name },
new RedisValue[] { TimeToLiveInSeconds, handler.Id, limit })
.ConfigureAwait(false);
var acquired = !rawResult.IsNull;
if (acquired)
break;
await Task.Delay(10).ConfigureAwait(false);
} while (true);
return handler;
}
public async Task ReleaseAsync(LockHandler handler, string name)
{
var redis = _redisFactory().GetDatabase();
await redis.SortedSetRemoveAsync(name, handler.Id)
.ConfigureAwait(false);
}
}
public sealed class LockHandler : IAsyncDisposable
{
private readonly RedisSemaphore _semaphore;
private readonly string _name;
public LockHandler(RedisSemaphore semaphore, string name)
{
_semaphore = semaphore;
_name = name;
Id = Guid.NewGuid().ToString();
}
public string Id { get; }
public async ValueTask DisposeAsync()
{
await _semaphore.ReleaseAsync(this, _name).ConfigureAwait(false);
}
}Посмотрим, что получилось.
Плюсы:
Просто конфигурировать лимит
Канал используется эффективно
Легко наблюдать за утилизацией канала
Минусы:
Дополнительный элемент инфраструктуры
Ещё одна точка отказа
Накладные расходы на обращение к Redis-у
Нетривиальный код
Если вы используете Redis в проекте, то почему бы не сделать на нём и блокировки. Тащить же его к себе только ради этого уже не так весело. Что-то подобное можно реализовать, используя базу данных, но скорее всего это добавит немало хлопот и накладных расходов. Второй минус лично мне не кажется очень существенным. Что ни говори, а отказывает Redis обычно не так уж часто, особенно, если это SaaS.
Легкость настройки такой блокировки – это существенный плюс. Не надо все перенастраивать при каждом масштабировании, подбирать лимиты под машины. Можно следить за утилизацией канала в графане, это удобно.
Думаю, можно реализовать троттлинг исходящих запросов и на уровне инфраструктуры, но мне кажется удобным иметь в коде контроль над состоянием блокировки. Кроме того, настроить это в чужих облаках наверняка будет непросто. А вам приходилось когда-нибудь ограничивать число исходящих запросов? Как делаете это вы?


