Представьте, что у вас имеется большой проект по машинному обучению. Естественно, сначала над ним работали дата-сайентисты, а затем инженеры-программисты, которые оптимизировали модель для быстрого выполнения на определенных GPU. В итоге модель изменилась так сильно, что дата-сайентисты перестали в ней что-либо понимать. Специально к старту нового потока курса «Профессия Data Scientist» делимся материалом именно о том, как решить эту проблему. Конечно же, нужно буквально предоставить дата-сайентистам и инженерам общий язык. Подробности под катом.

В реальной жизни в проектах машинного обучения между специалистами по Data Science и разработчиками регулярно возникают трения. Они связаны в основном с проблемами трансляции модели машинного обучения (выраженной, как правило, в математических терминах) в код, который сможет масштабироваться на несколько графических или центральных процессоров. Множество раз мы сталкивались с ситуацией, когда:
В реальной жизни в проектах машинного обучения между специалистами по Data Science и разработчиками регулярно возникают трения. Они в основном связаны с проблемами трансляции модели машинного обучения (выраженной, как правило, в математических терминах), в код, который сможет масштабироваться на несколько графических или центральных процессоров. Множество раз мы сталкивались с такой ситуацией:
Ситуация, описанная выше, — следствие высокого уровня сложности, возникающего при оптимизации моделей машинного обучения с применением популярных высокопроизводительных библиотек, к примеру CuBLAS, MKL и CuDNN. Эти библиотеки необходимы для оптимизации производительности модели, но содержат множество низкоуровневых процедур в таких областях, как проверка памяти, параллелизм, инструментальная логика, — и это лишь некоторые из модификаций, которые делают модель почти непонятной для работавших с ней вначале людей. В больших группах специалистов Data Science эта проблема усложняется на порядок.
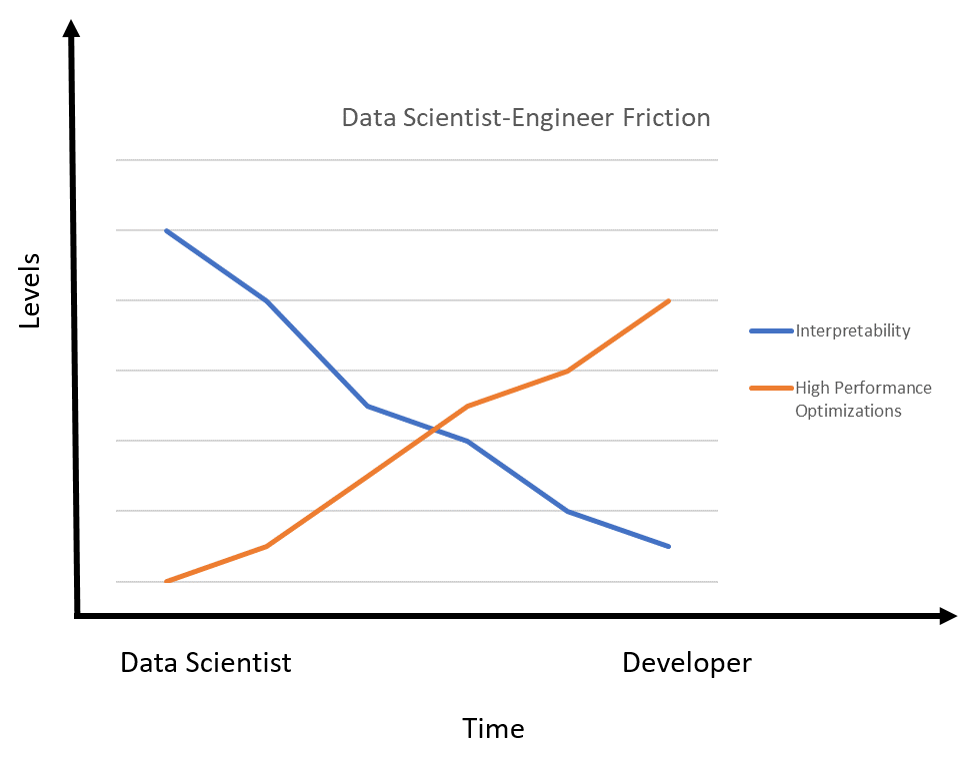
Трения между исследователями и инженерами — вездесущая проблема в любых крупномасштабных операциях Data Science. Крупные интернет-машины: Google, Amazon или Facebook, сталкиваются со многими формами этих трудностей в любой проблеме машинного обучения, которую они хотят решить. В прошлом году Лаборатория искусственного интеллекта (Facebook AI Labs) выпустила первую версию Tensor Comprehensions — библиотеки с открытым исходным кодом, помогающей преодолеть разрыв между специалистами Data Science и инженерами. Концептуально Tensor Comprehensions предоставляет математический язык, позволяющий исследователям моделировать проблемы, которые легко преобразуются в высокопроизводительный код. Лежащие в основе Tensor Comprehensions идеи изложены в исследовательской работе, опубликованной Facebook AI Labs в прошлом году. Первый релиз Tensor Comprehensions содержит 4 фундаментальных компонента:
Tensor Comprehensions строится на идеях других высокопроизводительных вычислительных фреймворков, таких как Halide. Tensor Comprehensions фактически использует компилятор Halide как библиотеку. В частности, фреймворк полагается на промежуточные средства представления (IR) и анализа в Halide и объединяет его с полиэдрическими методами компиляции, так что разработчики могут писать слои с помощью схожего синтаксиса высокого уровня, но без необходимости явно указывать, как он будет выполняться.

Источник
Использование Tensor Comprehensions во фреймворках глубокого обучения достаточно просто, оно показано ниже, в коде на PyTorch:
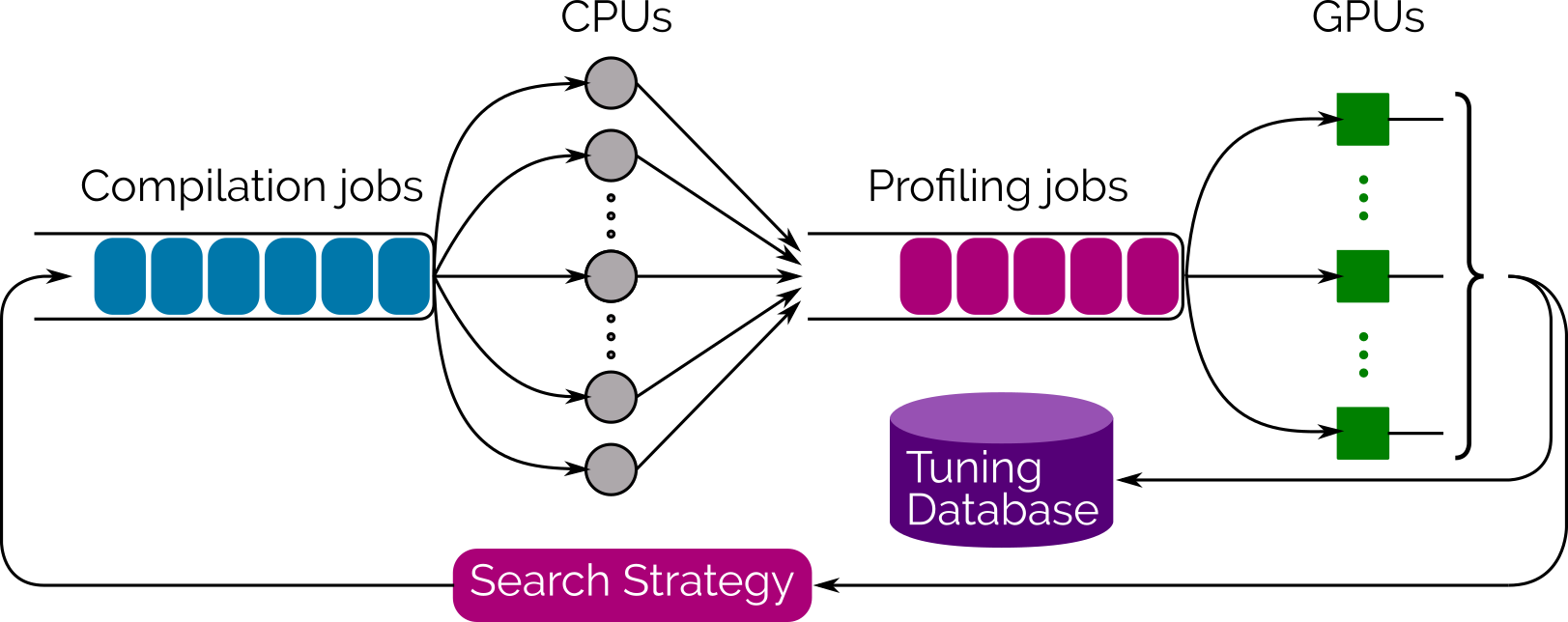
Код выше создаёт программу, оптимизированную для работы на архитектуре CUDA GPU. Tensor Comprehensions опирается на методику, называемую «полиэдрическая [прим. перев. — буквально „многогранная“, поскольку полагается на представление программ, особенно массивов и циклов, в виде параметрических многогранников] компиляция», для преодоления входного сопротивления несоответствия между логической схемой тензорных операций высокого уровня (упорядочения размеров) и форматом данных, который ожидает генератор кода полиэдрического типа. Полиэдрическая компиляция позволяет Tensor Comprehensions для каждой новой сети планировать вычисления отдельных элементов тензора по требованию. Другим важным вкладом Tensor Comprehensions является использование библиотеки автонастройки множества объединённых графических процессоров (multi-GPU), основанной на эволюционных методах поиска, генерирующих и оценивающих тысячи вариантов реализации и, наконец, выбирающих наиболее эффективные варианты.
Источник
Первоначальные тесты показали, что Tensor Comprehensions уже соответствует и даже во многих случаях превосходит производительность нативных высокопроизводительных библиотек. Следующая столбцовая диаграмма иллюстрирует прирост производительности, наблюдаемый при сравнении ядер, автоматически полученных с помощью Tensor Comprehensions, с существующими альтернативами на Caffe2 и ATen (которые используют реализации библиотек производителя, например CuDNN).

Источник
Tensor Comprehensions доступна на Github как релиз с открытым исходным кодом. Будущие выпуски могут расширить фреймворк поддержкой других популярных библиотек глубокого обучения — TensorFlow или MxNet. Даже если вы не пользуетесь фреймворком, идеи, лежащие в основе Tensor Comprehensions, дают представление о том, как смягчить трения между исследователями и инженерами, занятыми в большом проекте ML.
На тот случай если вы задумали сменить сферу или повысить свою квалификацию — промокод HABR даст вам дополнительные 10% к скидке указанной на баннере.

В реальной жизни в проектах машинного обучения между специалистами по Data Science и разработчиками регулярно возникают трения. Они связаны в основном с проблемами трансляции модели машинного обучения (выраженной, как правило, в математических терминах) в код, который сможет масштабироваться на несколько графических или центральных процессоров. Множество раз мы сталкивались с ситуацией, когда:
В реальной жизни в проектах машинного обучения между специалистами по Data Science и разработчиками регулярно возникают трения. Они в основном связаны с проблемами трансляции модели машинного обучения (выраженной, как правило, в математических терминах), в код, который сможет масштабироваться на несколько графических или центральных процессоров. Множество раз мы сталкивались с такой ситуацией:
- Специалист по Data Science или исследователь пишет алгоритм машинного обучения с помощью высокоуровневой нотации, например, на завоёвывающем сердца исследователей PyTorch.
- Инженер берёт модель и транслирует её в более действенный код, возможно, используя другой фреймворк: TensorFlow или Caffe2, и начинает применять библиотеки производительности вроде CuBLAS, чтобы оптимизировать выполнение модели на разных GPU.
- Спустя какое-то время трансформации модели настолько велики, что специалист по Data Science едва может понять её. Другими словами, знания о модели полностью переходят от дата-сайентистов к инженерам.
Ситуация, описанная выше, — следствие высокого уровня сложности, возникающего при оптимизации моделей машинного обучения с применением популярных высокопроизводительных библиотек, к примеру CuBLAS, MKL и CuDNN. Эти библиотеки необходимы для оптимизации производительности модели, но содержат множество низкоуровневых процедур в таких областях, как проверка памяти, параллелизм, инструментальная логика, — и это лишь некоторые из модификаций, которые делают модель почти непонятной для работавших с ней вначале людей. В больших группах специалистов Data Science эта проблема усложняется на порядок.
Влияние Tensor Comprehensions
Трения между исследователями и инженерами — вездесущая проблема в любых крупномасштабных операциях Data Science. Крупные интернет-машины: Google, Amazon или Facebook, сталкиваются со многими формами этих трудностей в любой проблеме машинного обучения, которую они хотят решить. В прошлом году Лаборатория искусственного интеллекта (Facebook AI Labs) выпустила первую версию Tensor Comprehensions — библиотеки с открытым исходным кодом, помогающей преодолеть разрыв между специалистами Data Science и инженерами. Концептуально Tensor Comprehensions предоставляет математический язык, позволяющий исследователям моделировать проблемы, которые легко преобразуются в высокопроизводительный код. Лежащие в основе Tensor Comprehensions идеи изложены в исследовательской работе, опубликованной Facebook AI Labs в прошлом году. Первый релиз Tensor Comprehensions содержит 4 фундаментальных компонента:
- Язык высокого уровня для выражения возникающих в ML тензорных вычислений с синтаксисом, обобщающим нотацию Эйнштейна.
- Сквозную компиляцию, способную понизить тензоры до эффективного GPU кода. Она обеспечивает высокую базовую производительность пользовательских операторов и остаётся конкурентоспособной по сравнению с библиотеками поставщиков на стандартных операторах.
- Коллекция алгоритмов компиляции полиэдрических компиляторов с определённым доменом и целевой ориентацией. В отличие от компиляторов для распараллеливания общего назначения оптимизация Tensor Comprehensions направлена в первую очередь на уменьшение накладных расходов на запуск и синхронизацию с помощью слияния ядер, а также способствуют многоуровневому параллелизму и продвижению на более глубокие уровни иерархии памяти.
- Фреймворк автонастройки, использующий преимущества JIT-компиляции и кэширования кода. Интеграция с ML-фреймворками, например PyTorch и Caffe2 (эти фреймворки — ядро стека ML Facebook).
Tensor Comprehensions строится на идеях других высокопроизводительных вычислительных фреймворков, таких как Halide. Tensor Comprehensions фактически использует компилятор Halide как библиотеку. В частности, фреймворк полагается на промежуточные средства представления (IR) и анализа в Halide и объединяет его с полиэдрическими методами компиляции, так что разработчики могут писать слои с помощью схожего синтаксиса высокого уровня, но без необходимости явно указывать, как он будет выполняться.
Источник
Использование Tensor Comprehensions во фреймворках глубокого обучения достаточно просто, оно показано ниже, в коде на PyTorch:
import tensor_comprehensions as tc
import torch
lang = """
def matmul(float(M, K) A, float(K, N) B) -> (C) {
C(m, n) +=! A(m, r_k) * B(r_k, n)
}
"""
matmul = tc.define(lang, name="matmul")
mat1, mat2 = torch.randn(3, 4).cuda(), torch.randn(4, 5).cuda()
out = matmul(mat1, mat2)
Код выше создаёт программу, оптимизированную для работы на архитектуре CUDA GPU. Tensor Comprehensions опирается на методику, называемую «полиэдрическая [прим. перев. — буквально „многогранная“, поскольку полагается на представление программ, особенно массивов и циклов, в виде параметрических многогранников] компиляция», для преодоления входного сопротивления несоответствия между логической схемой тензорных операций высокого уровня (упорядочения размеров) и форматом данных, который ожидает генератор кода полиэдрического типа. Полиэдрическая компиляция позволяет Tensor Comprehensions для каждой новой сети планировать вычисления отдельных элементов тензора по требованию. Другим важным вкладом Tensor Comprehensions является использование библиотеки автонастройки множества объединённых графических процессоров (multi-GPU), основанной на эволюционных методах поиска, генерирующих и оценивающих тысячи вариантов реализации и, наконец, выбирающих наиболее эффективные варианты.
Источник
Первоначальные тесты показали, что Tensor Comprehensions уже соответствует и даже во многих случаях превосходит производительность нативных высокопроизводительных библиотек. Следующая столбцовая диаграмма иллюстрирует прирост производительности, наблюдаемый при сравнении ядер, автоматически полученных с помощью Tensor Comprehensions, с существующими альтернативами на Caffe2 и ATen (которые используют реализации библиотек производителя, например CuDNN).
Источник
Tensor Comprehensions доступна на Github как релиз с открытым исходным кодом. Будущие выпуски могут расширить фреймворк поддержкой других популярных библиотек глубокого обучения — TensorFlow или MxNet. Даже если вы не пользуетесь фреймворком, идеи, лежащие в основе Tensor Comprehensions, дают представление о том, как смягчить трения между исследователями и инженерами, занятыми в большом проекте ML.
На тот случай если вы задумали сменить сферу или повысить свою квалификацию — промокод HABR даст вам дополнительные 10% к скидке указанной на баннере.
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Machine Learning
- Разработчик игр на Unity
- Курс по JavaScript
- Профессия Веб-разработчик
- Профессия Java-разработчик
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности


")
