
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Представим простую историю. Вы заканчиваете делать рефакторинг, которым занимались последние 2 недели. Вы хорошо над ним поработали, сделали несколько ключевых изменений в проекте. Делаете долгожданный pull request и ... 12 конфликтов.
Или другой вариант. Вы работали и постоянно подливали себе основную ветку, чтобы код сильно не расходился. Делаете pull request, он висит несколько дней, после этого вы получаете approve и ... 15 конфликтов. Кто-то слил свой большой pull request раньше.
Но ведь вы всё делали правильно. Работали над рефакторингом в отдельной ветке. Почему вам надо разрешать эти конфликты и можно ли как-то попроще? Можно ли работать в какой-то особой ветке, которую потом легко сливать в главную ветку без конфликтов? Оказывается, можно.
В этой статье мы поговорим про технику Branch by Abstraction. Как она может помочь не копить большие изменения в нашей ветке, избегать merge hell и прокачать ваш CI.
Я буду описывать примеры из Android-разработки, но они также справедливы для большинства типов проектов и платформ.
А какой ещё branch может быть?
Итак, Branch by Abstraction. Давайте начнём с первого слова — branch. Обычно оно у нас чётко ассоциируется с веткой в репозитории. Начиная делать новую задачу, мы машинально пишем:
git checkout -b feature/new-acquiringи мысленно понимаем, что создали новую ветку, новый branch.
Давайте считать отсюда и далее по тексту, что branch — это действительно ветвь, но не обязательно в репозитории. Давайте будем под этим словом понимать что-то более общее типа абстрактной ветви кода.
Как мы можем сделать абстрактную ветвь? Разными способами.
Можем просто скопировать файл. Есть файл New File.txt, мы делаем копию Copy of New File.txt. Появится новая версия кода, новая ветвь.
Можем в коде написать условный оператор
ifи сделать немного «копипаста». Появится новая версия кода.Можно написать конфигурацию make-файлов таким образом, чтобы у нас были разные версии кода.
Можно продолжать фантазировать и придумывать другие способы.
Примеры выше — максимально банальные, но они хорошо показывают, как можно представить в голове абстрактную ветвь кода.
Как вы уже догадались, Branch by Abstraction — это техника, при которой мы создаём ветвь кода через абстракцию в нём.
А мне это точно надо?
Когда нужно применять Branch by Abstraction? Для каждой фичи, или как?
С точки зрения процесса разработки, Branch by Abstraction — это инструмент. В одном случае он принесёт пользу, в другом — нет.
Скорее всего, он не нужен, когда:
задача мелкая, мало изменений, небольшой pull request. Поэтому вряд ли будут проблемы слить изменения в develop;
если делаем приложение в одиночку, то, скорее всего, делаем задачи последовательно. Вряд ли мы будем самостоятельно создавать ситуацию, где в разных ветках меняем один и тот же код;
если проект хорошо разделён на изолированные модули и созданы условия, в которых мы работаем изолированно над своим модулем.
Но вот ситуации, когда Branch by Abstraction может сильно помочь:
делаем большой долгий рефакторинг или фичу в общем коде;
когда наша ветка в репозитории может устареть. Например, мы часто отвлекаемся на другие задачи и временно откладываем наполовину сделанную задачу.
Что же такое Branch by Abstraction?
Одним из главных евангелистов по теме Branch by Abstraction принято считать Пола Хамманта (одна из первых статей на тему). В интернете можно найти много материалов от него. Также можно прочитать более компактную версию у Мартина Фаулера.
Лично мне нравится описание, которое дал Мартин:
“Branch by Abstraction” is a technique for making a large-scale change to a software system in gradual way that allows you to release the system regularly while the change is still in-progress.
Если говорить простым языком, то Branch by Abstraction — это такая техника разработки, при которой вы делаете задачу постепенно и одновременно релизите приложение.
Так как Branch by Abstraction — это техника, то она должна состоять из набора правил и инструкций. Так оно и есть. Обычно выделяют 4-5 шагов, которые нужно сделать, чтобы следовать этой технике. Их мы и рассмотрим в этой части.
Я буду использовать общепринятые в Android-разработке наименования классов. Но в целом это никак не привязано к платформе и может применяться где угодно.
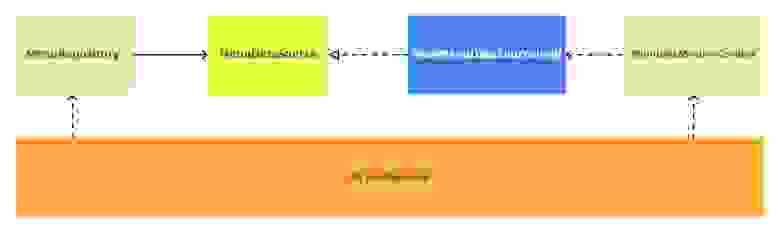
Итак, предположим, у нас есть класс MenuRepository и он использует источник данных MenuDataSource как зависимость. Супер-стандартная ситуация. Выглядит примерно так:
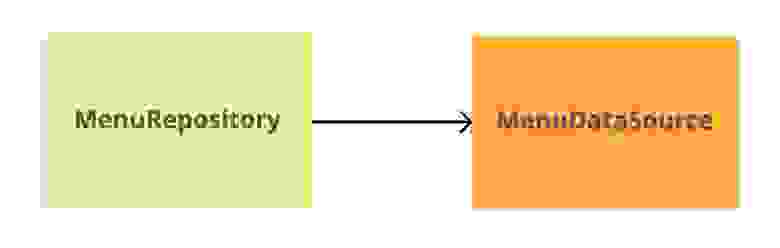
Наша задача — отрефакторить MenuDataSource или перейти на новую реализацию источника данных.
Шаг 1: введение абстракции
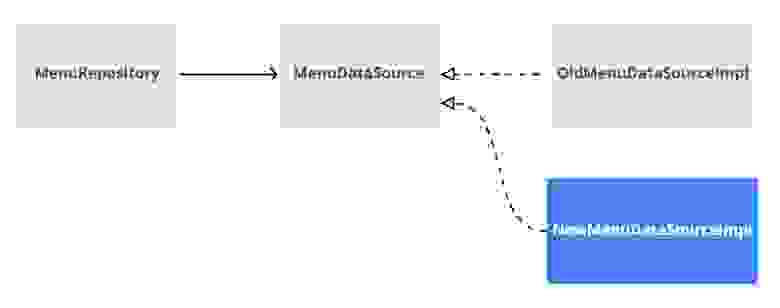
Первым делом вводим абстракцию. Например, вводим интерфейс MenuDataSource, а реализацию уносим в MenuDataSourceImpl.

В общем случае абстракция может быть введена любым способом: через композицию, наследование или функциональную абстракцию. В примерах я буду использовать композицию как самую распространённую.
Такое изменение сразу можно и нужно сливать в основную ветку, оно безопасное и никак не влияет на работу и код MenuRepository.
Шаг 2: создаём новую реализацию
Её можно сделать для начала no-op или копию существующей. На схеме я её назвал NewMenuDataSourceImpl.
Это тоже можно сразу сливать в основную ветку. Единственное, что надо учесть: если вы делаете копию существующей реализации, то вместе с этим лучше скопировать и все тесты. Да, здесь будет дублироваться код, но это временное решение, на период работы над новой реализацией. Тесты в процессе будут тоже редактироваться и обновляться.
Шаг 3: включить для себя, выключить для всех остальных
Теперь нужно удостовериться, что можем работать над новой реализацией, тогда как для остальных разработчиков будет по умолчанию работать старая. В вашем проекте уже может быть рабочий механизм тогглов/флагов, тогда лучше делать через него. Если нет, то можно сделать это любым удобным способом. Главное, удостовериться, что абстракция будет выключена и не существует возможности её включить в рантайме. Например, если есть механизм тогглов, который присылает ваш бэкенд, то нужно иметь гарантии, что он не сможет включить вашу абстракцию на проде.
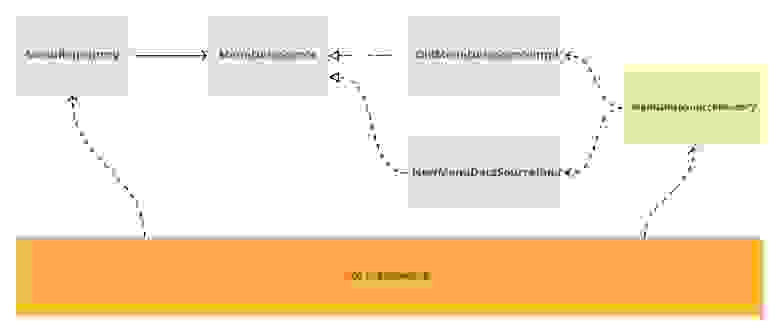
На схеме я добавил фабрику MenuDataSourceFactory, которая умеет производить нужный DataSource. Логика тогглов или другой механизм выбора нужной реализации пусть будет инкапсулирован там. Также на схеме добавил связь с DI в качестве одного из примеров, как MenuRepository может получить нужную версию DataSource.
Сливаем изменения в основную ветку. Поздравляю! С этого момента можно считать, что мы создали абстрактную ветку, ту самую Branch by Abstraction.
Шаг 4: итеративно делаем новую реализацию
На выступлении 2020 года Пол Хаммант приводит круговую диаграмму работы по Branch by Abstraction.
Из неё следует, что после того, как вы ввели абстракцию, можно работать в абстрактной ветке мелкими итеративными шагами: делать новую реализацию, рефакторить, писать тесты. Главное, за чем вы должны следить, — чтобы проект собирался и тесты проходили, т.е. чтобы был зеленый пайплайн в вашем CI.
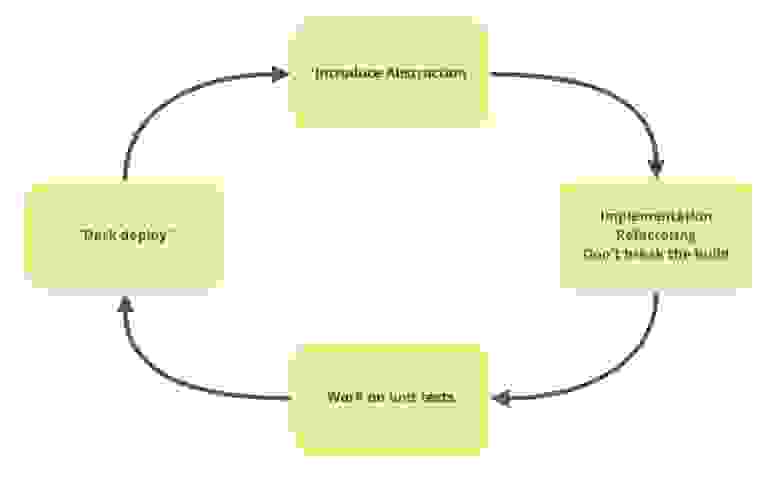
Интегрируя изменения маленькими частями и часто, вы будете избегать больших мержей и вдобавок ваши коллеги быстрее будут видеть изменения в коде. Если вдруг их задача находится где-то рядом, они быстрее увидят, что у вас происходит, и вы сможете это обсудить максимально рано.
Шаг 5: удаляем старую реализацию
После того как мы закончили работу над новой реализацией, старую можно удалять, как и механизм включения (удалить тогглы).
То есть в итоге всё будет выглядеть вот так:
Если надо, то можно удалить и абстракции. На мой взгляд, это не обязательно и зачастую не нужный шаг, только если вы не приближаетесь к той известной поговорке:
Любую проблему можно решить введением новой абстракции. За исключением проблемы чрезмерного количества абстракций.
Но если удалять всё, то станет всё совсем просто:

«Стоп! Все эти стрелочки влево вправо я видел, когда читал про инверсию зависимостей! Это тоже самое?» — можете справедливо спросить вы. Нет, не тоже самое.
Действительно, всё, что я нарисовал, можно встретить в статьях и книжках про «Инверсию зависимостей» (ту самую букву D из SOLID). Тоже выделяем интерфейс, рисуем стрелочку вправо — и вуаля.
Здесь надо понимать важное и принципиальное отличие. Когда мы говорим про инверсию зависимостей, то ключевую роль играет то, как модули или слои зависят друг от друга. Меняется ли направление зависимостей, если мы вводим абстракцию. Далеко не всегда выделение абстракции будет менять зависимость между модулями или слоями. На рисунке ниже показано это отличие.

Слева — инверсия зависимостей. Сначала Module 1 зависел от Module 2, а потом мы инвертировали это и теперь Module 2 зависит от Module 1.
Справа — не инверсия зависимостей. Как Module 1 зависел от Module 2, так он и остался зависеть.
Инверсия зависимостей — это принцип организации зависимостей в приложении. Она помогает, например, грамотно разделить бизнес-логику от логики приложения или инфраструктуры.
Branch by Abstraction — это техника, которая позволяет создать «виртуальную» ветку кода и работать в ней. Это никак не связано с организацией зависимостей в приложении.
Пример с кодом
Давайте посмотрим на то же самое в коде.
Для разнообразия я возьму не те же классы, а немного другой кейс. Это реальный код из приложения Додо Пиццы, только упрощённый и с удалением всего лишнего.
У нас есть класс CardPaymentInteractorImpl, который отвечает за кейс оплаты по карте. Он использует доменный сервис CardChargeService, чтобы произвести непосредственно оплату. cardChargeService нам приходит как зависимость. В данном случае уже есть абстракция (CardChargeService это интерфейс, его не нужно вводить).
interface CardChargeService {
fun chargeNewCard(
card: Card
): PaymentAuthorization
}
class CardPaymentInteractorImpl(
... // dependencies for interactor
private val cardChargeService: CardChargeService
) : CardPaymentInteractor {
override fun chargeOrder(...): Async<PaymentAuthorization> {
// some code
cardChargeService.chargeNewCardPayment(...)
// some code
}
...
}Делаем новую реализацию, пусть она называется CardChargeServiceAsyncImpl (новая асинхронная оплата, не будем заострять внимание на нейминге). И включаем нужную версию через DI. Всё просто.
class CardChargeServiceAsyncImpl(
... // dependencies
) : CardChargeService {
override fun chargeNewCard(card: Card): PaymentAuthorization {
// new implementation
}
}
@Provides
fun provideCardChargeService(
featureService: FeatureService
): CardChargeService {
return if (featureService.isEnabled(ASYNC_PAYMENT)) {
CardChargeServiceAsyncImpl(
... // dependencies
)
} else {
CardChargeServiceImpl(
... // dependencies
)
}
}После этого работаем над CardChargeServiceAsyncImpl, часто сливаем изменения в основную ветку. В процессе работы этот код может уезжать в релиз, в этом нет ничего страшного, потому что новая реализация закрыта тогглом.
Пример чуть посложнее
В примере выше мы рассмотрели вариант, где у нас для CardChargeService уже есть абстракция, поэтому всё выглядело слишком просто. Это некий идеальный кейс, который будет не всегда. У меня чаще бывает такое, что надо сделать какой-то рефакторинг и нет готовых абстракций для этого. Что можно сделать в таком случае?
Рассмотрим ещё один реальный, но упрощённый пример. Допустим, у нас есть класс MenuService, который надо отрефакторить «где-то посередине» и нет очевидной готовой зависимости.
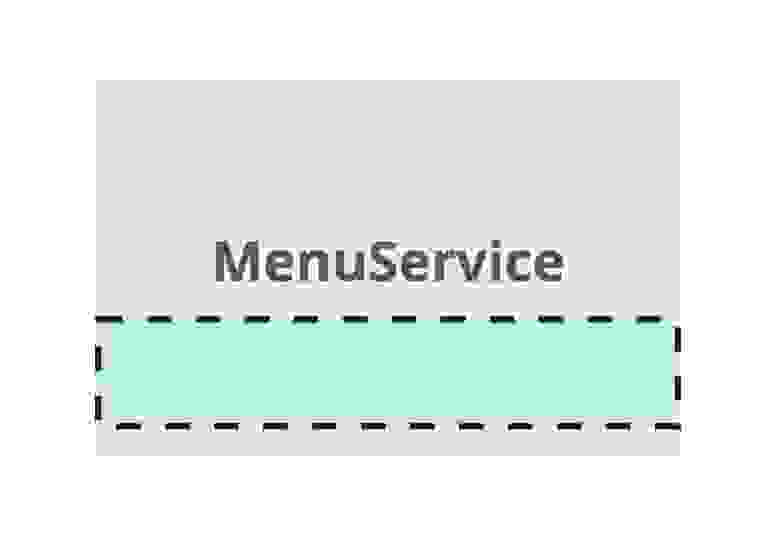
Так как нет готовой зависимости, то вычленяем её из кода и объявляем как абстракцию.
Сразу посмотрим в код. MenuService — это класс, который отвечает за доменную логику с меню. В одном из методов мы получаем объект menuDto, конвертируем его в доменные объекты через расширения toMenuItems и toProducts и сохраняем.
class MenuServiceImpl(
... // dependencies for service
) : MenuService {
fun updateMenu() {
val menuDto = ...
...
onMenuLoaded(menuDto)
...
}
private fun onMenuLoaded(menuDto: MenuDto) {
menuItemRepository.save(menuDto.toMenuItems())
productRepository.save(menuDto.toProducts())
}
...
}
fun MenuDto.toMenuItems(): Collection<MenuItem> = ...
fun MenuDto.toProducts(): Collection<Product> = ...Допустим, что в новой версии меню изменился формат и логика парсинга, toMenuItems и toProducts теперь не подходят.
Ок, начинаем делать Branch By Abstraction, вводим абстракцию. Например, назовём её MenuConverter и тут же перенесём текущую реализацию в класс OldMenuConverter.

Для новой версии конвертера MenuConverterImpl можем пока сделать пустую реализацию.
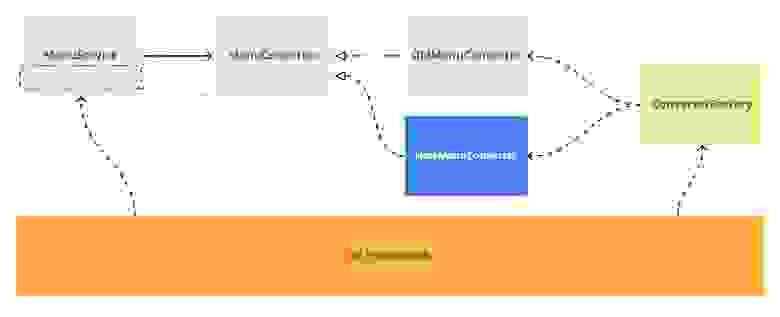
В коде это выглядит так:
interface MenuConverter {
fun convert(menuDto: MenuDto): Menu
}
class MenuConverterImpl : MenuConverter {
override fun convert(menuDto: MenuDto): Menu {
return Menu(
items = listOf(),
products = listOf()
)
}
}
class MenuConverterOldImpl : MenuConverter {
override fun convert(menuDto: MenuDto): Menu {
return Menu(
items = menuDto.toMenuItems(),
products = menuDto.toProducts()
)
}
}И в сервисе заменяем прямое использование toMenuItems и toProducts на menuConverter::convert.
class MenuServiceImpl(
... // dependencies for service
private val menuConverter: MenuConverter
) : MenuService {
...
private fun onMenuLoaded(menuDto: MenuDto) {
val menu = menuDto.let(menuConverter::convert)
menuItemRepository.save(menu.items)
productRepository.save(menu.products)
}
}Включаем в DI и используем:
@Provides
fun provideMenuConverter(featureService: FeatureService): MenuConverter {
return if (featureService.isEnabled(NEW_MENU_PARSING)) {
MenuConverterImpl()
} else {
MenuConverterOldImpl()
}
}Всё, абстрактная ветка создана, теперь можно работать над новым меню.
После всех этапов и удаления старых реализаций может остаться что-то вроде такого:

Более сложный пример
Несмотря на то, что выше были реальные примеры, я понимаю, что они довольно простые. Они могут показаться как из учебника. И не всегда можно использовать Branch by Abstraction, когда хочется.
Давайте разберём пример посложнее.
Введу немного в контекст. Одна из основных функций приложения Додо Пиццы — это заказ на доставку. Значит, нам нужен адрес доставки. Адрес доставки — это сущность, от которой зависит очень много других компонентов приложения: профиль, чекаут, онбординг и другие. В общем, ситуация такая, что адрес используется во многих местах.
Задача состоит в том, чтобы перейти на новую адресную систему во всей нашей системе Dodo IS. Если говорить про мобильное приложение, то доменный объект адреса и логика работы с ним сильно изменились, нельзя было просто расширить старый. В итоге надо было отрефакторить много кода.
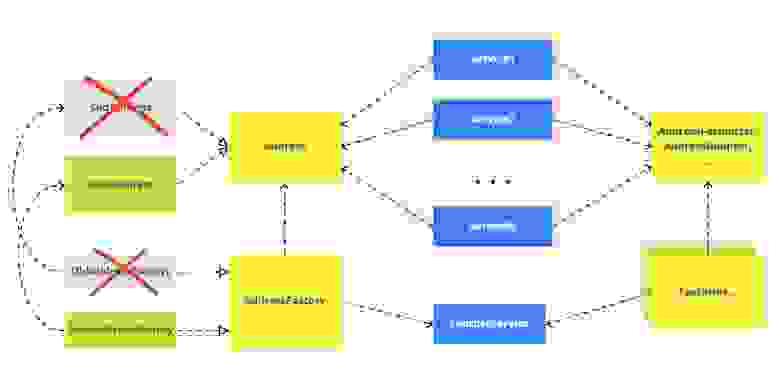
Выглядело примерно всё вот так. Был доменный объект Address, от него зависело много компонентов (я их обозначил как Service1, 2, N). Надо было перейти на NewAddress.

Делаем первый шаг — вводим абстракцию. Здесь это будет посложнее, чем в предыдущих примерах. Мы вводим абстракции:
AddressAddressFactoryи вспомогательные классы для работы с адресами, назовём их
AddressFormatter,AddressAdapterи т.п. и фабрики для них, если нужны.
Переключатель новых и старых реализаций через фича-тогглы будет в фабриках.
На шаге введения абстракций мы должны добиться того, чтобы текущие адреса работали как раньше и ничего не сломалось. После этого можем сливать код в develop, абстрактная ветка создана.
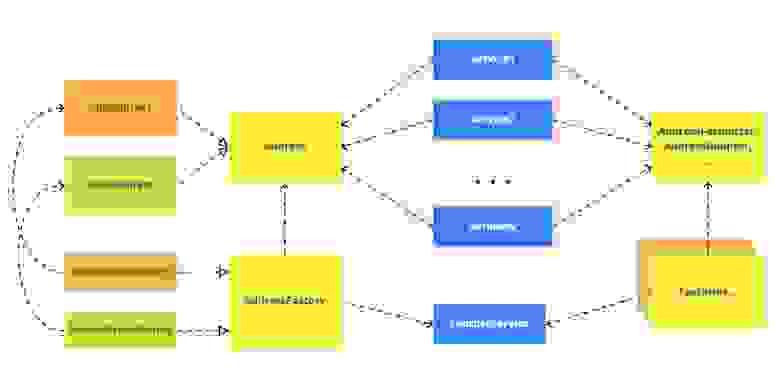
Теперь можно итеративно работать над новой адресной системой.
В идеальном мире мы должны были бы работать только над новыми реализациями (жёлтыми прямоугольниками). В реальности местами код имеет более сильное связывание, поэтому мы работали и над самими сервисами (Service1, 2, N) тоже. Но старались максимально выносить логику в общие вспомогательные классы, которые накрыты абстракцией.
Мы делали этот рефакторинг несколько месяцев, за это время прошло несколько релизов. Но ничего не ломалось, рефакторинг продолжался. Branch by Abstraction отлично сработал!
Последний шаг — удаление старых адресов и всего, что с ними связано. На момент написания статьи их ещё не удалили, потому что переход на новую адресную систему происходит не только в мобильном приложении, а в целом во всей Dodo IS. Мы работаем в 15 странах и раскатываем это решение постепенно. Поэтому ещё какое-то время будет переходный период с двумя адресными системами.
Но когда удалим, всё должно выглядеть вот так.
Дополнительные преимущества
Перед тем как закончить, я хотел бы перечислить дополнительные плюшки, которые мы получаем, используя Branch by Abstraction.
Легко ставить на паузу
Branch by Abstraction чаще всего подходит под большие и долгие задачи, для долгих рефакторингов или переезда с одного фреймворка на другой. Но мы живём в таком быстро меняющемся мире, что завтра придётся срочно начать делать другую задачу.
Например, мы делали рефакторинг оплаты в мобильном приложении, такой, чтобы приложение могло поддерживать сразу несколько эквайеров. Это нужно было для пиццерий во Вьетнаме — планировалось, что там будут использоваться сразу два эквайринга в приложении. Для нас это был немаленький и продолжительный рефакторинг. Его оценили в 2 спринта. Но после первого спринта бизнес-приоритеты изменились и нам надо было переключиться на задачу по новой адресной системе. А по эквайерам во Вьетнаме ситуация изменилась, приоритеты упали. Мы легко поставили задачу на паузу. Для этого не пришлось долго держать отдельную ветку и постоянно её обновлять.
Релизы не останавливаются
Для бизнеса критически важно регулярно и предсказуемо выпускать новые фичи и релизы. Для команд разработки это тоже важно, потому что регулярные и сравнительно небольшие релизы повышают стабильность системы. Мы не копим большие изменения, чтобы выкатить их сразу. Чем меньше частота релизов, тем выше шанс выпустить нестабильный билд и броситься его героически чинить.
Branch by Abstraction позволяет релизам выходить вне зависимости от того, на какой стадии задачи вы находитесь, даже если у вас сейчас абсолютно не работающий код. Главное, чтобы он скомпилировался и был надёжно закрыт тогглом.
Код становится лучше
У многих из нас есть legacy код (или скоро появится). Или просто какой-то код, который написан не идеально или не по архитектурным договорённостям в команде. Часто он ещё и не покрыт тестами. В этом случае введение абстракции приведёт и к улучшению тестируемости кода. Если вы вводите абстракцию, то сможете покрыть новую реализацию тестами. Таким образом часть вашего кода станет лучше. Конечно, здесь не надо доводить до абсурда и вводить абстракцию на каждый чих. Но для legacy-кода и кода с сильной связанностью введение абстракций, которые можно протестировать, скорее всего, будет во благо.
Выводы
Подведём итоги. Можно ли делать большой и продолжительный рефакторинг и не страдать потом от мёрж-конфликтов? Да, можно! Branch by Abstraction как раз подходит для этого.
Эта техника позволяет делать продолжительные задачи, при этом регулярно (хоть каждый день) сливать свой код в основную ветку.
Основная идея сводится к тому, что мы работаем не просто в отдельной ветке репозитория, а в абстрактной ветке. Её мы создаём сами в коде с помощью введения абстракции и механизма тогглов.
Branch by Abstraction состоит из простых шагов:
ввести абстракцию и создать новую реализацию (она может быть пустой);
включить для себя, выключить для всех остальных;
итеративно делать новую реализацию;
выключить и удалить старую реализацию.
Главное, не забывать, что код может в любой момент уйти в прод. Поэтому он должен быть покрыт тестами, не ломать билд и не должно быть возможности его случайно включить в рантайме на проде.
Надеюсь, что эта статья была полезной и вы теперь сможете применять эту технику в своей работе. Если вы уже её используете, буду рад почитать о вашем опыте в комментариях.
")
![[Личный опыт] Как вырасти до Senior в компании уровня FAANG на примере Uber](/upload/resize_cache/iblock/1c0/105_70_0/1c03291fce4410c3f91e5dffc09c43ca.png "[Личный опыт] Как вырасти до Senior в компании уровня FAANG на примере Uber")
