
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Прим. перев.: Представляем вашему вниманию технические подробности о причинах недавнего простоя в работе облачного сервиса, обслуживаемого создателями Grafana. Это классический пример того, как новая и, казалось бы, исключительно полезная возможность, призванная улучшить качество инфраструктуры… может навредить, если не предусмотреть многочисленные нюансы её применения в реалиях production. Замечательно, когда появляются такие материалы, позволяющие учиться не только на своих ошибках. Подробности — в переводе этого текста от вице-президента по продукту из Grafana Labs.

В пятницу, 19 июля, сервис Hosted Prometheus в Grafana Cloud перестал функционировать примерно на 30 минут. Приношу извинения всем клиентам, пострадавшим от сбоя. Наша задача — предоставлять нужные инструменты для мониторинга, и мы понимаем, что их недоступность усложняет вашу жизнь. Мы крайне серьезно относимся к этому инциденту. В этой заметке объясняется, что произошло, как мы на это отреагировали и что делаем для того, чтобы подобное больше не повторялось.
Сервис Grafana Cloud Hosted Prometheus основан на Cortex — проекте CNCF по созданию горизонтально масштабируемого, высокодоступного, мультитенантного (multi-tenant) сервиса Prometheus. Архитектура Cortex состоит из набора отдельных микросервисов, каждый из которых выполняет свою функцию: репликацию, хранение, запросы и т.д. Cortex активно разрабатывается, у него постоянно появляются новые возможности и повышается производительность. Мы регулярно деплоим новые релизы Cortex в кластеры, чтобы клиенты могли воспользоваться этими возможностями — благо, Cortex умеет обновляться без простоев.
Для беспростойных обновлений сервис Ingester Cortex'а требует дополнительную реплику Ingester'а во время процесса обновления. (Прим. перев.: Ingester — базовый компонент Cortex'а. Его задача — собирать постоянный поток sample'ов, группировать их в chunk'и Prometheus и сохранять в базе данных вроде DynamoDB, BigTable или Cassandra.) Это позволяет старым Ingester'ам пересылать текущие данные новым Ingester'ам. Стоит отметить, что Ingester'ы требовательны к ресурсам. Для их работы необходимо иметь по 4 ядра и 15 Гб памяти на pod, т.е. 25 % процессорной мощности и памяти базовой машины в случае наших кластерах Kubernetes. В целом у нас обычно гораздо больше неиспользованных ресурсов в кластере, нежели 4 ядра и 15 Гб памяти, поэтому мы можем легко запускать эти дополнительные Ingester'ы во время обновлений.
Однако часто бывает так, что во время нормальной работы ни на одной из машин нет этих 25% невостребованных ресурсов. Да мы и не стремимся: CPU и память всегда пригодятся для других процессов. Для решения этой проблемы мы решили воспользоваться Kubernetes Pod Priorities. Идея в том, чтобы присваивать Ingester'ам более высокий приоритет, чем другим (stateless) микросервисам. Когда нам нужно запустить дополнительный (N+1) Ingester, мы временно вытесняем другие, меньшие pod'ы. Эти pod'ы переносятся в свободные ресурсы на других машинах, оставляя достаточно большую «дыру» для запуска дополнительного Ingester'а.
В четверг, 18 июля, мы развернули четыре новых уровня приоритетов в своих кластерах: критический, высокий, средний и низкий. Они тестировались на внутреннем кластере без клиентского трафика примерно одну неделю. По умолчанию pod'ы без заданного приоритета получали средний приоритет, для Ingester'ов был установлен класс с высоким приоритетом. Критический был зарезервирован для мониторинга (Prometheus, Alertmanager, node-exporter, kube-state-metrics и т.д.). Наш конфиг — открытый, и посмотреть PR можно здесь.
В пятницу, 19 июля, один из инженеров запустил новый выделенный кластер Cortex для крупного клиента. Конфиг для этого кластера не включал новые приоритеты pod'ов, поэтому всем новым pod'ам присваивался приоритет по умолчанию — средний.
В кластере Kubernetes не хватило ресурсов для нового кластера Cortex, а существующий production-кластер Cortex не был обновлен (Ingester'ы остались без высокого приоритета). Поскольку Ingester'ы нового кластера по умолчанию имели средний приоритет, а существующие в production pod'ы работали вообще без приоритета, Ingester'ы нового кластера вытеснили Ingester из существующего production-кластера Cortex.
ReplicaSet для вытесненного Ingester'а в production-кластере обнаружил вытесненный pod и создал новый для поддержания заданного количества копий. Новому pod'у по умолчанию был присвоен средний приоритет, и очередной «старый» Ingester в production лишился ресурсов. Результатом стал лавинообразный процесс, который привел к вытеснению всех pod'ов с Ingester для production-кластеров Cortex'а.
Ingester'ы сохраняют состояние (stateful) и хранят данные за предыдущие 12 часов. Это позволяет нам более эффективно сжимать их перед записью в долгосрочное хранилище. Для этого Cortex проводит шардинг данных по сериям, используя распределенную хэш-таблицу (Distributed Hash Table, DHT), и реплицирует каждую серию на три Ingester'а с помощью кворумной согласованности в стиле Dynamo. Cortex не пишет данные в Ingester'ы, которые отключаются. Таким образом, когда большое число Ingester'ов покидают DHT, Cortex не может обеспечить достаточную репликацию записей, и они «падают».
Новые уведомления Prometheus на основе «бюджетных ошибок» (error-budget-based — подробности появятся в будущей статье) стали бить тревогу через 4 минуты с момента начала отключения. В течение следующих примерно пяти минут мы провели диагностику и нарастили нижележащий кластер Kubernetes для размещения как нового, так и существующих production-кластеров.
Еще через пять минут старые Ingester'ы успешно записали свои данные, а новые — запустились, и кластеры Cortex снова стали доступны.
Еще 10 минут ушло на диагностику и исправление out-of-memory (OOM) ошибок от обратных прокси-серверов аутентификации, расположенных перед Cortex. ООМ-ошибки были вызваны десятикратным ростом QPS (как мы полагаем, из-за чрезмерно агрессивных запросов с серверов Prometheus клиента).
Общая продолжительность простоя составила 26 минут. Данные не были потеряны. Ingester'ы успешно загрузили все in-memory-данные в долговременное хранилище. Во время отключения Prometheus-серверы клиентов сохраняли в буфер удаленные (remote) записи с помощью нового API remote_write на основе WAL (за авторством Callum Styan из Grafana Labs) и повторили неудачные записи после сбоя.
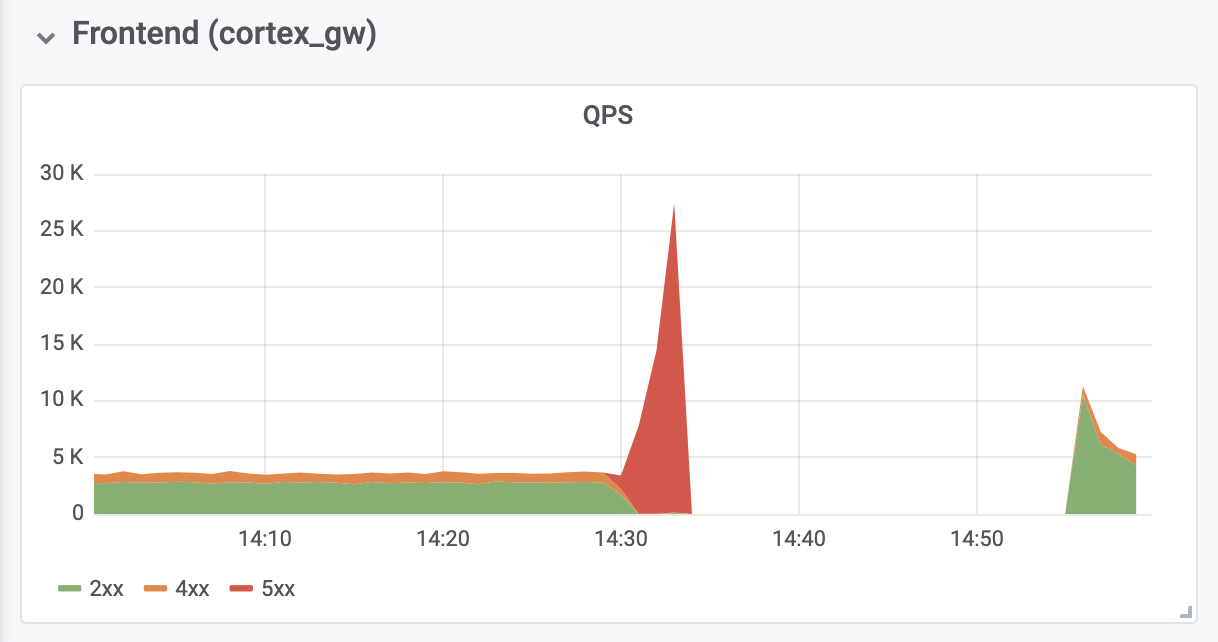
Операции записи production-кластера
Важно извлечь уроки из этого инцидента и предпринять необходимые меры, чтобы избежать его повторения.
Оглядываясь назад, следует признать, что нам не следовало задавать по умолчанию средний приоритет, пока все Ingester'ы в production не получили высокий приоритет. Кроме того, следовало заранее позаботиться об их высоком приоритете. Теперь все исправлено. Надеемся, что наш опыт поможет другим организациям, рассматривающим возможность использования приоритетов pod’ов в Kubernetes.
Мы добавим дополнительный уровень контроля за развертыванием любых дополнительных объектов, конфигурации которых глобальны для кластера. Впредь подобные изменения будут оцениваться большим количеством людей. Кроме того, модификация, которая привела к сбою, считалась слишком незначительной для отдельного проектного документа — она обсуждалась только в GitHub issue. С этого момента все подобные изменения конфигов будут сопровождаться соответствующей проектной документацией.
Наконец, мы автоматизируем изменение размера у обратного прокси-сервера аутентификации для предотвращения ООМ при перегрузке, свидетелями чего мы стали, и проанализируем параметры Prometheus по умолчанию, связанные с откатом и масштабированием, для предупреждения в будущем подобных проблем.
Пережитый сбой имел и некоторые позитивные последствия: получив в распоряжение необходимые ресурсы, Cortex автоматически восстановился без дополнительного вмешательства. Мы также получили ценный опыт работы с Grafana Loki — нашей новой системой агрегации логов, — которая помогла убедиться, что все Ingester'ы должным образом повели себя во время и после сбоя.
Читайте также в нашем блоге:
В пятницу, 19 июля, сервис Hosted Prometheus в Grafana Cloud перестал функционировать примерно на 30 минут. Приношу извинения всем клиентам, пострадавшим от сбоя. Наша задача — предоставлять нужные инструменты для мониторинга, и мы понимаем, что их недоступность усложняет вашу жизнь. Мы крайне серьезно относимся к этому инциденту. В этой заметке объясняется, что произошло, как мы на это отреагировали и что делаем для того, чтобы подобное больше не повторялось.
Предыстория
Сервис Grafana Cloud Hosted Prometheus основан на Cortex — проекте CNCF по созданию горизонтально масштабируемого, высокодоступного, мультитенантного (multi-tenant) сервиса Prometheus. Архитектура Cortex состоит из набора отдельных микросервисов, каждый из которых выполняет свою функцию: репликацию, хранение, запросы и т.д. Cortex активно разрабатывается, у него постоянно появляются новые возможности и повышается производительность. Мы регулярно деплоим новые релизы Cortex в кластеры, чтобы клиенты могли воспользоваться этими возможностями — благо, Cortex умеет обновляться без простоев.
Для беспростойных обновлений сервис Ingester Cortex'а требует дополнительную реплику Ingester'а во время процесса обновления. (Прим. перев.: Ingester — базовый компонент Cortex'а. Его задача — собирать постоянный поток sample'ов, группировать их в chunk'и Prometheus и сохранять в базе данных вроде DynamoDB, BigTable или Cassandra.) Это позволяет старым Ingester'ам пересылать текущие данные новым Ingester'ам. Стоит отметить, что Ingester'ы требовательны к ресурсам. Для их работы необходимо иметь по 4 ядра и 15 Гб памяти на pod, т.е. 25 % процессорной мощности и памяти базовой машины в случае наших кластерах Kubernetes. В целом у нас обычно гораздо больше неиспользованных ресурсов в кластере, нежели 4 ядра и 15 Гб памяти, поэтому мы можем легко запускать эти дополнительные Ingester'ы во время обновлений.
Однако часто бывает так, что во время нормальной работы ни на одной из машин нет этих 25% невостребованных ресурсов. Да мы и не стремимся: CPU и память всегда пригодятся для других процессов. Для решения этой проблемы мы решили воспользоваться Kubernetes Pod Priorities. Идея в том, чтобы присваивать Ingester'ам более высокий приоритет, чем другим (stateless) микросервисам. Когда нам нужно запустить дополнительный (N+1) Ingester, мы временно вытесняем другие, меньшие pod'ы. Эти pod'ы переносятся в свободные ресурсы на других машинах, оставляя достаточно большую «дыру» для запуска дополнительного Ingester'а.
В четверг, 18 июля, мы развернули четыре новых уровня приоритетов в своих кластерах: критический, высокий, средний и низкий. Они тестировались на внутреннем кластере без клиентского трафика примерно одну неделю. По умолчанию pod'ы без заданного приоритета получали средний приоритет, для Ingester'ов был установлен класс с высоким приоритетом. Критический был зарезервирован для мониторинга (Prometheus, Alertmanager, node-exporter, kube-state-metrics и т.д.). Наш конфиг — открытый, и посмотреть PR можно здесь.
Авария
В пятницу, 19 июля, один из инженеров запустил новый выделенный кластер Cortex для крупного клиента. Конфиг для этого кластера не включал новые приоритеты pod'ов, поэтому всем новым pod'ам присваивался приоритет по умолчанию — средний.
В кластере Kubernetes не хватило ресурсов для нового кластера Cortex, а существующий production-кластер Cortex не был обновлен (Ingester'ы остались без высокого приоритета). Поскольку Ingester'ы нового кластера по умолчанию имели средний приоритет, а существующие в production pod'ы работали вообще без приоритета, Ingester'ы нового кластера вытеснили Ingester из существующего production-кластера Cortex.
ReplicaSet для вытесненного Ingester'а в production-кластере обнаружил вытесненный pod и создал новый для поддержания заданного количества копий. Новому pod'у по умолчанию был присвоен средний приоритет, и очередной «старый» Ingester в production лишился ресурсов. Результатом стал лавинообразный процесс, который привел к вытеснению всех pod'ов с Ingester для production-кластеров Cortex'а.
Ingester'ы сохраняют состояние (stateful) и хранят данные за предыдущие 12 часов. Это позволяет нам более эффективно сжимать их перед записью в долгосрочное хранилище. Для этого Cortex проводит шардинг данных по сериям, используя распределенную хэш-таблицу (Distributed Hash Table, DHT), и реплицирует каждую серию на три Ingester'а с помощью кворумной согласованности в стиле Dynamo. Cortex не пишет данные в Ingester'ы, которые отключаются. Таким образом, когда большое число Ingester'ов покидают DHT, Cortex не может обеспечить достаточную репликацию записей, и они «падают».
Обнаружение и устранение
Новые уведомления Prometheus на основе «бюджетных ошибок» (error-budget-based — подробности появятся в будущей статье) стали бить тревогу через 4 минуты с момента начала отключения. В течение следующих примерно пяти минут мы провели диагностику и нарастили нижележащий кластер Kubernetes для размещения как нового, так и существующих production-кластеров.
Еще через пять минут старые Ingester'ы успешно записали свои данные, а новые — запустились, и кластеры Cortex снова стали доступны.
Еще 10 минут ушло на диагностику и исправление out-of-memory (OOM) ошибок от обратных прокси-серверов аутентификации, расположенных перед Cortex. ООМ-ошибки были вызваны десятикратным ростом QPS (как мы полагаем, из-за чрезмерно агрессивных запросов с серверов Prometheus клиента).
Последствия
Общая продолжительность простоя составила 26 минут. Данные не были потеряны. Ingester'ы успешно загрузили все in-memory-данные в долговременное хранилище. Во время отключения Prometheus-серверы клиентов сохраняли в буфер удаленные (remote) записи с помощью нового API remote_write на основе WAL (за авторством Callum Styan из Grafana Labs) и повторили неудачные записи после сбоя.
Операции записи production-кластера
Выводы
Важно извлечь уроки из этого инцидента и предпринять необходимые меры, чтобы избежать его повторения.
Оглядываясь назад, следует признать, что нам не следовало задавать по умолчанию средний приоритет, пока все Ingester'ы в production не получили высокий приоритет. Кроме того, следовало заранее позаботиться об их высоком приоритете. Теперь все исправлено. Надеемся, что наш опыт поможет другим организациям, рассматривающим возможность использования приоритетов pod’ов в Kubernetes.
Мы добавим дополнительный уровень контроля за развертыванием любых дополнительных объектов, конфигурации которых глобальны для кластера. Впредь подобные изменения будут оцениваться большим количеством людей. Кроме того, модификация, которая привела к сбою, считалась слишком незначительной для отдельного проектного документа — она обсуждалась только в GitHub issue. С этого момента все подобные изменения конфигов будут сопровождаться соответствующей проектной документацией.
Наконец, мы автоматизируем изменение размера у обратного прокси-сервера аутентификации для предотвращения ООМ при перегрузке, свидетелями чего мы стали, и проанализируем параметры Prometheus по умолчанию, связанные с откатом и масштабированием, для предупреждения в будущем подобных проблем.
Пережитый сбой имел и некоторые позитивные последствия: получив в распоряжение необходимые ресурсы, Cortex автоматически восстановился без дополнительного вмешательства. Мы также получили ценный опыт работы с Grafana Loki — нашей новой системой агрегации логов, — которая помогла убедиться, что все Ingester'ы должным образом повели себя во время и после сбоя.
P.S. от переводчика
Читайте также в нашем блоге:
- «Автомасштабирование и управление ресурсами в Kubernetes (обзор и видео доклада)»;
- «Kubernetes-приключение Dailymotion: создание инфраструктуры в облаках + on-premises»;
- «Переход Tinder на Kubernetes»;
- «Истории успеха Kubernetes в production. Часть 10: Reddit».
")

