
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Наличие технических ошибок на сайте может негативно сказаться на его ранжировании, что в свою очередь приведет к снижению поискового трафика и позиций в поисковых системах. Чтобы выявить технические ошибки, необходимо провести комплексный технический SEO-аудит сайта. Одним из основных помощников в этой сложной и трудозатратной задаче для нас выступает десктопная программа Screaming Frog.
О Screaming Frog
Screaming Frog – это софт для сканирования сайта, ключевыми функциями которого являются:
поиск битых ссылок;
поиск ссылок с редиректом;
поиск дублей страниц;
анализ изображений;
поиск страниц, где отсутствуют мета-теги или основной заголовок h1;
извлечение элементов со страниц сайта;
поиск пустых страниц или неинформативных страниц, где крайне мало контента.
С помощью данной программы можно проанализировать страницы, которые закрыты в файле robots.txt, проверить наличие и корректность заполнения тегов alt у изображений, а также наличие атрибута Canonical и многое другое.
Screaming Frog может просканировать весь сайт полностью, либо же определенный каталог, либо заданный вручную список страниц. Чтобы не создавать сильную нагрузку на сервер, можно в любой момент остановить сканирование.
Важным плюсом является то, что результат сканирования можно выгрузить в формате csv или xlsx. Но есть и некоторые минусы:
сложный и интуитивно непонятный интерфейс для новых пользователей;
данные хранятся в оперативной памяти вашего ПК, в связи чем довольно проблематично полностью сканировать объемный сайт. А также при работе с софтом работа ПК может замедлиться;
программа платная (но есть бесплатная версия с ограничениями).
А теперь подробнее.
Поиск битых ссылок
Мы намеренно перескочили через тему «Настройка Screaming Frog», так как в сети присутствует большое количество мануалов по настройке программы, описаний интерфейса и вводной информации о том, как работать с программой и сканировать сайт. Переходим сразу к техническому анализу сайта.
Итак, мы просканировали сайт. Для поиска битых ссылок необходимо справа найти вкладку «Response Code» — «Client Error (4xx)». Теперь мы видим список битых ссылок при их наличии на сайте.
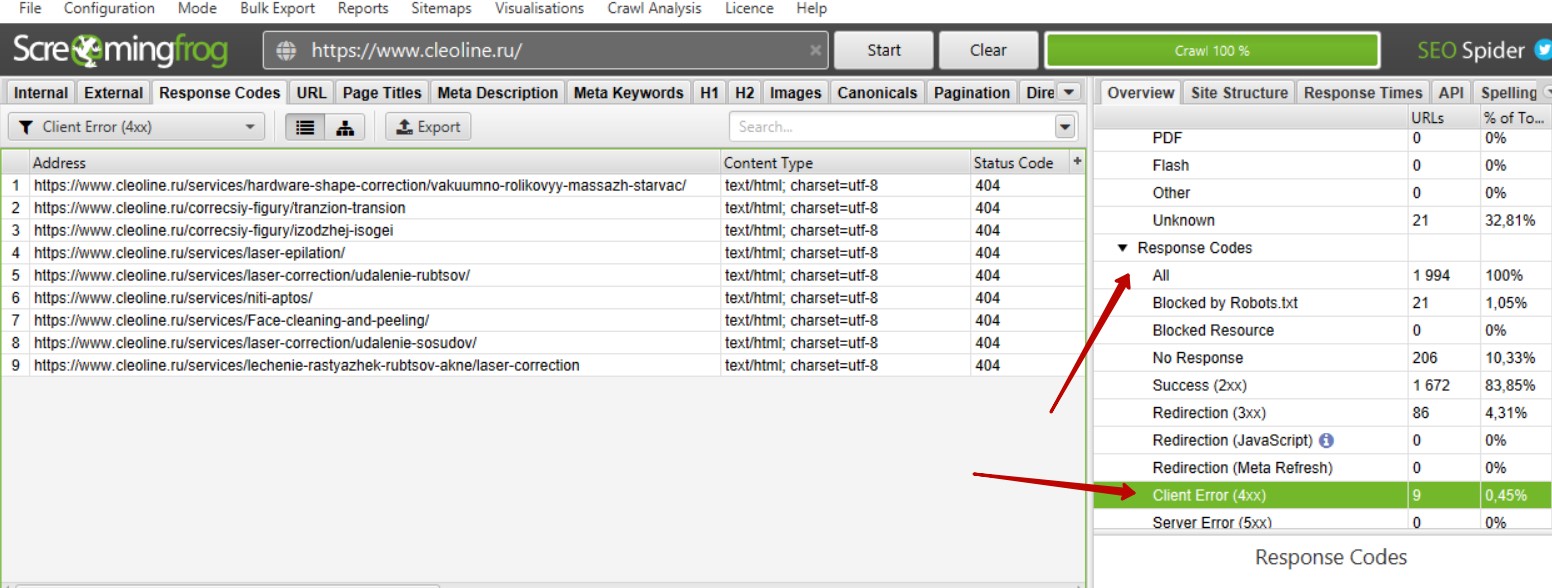
Как определить на каких страницах находятся битые ссылки?
Необходимо выбрать ссылку или выделить несколько ссылок и внизу слева выбрать вкладку «Inlinks». В нижней части появится список страниц, где размещена выбранная ссылка или список ссылок.
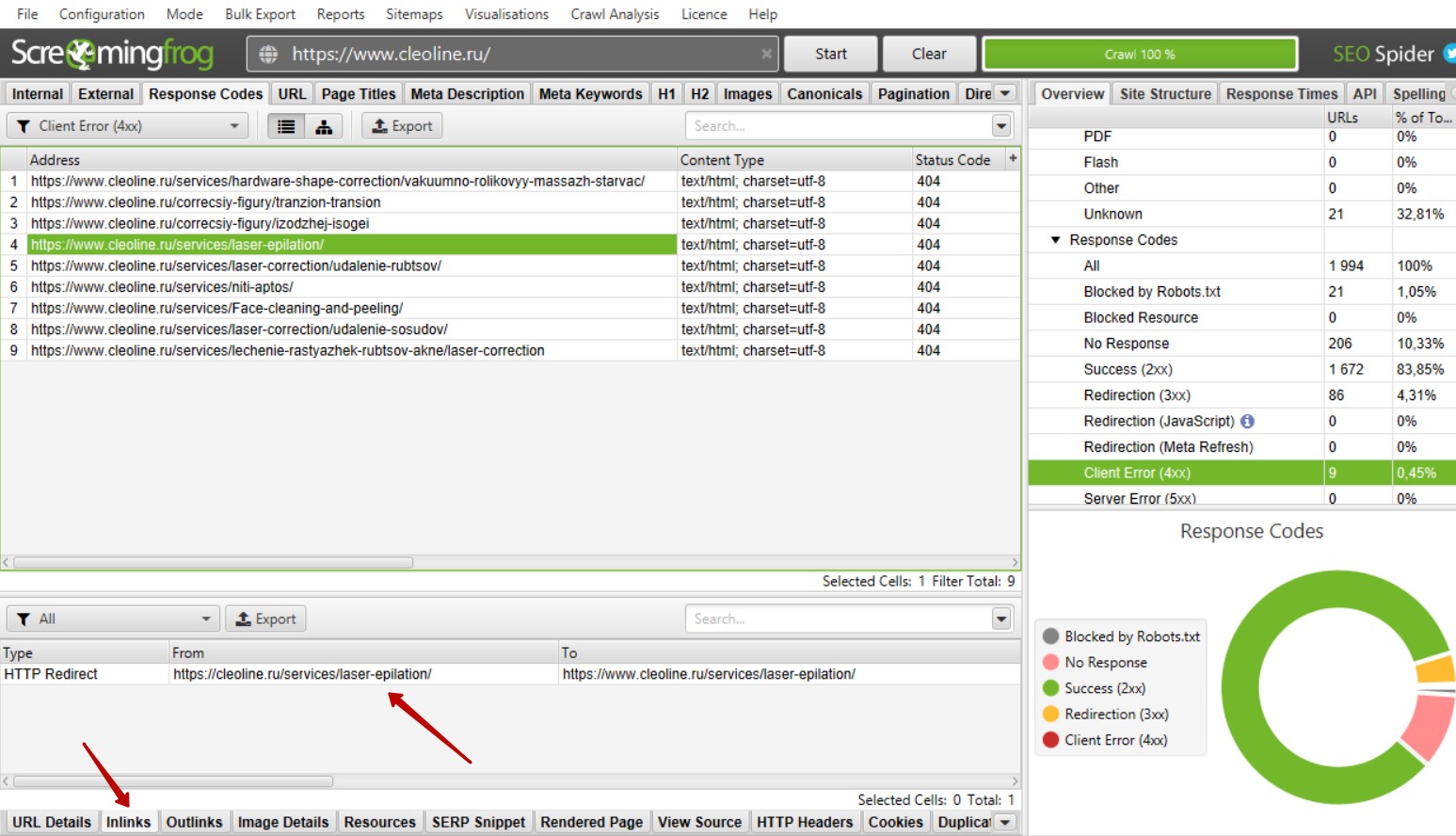
Такие ссылки рекомендуется убирать, так как большое количество битых ссылок может негативно сказаться на ранжировании сайта.
Как найти битые ссылки на странице сайта?
Если при осмотре страницы битая ссылка не бросается в глаза, необходимо открыть код сайта «ctrl + shift + i», далее открыть форму поиска в коде «ctrl + а» и вбить адрес битой ссылки.

Битые ссылки могут быть размещены в текстах страниц. В таком случае необходимо убирать ссылки вручную. В некоторых случаях ссылка может быть размещена сразу на нескольких страницах. Это говорит о том, что ссылка размещена в меню, в футере или в каком-либо другом сквозном блоке. В таком случае не нужно заходить на каждую страницу отдельно, а можно просто удалить или заменить ссылку.
Почему битые ссылки – это плохо?
Битые ссылки не оказывают прямого влияния на ранжирование сайта, и каких-либо санкций за битые ссылки со стороны поисковых систем нет. Однако они могут потратить часть краулингового бюджета поисковых роботов, понизить показатель качества сайта, увеличить количество отказов. Кроме того, битые ссылки не передают вес другим страницам, а если на неё стоят ссылки с внешних ресурсов, вес такой ссылки не учитывается. Поэтому битые ссылки необходимо удалять с сайта либо заменять их на действующие.
Поиск ссылок с 301 редиректом
301 редирект – перенаправление со старого адреса на новый, если изменился адрес страницы, а контент не менялся. Это делается как раз для того, чтобы не появлялись битые ссылки. Но лучше сразу ставить ссылку с 200 кодом ответа на существующую страницу. Если нет возможности менять ссылки, тогда настраивают 301 редирект. Обычно мы от таких ссылок избавляемся.
Поиск ссылок с 301 редиректом производится аналогичным поиску битых ссылок образом. Необходимо справа найти вкладку «Response Code» — «Redirection (3xx)». Теперь мы видим список ссылок с 301 редиректом и другими редиректами с 3xx кодом при их наличии на сайте.

Как определить на каких страницах находятся ссылки с 301 редиректом?
Поиск таких ссылок осуществляется так же, как и поиск битых ссылок. Необходимо выбрать ссылку или выделить несколько ссылок и внизу слева выбрать вкладку «Inlinks». В нижней части появится список страниц, где размещена выбранная ссылки или список ссылок, как и в случае с битыми ссылками.
Рядом присутствует вкладка Outlinks, где указаны страницы, куда приходит редирект.

Почему желательно избавляться от таких ссылок?
Небольшое количество таких ссылок никак не отразится на ранжировании сайта. Однако, если ссылок с редиректами много или такие ссылки размещены на всех страницах в меню, футере или других сквозных блоках, рекомендуется заменить данные ссылки на существующие страницы, на которые настроен редирект. Такие ссылки не несут в себе информацию о том, почему происходит перенаправление на другой адрес, что усложняет поисковым системам обработку данного редиректа.
Поиск дублей страниц
Наличие дублей страниц негативно сказывается на ранжировании сайта, так как из двух страниц поисковые системы вероятнее всего будут индексировать только одну наиболее релевантную, на их взгляд, страницу. Дублями страниц могут восприниматься страницы с разным контентом, но одинаковыми тегами title. Бывает, что у страниц услуг и статей идентичные теги title, и такие страницы признаются дублями. При этом интент запросов совсем разный: у первой – информационный, у второй – коммерческий. Для избежания возникновения дублей следует в первую очередь проверять сайт на наличие дубликатов title и при наличии дублей корректировать мета-теги.
Как искать дубликаты title?
Выбираем справа вкладку «Page Titles» — «Duplicate» и получаем список страниц на которых дублируются мета-теги.

В случае, когда на страницах разный контент и одинаковые теги title, необходимо скорректировать мета-теги.
Если страницы идентичны и по тегами, и по контенту, следует удалить одну страницу и настроить 301 редирект с адреса удаленной страницы на существующую страницу. Это поможет, если ссылки на удаленные страницы размещены на других сайтах или находится в индексе. 301 редирект здесь нужен, чтобы пользователи попадали не на удаленную, а на нужную страницу.
Но на самом сайте такие ссылки нужно удалить. Поэтому рекомендуем сразу проверить, есть ли на сайте ссылки на удаленную страницу (см. инструкции выше) и заменить их на существующую страницу.
Анализ заголовков h1
На каждой странице должен присутствовать основной заголовок в тегах <h1>, который максимально подробно и при этом кратко отражает содержание страницы. Это позволяет поисковым система более точно определить, что за информация размещена на странице. При проведении SEO-аудита необходимо проверить наличие основного заголовка на всех страницах сайта. Кроме того, тегами <h1> должен быть размечен только один основной заголовок.
Как найти страницы, где отсутствует основной заголовок h1?
Необходимо справа выбрать вкладку «H1» — «Missing>. Вы увидите список страниц, где отсутствует заголовок h1. Следует добавить данный заголовок на все страницы сайта.
В том же блоке справа во вкладке «Multiple» будут страницы, где присутствует несколько заголовков h1. В таком случае необходимо удалить второй заголовок, если он дублирует первый либо в нём нет необходимости, или разметить заголовок тегами <h2> — <h6> в соответствии с его иерархией.
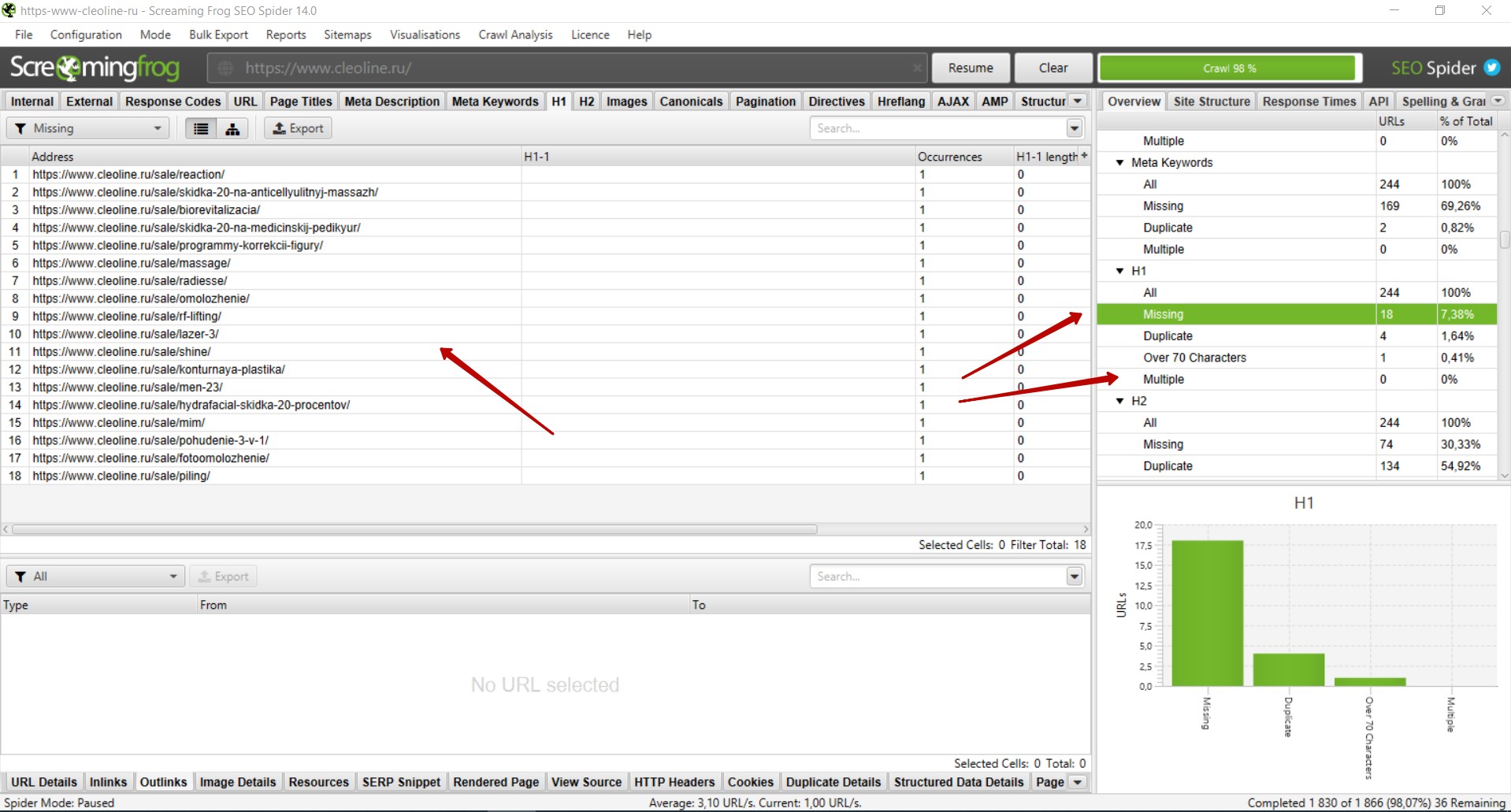
Рекомендуем также проверить вкладку «Duplicate» на наличие дублей заголовков h1. В целом, дубли h1 не являются проблемой. Однако при наличии большого количества дублей рекомендуем корректировать заголовки, в особенности на страницах товаров / услуг / статей и в случаях, когда на сайте настроена автоматическая генерация мета-тегов.
Проверка наличия и корректности Canonical
Для избежания возникновения дублей страниц рекомендуется на всех страницах размещать атрибут Canonical с указанием канонической (основной) страницы. Атрибут rel=canonical тега <link> указывает поисковым системам, что некоторые страницы могут быть одинаковыми, несмотря на разные URL-адреса (например, страницы пагинации).
Наличие данного атрибута не является фактором ранжирования, но в некоторых случаях может положительно сказаться на индексации сайта и избежать возникновения дублей страниц, например когда в URL добавляются GET-параметры (рекламные метки, сортировка и т.п.).
Для того, чтобы проверить на каких страницах размещен данный атрибут и корректно ли указаны ссылки, необходимо справа выбрать вкладку «Canonicals» — «All». Во вкладке «Missing» можно посмотреть список страниц, где данный атрибут отсутствует.

Поиск пустых или малоинформативных страниц
Наличие пустых или малоинформативных страниц может негативно сказаться на ранжировании сайта. Чаще всего такие страницы исключаются из индекса поисковых систем. Такие страницы рекомендуется удалять или дорабатывать таким образом, чтобы страница полностью отвечала на вопросы пользователя.
Для поиска пустых или малоинформативных страниц необходимо справа выбрать вкладку «Crawl Dara» — «Internal» — «All».

Через форму поиска следует отфильтровать страницы с контентом.
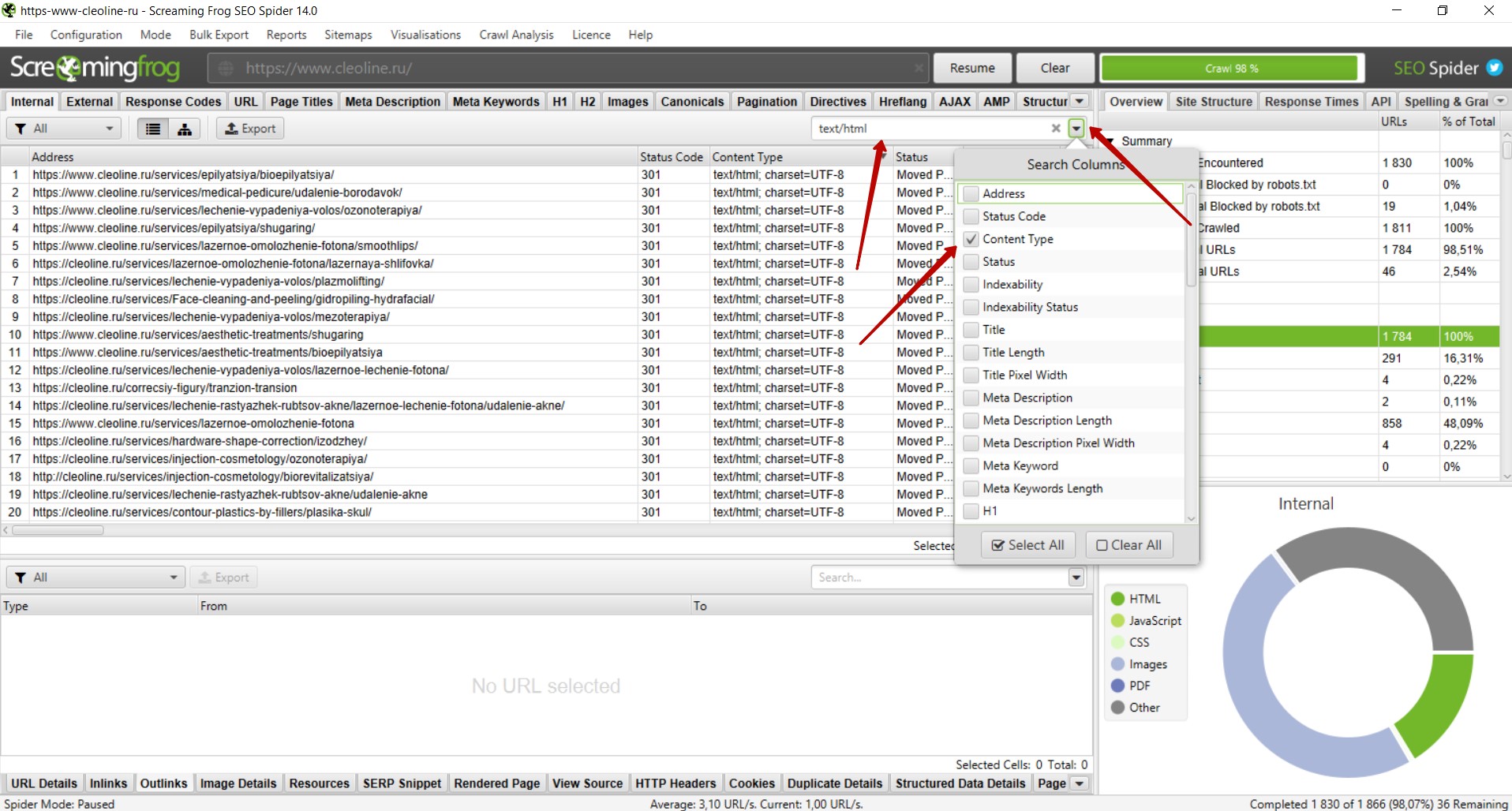
Далее необходимо в поле со списком страниц найти столбец «Word Count», отсортировать список страниц по убыванию количества слов и уже вручную проверить страницы с низким количеством слов в тексте страниц.

Спамный тег Keywords
Тег Keywords давно не учитывается поисковыми системами как фактор ранжирования и не оказывает положительного влияния. Однако при наличии на сайте спамных текстов и мета-тегов данный тег может стать одним из сигналов, что страница продвигается неестественными способами.
Для избежания таких ситуаций, мы рекомендуем удалять теги Keywords со всех страниц сайта.
Чтобы найти страницы, где размещен данный тег, необходимо справа выбрать вкладку «Meta Keywords» — «Missing», и вы увидите список страниц, где присутствует данный тег.
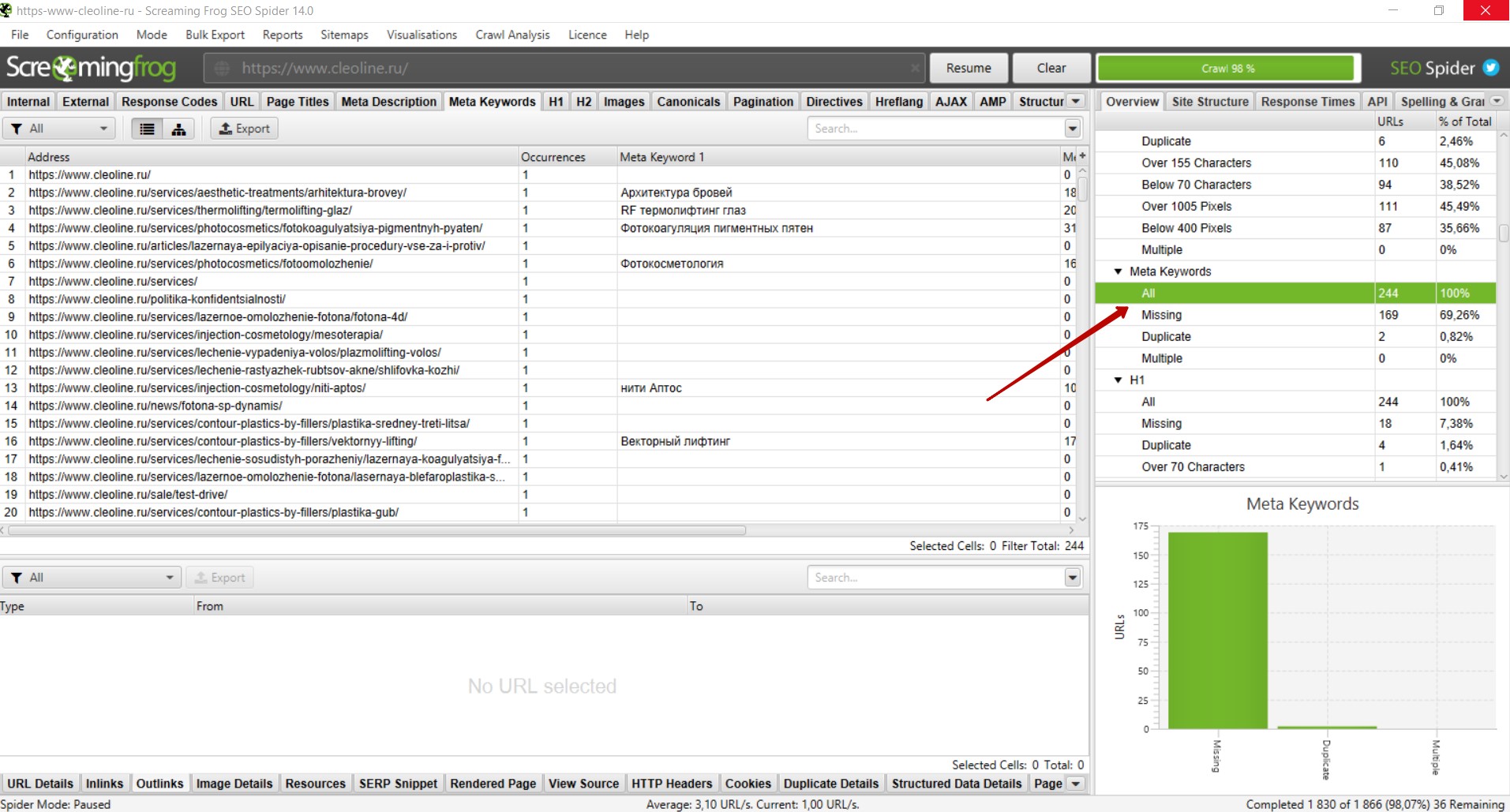
Анализ изображений
Изображения на сайте очень важны для продвижения и правильная оптимизация изображений может положительно сказаться на ранжировании сайтов и принести дополнительный трафик, например с поиска по картинкам.
Чтобы приступить к анализу изображений, следует перейти справа во вкладку «Crawl Data» — «Internal» — «Images». Вы увидите список ссылок на изображения. Необходимо проверить код ответа сервера в столбце «Status Code» — все ссылки должны отдавать 200 код ответа. Битые изображения следует удалить либо заменить на существующие. Если закрыты служебные папки, изображения рекомендуем открывать в файле robots.txt , чтобы они индексировались поисковыми системами.

Следует также проверить вес изображений в столбце «Size». Изображения с весом более 3 мб рекомендуем сжимать, чтобы они не замедляли скорость загрузки страниц.
Анализ тегов Noindex и Nofollow
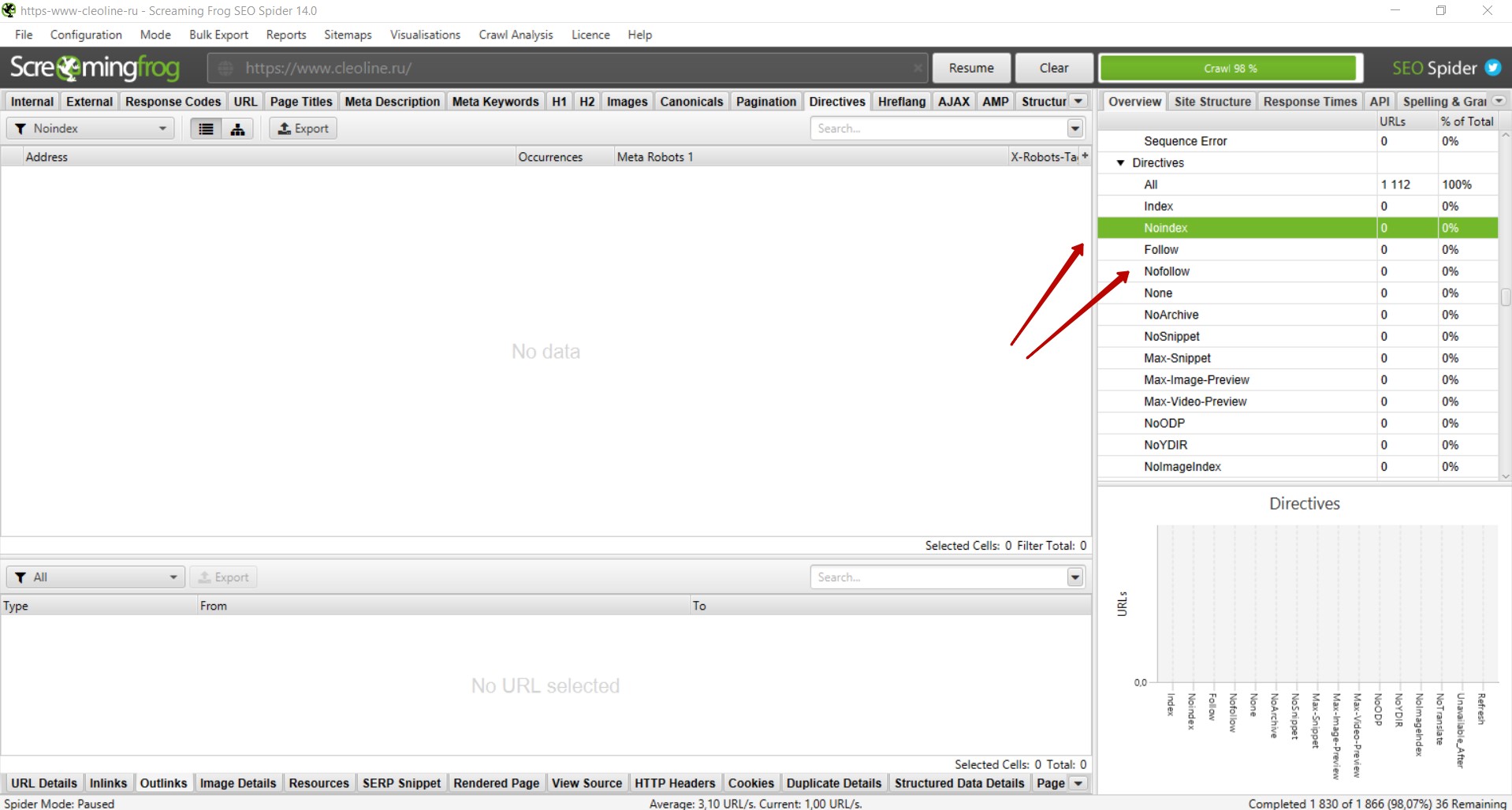
На некоторых страницах могут быть размещены теги «noindex», «nofollow». Чаще всего с помощью таких тегов намеренно закрывают страницы, которые не должны индексироваться. Однако некоторые теги могут быть размещены на страницах сайта ошибочно, в результате чего нужные страницы не попадут в индекс и не будут приносить трафик.
Поэтому рекомендуем проверять наличие данных тегов на страницах сайта. Для этого необходимо справа выбрать вкладку «Directives» — «noindex» и «nofollow» и проверить, не размещены ли данные теги на нужных для продвижения страницах. При наличии таких тегов на важных страницах рекомендуем убрать их из кода, чтобы страницы индексировались поисковыми системами.
Извлечение элементов со страниц сайта
Иногда возникает потребность извлечь какой либо элемент со страниц сайта. Например, подзаголовки, цены, названия каких-то определенных блоков и т.д.
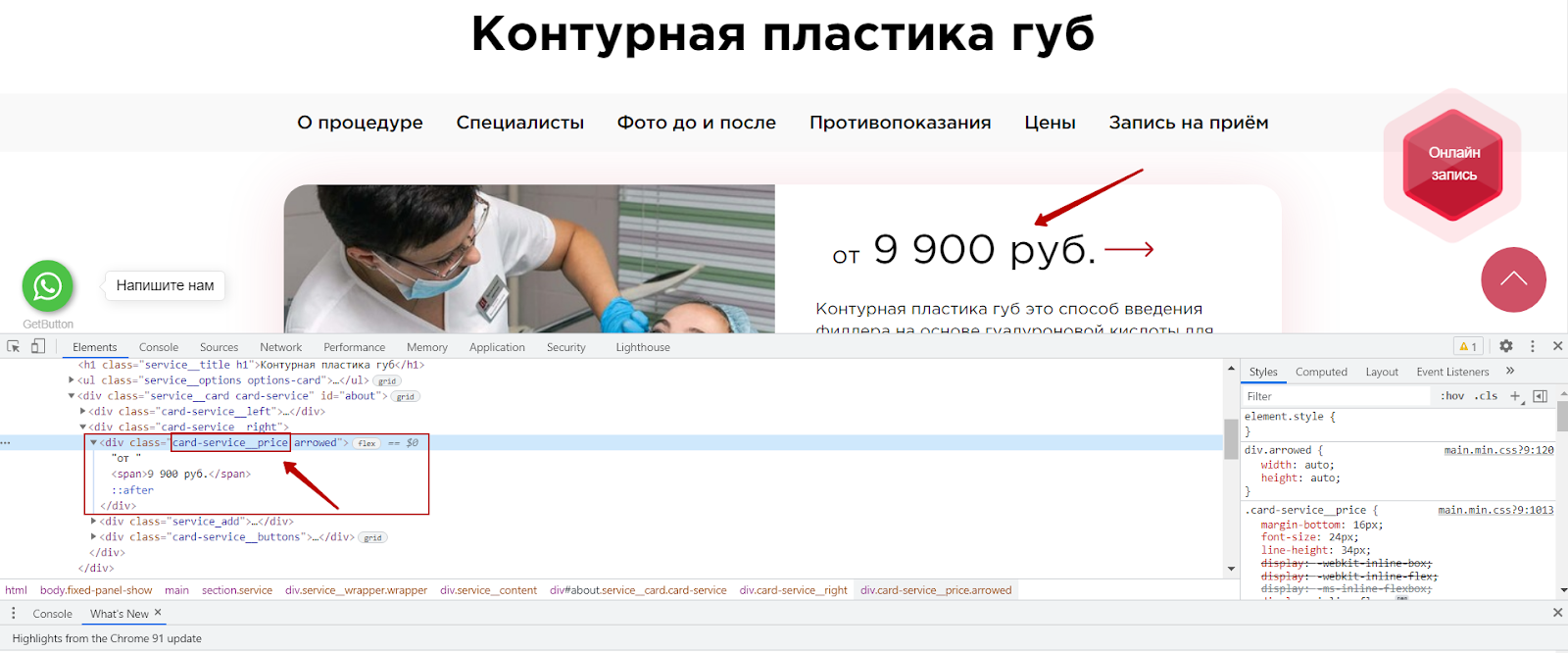
В случае с нашим клиентом мы обнаружили, что на некоторых страницах отсутствуют цены. Наличие цены на коммерческих страницах является одним из факторов ранжирования, в связи с чем мы подготовили рекомендацию о необходимости разместить цену на всех страницах сайта. Чтобы подготовить список страниц, где отсутствует цена, мы воспользовались функцией Custom Extraction.
Как это сделать?
Для начала необходимо определить, где находится нужный элемент на странице сайта, и скопировать стиль данного элемента.
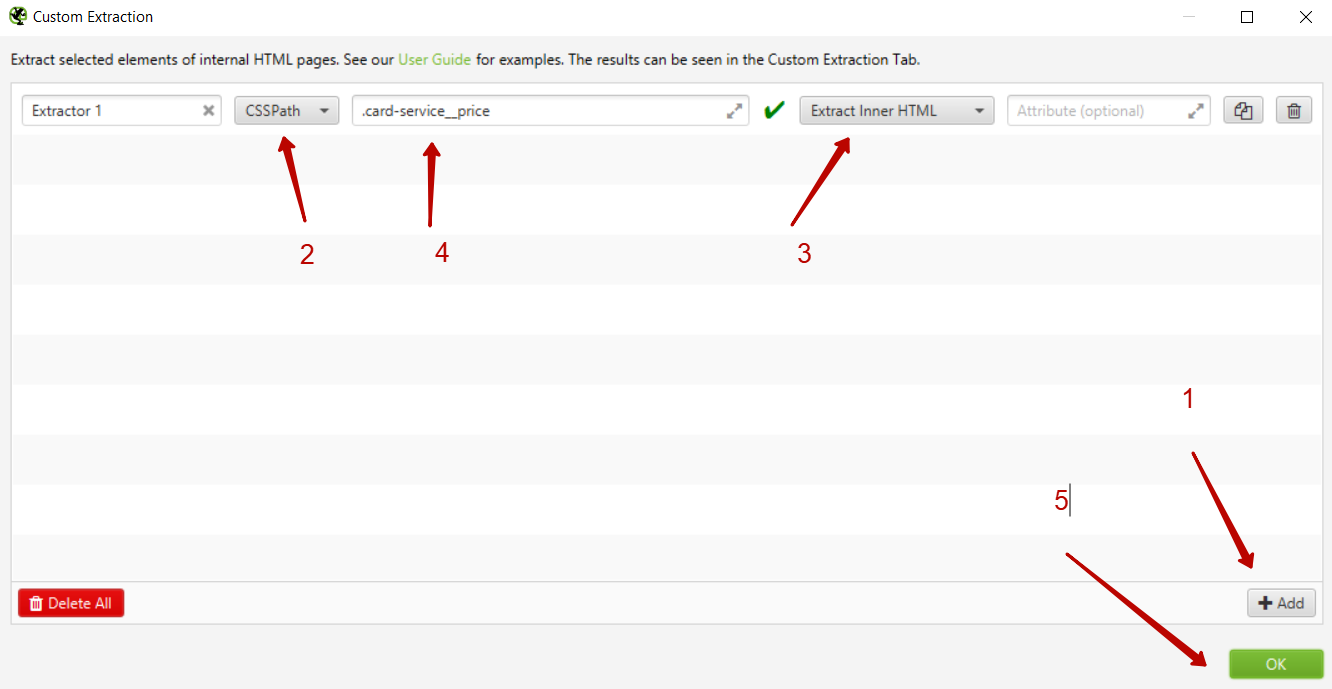
В интерфейсе Screaming Frog необходимо выбрать вкладку Configuration — Custom — Extraction.

Далее необходимо добавить новый элемент, нажав на кнопку add, и выбрать способ извлечения — CSSPath и что извлекаем — Extract Inner HTML. Далее указываем CSS стиль элемента, который ранее мы скопировали из кода сайта и ставим перед названием стиля точку.
После этого запускаем парсинг.
Нас интересуют только страницы услуг, поэтому необходимо отфильтровать только страницы раздела /services/, где размещены ссылки на страницы услуг. И мы получаем список извлеченных страниц и элементов и можем найти страницы, где отсутствует цена.
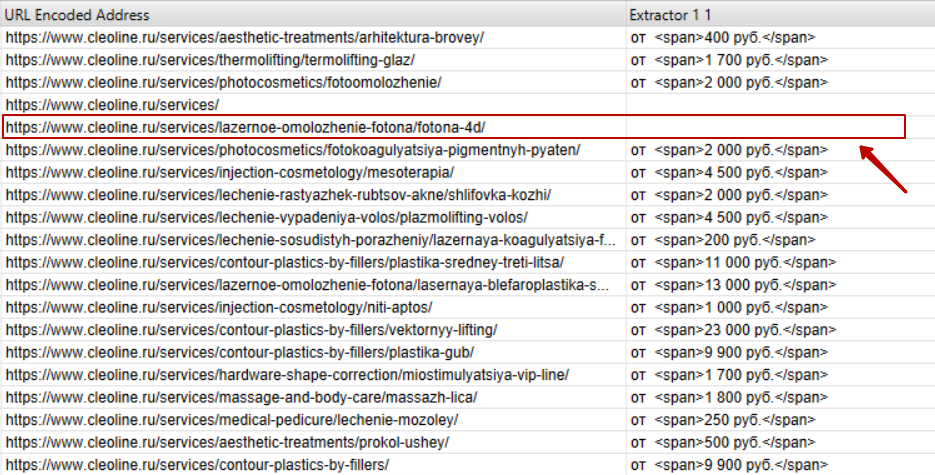
Функционал Custom Extraction довольно сложен, мы привели лишь небольшой пример, как с его помощью можно извлечь элементы страницы. Если вам будет интересно, мы можем рассказать о возможностях этой функции более подробно в следующей статье.
Выводы
Мы рассмотрели основные моменты, которые необходимо всегда проверять при проведении технического SEO-аудита в программе Screaming Frog. Многие технические проблемы / недочеты могут не оказывать прямого влияния на ранжирование сайта, однако в совокупности большое количество технических ошибок может значительно затруднить поисковое продвижение.
Обращаем внимание, что технический анализ должен проводиться не только через Screaming Frog, но и с помощью других инструментов, например Яндекс.Вебмастер и Google Search Console.
Мы рекомендуем не останавливаться на одной технической проверке и проводить такой анализ раз в 1-3 месяца, в зависимости от обновления страниц сайта.
Стоит учитывать, что устранение технических недочетов не гарантирует улучшение позиций и рост поискового трафика. Для увеличения видимости сайта в поисковых системах необходима комплексная доработка технической составляющей сайта, коммерческих факторов, работа с текстами и мета-тегами, структурой сайта, ссылочным окружением и другими факторами.
Если у вас остались какие-либо вопросы, — готовы ответить на них в комментариях.
А если вопросов будет много, подробнее раскроем их уже в следующих статьях.


