
Команда инженеров из MIT разработала объектно-ориентированную иерархию памяти для более эффективной работы с данными. В статье разбираемся с тем, как она устроена.

/ PxHere / PD
Как известно, рост производительности современных CPU не сопровождается соответствующим снижением задержки при обращении к памяти. Разница в изменении показателей от года к году может доходить до 10 раз (PDF, стр.3). Как результат — возникает бутылочное горлышко, которое не дает в полной мере пользоваться имеющими ресурсами и замедляет обработку данных.
Ущерб производительности наносит так называемая декомпрессионная задержка. В некоторых случаях на подготовительную декомпрессию данных может уходить до 64 процессорных циклов.
Для сравнения: сложение и умножение чисел с плавающей точкой занимают не больше десяти циклов. Проблема в том, что память работает с блоками данных фиксированного размера, а приложения — оперируют объектами, которые могут содержать различные типы данных и отличаться друг от друга по размеру. Чтобы решить проблему, инженеры из MIT разработали объектно-ориентированную иерархию памяти, которая оптимизирует обработку данных.
В основе решения лежат три технологии: Hotpads, Zippads и алгоритм сжатия COCO.
Hotpads — это программно-управляемая иерархия сверхоперативной регистровой памяти (scratchpad). Эти регистры называются пэдами (pads) и их три штуки — от L1 до L3. В них хранятся объекты разных размеров, метаданные и массивы указателей.
По сути, архитектура представляет собой систему кэшей, но заточенную для работы с объектами. Уровень пэда, на котором находится объект, зависит от того, как часто его используют. Если один из уровней «переполняется», система запускает механизм, аналогичный «сборщикам мусора» в языках Java или Go. Он анализирует, какие объекты используется реже остальных и автоматически перемещает их между уровнями.

Zippads сжимает объекты, чей объем не превышает 128 байт. Более крупные объекты делятся на части, которые затем размещаются в разных участках памяти. Как пишут разработчики, такой подход повышает коэффициент эффективно используемой памяти.
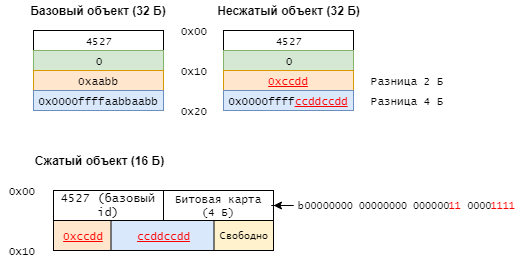
Для сжатия объектов применяется алгоритм COCO (Cross-Object COmpression), о котором мы расскажем далее, хотя система способна работать и с Base-Delta-Immediate или FPC. Алгоритм COCO представляет собой разновидность разностного сжатия (differential compression). Он сравнивает объекты с «базовыми» и удаляет повторяющиеся биты — см. схему ниже:
По словам инженеров из MIT, их объектно-ориентированная иерархия памяти на 17% производительнее классических подходов. Она гораздо ближе по своему устройству к архитектуре современных приложений, поэтому у нового метода есть потенциал.
Ожидается, что в первую очередь технологию могут начать использовать компании, которые работают с большими данными и алгоритмами машинного обучения. Еще одно потенциальное направление — облачные платформы. IaaS-провайдеры получат возможность эффективнее работать с виртуализацией, системами хранения данных и вычислительными ресурсами.
/ PxHere / PD
Как известно, рост производительности современных CPU не сопровождается соответствующим снижением задержки при обращении к памяти. Разница в изменении показателей от года к году может доходить до 10 раз (PDF, стр.3). Как результат — возникает бутылочное горлышко, которое не дает в полной мере пользоваться имеющими ресурсами и замедляет обработку данных.
Ущерб производительности наносит так называемая декомпрессионная задержка. В некоторых случаях на подготовительную декомпрессию данных может уходить до 64 процессорных циклов.
Для сравнения: сложение и умножение чисел с плавающей точкой занимают не больше десяти циклов. Проблема в том, что память работает с блоками данных фиксированного размера, а приложения — оперируют объектами, которые могут содержать различные типы данных и отличаться друг от друга по размеру. Чтобы решить проблему, инженеры из MIT разработали объектно-ориентированную иерархию памяти, которая оптимизирует обработку данных.
Как устроена технология
В основе решения лежат три технологии: Hotpads, Zippads и алгоритм сжатия COCO.
Hotpads — это программно-управляемая иерархия сверхоперативной регистровой памяти (scratchpad). Эти регистры называются пэдами (pads) и их три штуки — от L1 до L3. В них хранятся объекты разных размеров, метаданные и массивы указателей.
По сути, архитектура представляет собой систему кэшей, но заточенную для работы с объектами. Уровень пэда, на котором находится объект, зависит от того, как часто его используют. Если один из уровней «переполняется», система запускает механизм, аналогичный «сборщикам мусора» в языках Java или Go. Он анализирует, какие объекты используется реже остальных и автоматически перемещает их между уровнями.
Zippads работает на основе Hotpads — архивирует и разархивирует данные, которые поступают или покидают два последних уровня иерархии — пэд L3 и основную память. В первом и втором пэдах данные хранятся в неизменном виде.
Zippads сжимает объекты, чей объем не превышает 128 байт. Более крупные объекты делятся на части, которые затем размещаются в разных участках памяти. Как пишут разработчики, такой подход повышает коэффициент эффективно используемой памяти.
Для сжатия объектов применяется алгоритм COCO (Cross-Object COmpression), о котором мы расскажем далее, хотя система способна работать и с Base-Delta-Immediate или FPC. Алгоритм COCO представляет собой разновидность разностного сжатия (differential compression). Он сравнивает объекты с «базовыми» и удаляет повторяющиеся биты — см. схему ниже:
По словам инженеров из MIT, их объектно-ориентированная иерархия памяти на 17% производительнее классических подходов. Она гораздо ближе по своему устройству к архитектуре современных приложений, поэтому у нового метода есть потенциал.
Ожидается, что в первую очередь технологию могут начать использовать компании, которые работают с большими данными и алгоритмами машинного обучения. Еще одно потенциальное направление — облачные платформы. IaaS-провайдеры получат возможность эффективнее работать с виртуализацией, системами хранения данных и вычислительными ресурсами.
Наши дополнительные ресурсы и источники:
«Как мы строим IaaS»: материалы о работе 1cloud
Эволюция архитектуры облака 1cloud
Потенциальные атаки на HTTPS и способы защиты от них




