
Давненько я ничего не рассказывал о Яндекс.Браузере, а ведь интерес к нему на Хабре был нешуточный. Пора исправляться. Сегодня хочу поднять тему подсказок в адресной строке.
Задумайтесь, сколько раз в день вы вводите что-то в строку своего браузера. Вы набираете слово на клавиатуре, а браузер что-то предлагает в ответ. Это один из самых популярных сценариев, но мы почти никогда не задумываемся о том, как он работает. Вот об этом мы и поговорим сегодня. И помогут мне коллеги из команды поиска Яндекса, один из проектов которой — ранжирование подсказок в Браузере.
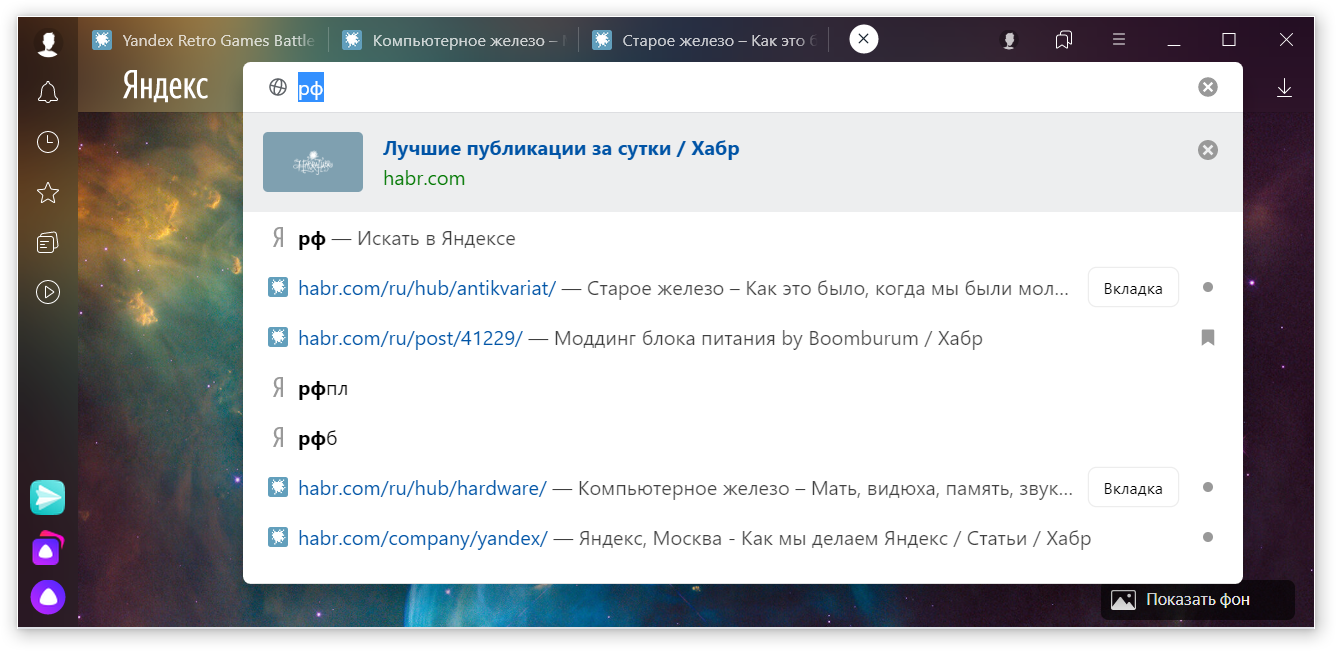
Для лучшего погружения в контекст начнём с истории. Помните ли вы первый браузер в мире? Тот самый, который создал Тим Бернерс-Ли, создатель языка JavaScript. Честно говоря, и я не помню, но хорошие люди сделали веб-версию для любопытных. Этот браузер умел отображать текст… и всё. Даже картинки на старте не поддерживал. А ещё там не было адресной строки в привычном для нас месте. Сайты открывались через меню, как документы в офисном редакторе. При этом было важно вводить точный адрес желаемой страницы. Забыли про http:// в начале? Получите Bad request. Никакого дружелюбия к пользователям не требовалось, потому что пользователями выступали учёные и технари.
Но затем интернет пришёл в дома «обычных» пользователей. Интерфейсы стали упрощаться: адресная строка поселилась у всех на виду, а рядом с ней добавили ещё одну — для поисковых запросов. Браузеры научились не только подставлять http://, но и подсказывать людям адреса уже посещённых страниц или введённые ранее запросы. Речь идёт про саджест — подсказки, которые появляются под строкой по мере ввода в неё текста.
Затем в Chrome адресную строку объединили с поисковой — так родился омнибокс, который умел переваривать как адреса, так и запросы. Причём саджест тоже стал единый. Браузерам пришлось учиться ранжированию подсказок. Поставить на первое место сайт из истории? Или из закладок? Или сходить в облако и предложить окончание запроса? Или оставить WYT (What You Typed) и отправить в поиск?
Добавьте к этому, что вариантов подсказок со временем становилось всё больше и больше. К примеру, в Яндекс.Браузере лет семь-восемь назад впервые предложили подсказки с быстрыми ответами. Это когда пользователь вводит [курс доллара], [погода] или [сколько лет илону маску] и сразу получает ответ в подсказке под строкой, без необходимости загружать страницу поисковой системы.

Ещё в англоязычном мире почему-то не знают о проблеме переключения раскладок. В своём браузере мы ещё на старте это решили. Например, если человек вводит [ьфшд], то браузер догадывается предложить не только поиск, но и адреса, начинающиеся с mail.

В общем, подсказок много, все они по отдельности полезны. Но если не суметь их качественно отранжировать, то толку будет мало.
Яндекс.Браузер основан на проекте Chromium, мы его любим, регулярно правим там баги, иногда оптимизируем, а если очень повезёт, то и наши продуктовые фишки туда прорастают. Поэтому мы изначально использовали логику ранжирования саджеста именно оттуда. Уверен, большинство из вас никогда не задумывались о том, как она работает. Давайте я расскажу.
Подсказки бывают двух типов: локальные и серверные. Для серверных нужно отправить запрос в облако и дождаться ответа. Для локальных, соответственно, не нужно. Прямо сейчас эта деталь неважна, но чуть ниже по тексту это станет важно. Итак, за каждую подсказку отвечает свой компонент. В Chromium их называют провайдерами. Все они действуют независимо друг от друга. На вход каждого провайдера подаётся вводимый пользователем текст. На выходе — подсказки с рассчитанной по своему алгоритму релевантностью. Этот алгоритм уникален для каждого провайдера и может учитывать частоту перехода по подсказке, когда это происходило последний раз, есть ли эта подсказка в закладках или только в истории и т. д.
Покажу это на примере.
Предположим, что пользователь вводит первую букву. Пусть это будет уже любимая нами буква m. Сразу после этого провайдеры начинают независимо друг от друга формировать подсказки и рассчитывать их релевантность.

Затем браузер объединяет эти подсказки в список, убирает дубликаты, сортирует по релевантности и показывает первые 10 результатов.

Вроде бы всё логично, да? Но у такого подхода есть недостаток: каждый провайдер вычисляет релевантность только на основе своих данных и никак не учитывает информацию, поступающую из других источников. Провайдеры неплохо ранжируют свои подсказки, но как соотнести релевантность одних подсказок с релевантностью других? В Chromium для этого ввели разные сложные эвристики, эмпирически подобрали коэффициенты для балансировки тех или иных источников. Со временем вмешиваться в эту логику стало просто страшно: слишком многое было захардкожено. При этом развивать ранжирование как-то нужно, ведь сами подсказки развиваются (появляются, исчезают, меняют форму). Если этим не заниматься, то сам инструмент со временем станет всё менее полезным.
Ну что же. Отсортировать несколько документов по релевантности — это классическая задача для машинного обучения, которая решается в поиске Яндекса каждый день. Тем более что в поисковой строке на yandex.ru тоже есть саджест и команда накопила существенный опыт в этом месте. Поэтому мы решили провести эксперимент, в котором будем смешивать подсказки от разных провайдеров с помощью ML.
Базовая идея первого подхода к снаряду состояла в том, чтобы взять все параметры, на основе которых провайдеры уже и так рассчитывают релевантность, обучить ML-модель и получить профит. Но не вышло.
Причина в том, что каждый провайдер работает с 1–2 параметрами. И в итоговой модели было всего 6–8 фич. Слишком мало для ML, хотя даже так получилось лучше, чем набор эвристик и констант. «Нужно больше золота», — подумали мы и пошли искать дополнительные фичи.
Что ж. Засучив рукава, мы начали сами формулировать новые фичи, которые можно было бы отдать машине. Например, длина адреса, его тип (https, ftp, file, about или что-то ещё), частота кликов пользователя по подсказкам такого типа и т. п. Всего мы напридумывали порядка 80 фич. Машине уже было где развернуться. Хотя в итоге и пришлось умерить наши аппетиты, но об этом чуть позже.
Итак, мы сформулировали десятки параметров, которые потенциально могли помочь машине отранжировать подсказки в саджесте с максимальной пользой для человека. Придумать мало — нужно ещё и в коде Браузера реализовать их учёт, чтобы и модель работала, и данные для её обучения были. На всякий случай напомню, что лог использования фич не только обезличен (даже urls передавались для обучения не явные, а в виде солёного хэша), но и не отправляется, если не стоит галочка про статистику в настройках. Кстати, этот шаг помог нам окончательно убедиться в необходимости доработок. В данных нашлись разнообразные стьюпиды. К примеру, подсказка из истории с десятками переходов могла неожиданно оказаться ниже, чем почти заброшенная закладка.
Чтобы предугадать дальнейшие шаги, достаточно прочитать несколько туториалов по машинному обучению. Буквально за пару дней собрали proof of concept на базе CatBoost. Более подробно об этой технологии мы уже рассказывали, когда выкладывали её в опенсорс. Напомню только, что эта ML-библиотека хорошо подходит для работы с разнородными фичами, что нам и было нужно. Далее обучили модель на сырых данных, без какой-либо обработки. Удивительно, но даже такое, сырое решение оказалось в среднем лучше, чем предыдущее. Хотя и не без проблем, поэтому нужно было перейти от концепта к нормальному решению.
В сырых данных, используемых для обучения модели, было много шума и мусора. Например, некоторые сессии работы с саджестом адресной строки длились 20 минут (очевидно, что человек открыл саджест и ушёл пить кофе — это не признак плохого саджеста). Или более 1000 открытий саджеста за короткий промежуток времени (а это вообще не люди, а боты какие-то). Всё это нужно было вычистить из данных, чтобы не искажать результат. Это несложно, но об этом было важно не забыть.
Затем мы обучили модель на чистых данных, перенесли её в код в Браузера и начали тестировать. И да, опять наступили на грабли.
Помните, чуть выше я рассказывал про то, что провайдеры бывают локальные и серверные? Если провайдер по своей природе может отрабатывать слишком долго, то его ответ не блокирует расчёт релевантности и отрисовку подсказок. Как только асинхронный провайдер соизволит ответить, происходит перерасчёт и перерисовка. Кстати, это касается не только серверных провайдеров, но и локального исторического, потому что он обращается к достаточно медленной базе SQLite. Из-за этого случился казус: подсказки в саджесте могли начать прыгать с места на место по мере набора букв. Опишу это на примере.
Допустим, пользователь вводит слово yandex.ru. Он набирает слово по буквам. На букве y в саджесте появляется десяток подсказок, несколько из которых это yandex.ru, mail.yandex.ru и maps.yandex.ru. По мере ввода yandex.ru оставался на первой позиции, но вот mail.yandex.ru и maps.yandex.ru прыгали и постоянно менялись местами. И это логично с технической точки зрения: асинхронность так и работает. Но это неприятно для пользователя, а значит, плохо для продукта.
Как такое побороть? Отказаться от асинхронности провайдеров? Это худший вариант, потому что тогда продукт начнёт тормозить в глазах человека. К счастью, мы нашли альтернативу. Методом проб и ошибок мы поняли, что 80 фич для ML — это даже избыточно. Многие из них не вносили существенной пользы в качество ранжирования, но при этом провоцировали прыжки подсказок. В итоге мы оптимизировали модель так, чтобы она работала на 40 наиболее полезных фичах, почти без потери качества, но зато — со стабильностью результатов.
На этом наша модель была готова. Результат — новый алгоритм, который на выходе формирует новую релевантность для подсказок. По сути, это число в диапазоне от 0,99...9 до 0,00...1. Чем больше, тем выше вероятность, что именно эту подсказку выберет человек. Но оставалось сделать ещё кое-что важное.
Машинное обучение — это инструмент, который позволяет добиться результата там, где человеческой памяти и ресурсов уже просто не хватает. Но он не идеален, поэтому человек всегда должен контролировать осмысленность происходящего. Например, в подсказках Браузера всегда должен быть пункт «Искать в [название поисковика]». Иначе ломается сама суть омнибокса. Другой пример: если человек вводит в строку адрес страницы, то на первом месте всегда должен быть вариант перейти по этому адресу, даже если машина посчитала такую подсказку менее полезной. Потому что вы вряд ли обрадуетесь, если привычное нажатие Enter отправит вас вовсе не туда, куда вы хотели. Подобные вещи не должны отдаваться на откуп машине. Их нужно учесть в продукте руками разработчика, а потом обязательно перепроверить глазами QA-инженера.
Эксперимент с новым ранжированием показал, что люди стали кликать на более высокие позиции в саджесте, что сказывается и на времени ввода запросов. Например, CTR второй подсказки вырос аж на 15%. Кстати, это подтвердилось и другим нашим экспериментом: суть его заключалась в уменьшении количества подсказок, которые показывали пользователю (с 10 до 8 штук). Эксперимент показал, что для пользователей изменение подсказок критично: в экспериментальной группе увеличилось число закрытий саджеста без перехода по подсказке. Но когда мы провели этот эксперимент с новым ранжированием, такого эффекта больше не наблюдалось. (На всякий случай скажу, что отказываться от девятой и десятой подсказки мы не стали: незачем сокращать выбор без явной пользы для человека.)
Конечно же, финальную точку ставить рано. Подсказки развиваются, а значит, их ранжирование должно развиваться тоже. У нас уже есть идеи на будущее. Например, добавить немного персонализации или поэкспериментировать с размером модели. Надеюсь, расскажем об этом в ближайшем будущем. Было бы интересно послушать и ваши идеи.
Задумайтесь, сколько раз в день вы вводите что-то в строку своего браузера. Вы набираете слово на клавиатуре, а браузер что-то предлагает в ответ. Это один из самых популярных сценариев, но мы почти никогда не задумываемся о том, как он работает. Вот об этом мы и поговорим сегодня. И помогут мне коллеги из команды поиска Яндекса, один из проектов которой — ранжирование подсказок в Браузере.
Для лучшего погружения в контекст начнём с истории. Помните ли вы первый браузер в мире? Тот самый, который создал Тим Бернерс-Ли, создатель языка JavaScript. Честно говоря, и я не помню, но хорошие люди сделали веб-версию для любопытных. Этот браузер умел отображать текст… и всё. Даже картинки на старте не поддерживал. А ещё там не было адресной строки в привычном для нас месте. Сайты открывались через меню, как документы в офисном редакторе. При этом было важно вводить точный адрес желаемой страницы. Забыли про http:// в начале? Получите Bad request. Никакого дружелюбия к пользователям не требовалось, потому что пользователями выступали учёные и технари.
Но затем интернет пришёл в дома «обычных» пользователей. Интерфейсы стали упрощаться: адресная строка поселилась у всех на виду, а рядом с ней добавили ещё одну — для поисковых запросов. Браузеры научились не только подставлять http://, но и подсказывать людям адреса уже посещённых страниц или введённые ранее запросы. Речь идёт про саджест — подсказки, которые появляются под строкой по мере ввода в неё текста.
Затем в Chrome адресную строку объединили с поисковой — так родился омнибокс, который умел переваривать как адреса, так и запросы. Причём саджест тоже стал единый. Браузерам пришлось учиться ранжированию подсказок. Поставить на первое место сайт из истории? Или из закладок? Или сходить в облако и предложить окончание запроса? Или оставить WYT (What You Typed) и отправить в поиск?
Добавьте к этому, что вариантов подсказок со временем становилось всё больше и больше. К примеру, в Яндекс.Браузере лет семь-восемь назад впервые предложили подсказки с быстрыми ответами. Это когда пользователь вводит [курс доллара], [погода] или [сколько лет илону маску] и сразу получает ответ в подсказке под строкой, без необходимости загружать страницу поисковой системы.
Ещё в англоязычном мире почему-то не знают о проблеме переключения раскладок. В своём браузере мы ещё на старте это решили. Например, если человек вводит [ьфшд], то браузер догадывается предложить не только поиск, но и адреса, начинающиеся с mail.
В общем, подсказок много, все они по отдельности полезны. Но если не суметь их качественно отранжировать, то толку будет мало.
Как мы ранжировали раньше
Яндекс.Браузер основан на проекте Chromium, мы его любим, регулярно правим там баги, иногда оптимизируем, а если очень повезёт, то и наши продуктовые фишки туда прорастают. Поэтому мы изначально использовали логику ранжирования саджеста именно оттуда. Уверен, большинство из вас никогда не задумывались о том, как она работает. Давайте я расскажу.
Подсказки бывают двух типов: локальные и серверные. Для серверных нужно отправить запрос в облако и дождаться ответа. Для локальных, соответственно, не нужно. Прямо сейчас эта деталь неважна, но чуть ниже по тексту это станет важно. Итак, за каждую подсказку отвечает свой компонент. В Chromium их называют провайдерами. Все они действуют независимо друг от друга. На вход каждого провайдера подаётся вводимый пользователем текст. На выходе — подсказки с рассчитанной по своему алгоритму релевантностью. Этот алгоритм уникален для каждого провайдера и может учитывать частоту перехода по подсказке, когда это происходило последний раз, есть ли эта подсказка в закладках или только в истории и т. д.
Покажу это на примере.
Предположим, что пользователь вводит первую букву. Пусть это будет уже любимая нами буква m. Сразу после этого провайдеры начинают независимо друг от друга формировать подсказки и рассчитывать их релевантность.
Затем браузер объединяет эти подсказки в список, убирает дубликаты, сортирует по релевантности и показывает первые 10 результатов.
Вроде бы всё логично, да? Но у такого подхода есть недостаток: каждый провайдер вычисляет релевантность только на основе своих данных и никак не учитывает информацию, поступающую из других источников. Провайдеры неплохо ранжируют свои подсказки, но как соотнести релевантность одних подсказок с релевантностью других? В Chromium для этого ввели разные сложные эвристики, эмпирически подобрали коэффициенты для балансировки тех или иных источников. Со временем вмешиваться в эту логику стало просто страшно: слишком многое было захардкожено. При этом развивать ранжирование как-то нужно, ведь сами подсказки развиваются (появляются, исчезают, меняют форму). Если этим не заниматься, то сам инструмент со временем станет всё менее полезным.
Как мы собрали концепт нового ранжирования
Ну что же. Отсортировать несколько документов по релевантности — это классическая задача для машинного обучения, которая решается в поиске Яндекса каждый день. Тем более что в поисковой строке на yandex.ru тоже есть саджест и команда накопила существенный опыт в этом месте. Поэтому мы решили провести эксперимент, в котором будем смешивать подсказки от разных провайдеров с помощью ML.
Базовая идея первого подхода к снаряду состояла в том, чтобы взять все параметры, на основе которых провайдеры уже и так рассчитывают релевантность, обучить ML-модель и получить профит. Но не вышло.
Причина в том, что каждый провайдер работает с 1–2 параметрами. И в итоговой модели было всего 6–8 фич. Слишком мало для ML, хотя даже так получилось лучше, чем набор эвристик и констант. «Нужно больше золота», — подумали мы и пошли искать дополнительные фичи.
Что ж. Засучив рукава, мы начали сами формулировать новые фичи, которые можно было бы отдать машине. Например, длина адреса, его тип (https, ftp, file, about или что-то ещё), частота кликов пользователя по подсказкам такого типа и т. п. Всего мы напридумывали порядка 80 фич. Машине уже было где развернуться. Хотя в итоге и пришлось умерить наши аппетиты, но об этом чуть позже.
Итак, мы сформулировали десятки параметров, которые потенциально могли помочь машине отранжировать подсказки в саджесте с максимальной пользой для человека. Придумать мало — нужно ещё и в коде Браузера реализовать их учёт, чтобы и модель работала, и данные для её обучения были. На всякий случай напомню, что лог использования фич не только обезличен (даже urls передавались для обучения не явные, а в виде солёного хэша), но и не отправляется, если не стоит галочка про статистику в настройках. Кстати, этот шаг помог нам окончательно убедиться в необходимости доработок. В данных нашлись разнообразные стьюпиды. К примеру, подсказка из истории с десятками переходов могла неожиданно оказаться ниже, чем почти заброшенная закладка.
Чтобы предугадать дальнейшие шаги, достаточно прочитать несколько туториалов по машинному обучению. Буквально за пару дней собрали proof of concept на базе CatBoost. Более подробно об этой технологии мы уже рассказывали, когда выкладывали её в опенсорс. Напомню только, что эта ML-библиотека хорошо подходит для работы с разнородными фичами, что нам и было нужно. Далее обучили модель на сырых данных, без какой-либо обработки. Удивительно, но даже такое, сырое решение оказалось в среднем лучше, чем предыдущее. Хотя и не без проблем, поэтому нужно было перейти от концепта к нормальному решению.
Как мы шлифовали наше решение
В сырых данных, используемых для обучения модели, было много шума и мусора. Например, некоторые сессии работы с саджестом адресной строки длились 20 минут (очевидно, что человек открыл саджест и ушёл пить кофе — это не признак плохого саджеста). Или более 1000 открытий саджеста за короткий промежуток времени (а это вообще не люди, а боты какие-то). Всё это нужно было вычистить из данных, чтобы не искажать результат. Это несложно, но об этом было важно не забыть.
Затем мы обучили модель на чистых данных, перенесли её в код в Браузера и начали тестировать. И да, опять наступили на грабли.
Помните, чуть выше я рассказывал про то, что провайдеры бывают локальные и серверные? Если провайдер по своей природе может отрабатывать слишком долго, то его ответ не блокирует расчёт релевантности и отрисовку подсказок. Как только асинхронный провайдер соизволит ответить, происходит перерасчёт и перерисовка. Кстати, это касается не только серверных провайдеров, но и локального исторического, потому что он обращается к достаточно медленной базе SQLite. Из-за этого случился казус: подсказки в саджесте могли начать прыгать с места на место по мере набора букв. Опишу это на примере.
Допустим, пользователь вводит слово yandex.ru. Он набирает слово по буквам. На букве y в саджесте появляется десяток подсказок, несколько из которых это yandex.ru, mail.yandex.ru и maps.yandex.ru. По мере ввода yandex.ru оставался на первой позиции, но вот mail.yandex.ru и maps.yandex.ru прыгали и постоянно менялись местами. И это логично с технической точки зрения: асинхронность так и работает. Но это неприятно для пользователя, а значит, плохо для продукта.
Как такое побороть? Отказаться от асинхронности провайдеров? Это худший вариант, потому что тогда продукт начнёт тормозить в глазах человека. К счастью, мы нашли альтернативу. Методом проб и ошибок мы поняли, что 80 фич для ML — это даже избыточно. Многие из них не вносили существенной пользы в качество ранжирования, но при этом провоцировали прыжки подсказок. В итоге мы оптимизировали модель так, чтобы она работала на 40 наиболее полезных фичах, почти без потери качества, но зато — со стабильностью результатов.
На этом наша модель была готова. Результат — новый алгоритм, который на выходе формирует новую релевантность для подсказок. По сути, это число в диапазоне от 0,99...9 до 0,00...1. Чем больше, тем выше вероятность, что именно эту подсказку выберет человек. Но оставалось сделать ещё кое-что важное.
Кое-что важное
Машинное обучение — это инструмент, который позволяет добиться результата там, где человеческой памяти и ресурсов уже просто не хватает. Но он не идеален, поэтому человек всегда должен контролировать осмысленность происходящего. Например, в подсказках Браузера всегда должен быть пункт «Искать в [название поисковика]». Иначе ломается сама суть омнибокса. Другой пример: если человек вводит в строку адрес страницы, то на первом месте всегда должен быть вариант перейти по этому адресу, даже если машина посчитала такую подсказку менее полезной. Потому что вы вряд ли обрадуетесь, если привычное нажатие Enter отправит вас вовсе не туда, куда вы хотели. Подобные вещи не должны отдаваться на откуп машине. Их нужно учесть в продукте руками разработчика, а потом обязательно перепроверить глазами QA-инженера.
Итоги
Эксперимент с новым ранжированием показал, что люди стали кликать на более высокие позиции в саджесте, что сказывается и на времени ввода запросов. Например, CTR второй подсказки вырос аж на 15%. Кстати, это подтвердилось и другим нашим экспериментом: суть его заключалась в уменьшении количества подсказок, которые показывали пользователю (с 10 до 8 штук). Эксперимент показал, что для пользователей изменение подсказок критично: в экспериментальной группе увеличилось число закрытий саджеста без перехода по подсказке. Но когда мы провели этот эксперимент с новым ранжированием, такого эффекта больше не наблюдалось. (На всякий случай скажу, что отказываться от девятой и десятой подсказки мы не стали: незачем сокращать выбор без явной пользы для человека.)
Конечно же, финальную точку ставить рано. Подсказки развиваются, а значит, их ранжирование должно развиваться тоже. У нас уже есть идеи на будущее. Например, добавить немного персонализации или поэкспериментировать с размером модели. Надеюсь, расскажем об этом в ближайшем будущем. Было бы интересно послушать и ваши идеи.


")
