Введение
Эта статья о том, как мы совместно с роснефтёвой «дочкой» «Самаранефтехимпроект» и Казанским Федеральным Университетом в сентябре 2020 года провели «Хакатон трёх городов», на котором предложили студентам решить классическую задачу сейсмической корреляции отражающих горизонтов. С такими задачами постоянно сталкиваются специалисты по сейсморазведке по всему миру. Для участников задачу решили преподнести как «задачу поиска оптимального пути», чтобы не отпугнуть студентов страшными словами. В статье расскажем подробнее про задачу и разберём интересные решения участников. Это будет увлекательно для специалистов как по прикладному математическому моделированию, так и машинному обучению и анализу данных.
Организационная часть
Интересные подробности организации онлайн-хакатона в трёх городах мы рассказали в статье на vc.ru – Нефтянка и хакатон. Марафон – это не только бег.
Упомянем лишь, что для онлайн-формата мы выбрали сервис Discord и оставим ссылку на правила хакатона (ссылка на площадке Boosters).
Постановка задачи
В сейсморазведке существует понятие «сейсмический отражающий горизонт» – это устойчивая по динамике и площади распространения отражённая волна, которая соответствует определённой геологической границе. Корректно проведя обработку полевых сейсмических данных и распознав (специалисты по сейсморазведке говорят – «проинтерпретировав») сейсмические горизонты, можно с точностью до 5-10 метров определить глубины их залегания. Определив глубины, далее можно уже вместе с геологами привязать данные горизонты к геохронологической шкале (Геохронологическая шкала – Википедия) и распознать их более мелких собратьев. А после чего решать – между какими горизонтами могут залегать ловушки с нефтью, как выглядит рельеф структурной модели месторождения и др.

Вертикальные сечения сейсмического куба и распознанные сейсмические отражающие горизонты
На практике горизонты выделяются послойно на сейсмических разрезах сейсмического куба – как вручную, с помощью расстановки (специалисты по сейсморазведке говорят – «пикирования») большого числа реперных точек, так и с помощью автоматизированных и полуавтоматизированных процедур поиска. Безусловно, качественное решение задачи интерпретации сейсмических горизонтов с помощью программного обеспечения крайне востребовано и позволяет существенно снизить временные затраты специалистов по сейсморазведке.
В то же время, изучение источников (Least-squares horizons with local slopes and multi-grid correlations, Waveform Embedding: automatic horizon picking with unsupervised deep learning) показывает, что разработанные алгоритмы и решения основаны на небольшом числе математических подходов, поэтому мы решили попробовать привлечь студентов с их ещё не затуманенным научными изысканиями сознанием и предложить им данную задачу в форме задачи поиска оптимального пути на сложной поверхности.
В итоге задача была сформулирована так: построение пути движения на сложной поверхности, проходящего через заданные точки и удовлетворяющего условиям минимума некоторого функционала, зависящего от длины пути и его углов (градиентов).
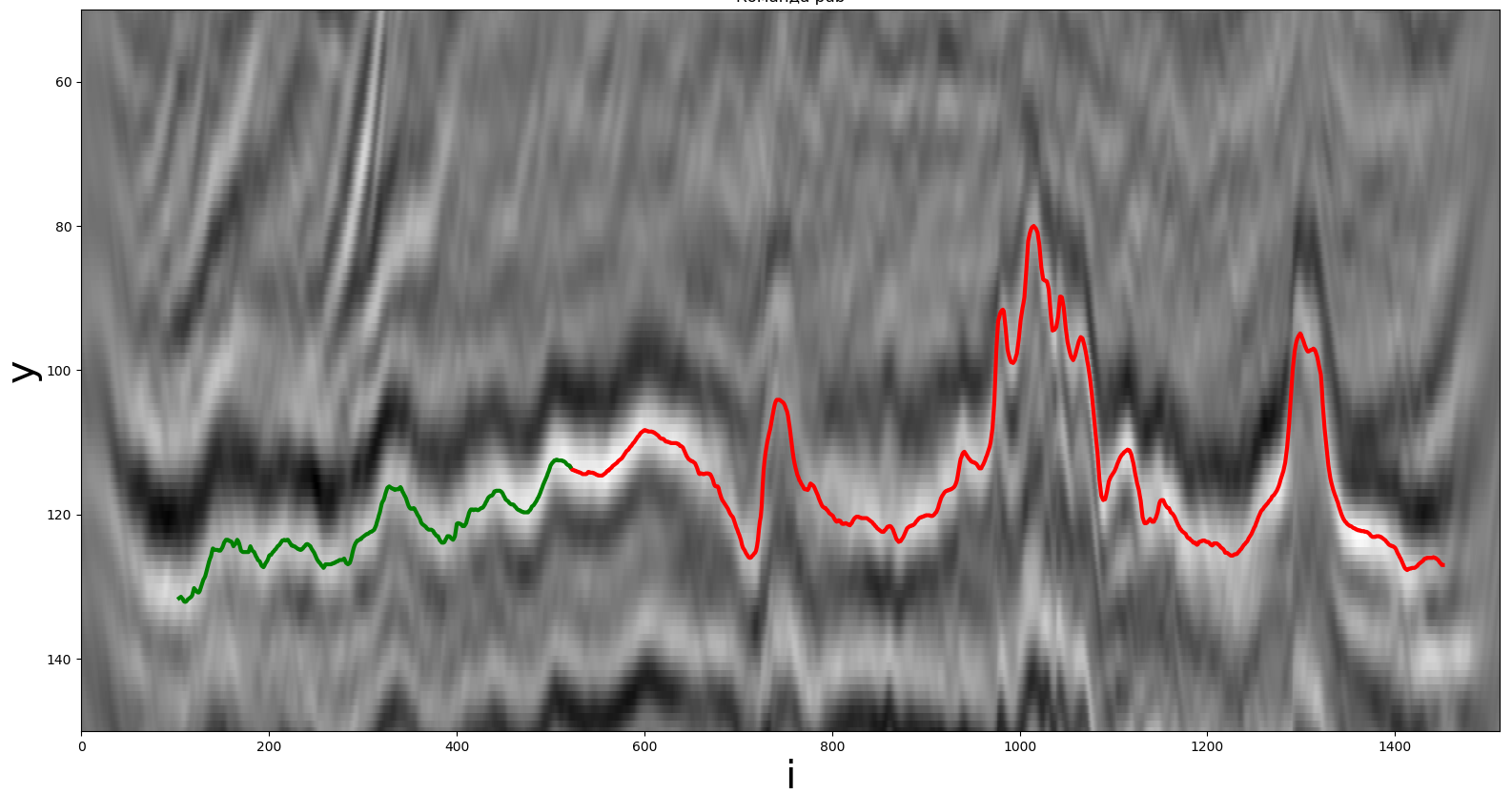
Пример части исходного сейсмического разреза для построения горизонта. Зеленая линия – заранее известная часть, красная – искомая.
Участникам соревнования предстояло за 12 часов найти решение, позволяющее продолжить путь по оптимальной траектории на скрытой части датасета. На валидацию решения предоставлялось 20 попыток, побеждал участник с минимальным значением метрики.
Подробное описание данных
Ниже подробное описание данных, которые были доступны участнику:


Визуализация всех данных, которые были доступны участнику – 2 сейсмических среза с горизонтами.
По-простому, участнику надо было продолжить hor_2 в области L1. Область L2 представляла собой перпендикулярный срез L1. Мы её добавили для генерации участниками дополнительных знаний. Но, к сожалению, она не пригодилась участникам.
Визуализация всех данных, которые были доступны участнику – 2 сейсмических среза с горизонтами.
По-простому, участнику надо было продолжить hor_2 в области L1. Область L2 представляла собой перпендикулярный срез L1. Мы её добавили для генерации участниками дополнительных знаний. Но, к сожалению, она не пригодилась участникам.
На протяжении соревнования турнирная таблица строилась на основе значений метрики на публичной части тестовых данных. После окончания соревнования значение метрики было пересчитано на приватной части, и турнирная таблица была обновлена. Это важно для того, чтобы получить устойчивые решения, то есть не только подогнанные под публичные данные, но и способные показать сопоставимый результат на приватных. Оказалось, что это было сделано не зря, и после финальной оценки качества турнирная таблица изменилась.
Для количественной оценки полученных результатов использовалась следующая метрика:
где:
N– размерность искомого горизонта;
yi pred– координаты горизонта, полученного с помощью алгоритма, i0,N;
yi etalon– координаты эталонного горизонта;
zi,yi – значения карты поверхности в точке с координатамиi,yi;
yi =yiheight, где height – максимально возможное значение координаты y карты поверхности;
zi,yi=zi,yimax(z), где max(z) – наибольшее значение карты поверхности.
Реализация метрики в Python

Какие методы применяли команды
Задача подбиралась изначально такой, которую можно было бы решить несколькими способами: прямым и обратным (классическими математическими методами и методами машинного обучения соответственно).
С точки зрения машинного обучения задачу можно решать двумя методами:
1) Построение регрессии
Используя известные пары точек (xi,yi), можно построить отображение f:(xi)↦yi путём минимизации функции потерь L. (xi)– признаковое описание i-й точки.

Функцией потерь может быть как исходная функция ошибки из постановки задачи, так и более простая функция, например, среднеквадратическое отклонение построенного и исходного путей:1Ni=1N(yi — yi)^2.
Для построения отображения f можно воспользоваться множеством популярных методов машинного обучения: начиная с полиномиальной регрессии, проходя через случайный лес и глубокими нейронными сетями.

2) Семантическая сегментация

Пример семантической сегментации
Исходную задачу можно решать как задачу компьютерного зрения. Точки (x, y) рассматривать как пикселы изображения, где всё изображение – это весь датасет, а «яркость» пиксела (x, y) – значение z(x, y). Для построения пути нужно каждому пикселю присвоить один из классов – 0 или 1. Часть изображения, находящаяся ниже пути или включающая его, относится к классу 0, а оставшаяся – к классу 1. Бытовое решение для такой задачи – полносвёрточная нейросеть U-Net, на вход получающая кусок (патч) исходного изображения и выдающая массив того же размера, состоящий из нулей и единиц, обозначающих классы соответствующих пикселов.
Кроме методов глубокого обучения, для сегментации изображений можно также использовать методы классического компьютерного зрения и обработки изображений, например, Flood fill. Это и сделал один из участников, тем самым предобработав изображение для дальнейшего применения алгоритмов поиска кратчайшего пути.
С точки зрения классических математических методов предложенная задача является классической задачей оптимизации, и мы наблюдали попытки её решения следующими группами методов:
1. Методы, использующие принцип локального экстремума;
Суть данного подхода заключается в поиске локальных экстремумов значений поверхности в пределах заданного окна поиска. Далее выбирается то значение координаты y среди найденных экстремумов, которое наименьшим образом отличается от y, найденного на предыдущем шаге.
2. Методы, использующие принцип глобального экстремума;
В рамках данного подхода при определении координаты yi ищется глобальный экстремум среди усреднённых значений поверхности карты в пределах заданного окна поиска.
3. Методы, основанные на минимизации заданной эвристики.
Данным подходом воспользовалось несколько команд, суть данного подхода заключается создании и минимизации предложенного командами функционала.
Итоги и кто победил
Для начала разберём решения участников.
Методы машинного обучения:
Одним из решений была авторегрессионная свёрточная нейросеть, выдающая вещественное число – значение пути yi для i-го шага. На вход нейросети подавались патчи 32x32 пиксела исходного изображения. В качестве функции для извлечения признаков использовалась предобученная свёрточная нейросеть ResNet34. Полученное этой нейросетью признаковое представление объединялось со значениями данного пути с предыдущих 32 шагов. Для прогнозирования дальше 32 шагов в качестве предыдущих значений горизонта использовались предыдущие прогнозы нейросети. Нейросеть обучалась модификацией стохастического градиентного спуска Adam с экспоненциальным уменьшением шага оптимизатора по мере обучения. Для обучения минимизировалось среднее абсолютное отклонение (эксперименты со среднеквадратическим отклонением дали хуже результат). Во избежание переобучения использовался Дропаут, то есть случайное обнуление части нейронов. Для обучения нейросети потребовалось около 10 минут, 20 полных проходов по всему датасету и 720 шагов оптимизатора.
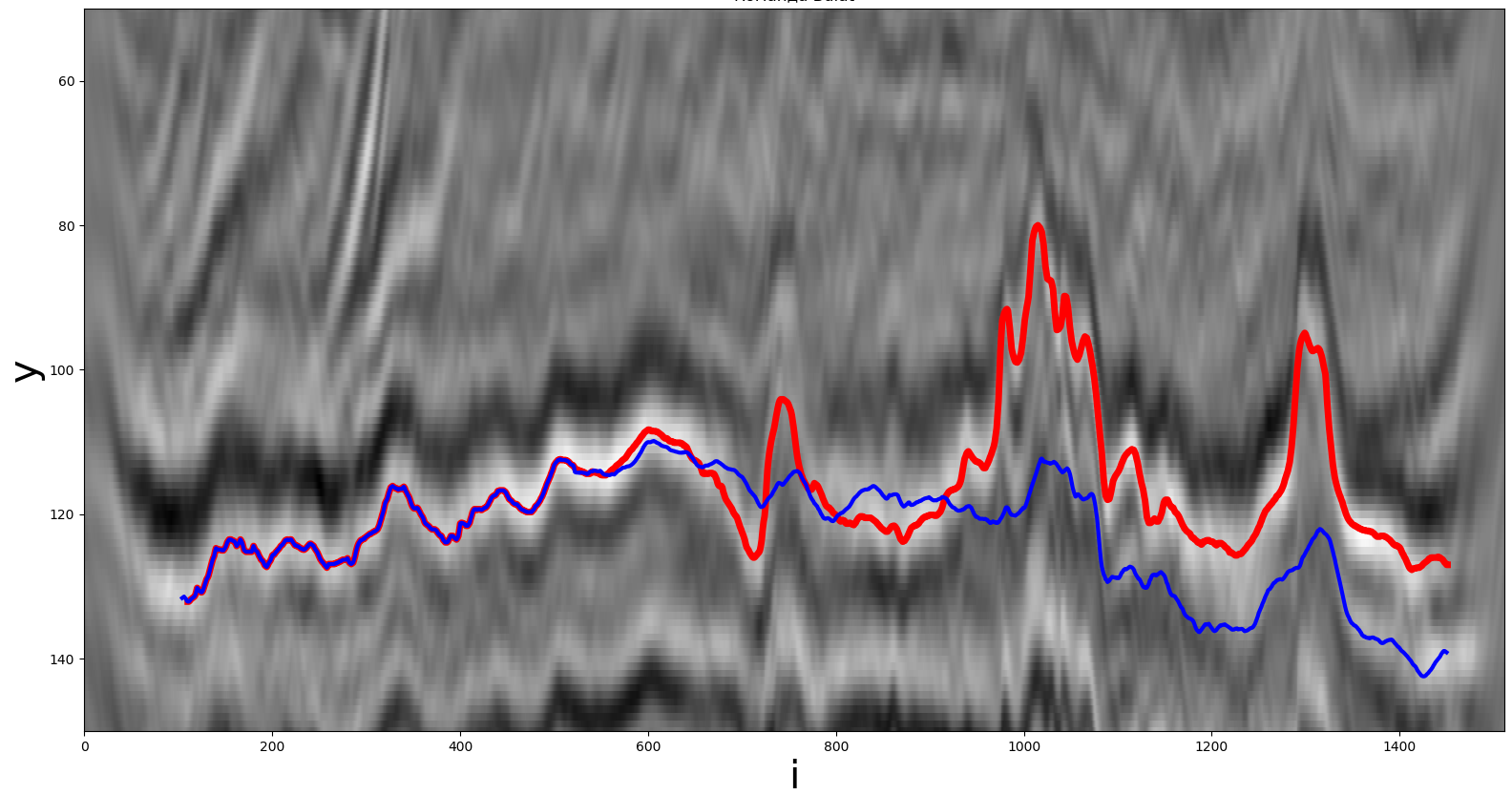
Решение, полученное с помощью свёрточной нейросети. Красная линия – реальный путь, синяя – полученный участником.
Прогноз нейросети занимает около 1 минуты на CPU AMD Threadripper 2950x и GPU Nvidia GTX 1080 Ti.
Результат нейросети (метрика) – 5.71 на публичной турнирной таблице. Также были проделаны эксперименты с заменой свёрточной нейросети на рекуррентную, но её результат был хуже. В итоге в качестве финального решения были использованы классические методы вычислительной математики.
Кроме законченных решений, участники также поделились своими идеями, которые не успели реализовать из-за жёстких временных рамок соревнования и вычислительной сложности их задумок. Некоторые из них пытались применить нейронные сети, но, потратив большую часть времени, переходили к более простым и эффективным алгоритмам или даже к грубому перебору и правилам, что в итоге дало лучший результат и привело к призовым местам.
Также ряд интересных решений основан на знаниях из других дисциплин: например, классическое компьютерное зрение и обработка изображений, теория графов, анализ временных рядов. Одна из команд даже поставила задачу в терминах обучения с подкреплением, про которое вы могли слышать, и придумала решение, но, к сожалению, не успела его реализовать.
Классические математические методы:
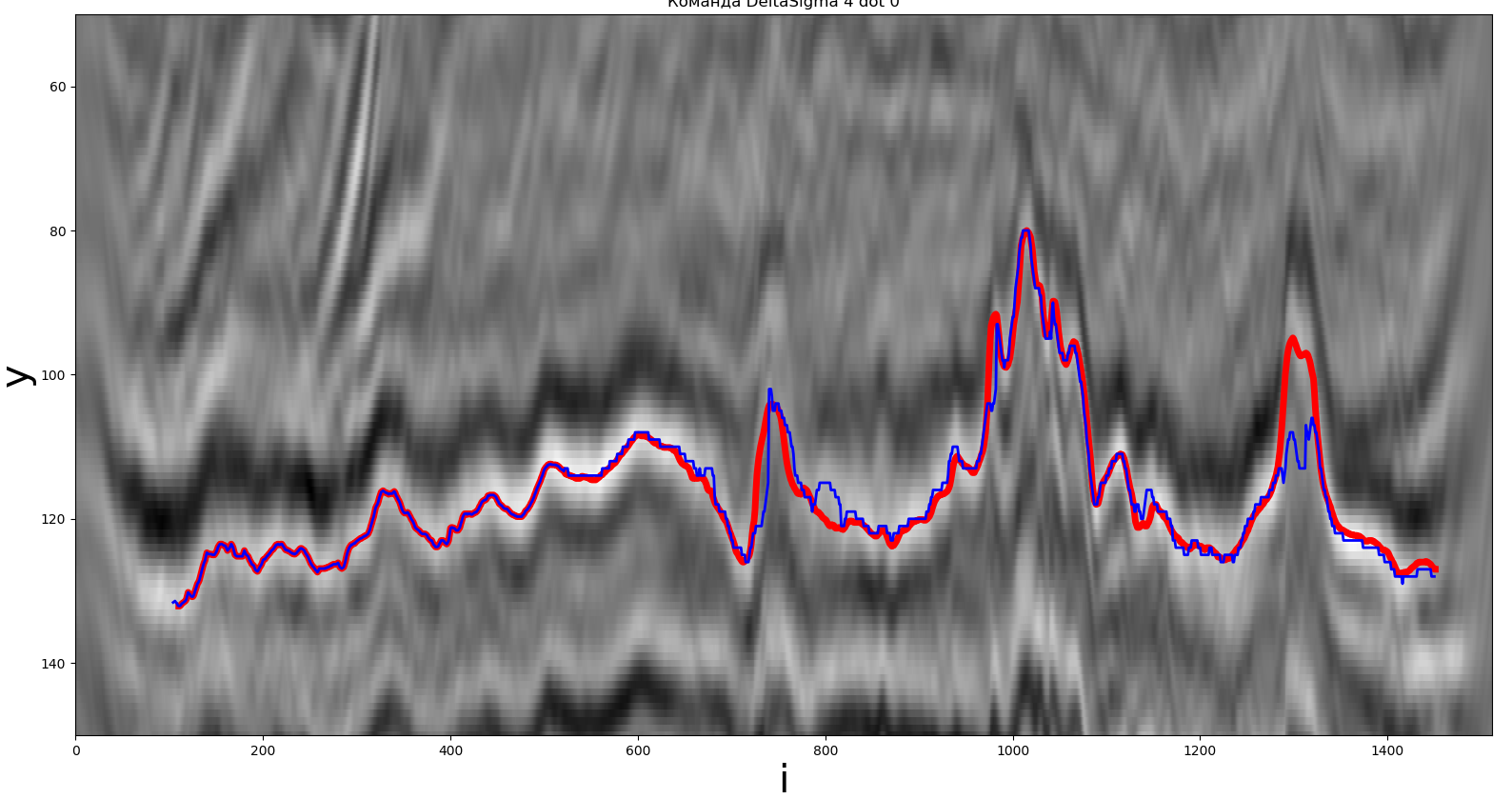
Одно из решений, полученное методом локального экстремума. Красная линия – реальный путь, синяя – полученная участником.
Для данного метода в качестве экстремума использовался локальный максимум. Синим цветом отмечен построенный участниками путь, красным – искомый горизонт. Подробное описание представлено ниже.
yi+1=minj-yi,i0,N-1,j,
=m|z(i,m)>z(i,m-1)z(i,m)>z(i,m+1),mm1,m2,
m1=max(1,yi-sizey),
m2=min(height-1,yi+sizey),
где:
height – максимально возможное значение координаты y карты поверхности;
sizey – размер окна поиска.
Метод реализован на языке Python. Время работы составило порядка 0.103 секунд, F(y, z) = 1.57, sizey= 100.
Вывод: метод достаточно прост для реализации, время работы не превышает 0.1 секунды.
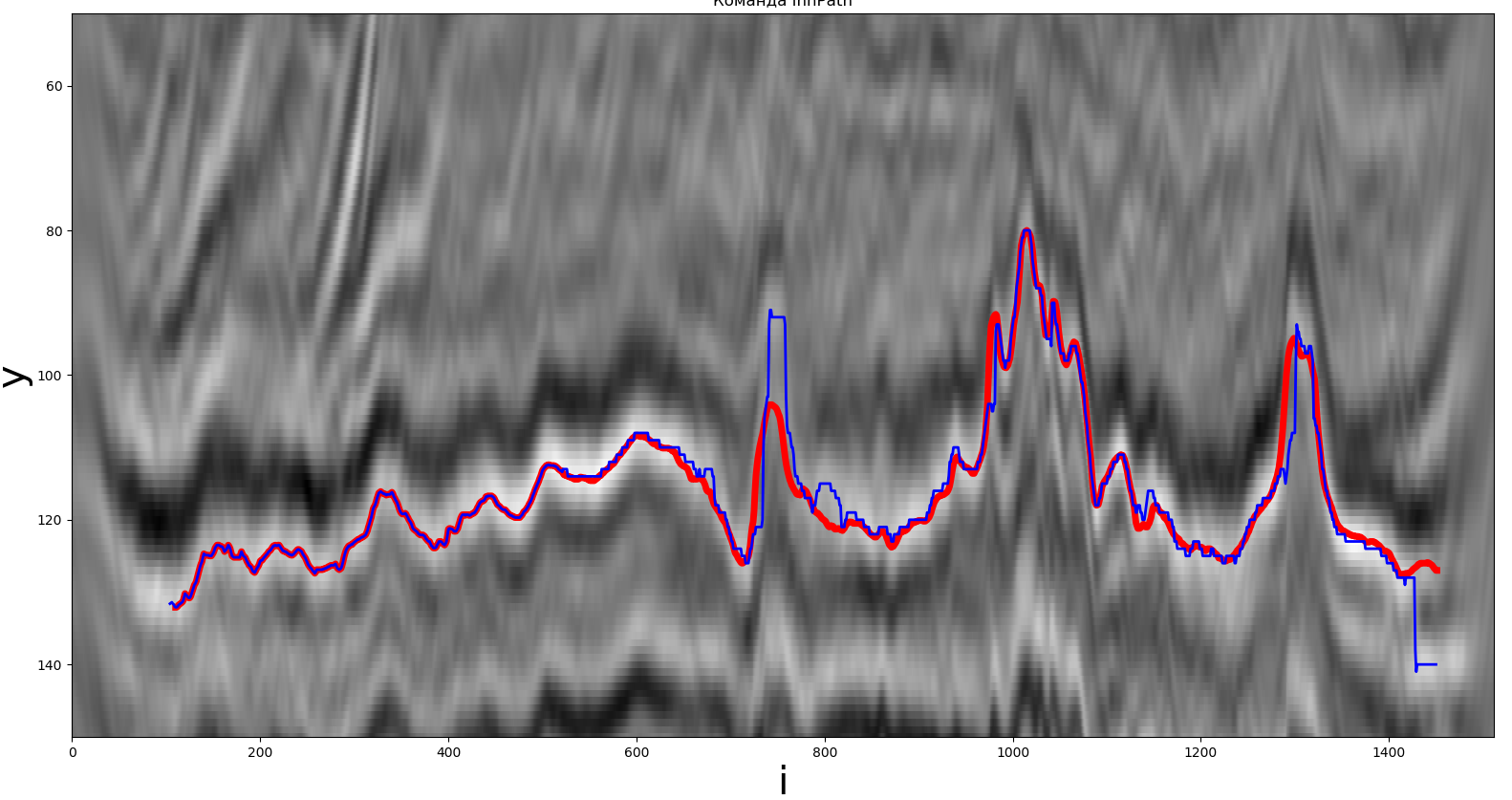
Одно из решений, полученное глобальным экстремумом. Красная линия – реальный путь, синяя – полученный участником.
Перейдём к следующей группе. Как и ранее, в данном методе максимум использовался в качестве экстремума.
yi=argmax1sizex j=0sizex-1z(i+j,m),i0,N,mm1,m2,
m1=max(1,yi-sizey),
m2=min(height-1,yi+sizey),
где:
height – максимально возможное значение координаты y карты поверхности;
sizex,sizey – размер окна поиска.
Метод реализован на языке Python. Время работы составило порядка 0.19 секунд, F(y, z) = 1.97, sizex= 9, sizey= 21.
Вывод: метод достаточно прост для реализации, время работы не превышает 0.2 секунд.
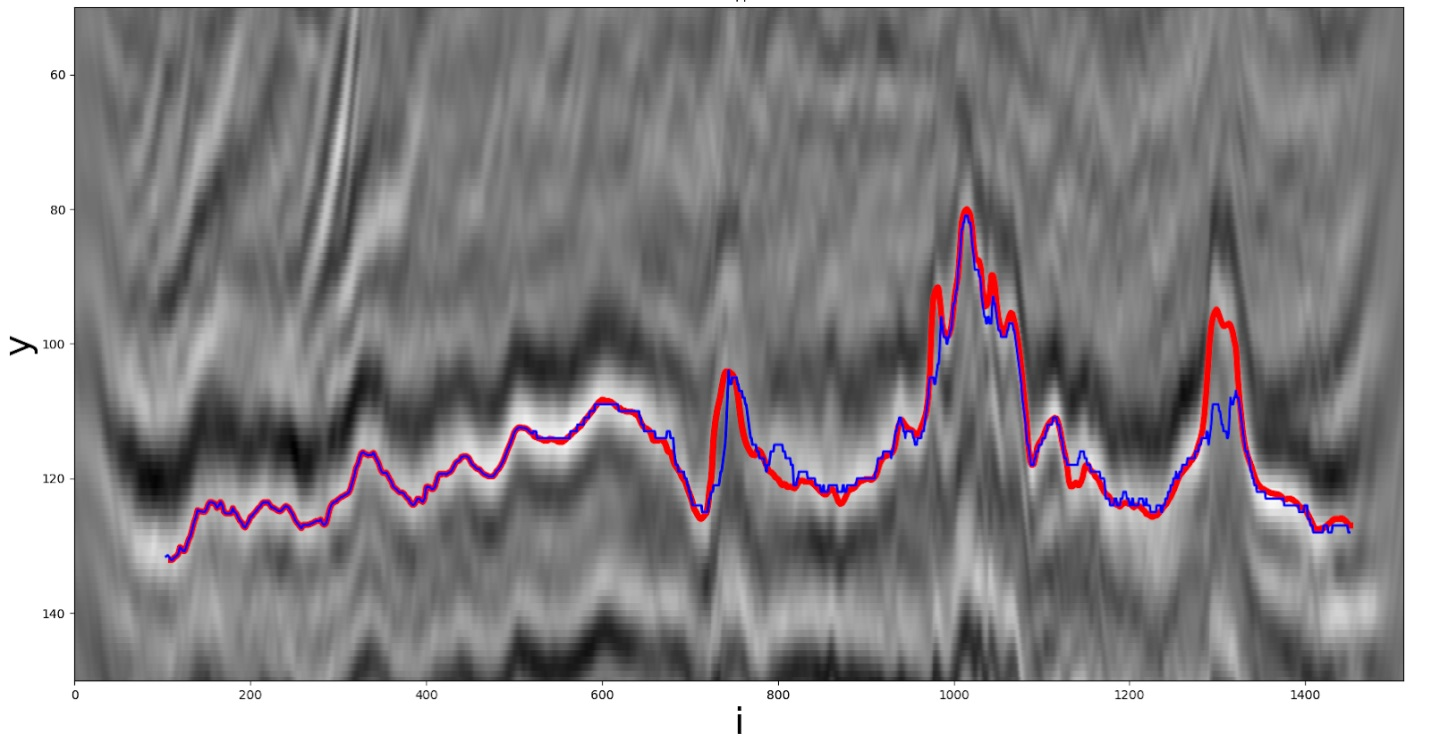
Одно из решений, полученное эвристикой. Красная линия – реальный путь, синяя – полученный участником.
Рассмотрим последнюю группу методов. Как уже говорилось ранее, очередная координата yi+1 ищется по минимуму функционала в пределах заданного окна поиска.
Ниже представлен один из функционалов, предложенных командами. С математической точки он выглядит следующим образом:
yi+1=min(z(i,j)-z(i,yi))2max2(z)+(j-yi)2height2,i0,N-1,j,
=m|z(i,m)>z(i,m-1)z(i,m)>z(i,m+1),mm1,m2,
m1=max(1,yi-sizey),
m2=min(height-1,yi+sizey),
где:
height – максимально возможное значение координаты y карты поверхности;
– коэффициент, отвечающий за влияние ошибки по y на значение функционала;
sizey – размер окна поиска;
max(z) – наибольшее значение карты поверхности.
Метод был реализован на языке Python. Время работы составило порядка 0.12 секунд, F(y, z) = 1.58, sizey= 50, = 15000.7.
Вывод: время работы метода не превышает 0.15 секунд.
Методы всех трех групп показали достаточно близкие результаты на заданном наборе данных. Наименьшее значение метрики (1.57) было достигнуто методом, основанным на поиске локальных экстремумов значений поверхности в пределах заданного окна поиска.
Заключительная часть
К сожалению, к концу хакатона почти все новаторы
Мы хотели объединить участников из двух областей: вычислительной математики и машинного обучения. Одни привыкли работать с неструктурированными данными неизвестной природы, другие – изучать физические процессы и строить на их основе математические модели. Чтобы увеличить разнообразие идей и решений, мы кратко рассказали, как были получены данные. Это одна из причин, по которой решение на основе простых численных методов дало лучшие результаты. Второй причиной стало то, что для студенческого хакатона мы подготовили не очень «сложные» данные небольшого объёма, поэтому современные трудоёмкие методы машинного обучения проигрывают более простым альтернативам.
Мы считаем, что это отличный урок, который поможет участникам правильно ставить задачи и выбирать оптимальные методы для их решения. Важно помнить, что сначала стоит попробовать простое решение, так называемый бейзлайн, возможно именно он позволит достичь цели в короткие сроки.
Участниками Хакатона были предложены авторские алгоритмы нахождения оптимального пути в массиве больших данных применительно к задаче автоматической сейсмической кинематической интерпретации, которая в настоящее время решается в рамках разработки корпоративного программного обеспечения в области геологии и сейсмики. Наиболее конкурентные реализации алгоритмов найдут своё применение при разработке и реализации программных модулей данных программных комплексов.
Будем рады вас видеть на финале марафона ИТ-соревнований, который пройдёт 28 ноября онлайн. В программе: награждение победителей соревнований, презентация первой версии мобильного приложения для экспресс-оценки качества пропанта. Также в рамках мероприятия будут организованы панельные дискуссии на актуальные темы «Управление данными и DS проектами» и «Компьютерное зрение». Интересными кейсами поделятся представители «Head of Data Science Alfa», CDO «Мегафон», «Huawei», «Head of CV X5» и др. Не пропустите всё самое интересное (Марафон ИТ-соревнований 2020 – Роснефть).




