

Многие сетевые приложения состоят из веб-сервера, обрабатывающего трафик в реальном времени, и дополнительного обработчика, запускаемого в фоне асинхронно. Есть множество отличных советов по проверке состояния трафика да и сообщество не перестает разрабатывать инструменты вроде Prometheus, которые помогают в оценке. Но обработчики порой не менее – а то и более – важны. Им также нужны внимание и оценка, однако руководства по тому, как осуществлять это, избегая распространенных подводных камней, мало.
Эта статья посвящена ловушкам, наиболее часто встречающимся в процессе оценки асинхронных обработчиков, — на примере инцидента в рабочей среде, когда даже при наличии метрик невозможно было точно определить, чем заняты обработчики. Применение метрик сместило фокус настолько, что сами же метрики откровенно врали, мол, обработчики ваши ни к черту.
Мы увидим, как использовать метрики таким образом, чтобы обеспечить точную оценку, а в заключении покажем эталонную реализацию prometheus-client-tracer с открытым исходным кодом, который и вы можете применить в своих приложениях.
Инцидент
Оповещения прилетали с пулеметной скоростью: резко выросло число ошибок HTTP, и панели управления подтверждали — очереди запросов растут, а время ответа на них истекает. Минуты 2 спустя очереди расчистились, и все пришло в норму.
При ближайшем рассмотрении выяснилось, что наши API серверы встали, ожидая ответа БД, из-за чего забуксовала и внезапно встала вся активность. А если учесть, что самая тяжелая нагрузка ложится чаще на уровень асинхронных обработчиков, они и стали главными подозреваемыми. Напрашивался логичный вопрос: чем они там вообще заняты?!
Метрика Prometheus показывает, на что у обработчиков уходит время, вот она:
# HELP job_worked_seconds_total Sum of the time spent processing each job class
# TYPE job_worked_seconds_total counter
job_worked_seconds_total{job}Отследив суммарное время исполнения каждой задачи и частоту, с которой меняется метрика, мы узнаем, сколько потрачено рабочего времени. Если за отрезок в 15 сек. цифра выросла на 15, это подразумевает 1 занятый обработчик (по секунде на каждую прошедшую секунду), тогда как увеличение на 30 подразумевает 2 обработчика и т.д.
График рабочей активности во время инцидента покажет, с чем мы столкнулись. Результаты неутешительные; время инцидента (16:02–16:04) отмечено линией тревожного (в масть) красного цвета:

Активность обработчика во время инцидента: виден заметный пробел.
Мне, как человеку, который занимался отладкой после этого кошмара, больно было видеть, что кривая активности оказалась в самом низу как раз во время инцидента. Это — время работы с веб-хуками, на которой у нас занято 20 выделенных обработчиков. Из логов я знаю, что все они были при деле, и я ждал, что кривая будет примерно на уровне 20 сек., а увидел почти ровную прямую. Более того, видите этот большой синий пик в 16:05? Судя по графику, 20 однопоточных обработчиков затратило 45 сек. на каждую секунду деятельности, но разве такое возможно?!
Где и что пошло не так?
График инцидента врет: скрывает рабочую активность и одновременно показывает лишнее — смотря, где замерять. Чтобы выяснить, почему так происходит, нужно принять во внимание реализацию отслеживания метрик и как она взаимодействует с Prometheus, собирающим метрики.
Начав с того, как обработчики собирают метрики, можно набросать примерную схему реализации рабочего процесса (см.ниже). Заметьте: обработчики обновляют метрики только по завершению задачи.
class Worker
JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...)
def work
job = acquire_job
start = Time.monotonic_now
job.run
ensure # run after our main method block
duration = Time.monotonic_now - start
JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class })
end
endPrometheus (с его философией извлечения метрик) посылает GET-запрос каждому обработчику каждые 15 сек., записывая значения метрик на момент запроса. Обработчики постоянно обновляют метрики выполненных задач, и мы со временем можем графически отобразить динамику изменения значений.
Проблема с недо- и переоценкой начинает проявляться всякий раз, когда когда срок выполнение задачи превышает время ожидания запроса, приходящего каждые 15 секунд. Например, какая-нибудь задача начинается за 5 секунд до запроса и завершается через 1 секунду после. Целиком и в общем, оно длится 6 секунд, но это время видно только при оценке временных затрат, сделанной после запроса, тогда как 5 из этих 6 секунд затрачены до запроса.
Показатели врут еще безбожнее, если задачи занимают больше времени, чем отчетный период (15 секунд) За время выполнения задачи на 1 минуту Prometheus успеет послать обработчикам 4 запроса, однако метрика обновится только после четвертого.
Нарисовав временную шкалу рабочей активности, увидим, как момент обновления метрики влияет на то, что видит Prometheus. На схеме ниже мы разобьем временную шкалу двух обработчиков на несколько отрезков, отображающих задачи разной продолжительности. Красным (15 секунд) и синим (30 секунд) ярлычками отмечены 2 забора данных Prometheus; задачи, послужившие источником данных для оценки, отмечены цветом соответственно.
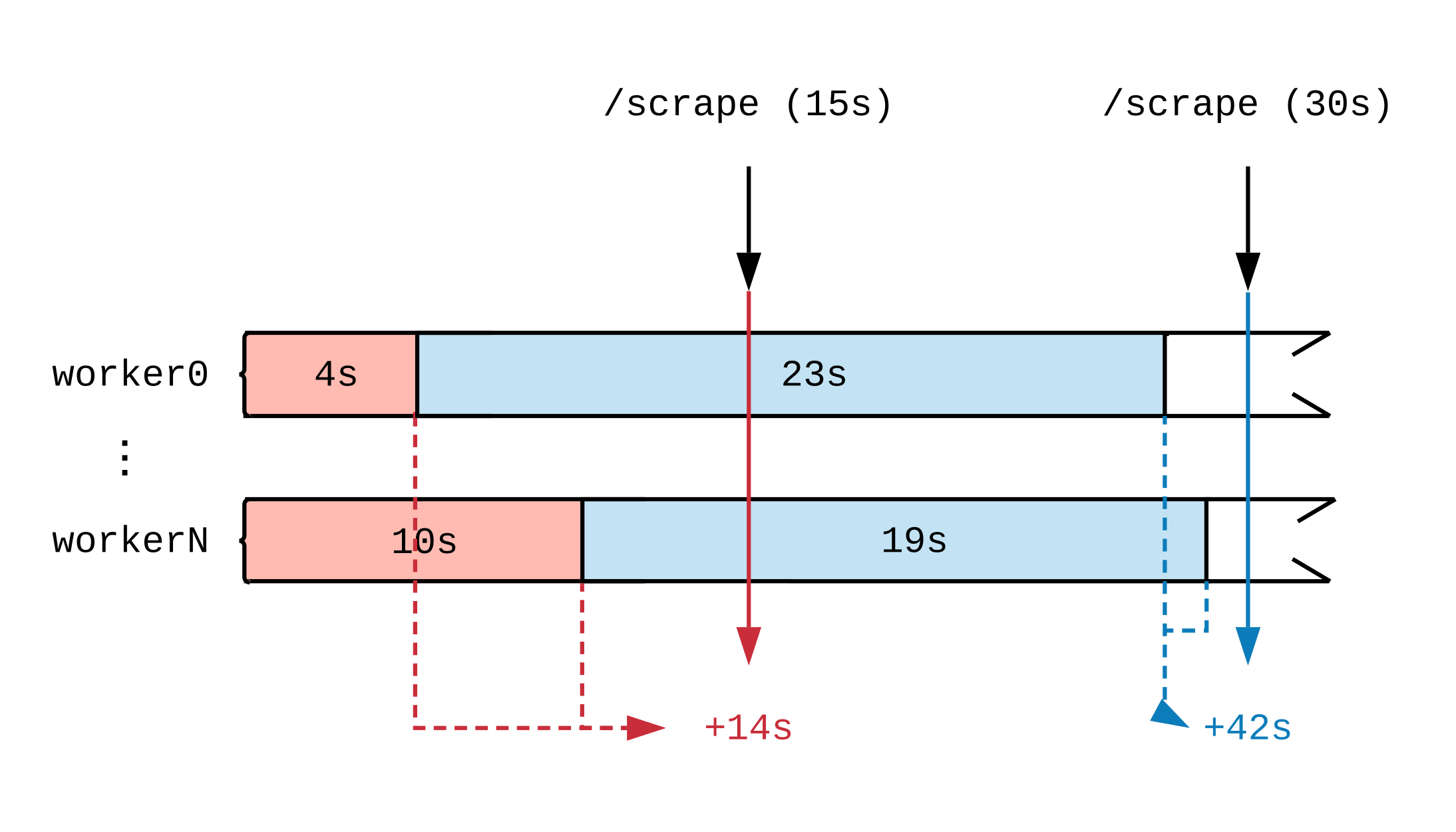
Вне зависимости от того, чем заняты обработчики при полной нагрузке, они в каждый 15-секундный интервал будут выполнять 30 секунд работы. Поскольку Prometheus не видит работу, пока она не выполнена, то судя по метрикам, в первый интервал времени было выполнено 14 секунд работы и 42 секунды — во второй. Если каждый обработчик примется за объемную задачу, то даже спустя несколько часов, до самого конца мы не увидим отчетов о том, что работа идет.
Чтобы продемонстрировать этот эффект, я провел эксперимент с десятью обработчиками, занятыми на задачах, протяженность которых разная и полунормально распределена между 0.1 секунды и чуть более высоким значением (см. рандомные задачи). Ниже — 3 графика, отображающих рабочую активность; протяженность во времени показана по нарастающей.
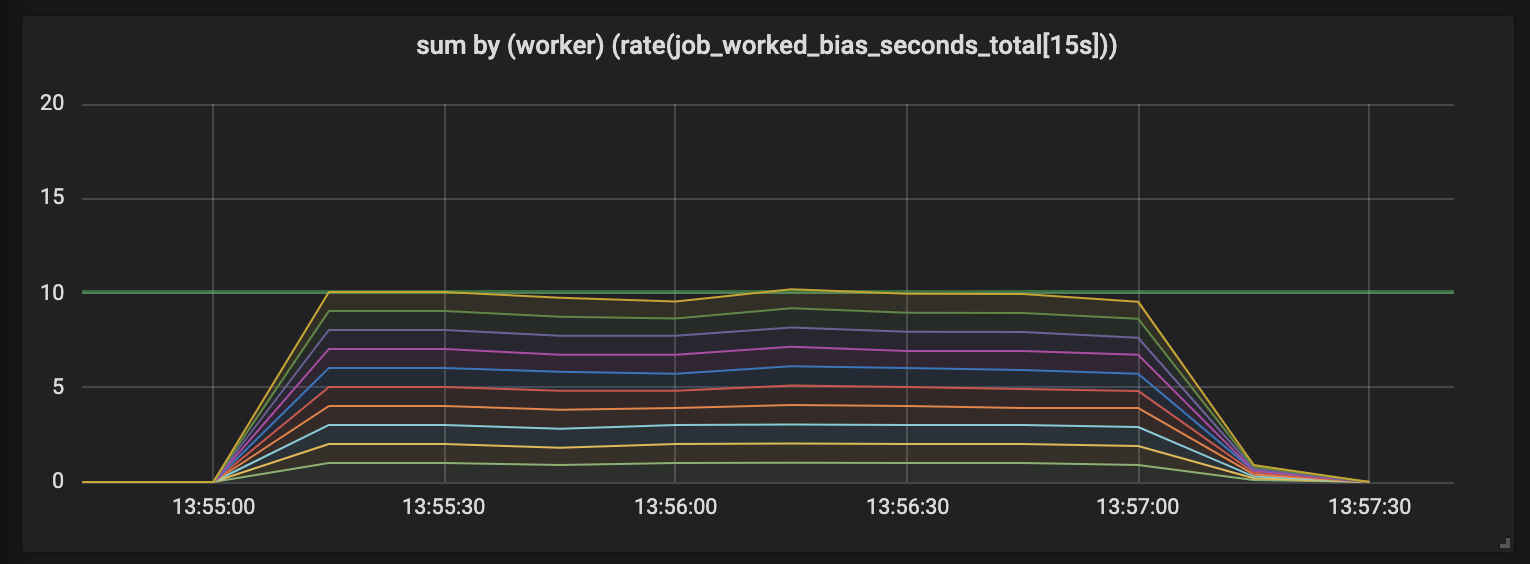
Задачи продолжительностью до 1 секунды.
Первый график показывает, что каждый обработчик отрабатывает примерно 1 секунду работы в каждую секунду времени — это видно по плоским линиям, а общий объем работ равен нашим возможностям (10 обработчиков выдают по секунде работы в секунду времени). Собственно, этого, вне зависимости от протяженности задачи, мы и ждем: именно столько и на коротких, и на длительных задачах обработчики при постоянной нагрузке и должны выдавать.
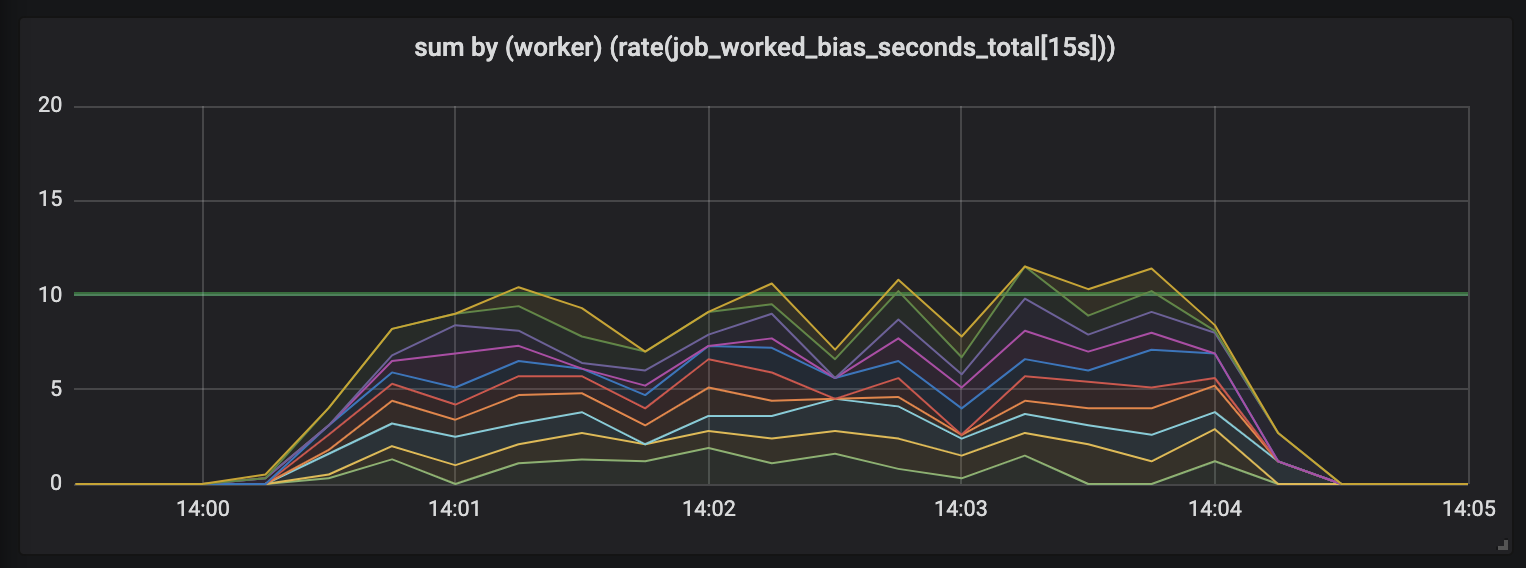
Задачи продолжительностью до 15 секунд.
Продолжительность задач растет, и в графике появляется беспорядок: у нас по-прежнему 10 обработчиков, все они полностью заняты, но общий объем работ скачет — то ниже, то выше границы полезной мощности (10 секунд).
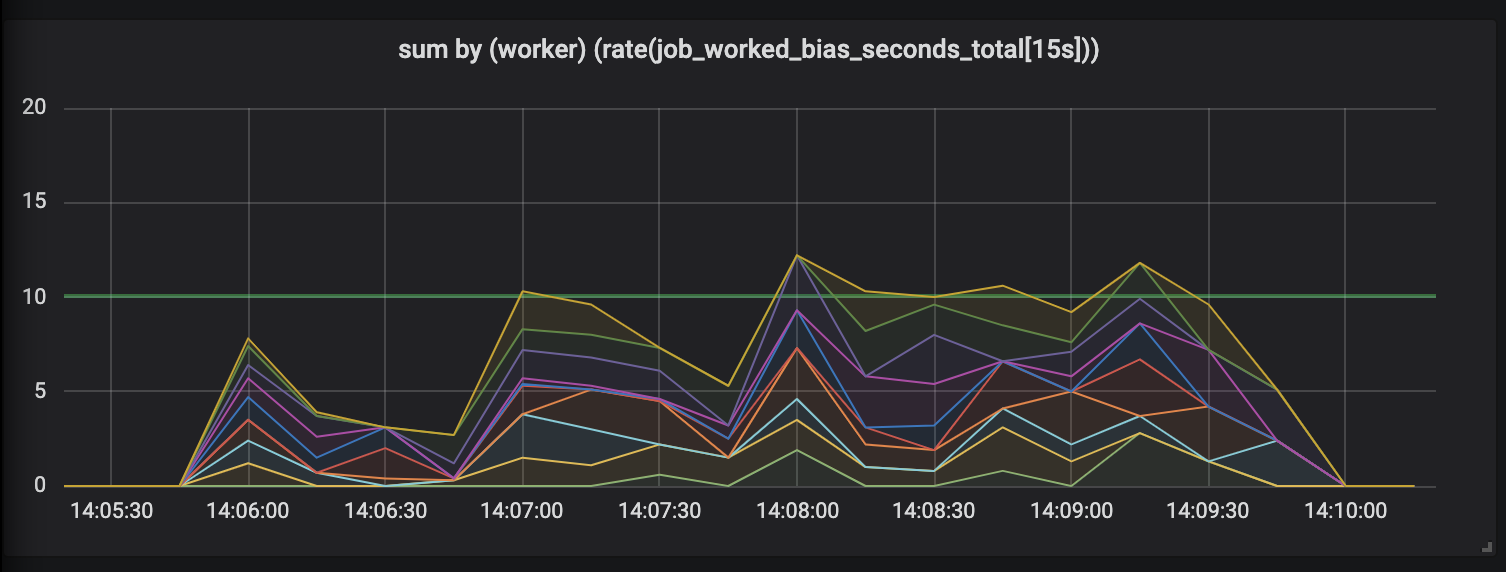
Задачи, продолжительностью до 30 секунд.
Оценка работ длительностью до 30 секунд просто смешна. Метрика с привязкой ко времени показывает нулевую активность для самых длительных задач и, только когда задачи завершены, рисует нам пики активности.
Восстановим доверие
Мало нам было этого, так есть еще одна, куда более коварная проблема с этими долговременными задачами, которые портят нам метрики. Всякий раз, как завершается долговременная задача — скажем, если Kubernetes выбрасывает из пула pod, или когда умирает узел, — то что случается с метриками? Стоит обновить их сразу по завершению задачи, как они показывают, что работу не делали вовсе.
Метрики не должны лгать. Ноутбук недоверчиво подвывает, вызывая экзистенциальный ужас, а инструменты наблюдения, искажающие картину мира, — это ловушка и в работе непригодны.
К счастью, дело поправимо. Искажение данных происходит потому, что Prometheus производит замеры независимо от того, когда обработчики обновляют метрики. Если попросить обработчики обновлять метрики тогда, когда Prometheus шлет запросы, то мы увидим, что Prometheus уже не чудит и показывает текущую активность.
Представляем… Tracer
Одно из решений проблемы искаженных метрик — это абстрактно спроектированный Tracer, он оценивает активность на длительных задачах, инкрементально обновляя связанные метрики Prometheus.
class Tracer
def trace(metric, labels, &block)
...
end
def collect(traces = @traces)
...
end
endTracer'ы обеспечивают метод трассировки, который берет метрики Prometheus и задачу, которые надо отслеживать. Команда trace выполнит заданный блок (безымянные функции Ruby) и гарантирует, что запросы к tracer.collect во время исполнения инкрементально обновят связанные метрики, сколько бы времени не прошло с последнего запроса к collect.
Нам надо подключить tracer к обработчикам, чтобы отслеживать продолжительность задачи и конечную точку, обслуживающую запросы Prometheus на метрики. Начинаем с обработчиков, инициализируем новый tracer и просим его отследить исполнение acquire_job.run.
class Worker
def initialize
@tracer = Tracer.new(self)
end
def work
@tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run }
end
# Tell the tracer to flush (incremental) trace progress to metrics
def collect
@tracer.collect
end
endНа данном этапе tracer будет только обновлять метрики по секундам, потраченным на выполненную задачу — как поступали мы в изначальной реализации метрик. Надо попросить tracer обновлять наши метрики перед тем, как мы исполним запрос от Prometheus. Сделать это можно, настроив ПО промежуточного слоя Rack.
# config.ru
# https://rack.github.io/
class WorkerCollector
def initialize(@app, workers: @workers); end
def call(env)
workers.each(&:collect)
@app.call(env) # call Prometheus::Exporter
end
end
# Rack middleware DSL
workers = start_workers # Array[Worker]
# Run the collector before serving metrics
use WorkerCollector, workers: workers
use Prometheus::Middleware::ExporterRack — это интерфейс для веб-серверов Ruby, позволяющий объединить несколько Rack-обработчиков в единую конечную точку. Приведенная выше команда config.ru определяет, что приложение Rack — всякий раз, как оно получает запрос, — первым делом шлет команду collect обработчикам, а уже потом велит Prometheus client отрисовать результаты сбора.
Что касается нашей диаграммы, то мы обновляем метрики всякий раз, когда завершается задача или когда мы получаем запрос на метрики. Задачи, на которые приходится несколько запросов, равным образом присылают данные на всех отрезках: как это показали задачи, длительность которых была разбита на 15-секундные интервалы.

Лучше ли это?
Использование tracer'а круглосуточно влияет на то, как регистрируется рабочая активность. В отличие от первоначальных измерений, которые показывали "пилу", когда количество пиков превышало число запущенных обработчиков и периодов глухой тишины, эксперимент с десятью обработчиками дает график, четко показывающий, что каждый обработчик вкладывается в обозреваемую работу равномерно.

Метрики, построенные на сравнении (слева) и контролируемые tracer'ом (справа), снятые с одного рабочего эксперимента.
В сравнении с откровенно неточным и хаотичным графиком первоначальных замеров, метрики, собранные tracer'ом, ровные и согласованные. Мы теперь не только точно привязываем работу к каждому запросу метрик, но еще и не беспокоимся из-за внезапной смерти какого-нибудь из обработчиков: Prometheus записывает метрики вплоть до исчезновения обработчика, оценивая всю его работу.
Можно ли это использовать?
Да! Интерфейс Tracer оказался полезен мне во многих проектах, так что это — отдельный Ruby gem, prometheus-client-tracer. Если вы в своих приложениях Ruby используете Prometheus client, то просто добавьте в свой Gemfile prometheus-client-tracer:
require "prometheus/client"
require "prometheus/client/tracer"
JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...)
Prometheus::Client.trace(JobWorkedSecondsTotal) do
sleep(long_time)
endЕсли вам это окажется полезным и если захотите, чтобы в Tracer появился официальный Prometheus Ruby client, оставьте отзыв в client_ruby#135.
Ну и напоследок, кое-какие мысли
Надеюсь, это поможет другим более осознанно собирать метрики задач, запускаемых на длительный срок, и вскрыть одну из распространенных проблем. Не заблуждайтесь, она связана не только с асинхронной обработкой: если ваши НТТР запросы замедляются, они тоже выиграют от использования tracer'а при оценке затраченного на обработку времени.
Как обычно, приветствуются любые отзывы и поправки: пишите в Twitter или откройте PR. Если хотите сделать вклад в tracer gem, исходный код лежит на prometheus-client-tracer-ruby.



