
Чем интенсивнее наш feature delivering, тем быстрее падает производительность. И, конечно, приходит время автоматизировать процесс слежения, чтобы просадка не дошла до прода или даже staging-окружения.
Про прод-мониторинг, оптимизацию и ручной анализ производительности легко узнать на web.dev. Но по автоматизации слежения за производительностью до того, как фичи покатятся в прод, информации не так уж много. Сегодня расскажу, как для профилирования собрать практически свой Lighthouse, чтобы проводить perfomance-тесты и успешно бороться с просадкой в работе команды фронтендеров.

Мы, как разработчики, начинаем что-то профилировать чаще всего несистемно — когда что-то совсем затормозит на проде или кто-то подсветит проблему. Мы берем чашечку кофе и открываем трейсинг. Потому что это первый инструмент, который приходит в голову. Может быть ещё вспомним про Lighthouse, но в любом случае мы пытаемся понять, что там на странице происходит.
В трейсинге мы видим много фреймов, еще больше запрашиваемых ресурсов, какие-то другие интересные штуки. И если мы смотрим на это раз в месяц, то всё это каждый раз новое — как с этим работать, пока непонятно.
Но если мы занимаемся этим регулярно, то постепенно у нас складывается «джентльменский набор»:
В первую очередь, это, конечно, вкладка Performance, которая показывает подробный анализ того, что у нас на странице происходит.
Потом добавляются bundle-анализаторы, чтобы посмотреть, что у нас содержится в ресурсах и из чего они состоят.
Еще мы можем добавить DevTools CPU Profile, чтобы понять, насколько быстро выполняется JS — и в подробностях ознакомиться с временем выполнения кода.
И напоследок — Lighthouse или Google PageSpeed Insight в качестве overview по метрикам.
Со временем это всё превращается в стандартный flow, и мы начинаем что-то оптимизировать — и добиваемся, скажем, ускорения по какой-то ключевой метрике на целых 30%. Но вдруг происходит деплой тридцати фич — каждый разработчик добавил по одному MPM-модулю весом в 500 килобайт. И наша метрика возвращается на исходную или даже ухудшается.

Решить эту ситуацию можно с помощью профилирования сразу после разработки. Но мало какой разработчик согласится заниматься профилированием сразу после написания кода: это занимает достаточно много времени, при этом сложно понять, что конкретно поменялось и что конкретно из правок повлияло на производительность.
Но можно автоматизировать этот процесс, чтобы не затормозился или не остановился feature-delivering. После отправки pull request’а можно сразу собрать всю нужную информацию для оптимизации, устранить причину ухудшения производительности, если она есть, а после этого — задеплоить уже качественный код.
Но что мы можем использовать для автоматизированного профилирования?
Lighthouse и Lighthouse-ci
Lighthouse — это хороший инструмент, с его помощью вы получите классные отчеты с информацией по всем ключевым метрикам, и даже вполне понятные советы по оптимизациям. Все его User-centric метрики из коробки всегда актуальные, потому что Google следит за этим. Его можно встроить в CI/CD — есть пакет, который основан на Puppeteer — и получать все нужные данные в JSON или даже в виде HTML-отчетов.
Но есть и существенные минусы. Во-первых, у него вечно разные результаты — даже если вы будете прогонять один замер огромное количество раз, будет довольно высокий разброс. А советы Lighthouse хоть и дает, но очень общие — что какой-то ресурс очень плох и его надо как-то вырезать. При этом вместо его имени вы видите хэш, и что в нем содержится — абсолютно непонятно.
Второй минус — его сложно масштабировать и добавлять в него новый функционал. Если вы захотите написать какой-то сценарий, чтобы проанализировать что-то более глубоко, встроив код на страницу при профилировании, то у вас это не получится. У него есть, конечно, система плагинов, которая позволяет вам анализировать трейсинги и вычленять оттуда дополнительные метрики, но на этом всё.
Ещё ему нужен Performance-бюджет — особенно если вы попытаетесь встроить его в CI. При этом он измеряет только загрузку страницы. Из коробки у него нет ретроспективы, то есть вы постоянно рассматриваете ситуацию в режиме настоящего времени, не представляя, какие показатели были раньше и что вообще на них повлияло. В Lighthouse-ci есть чуть более продвинутая тема по сравнению замеров различных ревизий между собой, но в Lighthouse ее нет совсем.
Даже если вы встроите Lighthouse в CI, всё равно придется запускать профайлер и webpack-bundle-analyzer, чтобы основательно разобраться в том, что влияет на производительность. То есть мы снова вернулись к ручному анализу:

Как мы можем это переоформить, чтобы вместо постоянного и довольно сложного flow у нас было время для более полезных вещей? Во-первых, стоит всё-таки отказаться от Lighthouse, потому что загрузка страницы — это не единственный показатель перфоманса, за которым стоит следить. Несмотря на то, что Google таргетит на него, у нас есть, например, SPA. А каждый второй сайт имеет какую-то динамику в своей основе — и за этим тоже нужно следить.
Как собрать свой Lighthouse
Вместо Lighthouse прекрасно работает Puppeteer — это Chrome, но без головы. На нем можно писать функциональные тесты, и там есть CDP — Chrome DevTools Protocol. Это программный интерфейс к DevTools — самая важная его часть, которая позволит нам сделать из него всё что угодно. Для нас будут полезными Tracing, Network, Emulation и Coverage:
Tracing даст нам записи тех тайм-лайнов, которые мы видим во вкладке Perfomance.
Network — это эмуляция сети для троттлинга, обработчиков запросов, и так далее.
Emulation — это эмуляция непосредственно в viewport девайса, который мы хотим замерить.
Coverage — это выполнение кода на странице, чтобы понять, какой код у нас на странице выполнялся, а какой — нет.
Профайлер из Chrome DevTools можно заменить на некий эвристический велосипед, а bundle analyzer — на простой JSON, который можно сортировать по определенным критериям и предоставлять разработчику. В результате получим triforce, который будет решать проблемы профилирования для разработчиков.
Покажу, как мы можем собрать наш Lighthouse.
Пишем профайлер
Что нам нужно для этого от Puppeteer? User-centric метрики из Lighthouse. Navigation timing, чтобы иметь представление о том, когда у нас какие ресурсы загрузились, на каком timestamp’е находилась страница и прочие детали. Данные о выполнении скриптов, чтобы, например, подсчитать Time to Interactive или просто понимать, что у нас на странице выполнялось. И данные о содержимом ресурсов, тех же чанков.
Для получения данных нужно достучаться до CDP через Puppeteer. Откроем страницу в браузере и поднимем CDP-сессию. И дальше мы сможем с ней общаться с помощью метода send, отправляя функции на выполнение и получая результат.
CDP-сессия
const browser = await puppeteer.launch();
const page = await browser.newPage();
const client = await page.target().createCDPSession();
await client.send('...', ...args);И попробуем сразу собрать трейсинги. Настраиваем окружение, которое нам позволит нормализовать сеть, сделать ее Fast 3G, затроттлить CPU и сделать окружение, которое будет троттлить всю страницу и показывать результаты для среднестатистического пользователя. Для записи трейсингов у Puppeteer есть встроенные методы, которые перенаправляют вызов метода в CDP. Перейдя на страницу, можно получить этот трейсинг в строковом формате, и запарсить его.
Собираем трейсинги
const puppeteer = require('puppeteer');
const getTracing = async (url) => {
// открываем браузер и страницу
const browser = await puppeteer.launch();
const page = await browser.newPage();
// поднимает CDP сессию
const client = await page.target().createCDPSession();
// настраиваем окружение
await client.send('Network.clearBrowserCache');
await client.send('Network.clearBrowserCookies');
await client.send('Network.emulateNetworkConditions', Fast3G);
await client.send('Emulation.setCPUThrottlingRate', { rate: 2 });
// начинаем записывать трейсинг
await page.tracing.start({});
// переходим по какому-то урлу
await page.goto(url);
// получаем записанный трейсинг загрузки страницы
const rawTracing = await page.tracing.stop();
return JSON.parse(rawTracing.toString());
};В результате получится масштабный JSON, своего рода Big Data для фронтенда. Его структура данных — это Trace Events. Она используется не только на фронтенде, а также в ядре Linux и Android для одного и того же — построения трейсингов, тайм-лайнов, где видно, что у вас происходило. Но из документации по этому формату есть только общие описания того, что в нем может быть. Они находятся в проекте Catapult-project на GitHub — у них, кстати, очень много тулзов, которые помогают измерять производительность.
В этом формате нам пригодятся 4 основных свойства. В первую очередь это args — полезная нагрузка, где содержатся какие-то произвольные объекты и структуры данных. Они коррелируются с именем события. Далее, это ph — фаза, которая описывает тип события в этом трейсинге. Из ключевых событий — Duration Events, Complete Events и Mark Events. Duration event связан с событиями begin и end, а Mark Events — это отметки на тайм-лайне с time stamps. Последние нам нужны, чтобы как-то скоординировать этот event и понять, когда он происходил.
В принципе этого всего достаточно, чтобы запарсить все события и собрать нужную нам информацию.
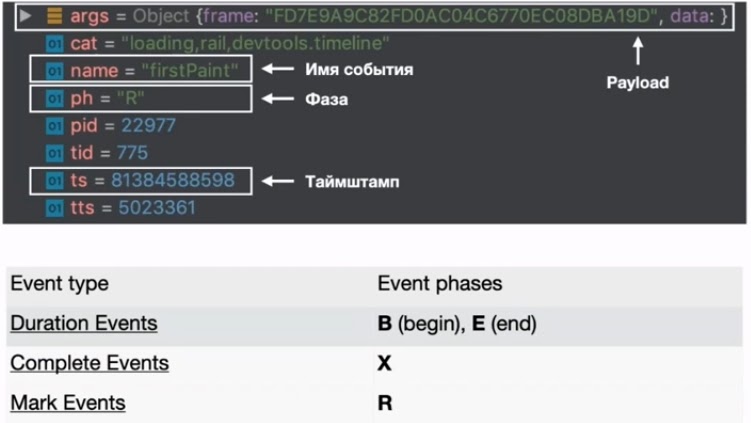
Категория (cat) будет нужна, чтобы отфильтровать событие по какому-то критерию. Например, вам нужны только user-timing. Или понять, какие вообще категории есть у вас в этом трейсинге.
На какие события мы будем смотреть?
Там их порядка 200, но актуальными для перфоманса можно назвать, например, Meaningful-отрисовки, Contentful Paint, Navigation timings и тому подобные штуки. Вот список тех, что использую я:

Нам также будет нужна точка отправки, т.е. с какого момента начала загружаться страница и соответственно — наш парсинг. Для этого найдем в массиве событие с name == responseStart и получим его timestamp.
Выполняем скрипты
Теперь фильтруем весь массив событий по какому-то имени, например, EvaluateScript, и получаем сразу все нужные нам значения: время выполнения скрипта, время начала его выполнения и адрес ресурса.
Фильтруем массив
const getScriptsEvaluating = (events) => events
.filter(({ name }) => name === 'EvaluateScript')
.map((event) => ({
duration: event.dur,
startTime: event.ts,
url: event.args.data && event.args.data.url
}));Дополнительно есть еще другие события, которые описывают отправку запросов, обработчики XML Http Requests, срабатывания таймеров, Request Animation Frame. В принципе, всё, что хотите, можно намайнить в трейсингах и предоставить разработчику. Все события можно найти здесь.
Нам также полезно понимать, какой объем от конкретного ресурса выполнялся. Сделать это можно с помощью Coverage. Достаточно вызвать у страницы метод записи коверейджа и после этого остановить запись, в тот момент, который вы посчитаете нужным. И можем подсчитать в абсолютном или относительном значении объем кода, который у нас выполнялся.
Coverage
const parseCoverage = (coverage) => (
coverage.map(({ ranges, url, text }) => {
const total = text.length;
const used = ranges.reduce((acc, { start, end }) => acc + (end - start), 0);
const unused = total - used;
return {
url,
total,
unused,
used
}
})
);В итоге у нас есть сырые данные по использованию кода и их можно прицепить к уже имеющейся информации по содержимому чанков. Это уже позволит оптимизировать ваш сайт и детектировать, где что прибавляется или убавляется.
Внутри данных больше всего нам интересен массив с промежутками кода, который выполнялся в конкретном файле. Из этой инфы можно получить уже относительные значения в сравнении с длиной файла. Можно даже использовать эти данные вкупе с сорс-мапами и получить точную информацию о том, что использовалось в автоматическом режиме.
Теперь, чтобы понять, когда загружались конкретные ресурсы, смотрим сеть.
Анализируем сеть
Для этого смотрим четыре связанных с помощью payload события — ResourceSendRequest, ResourceReceiveResponse, ResourceReceivedData и ResourceFinish — и возьмем от них timestamp’ы. Их можно организовать в мапу со всеми события, которые там есть и привязаны к конкретному запросу.
Мапа
Map<number, {
request: ResourceSendRequestEvent,
response: ResourceReceiveResponseEvent,
data: Array<ResourceReceivedDataEvent>,
finish: ResourceFinishEvent
}>Вместе с этим можно получить все имеющиеся на странице вызовы User TIming API: просто профильтровать массив по категории blink.user_timing. В Lighthouse они отображаются в отчете. Размещаем на странице User Timing, то есть выполняем performance.mark. И найдя в трейсинге событие с таким именем, получаем time stamp.
Получаем User TIming API
// на странице сайта
window.performance.mark('some_event');
// на стороне NodeJs
const someEventTs = traceEvents
.find(({ name }) => name === 'some_event').ts;После этого соберем описание каждого запроса, где будет всё, что нам нужно — размер ресурса, время начала его загрузки и конца загрузки, получения первого байта и так далее.
Собираем запросы
Array<{
size: number,
transfer: number,
timings: {
start: number,
response: number,
firstByte: number,
finish: number,
total: number
},
type: string,
url: string,
count: number,
internal: boolean,
extension: string
}>Оставшиеся события из трейсинга можно собрать в мапу с помощью find — это firstPaint и подобные штуки.
Собираем оставшиеся события
{
firstPaint: number,
firstContentfulPaint: number,
firstMeaningfulPaint: number,
largestContentfulPaint: number,
firstTextPaint: number,
firstImagePaint: number,
domInteractive: number,
domContentLoadedEventStart: number,
domContentLoadedEventEnd: number,
domComplete: number,
loadEventStart: number,
loadEventEnd: number
}Опции, которых не хватает в Lighthouse
SPA-сценарии
В первую очередь в Lighthouse не хватает функциональных тестов для замеров — например, переходов по роутингу или открытий поп-ап. Каждому разработчику стоит задуматься, насколько у него быстро открываются странички в режиме SPA и какие-то попапы. В Puppeteer это очень легко сделать, есть много методов, которые позволяют манипулировать страницей. Например, click и waitForSelector, которые позволяют на что-то кликнуть и дождаться появления селектора.
Замеряем
// сразу начинаем собирать трейсинг и коверейдж
await page.tracing.start({});
await page.coverage.startJSCoverage();
// осуществляем какое-то действие на странице
await page.click('.go-to-page-x');
// дожидаемся какого-то селектора, который скажет нам что загрузка завершилась
await page.waitForSelector('.page-x-content');
// останавливаем запись трейсинга и скора
const coverage = await page.coverage.stopJSCoverage();
const rawTracing = await page.tracing.stop();
const tracing = JSON.parse(rawTracing.toString());Помимо этого можно добавить обвязку из записи трейсинга и коверейджа и получить более подробную информацию об этих операциях: запись сети, выполнение скриптов, которое уже происходило в этой итерации, и коверейдж. А потом их дополнительно проанализировать на предмет, что у вас происходило в процессе SPA-шного перехода или загрузки попап.
Содержимое чанков
Оно нужно для понимания того, что у вас вообще там содержится и что стоит выпиливать. Когда мы используем бандлеры — webpack, rollup или parcel, они преобразуют исходники в обезличенные наборы чанков, которые скрываются под хэшами. Это не дает нам представления об их содержимом.
Мне же хотелось получить некую мапу, которая бы нам говорила, какой чанк соответствует какому набору модулей. Тут можно использовать webpack, который поставляет статы с описанием всего, что транспилировалось и бандлеризировалось. Мы получим JSON, который весит порядка 100 мегабайт, но его сложно анализировать.
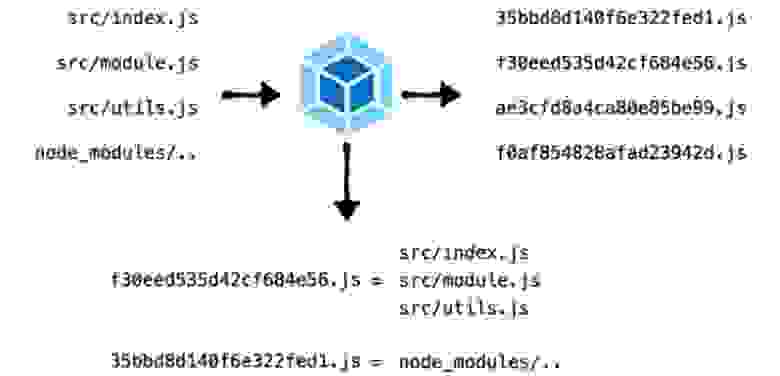
Поэтому мой коллега, Сергей Милюков, создал вариант лучше. Его плагин помогает собирать более лаконичные данные о том, что содержится в сгенерированных ресурсах. Там есть input и output. В input содержатся модули, которые участвуют в сборке, в output — все чанки на выходе. Это удобно читать в JSON даже глазами, а анализировать с помощью JS — тем более.
Что-то сверху — Script Injection
В Puppeteer, в отличие от Lighthouse, можно встраивать дополнительные скрипты на страницу, выполняя какой-то дополнительный код. Можно манипулировать страницей, обращаться к ней и что-то на ней выполнять перед загрузкой страницы, после чего грузятся уже ваши данные. Также можно добавлять скрипт-теги, например, npm-пакет сразу на страницу в процессе профилирования.
Script Injection
await page.evaluateOnNewDocument(() => window.foo = 'string');
await page.evaluate((arg) => console.log(arg), 'foo');
await page.addScriptTag({
type: 'module',
content: fs.readFileSync(require.resolve('./script.js'))
});Или можно дождаться получения Boolean результата. Этот метод возвращает promise, который разрезолвится, когда эта, переданная в качестве аргумента, функция вернет его.
await page.waitForFunction(() => Boolean(window.functionName));Это всё можно применить к очень крутой вещи — Element Timing API. Собрав их с помощью performance observer, можно выполнить этот код сразу перед загрузкой страницы. После этого переходим на страницу, которую хотим замерить, и получаем наши Element timing’s, выполнив просто evaluate. Мы получим еще данные для анализа.
Получаем Element timing’s
// добавляем скрипт перед началом загрузки страницы
await page.evaluateOnNewDocument(() => {
new PerformanceObserver((l) => {
if (!window.et) {
window.et = [];
}
window.et.push(l.getEntries());
}).observe({ type: 'element', buffered: true });
});
// переходим по урлу
await page.goto('https://example.com');
// достаём из области видимости страницы нужные данные
const elementTimings = await page.evaluate(() => window.et);Есть нюансы. Аргументы нужно передавать и в коллбэк, и методу evaluate или остальным. И весь код, который работает в коллбэках, будет выполнен в области видимости вашей страницы.
Итак, мы собрали свой Lighthouse со всеми особенностями, которые нам нужны. Мы уже можем это использовать для мониторинга производительности. Правда, это даст вам только наблюдение за циферками.
Чтобы получить профит, обнаружив ухудшение производительности, нужно применить всё это в Performance-тестах. Об этом я расскажу в следующий раз...
11-12 октября встречаемся в Москве на FrontendConf 2021. Программа составлена, расписание опубликовано. Все подробности на сайте.
Не так давно Глеб Михеев, глава ПК, рассказал про подготовку к конференции и доклады, которые его заинтересовали, пока ПК проводил отбор.



