
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Введение
Для обучения моделей ML необходимо множество размеченных данных. Хотя это не всегда обязательно, но иногда вам приходится самостоятельно размечать данные для обучения модели. Процесс аннотирования данных в проекте ML — это важная и затратная по времени задача. Для её правильного выполнения вам придётся принимать решения о способе разметки данных, например, о том, на какие классы вы хотите разбивать данные. Именно множество всех этих решений по правильному аннотированию данных мы будем называть планом разметки данных.
К сожалению, хотя это является важной частью успешного обучения ИИ-модели, создание эффективного плана разметки данных — это нечётко заданный и плохо задокументированный процесс. Цель этой статьи — дать вам понимание процесса создания плана разметки. Ради простоты мы рассмотрим только задачу многоклассовой классификации. Каждая задача машинного обучения имеет свою специфику плана разметки, поэтому мы представим в статье только общий подход. В ней мы просуммируем все вопросы, которые вам нужно будет задать себе при создании плана разметки.
Статья будет разбита на две части. Сначала мы рассмотрим процесс принятия решений о плане разметки на основании принципов машинного обучения. Затем мы сосредоточимся на процессе принятия решений на основе экспертизы в аннотировании.
План разметки: процесс принятия решений на основании принципов машинного обучения
Так как мы рассматриваем задачи многоклассовой классификации, необходимо определиться с классами, на которые вы хотите разбить свои данные. Этот вопрос может показаться тривиальным, но на самом деле это не так. Например, изначально вы решили разделить свои данные на десять разных классов. Десятый класс недостаточно представлен для обучения модели. Нужно ли обучать модель на меньшем количестве примеров? Действительно ли вам нужно правильно классифицировать данные из этого класса? И если нет, можно ли просто игнорировать этот класс? Именно такими вопросами нужно задаваться при разработке плана разметки.
1. Выбор количества классов: что нужно учесть
О чём говорит вам ваша задача?
Первым делом нужно рассмотреть информацию, которая дана в задаче. А конкретнее, содержит ли описание задачи, которую нужно решить, прямое указание количества классов? Например, в случае с набором данных MNIST мы определяем задачу чётко: правильно классифицировать каждую написанную от руки цифру. Цифр десять, поэтому мы разделяем данные на десять классов. Нужно обеспечить глубокое понимание задачи, чтобы выбрать количество классов.
Это первая подсказка о том, сколько классов вам нужно. Однако она служит хорошим показателем — возможно, вы не можете разделить данные согласно определению задачи. Например, бывают случаи, когда у вас недостаточно данных по конкретному классу для правильного обучения модели. И это подводит нас ко второму пункту.
Сколько данных у нас есть?
Если вы хотите, чтобы модель правильно различала каждый класс, ей необходимо предоставить достаточный объём данных. Если их недостаточно, даже при выборе правильного количества классов вы не сможете классифицировать часть данных. Это называется проблемой несбалансированных данных. Вместо применения техник обогащения данных (в этой статье мы не будем их рассматривать) можно подумать над тем, имеют ли они какие-то схожие черты, чтобы их можно было перегруппировать в недостаточно широко представленный класс. Затем можно отделить сгруппированные классы при помощи вложенного описания. Также можно по возможности задуматься о получении и разметке большего количества данных. Этому варианту во многих проектах разработки ИИ часто не уделяют внимания.
Ограничение трансферного обучения
Необходимо рассмотреть следующий конкретный случай: у вас уже есть обученная модель и вам нужно использовать её для решения задачи. Такая система называется трансферным обучением (transfer learning), она широко используется, но обладает некоторыми ограничениями. Трансферное обучение работает, только если исходная и целевая задачи обеих моделей достаточно схожи. Если это не так, трансферное обучение приводит к снижению производительности или точности новой модели. Из-за этого вам придётся адаптировать классы в соответствии с уже обученной моделью, чтобы не снижать её производительность. Это ограничение может подсказать вам, на какое количество классов стоит разбить данные.
Каковы потребности бизнеса?
Последний и во многих случаях самый важный аспект — потребности бизнеса. Снова рассмотрим пример: вы работаете над задачей для компании по классификации различных видов рыб. В данных есть множество разных видов рыб. Но на самом деле вашей компании нужно идеально отличать от других рыб тунца. Следовательно, вам нужно всего два класса: один для распознавания тунца, а во второй будут перегруппированы все остальные виды. Будьте внимательны к тому, что на самом деле требуется бизнесу. Не пытайтесь решать задачу, не описанную вашими ограничениями.
2. Выбор количества классов: эвристические подходы
При выборе количества классов любопытно бывает визуализировать данные на плоскости при помощи проецирования. Благодаря этому вы сможете увидеть, как статистические методы напрямую разделяют ваши данные. В данном случае техники снижения размерности могут оказаться очень полезными.
Первым мы порекомендуем алгоритм «стохастическое вложение соседей с t-распределением» (t-distributed Stochastic Neighbor Embedding, t-SNE). Он помогает визуализировать данные с высокой размерностью (например, изображения) создавая для каждого элемента данных точку на двухмерной или трёхмерной карте.
Хотя это и мощный алгоритм, на самом деле t-SNE устарел. Современным алгоритмом является Uniform Manifold Approximation and Projection (UMAP), выполняющий вычисления гораздо быстрее, чем t-SNE. Цель этих алгоритмов — использовать снижение размерности для визуализации данных, чтобы увидеть, как они разделяются оптимизированными алгоритмами. Важно помнить, что эти статистические методы могут служить только в качестве помощников в выборе, но не как решения.
После всех этих этапов вы уже сможете правильно выбрать нужное количество классов. Сразу после этого вы можете решить, какими будут классы для вашей задачи многоклассовой классификации.
Эти методики принятия решений используются до начала разметки данных. Но при возникновении потребности можно изменять своё решение уже в процессе разметки. Это зависит от проблем, с которыми вы сталкиваетесь при разметке данных. В следующем разделе мы рассмотрим этот аспект плана разметки.
II. План разметки: практика, основанная на экспертизе
Допустим, вы определились с тем, сколько классов и какие конкретно классы будут использоваться в вашей задаче многоклассовой классификации. Теперь вам нужно приступать к разметке данных. Во многих проектах разметки задействуется несколько разметчиков. Методы разметки на основе экспертизы продвигают идею использования множества разметчиков для аннотирования одних и тех же данных. Цель этого проста: пусть это долгий процесс, но мы стремимся повысить качество меток. И в самом деле, благодаря этому мы обеспечиваем соответствие меток и данных.
Чтобы лучше понять это, можно представить, что модели ML похожи на людей с узкой специализацией. Если между людьми возникают разногласия, то модель проявит себя не лучше них. А если она проявит себя лучше, то это сигнал: ваш план разметки (определение классов) недостаточно понятен или вы разбили данные на два класса, хотя этого не нужно было делать.
Для учёта того, что аннотировать одни и те же данные будет несколько людей, нужно ввести два понятия. Консенсус — для измерения степени согласия между различными аннотациями одних данных. Второй — это honeypot: создание эталонного набора данных для аннотаторов. С ним выполняется сравнение аннотаций, созданных разметчиками. Следовательно, мы сможем выполнять аудит качества работы аннотатора на протяжении процесса аннотирования.
Давайте рассмотрим на примерах, как работают консенсус и honeypot. Допустим, у нас есть два аннотатора, работающих над одним проектом распознавания изображений. Они аннотируют одно и то же изображение, после чего мы вычисляем консенсус. Мы измеряем согласованность между двумя разметчиками и получаем следующий результат:
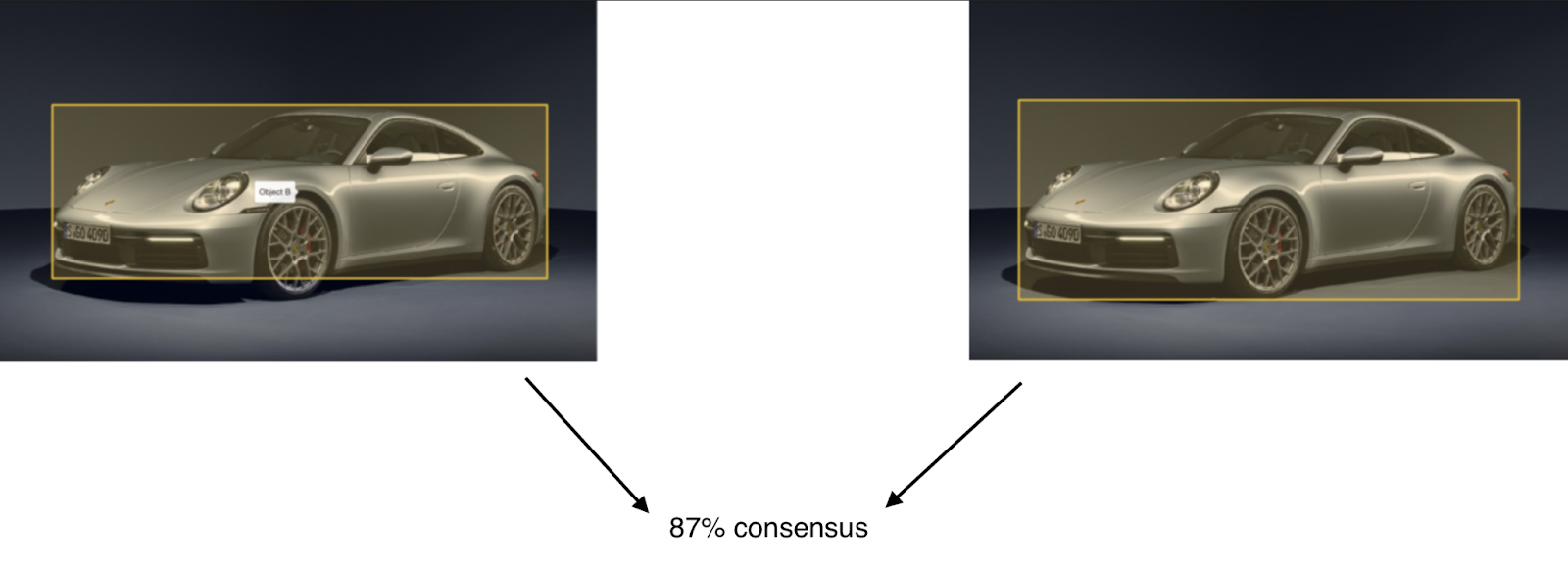
А для honeypot, позволяющего измерять точность аннотаций, мы видим следующий результат вычислений:

Экспертиза разметки позволяет нам проверить выбранный план разметки: мы пробуем аннотировать 10% данных при помощи консенсуса между разметчиками. В зависимости от результата можно продолжить реализацию плана или усовершенствовать его: если некоторые классы чрезмерно представлены в наборе данных, возможно, будет иметь смысл разделить их. Если же некоторые классы недостаточно хорошо представлены или если аннотаторы расходятся во мнениях по поводу некоторых классов (консенсус очень мал), нужно сгруппировать эти классы. Также можно рассмотреть консенсус по категориям, чтобы решить, какие классы группировать.
Заключение
План разметки — важнейшая часть многих проектов машинного обучения. В случае задачи многоклассовой классификации:
- Чётко определите количество необходимых классов. При этом нужно учесть количество данных, специфику имеющейся модели ИИ и потребности бизнеса.
- Определившись с количеством используемых классов, протестируйте их на небольшом объёме данных с разными разметчиками. Воспользуйтесь honeypot и консенсусом, чтобы модифицировать свой план, если он не соответствует требованиям.
В этой статье мы узнали о том, как создавать эффективный план разметки, взяв за пример задачу многоклассовой классификации. Каждая задача машинного обучения имеет собственную специфику проектирования плана разметки, однако часть знаний всё равно применима, например, этап проверки плана аннотирования.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
А вы используете honeypot (проверочные задания) для контроля качества разметки?
0%
Да
0
0%
Нет
0
100%
Не занимаюсь разметкой
2
Проголосовали 2 пользователя.
Воздержавшихся нет.




