
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Аналитику или исследователю данных приходится разрабатывать множество алгоритмов по обработке и анализу различных данных. Большинство алгоритмов разрабатываются для многоразового использования, а значит, код либо запускается разработчиком с определенной периодичностью, либо код передается другим пользователям для обработки своих данных. При этом алгоритмы имеют множество параметров и зависимостей, которые необходимо индивидуально настраивать под определенные данные.
Для того чтобы сделать процесс развертывания, использования и доработки алгоритма интуитивно понятным воспользуемся инструментом Kedro. Основная концепция kedro заключается в модульной структуре, где весь цикл работы с данными формируется из отдельных блоков в единый рабочий процесс. Проект на kedro имеет следующую структуру:

Где директория conf содержит конфигурационные файлы для подключения к внешним источникам, учетные данные, настройки ml-алгоритма и прочие параметры. data необходима для хранения данных на различных этапах обработки, docs предназначена для документации проекта, а logs для хранения журнала событий работы алгоритмов. Notebooks – предназначен для хранения jupyter-блокнотов и src, в которой размещается основной код для формирования pipeline проекта.
Для примера, возьмем хорошо известную задачу: предсказание выживших при кораблекрушении Титаника. Полный код, представленный в статье, можно найти в репозитории.
В первую очередь инициализируем git, создадим виртуальное окружение и установим kedro. Далее создадим файл config.yml со следующим содержимым:
output_dir: .
project_name: titanic
repo_name: titanic
python_package: titanicА затем выполним команду kedro new —config config.yml для формирования оболочки будущего проекта.
Чтобы использовать функционал kedro необходимо установить зависимости с помощью команды: kedro install. Следующий шаг – регистрация входных данных, которые будут анализироваться. Для этого поместим данные в titanic\data\01_raw. Все данные, которые будут загружаться kedro, необходимо указать в конфигурационном файле titanic\conf\base\catalog.yml следующим образом:
input_data:
type: pandas.CSVDataSet
filepath: data/01_raw/train.csvГде,
input_data – имя объекта данных, по которому будем обращаться в kedro;
type – модуль kedro, с помощью которого будем загружать данные;
filepath – расположение исходных данных.
Kedro поддерживает множество типов данных: csv, xlsx, json, parquet, sql-query и т.д. Следующий этап – настройка pipeline, который будет выполнять весь цикл работы алгоритма, от предобработки данных до оценки качества модели. Pipeline в Kedro выполняется с помощью nodes – блока модулей, которые выполняются последовательно, а полученные данные передаются от одного модуля к другому. Для начала напишем модуль предобработки данных. В директории src\titanic\pipelines создадим папку с именем data_processing, в которую поместим файл nodes.py со следующим содержимым:
import pandas as pd
def cat_to_num(arr):
return {i:c for c, i in enumerate(arr)}
def preprocess_dataset(df: pd.DataFrame) -> pd.DataFrame:
df = df.dropna(subset=["Embarked"])
d_sex = cat_to_num(df["Sex"].unique())
d_embarked = cat_to_num(df["Embarked"].unique())
df["Sex"] = df["Sex"].map(d_sex)
df["Embarked"]= df["Embarked"].map(d_embarked)
return dfДля примера преобразовали 2 столбца («Sex» и «Embarked») к числовому типу и удалили строки, с пропущенными значениями по столбцу Embarked. Далее для инициализации обработки данных в pipeline нам необходимо создать файл pipeline.py рядом с nodes.py в директории src\titanic\pipelines\data_processing со следующим содержимым:
from kedro.pipeline import Pipeline, node
from .nodes import preprocess_dataset
def create_pipeline(**kwargs):
return Pipeline(
[node(
func=preprocess_dataset,
inputs="input_data",
outputs="preprocessed_input_data",
name="preprocessing_input_data_node"
)
]
)Где,
func – метод для обработки входных данных, который реализован в nodes.py;
inputs – входные данные, имя указано в conf\base\catalog.yml;
outputs – задаем имя для обработанных данных;
name – задаем имя для модуля в pipeline. А также инициализируем pipeline в проектном пространстве, для этого создадим файл __init__.py в директории src\titanic\pipelines\data_processing\, в котором пропишем метод create_pipeline:
from .pipeline import create_pipelineЗаключительный момент создания отдельного модуля pipeline – регистрация в файле src\titanic\ pipeline_registry.py:
from typing import Dict
from kedro.pipeline import Pipeline
from titanic.pipelines import data_processing as dp
def register_pipelines() -> Dict[str, Pipeline]:
data_processing_pipeline = dp.create_pipeline()
return {"__default__": data_processing_pipeline,
"dp": data_processing_pipeline}Запустим проверку, чтобы убедиться в правильном составлении модуля обработки входных данных, для этого в терминале запустим команду, что запустит весь pipeline:
kedro runили запустим отдельный модуль, указав имя через аргумент –node:
kedro run --node=preprocessing_input_data_nodeВ результате должны получить подобный вывод:

Обработка выполнена, однако результат обработки хранится в памяти (MemoryDataSet) до завершения pipeline. Для того чтобы зафиксировать промежуточный результат необходимо дополнить файл titanic\conf\base\catalog.yml:
………………………….
preprocessed_input_data:
type: pandas.CSVDataSet
filepath: data/02_intermediate/preprocessed_input_data.csvТаким образом, результат метода preprocess_dataset будет сохранен в csv файл, в директорию data/02_intermediate/, к которому можно будет обратиться в любой момент. Далее приступим к DS составляющей pipeline. Для начала необходимо установить пакеты по работе с ml-алгоритмами, для этого отредактируем файл titanic\src\requirements.in:
………
scikit-learn==0.23.1И вызовем в терминале команду:
kedro install –build-reqsПо подобию с обработкой данных, создадим папку data_science в директории src\titanic\pipelines\ и добавим файл nodes.py со следующим содержимым:
import logging
from typing import Dict, Tuple
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
def get_score(name_metric: str, y_true: pd.Series, y_pred: (np.ndarray, np.array)) -> float:
## проверка на правильность названия метрики
name_metrics = [i for i in dir(metrics) if callable(getattr(metrics, i)) and not i.startswith("__")]
if name_metric not in name_metrics:
print("Invalid metric name")
return np.nan
score = getattr(metrics, name_metric)(y_true, y_pred)
return round(score, 2)
def split_data(df: pd.DataFrame, parameters: Dict) -> Tuple:
X = df[parameters["features"]]
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=parameters["test_size"],
random_state=parameters["random_state"])
return X_train, X_test, y_train, y_test
def train_model(X_train: pd.DataFrame, y_train: pd.Series, parameters: Dict) -> RandomForestClassifier:
rndm_forest = RandomForestClassifier(n_estimators=parameters["n_estimators"])
rndm_forest.fit(X_train, y_train)
return rndm_forest
def evaluate_model(rndm_forest: RandomForestClassifier, X_test: pd.DataFrame, y_test: pd.Series, parameters: Dict):
y_pred = rndm_forest.predict(X_test)
score = get_score(parameters["metric"], y_test, y_pred)
logger = logging.getLogger(__name__)
logger.info(f"Model has a value {score} for {parameters['metric']}")Метод split_data разбивает обработанные данные на обучающую и тестовую выборку, train_model – обучение модели, evaluate_model -проверяет качество модели, метод get_score возвращает значение по заданной метрике.
Как вы уже заметили, на вход методов передается аргумент parameters, который мы не импортируем и не извлекаем из других методов. Данный объект будет подтягиваться из конфигурационного файла titanic\conf\base\parameters.yml, из которого будем брать необходимые значения для настройки гиперпараметров модели, размера тестовой выборки и т.д. Метод get_score реализован для примера, чтобы показать возможность настройки любых параметров, которые будут полезны при настройке вашего проекта. Таким образом вам не нужно искать параметры в исходном коде, нужно лишь подправить файл parameters.yml и вызвать команду kedro run, для обучения модели с новыми параметрами. Внесем необходимые значения в файл parameters.yml:
test_size: 0.2
random_state: 17
n_estimators: 100
metric: "accuracy_score"
features:
- Pclass
- Sex
- SibSp
- Parch
- EmbarkedПараметр features (используем в методе split_data) необходим для отбора только тех признаков, которые будем использовать для обучения и предсказания, также можно указать и целевой признак, если данные берутся из различных источников. Далее повторяем операции сохранения данных, и инициализации pipeline. Для начала дополним файл titanic\conf\base\catalog.yml для сохранения обученной модели:
………….
classificator:
type: pickle.PickleDataSet
filepath: data/06_models/classificator.pickle
versioned: trueОтличием от предыдущих способов сохранения данных является аргумент versioned, если укажем значение true, модель будет сохраняться каждый раз при запуске pipeline. Далее создадим data_science модуль для pipeline, для этого поместим в директорию src\titanic\pipelines\data_science файл pipeline.py со следующим содержимым:
from kedro.pipeline import Pipeline, node
from .nodes import split_data, train_model, evaluate_model
def create_pipeline(**kwargs):
return Pipeline([
node(
func=split_data,
inputs=["preprocessed_input_data", "parameters"],
outputs=["X_train", "X_test", "y_train", "y_test"]
name="split_data_node"
),
node(
func=train_model,
inputs=["X_train", "y_train", "parameters"],
outputs="classificator",
name="train_model_node",
),
node(
func=evaluate_model,
inputs=["classificator", "X_test", "y_test", "parameters"],
outputs=None,
name="evaluate_model_node"
)
])Данный модуль состоит из 3-х функций, где использование входных данных зависит от выполнения предыдущих функций. Не забываем подавать на вход функций объект parameters, для доступа к параметрам, влияющих на обучающую способность модели.
Обратите внимание, каким образом функции обращаются к данным. В kedro указывается не физическое расположение данных, а используется имя объекта, которое хранится либо в памяти (MemoryDataSet — пока выполняется pipeline), либо ссылается на уже существующий объект, указанный в titanic\conf\base\catalog.yml. Также инициализируем data_science модуль в проектном пространстве, для этого создадим файл __init__.py в директории src\titanic\pipelines\data_science, в котором укажем следующую строку:
from .pipeline import create_pipelineТакже зарегистрируем data_science модуль в общий pipeline проекта, для этого редактируем файл \src\titanic\ pipeline_registry.py:
from typing import Dict
from kedro.pipeline import Pipeline
from titanic.pipelines import data_processing as dp
from titanic.pipelines import data_science as ds
def register_pipelines() -> Dict[str, Pipeline]:
data_processing_pipeline = dp.create_pipeline()
data_science_pipeline = ds.create_pipeline()
return {"__default__": data_processing_pipeline + data_science_pipeline,
"dp": data_processing_pipeline,
"ds": data_science_pipeline
}В данном случае знак «+» для двух pipelines используется для того, чтобы kedro понимал очередность выполнения модулей. Т.к. предобработку данных уже запускали раннее, можно запустить только ds часть с помощью аргумента –pipeline:
kedro run –pipeline=dsВ результате должны получить подобный вывод:
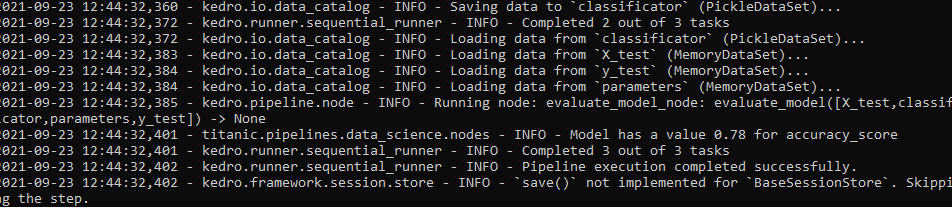
В консоли logger выводит сообщение о том, что точность модели на валидационных данных составляет 0.78 для метрики accuracy_score. По завершению pipeline, обученная модель появится в директории data/06_models/.
На этом закончим формирование pipeline. Создание модуля предсказания на тестовых данных, с лучшей моделью оставим для домашнего задания)))
Код в статье может показаться немного запутанным. Однако у kedro подробная и последовательная документация, которая ответит на любые вопросы по формированию проекта.
Подведем итоги:
Kedro – очень удобен для командной разработки, т.к. имеет определенную структуру, и не требуется поиск определенного параметра для настройки алгоритма в папке «temp» с названием файла «my_functions.py».
Для того чтобы прогнать новые данные, требуется лишь поместить данные в директорию data\01_raw и запустить команду в терминале — kedro run. Но главное – это наличие множества интересных плагинов для kedro, которые упрощают работу, как разработчика, так и исследователя данных. В следующей части статьи уделим внимание возможностям kedro, для визуального представления работы Вашего проекта.



 файла в 1С-Битрикс")
