
Привет, Хабр!
Среди рассматриваемых нами фреймворков для сложной обработки данных на Java есть и Apache Flink. Хотим предложить вам перевод неплохой статьи из блога Analytics Vidhya на портале Medium, чтобы оценить читательский интерес. Не стесняйтесь участвовать в голосовании!

В этой статье мы разберем «снизу вверх», как организовать потоковую обработку при помощи Flink; в облачных сервисах и на других платформах предоставляются решения для потоковой обработки (в некоторых из них «под капотом» интегрирован Flink). Если вы хотели разобраться в этой теме с азов, то нашли как раз то, что искали.
Наше монолитное решение не справлялось с возрастающими объемами входящих данных; следовательно, его требовалось развивать. Настало время перейти к новому поколению в эволюции нашего продукта. Было решено воспользоваться потоковой обработкой. Это новая парадигма поглощения данных, более выигрышная по сравнению с традиционной пакетной обработкой данных.
Apache Flink – это фреймворк для масштабируемой распределенной обработки потоков, предназначенный для операций над непрерывными потоками данных. В рамках этого фреймворка используются такие концепции как источники, преобразования потоков, параллельная обработка, планирование, присваивание ресурсов. Поддерживаются разнообразные места назначения данных. В частности, Apache Flink может подключаться к HDFS, Kafka, Amazon Kinesis, RabbitMQ и Cassandra.
Flink известен своей высокой пропускной способностью и малыми задержками, поддерживает согласованную строго однократную обработку (все данные обрабатываются по одному разу, без дублирования), а также высокую доступность. Как и любой другой успешный опенсорсный продукт, Flink обладает обширным сообществом, в котором культивируются и расширяются возможности этого фреймворка.
Flink может обрабатывать потоки данных (размер потока является неопределенным) или множества данных (размер множества данных является определенным). В этой статье рассматривается именно обработка потоков (обращение с объектами
Потоковая обработка и присущие ей вызовы
В настоящее время, при повсеместной распространенности устройств «Интернета Вещей» и прочих сенсоров, данные непрерывно поступают из множества источников. Такой нескончаемый поток данных требует адаптировать к новым условиям традиционные пакетные вычисления.
Обладая такими уникальными характеристиками, задачи обработки и запрашивания данных нетривиальны при выполнении. Результаты могут стремительно меняться, и получить однозначные выводы почти невозможно; временами вычисления могут блокироваться при попытке получить валидные результаты. Более того, результаты не воспроизводимы, поскольку и в процессе вычислений данные продолжают меняться. Наконец, еще одним фактором, сказывающимся на точности результатов, являются задержки.
Apache Flink позволяет справиться с такими проблемами при обработке, поскольку ориентируется на метки времени, которыми входящие данные снабжаются еще в источнике. Во Flink есть механизм аккумулирования событий на основе временных меток, проставленных на них -–и только после аккумулирования система переходит к выполнению обработки. В таком случае удается обойтись без применения микропакетов, а также в данном случае повышается точность результатов.
Flink реализует согласованную строго однократную обработку, что гарантирует точность вычислений, а разработчику не требуется для этого ничего специально программировать.
Как правило, Flink поглощает потоки данных из разных источников. Базовый объект —
Объект
Одна из основных целей Flink, наряду с преобразованием данных, заключается в управлении потоками и направлении их в те или иные места назначения. Эти места называются «стоками». В Flink есть встроенные стоки (текст, CSV, сокет), а также представляемые «из коробки» механизмы для подключения к иным системам, например, Apache Kafka.
При обработке потоков данных исключительно важен фактор времени. Существует три способа определить временную метку:
Подробнее о временных метках и о том, как они влияют на потоковую обработку, можно почитать по следующей ссылке.
Поток по определению бесконечен; следовательно, механизм обработки связан с определением фрагментов (например, периодов-окон). Таким образом поток разбивается на партии, удобные для агрегации и анализа. Определение окна – это операция над объектом DataStream или каким-то другим, который его наследует.
Есть несколько видов окон, зависящих от времени:
Кувыркающееся окно (конфигурация по умолчанию):
Поток делится на окна эквивалентного размера, которые не перекрываются друг с другом. Пока поток течет, Flink непрерывно производит вычисления над данными на основе такой фиксированной во времени раскадровки.

Кувыркающееся окно
Реализация в коде:
Скользящее окно
Такие окна могут перекрываться друг с другом, а свойства скользящего окна определяются размером данного окна и отступом (когда начинать следующее окно). В таком случае в конкретный момент времени могут обрабатываться события, относящиеся более чем к одному окну.

Скользящее окно
А вот как оно выглядит в коде:
Сеансовое окно
Включает все события, ограниченные рамками одного сеанса. Сеанс завершается при отсутствии активности, или если по истечении определенного временного периода не зафиксировано никаких событий. Данный период может быть фиксированным или динамическим, в зависимости от обрабатываемых событий. Теоретически, если промежуток между сеансами меньше размера окна, то сеанс может никогда не закончиться.
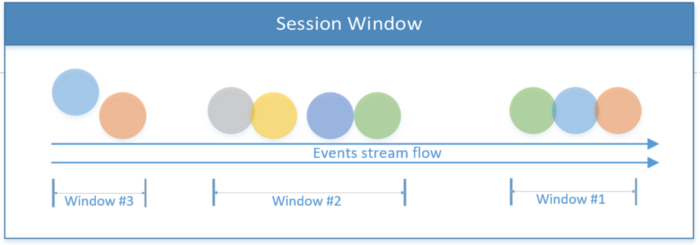
Сеансовое окно
В первом фрагменте кода ниже показан сеанс с фиксированной временной величиной (2 секунды). Второй пример реализует динамическое сеансовое окно, на основе событий потока.
Глобальное окно
Вся система трактуется как единственное окно.

Глобальное окно
Flink также позволяет реализовывать собственные окна, логику которых определяет пользователь.
Кроме окон, зависящих от времени, есть и другие, например, Окно счета, где устанавливается предельное количество входящих событий; по достижении порога X, Flink обрабатывает X событий.

Окно счета для трех событий
После теоретического введения давайте подробнее обсудим, что представляет собой поток данных с практической точки зрения. Подробнее об Apache Flink и потоковых процессах рассказано на официальном сайте.
В качестве резюме теоретической части на следующей блок-схеме показаны основные потоки данных, реализованные в сниппетах кода из этой статьи. Поток, изображенный ниже, начинается из источника (файлы записываются в каталог) и продолжается при обработке событий, превращаемых в объекты.
Реализация, изображенная ниже, состоит из двух путей обработки. Тот, что показан в верхней части разделяет один поток на два боковых потока, а затем объединяет их, получая поток третьего типа. Сценарий, изображенный в нижней части схемы, описывает обработку потока, после которой результаты работы передаются в сток.

Далее попытаемся пощупать руками практическую реализацию вышеизложенной теории; весь исходный код, рассматриваемый далее, выложен на GitHub.
Усвоить концепции Flink будет проще, если начать с простейшего приложения. В этом приложении продьюсер записывает файлы в каталог, таким образом имитируется поток информации. Flink считывает файлы из этого каталога и записывает обобщенную информацию по ним в каталог назначения; это и есть сток.
Далее давайте внимательно посмотрим, что происходит при обработке:
Преобразование сырых данных в объект:
В приведенном ниже фрагменте кода потоковый объект (
Создание точки назначения для потока (реализация стока данных):
Образец кода, описывающего создание стока данных.
В данном примере демонстрируется, как разделить основной поток, используя боковые потоки вывода. Flink обеспечивает создание множества боковых потоков из главного
Итак, используя боковой поток вывода, можно убить двух зайцев одним ударом: расщепить поток и преобразовать тип данных потока во множество типов данных (они могут быть уникальны для каждого бокового потока вывода).
В приведенном ниже фрагменте кода вызывается
Функция
Обратите внимание: определение бокового потока вывода основано на уникальном теге вывода (объект
Пример кода, демонстрирующий, как разделить поток
Последняя операция, которая будет рассмотрена в этой статье – объединение потоков. Идея заключается в том, чтобы скомбинировать два разных потока, форматы данных в которых могут отличаться, из которых собрать один поток с унифицированной структурой данных. В отличие от операции объединения из SQL, где слияние данных происходит по горизонтали, объединение потоков осуществляется по вертикали, поскольку поток событий продолжается и никак не ограничен во времени.
Объединение потоков выполняется путем вызова метода connect, после чего для каждого элемента в каждом отдельном потоке определяется операция отображения. В результате получается объединенный поток.
Листинг, демонстрирующий получение объединенного потока
Итак, резюмируем: демо-проект загружен на GitHub. Там описано, как его собрать и скомпилировать. Это хорошая отправная точка, чтобы поупражняться с Flink.
В этой статье описаны основные операции, позволяющие создать рабочее приложение для обработки потоков на основе Flink. Цель приложения – дать общее представление о важнейших вызовах, присущих потоковой обработке, и заложить базис для последующего создания полнофункционального приложения Flink.
Поскольку у потоковой обработки множество аспектов, и она сопряжена с разными сложностями, многие вопросы в этой статье остались не раскрыты; в частности, выполнение Flink и управление задачами, использование водяных знаков при установке времени для потоковых событий, подсадка состояния в события потока, выполнение итераций потока, выполнение SQL-подобных запросов к потокам и многое другое.
Надеемся, этой статьи было достаточно, чтобы вам захотелось попробовать Flink.
Среди рассматриваемых нами фреймворков для сложной обработки данных на Java есть и Apache Flink. Хотим предложить вам перевод неплохой статьи из блога Analytics Vidhya на портале Medium, чтобы оценить читательский интерес. Не стесняйтесь участвовать в голосовании!
В этой статье мы разберем «снизу вверх», как организовать потоковую обработку при помощи Flink; в облачных сервисах и на других платформах предоставляются решения для потоковой обработки (в некоторых из них «под капотом» интегрирован Flink). Если вы хотели разобраться в этой теме с азов, то нашли как раз то, что искали.
Наше монолитное решение не справлялось с возрастающими объемами входящих данных; следовательно, его требовалось развивать. Настало время перейти к новому поколению в эволюции нашего продукта. Было решено воспользоваться потоковой обработкой. Это новая парадигма поглощения данных, более выигрышная по сравнению с традиционной пакетной обработкой данных.
Apache Flink: краткая характеристика
Apache Flink – это фреймворк для масштабируемой распределенной обработки потоков, предназначенный для операций над непрерывными потоками данных. В рамках этого фреймворка используются такие концепции как источники, преобразования потоков, параллельная обработка, планирование, присваивание ресурсов. Поддерживаются разнообразные места назначения данных. В частности, Apache Flink может подключаться к HDFS, Kafka, Amazon Kinesis, RabbitMQ и Cassandra.
Flink известен своей высокой пропускной способностью и малыми задержками, поддерживает согласованную строго однократную обработку (все данные обрабатываются по одному разу, без дублирования), а также высокую доступность. Как и любой другой успешный опенсорсный продукт, Flink обладает обширным сообществом, в котором культивируются и расширяются возможности этого фреймворка.
Flink может обрабатывать потоки данных (размер потока является неопределенным) или множества данных (размер множества данных является определенным). В этой статье рассматривается именно обработка потоков (обращение с объектами
DataStream).Потоковая обработка и присущие ей вызовы
В настоящее время, при повсеместной распространенности устройств «Интернета Вещей» и прочих сенсоров, данные непрерывно поступают из множества источников. Такой нескончаемый поток данных требует адаптировать к новым условиям традиционные пакетные вычисления.
- Потоковые данные неограниченные; у них нет начала и конца.
- Новые данные поступают в непредсказуемом режиме, с нерегулярными интервалами.
- Данные могут поступать неупорядоченно, с различными временными метками.
Обладая такими уникальными характеристиками, задачи обработки и запрашивания данных нетривиальны при выполнении. Результаты могут стремительно меняться, и получить однозначные выводы почти невозможно; временами вычисления могут блокироваться при попытке получить валидные результаты. Более того, результаты не воспроизводимы, поскольку и в процессе вычислений данные продолжают меняться. Наконец, еще одним фактором, сказывающимся на точности результатов, являются задержки.
Apache Flink позволяет справиться с такими проблемами при обработке, поскольку ориентируется на метки времени, которыми входящие данные снабжаются еще в источнике. Во Flink есть механизм аккумулирования событий на основе временных меток, проставленных на них -–и только после аккумулирования система переходит к выполнению обработки. В таком случае удается обойтись без применения микропакетов, а также в данном случае повышается точность результатов.
Flink реализует согласованную строго однократную обработку, что гарантирует точность вычислений, а разработчику не требуется для этого ничего специально программировать.
Из чего состоят пакеты Flink
Как правило, Flink поглощает потоки данных из разных источников. Базовый объект —
DataStream<T>, представляющий собой поток однотипных элементов. Тип элемента в таком потоке определяется во время компиляции путем установки обобщенного типа T (подробнее об этом можно почитать здесь).Объект
DataStream содержит много полезных методов для преобразования, разделения и фильтрации данных. Для начала будет полезно иметь представление о том, что делают map, reduce и filter; это основные преобразующие методы:Map: получает объектTи в результате возвращает объект типаR;MapFunctionстрого однократно применяется с каждым элементом объектаDataStream.Reduce: получает два последовательных значения и возвращает один объект, скомбинировав их в объект того же типа; этот метод прогоняется по всем значениям в группе, пока из них не останется всего одно.Filter: получает объектTи возвращает поток объектовT; этот метод прогоняется по всем элементамDataStream, но возвращает только те, для которых функция возвращаетtrue.
Сток данных
Одна из основных целей Flink, наряду с преобразованием данных, заключается в управлении потоками и направлении их в те или иные места назначения. Эти места называются «стоками». В Flink есть встроенные стоки (текст, CSV, сокет), а также представляемые «из коробки» механизмы для подключения к иным системам, например, Apache Kafka.
Метки событий Flink Event
При обработке потоков данных исключительно важен фактор времени. Существует три способа определить временную метку:
- Время обработки (опция по умолчанию): это системное время машины, выполняющей операцию обработки потоков; следовательно, это самое простое определение времени. Оно не требует какой-либо координации между потоками и машинами. Поскольку данная концепция основана на машинном времени, она обеспечивает наилучшую производительность и минимальные задержки.
Недостаток, возникающий при использовании времени обработки существенен в распределенных и асинхронных окружениях, поскольку это не детерминистический метод. Метки времени, которыми сопровождаются события потока, могут рассинхронизироваться, если между ходом машинных часов есть разница; сетевая задержка также может привести к запаздыванию во времени, когда событие ушло с одной машины и прибыло на другую. - Время события: это момент времени, в который каждое отдельное событие будет получено на порождающем его источнике, прежде, чем перейдет в Flink. Время события встраивается в само событие и может быть извлечено, так, чтобы Flink мог правильно его обработать.
Поскольку не сам Flink устанавливает метку времени, должен быть механизм, который просигнализирует, должно быть обработано это событие или нет; данный механизм называется «водяной знак» (watermark). Тема водяных знаков выходит за рамки данной статьи; подробнее об этом можно почитать в документации по Flink. - Время поглощения: это момент времени, в который событие входит во Flink; присваивается, когда событие находится в источнике и, следовательно, данный показатель считается более стабильным, чем время обработки, присваиваемое, когда процесс начинает работу.
Время поглощения не подходит для обработки событий, приходящих вне очереди, либо опоздавших данных, поскольку метка времени ставится, когда поглощение начинается; этим оно отличается от времени события, в котором предусмотрена возможность выявлять отложенные события и обрабатывать их, опираясь на механизм водяных знаков.
// Установка атрибута Ingestion Time для StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);Подробнее о временных метках и о том, как они влияют на потоковую обработку, можно почитать по следующей ссылке.
Разбивка на окна
Поток по определению бесконечен; следовательно, механизм обработки связан с определением фрагментов (например, периодов-окон). Таким образом поток разбивается на партии, удобные для агрегации и анализа. Определение окна – это операция над объектом DataStream или каким-то другим, который его наследует.
Есть несколько видов окон, зависящих от времени:
Кувыркающееся окно (конфигурация по умолчанию):
Поток делится на окна эквивалентного размера, которые не перекрываются друг с другом. Пока поток течет, Flink непрерывно производит вычисления над данными на основе такой фиксированной во времени раскадровки.
Кувыркающееся окно
Реализация в коде:
// будет использоваться с потоком, не снабженным ключами
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// Кувыркающееся окно для потока, снабженного ключами
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)Скользящее окно
Такие окна могут перекрываться друг с другом, а свойства скользящего окна определяются размером данного окна и отступом (когда начинать следующее окно). В таком случае в конкретный момент времени могут обрабатываться события, относящиеся более чем к одному окну.
Скользящее окно
А вот как оно выглядит в коде:
// скользящее окно длиной 1 минуту и с интервалом срабатывания 30 секунд
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))Сеансовое окно
Включает все события, ограниченные рамками одного сеанса. Сеанс завершается при отсутствии активности, или если по истечении определенного временного периода не зафиксировано никаких событий. Данный период может быть фиксированным или динамическим, в зависимости от обрабатываемых событий. Теоретически, если промежуток между сеансами меньше размера окна, то сеанс может никогда не закончиться.
Сеансовое окно
В первом фрагменте кода ниже показан сеанс с фиксированной временной величиной (2 секунды). Второй пример реализует динамическое сеансовое окно, на основе событий потока.
// Определение фиксированного сеансового окна длительностью 2 секунды
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// Определение динамического сеансового окна, которое может быть задано элементами потока
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// возвращается промежуток между сеансами, который может зависеть от событий потока
}))Глобальное окно
Вся система трактуется как единственное окно.
Глобальное окно
Flink также позволяет реализовывать собственные окна, логику которых определяет пользователь.
Кроме окон, зависящих от времени, есть и другие, например, Окно счета, где устанавливается предельное количество входящих событий; по достижении порога X, Flink обрабатывает X событий.
Окно счета для трех событий
После теоретического введения давайте подробнее обсудим, что представляет собой поток данных с практической точки зрения. Подробнее об Apache Flink и потоковых процессах рассказано на официальном сайте.
Описание потока
В качестве резюме теоретической части на следующей блок-схеме показаны основные потоки данных, реализованные в сниппетах кода из этой статьи. Поток, изображенный ниже, начинается из источника (файлы записываются в каталог) и продолжается при обработке событий, превращаемых в объекты.
Реализация, изображенная ниже, состоит из двух путей обработки. Тот, что показан в верхней части разделяет один поток на два боковых потока, а затем объединяет их, получая поток третьего типа. Сценарий, изображенный в нижней части схемы, описывает обработку потока, после которой результаты работы передаются в сток.
Далее попытаемся пощупать руками практическую реализацию вышеизложенной теории; весь исходный код, рассматриваемый далее, выложен на GitHub.
Базовая обработка потоков (пример #1)
Усвоить концепции Flink будет проще, если начать с простейшего приложения. В этом приложении продьюсер записывает файлы в каталог, таким образом имитируется поток информации. Flink считывает файлы из этого каталога и записывает обобщенную информацию по ним в каталог назначения; это и есть сток.
Далее давайте внимательно посмотрим, что происходит при обработке:
Преобразование сырых данных в объект:
// Каждая запись преобразуется в объект InputData; каждая новая строка считается новой записью
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});В приведенном ниже фрагменте кода потоковый объект (
InputData) преобразуется в кортеж строки и целого числа. Он извлекает лишь определенные поля из потока объектов, группируя их по одному полю квантами по две секунды. // Каждая запись преобразуется в кортеж с именем и счетом
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // возвращает KeyedStream<T, Tuple> на основе первого элемента (поля 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // НЕ ИСПОЛЬЗОВАТЬ timeWindowAll с потоком на основе ключей
.timeWindow(Time.seconds(2)) // вернуть WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));Создание точки назначения для потока (реализация стока данных):
// Определить временное окно и подсчитать количество записей
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// для каждого элемента вернуть кортеж из временной метки и целого числа (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) // кувыркающееся окно
.reduce((x,y) -> // суммируем числа, и так до достижения единого результата
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
// Задаем в качестве стока для потокового файла каталог вывода
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// Добавляем поток стока к DataStream; при таком условии inputCountSummary будет вписан в путь countSink
inputCountSummary.addSink(countSink);
Образец кода, описывающего создание стока данных.
Расщепление потоков (пример #2)
В данном примере демонстрируется, как разделить основной поток, используя боковые потоки вывода. Flink обеспечивает создание множества боковых потоков из главного
DataStream. Тип данных, располагающихся с каждой стороны потока, может отличаться от типа данных основного потока, равно как и от типа данных каждого из боковых потоков.Итак, используя боковой поток вывода, можно убить двух зайцев одним ударом: расщепить поток и преобразовать тип данных потока во множество типов данных (они могут быть уникальны для каждого бокового потока вывода).
В приведенном ниже фрагменте кода вызывается
ProcessFunction, разделяющий поток на два боковых, в зависимости от свойства ввода. Для получения того же результата нам пришлось бы неоднократно использовать функцию filter.Функция
ProcessFunction собирает определенные объекты (на основе критерия) и отправляет в главный выводной коллектор (заключается в SingleOutputStreamOperator), а остальные события передаются в боковые выводы. Поток DataStream разделяется по вертикали и публикует различные форматы для каждого бокового потока.Обратите внимание: определение бокового потока вывода основано на уникальном теге вывода (объект
OutputTag). // Определить отдельный поток для Исполнителей
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
// Определить отдельный поток для Певцов
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// Преобразовать каждую запись в объект InputData и разделить главный поток на два боковых.
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// Преобразовать строку в объект InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
// Создать выходной кортеж со значениями имени и счета
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// Создать выходной кортеж со значениями имени и типа;
// Если новоиспеченный кортеж не совпадает с типом playerTag, то выбрасывается ошибка компиляции ("вывод метода не может быть применен к указанным типам")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// Собрать вывод основного потока как объекты InputData
collInputData.collect(inputData);
break;
}
}
});Пример кода, демонстрирующий, как разделить поток
Объединение потоков (пример #3)
Последняя операция, которая будет рассмотрена в этой статье – объединение потоков. Идея заключается в том, чтобы скомбинировать два разных потока, форматы данных в которых могут отличаться, из которых собрать один поток с унифицированной структурой данных. В отличие от операции объединения из SQL, где слияние данных происходит по горизонтали, объединение потоков осуществляется по вертикали, поскольку поток событий продолжается и никак не ограничен во времени.
Объединение потоков выполняется путем вызова метода connect, после чего для каждого элемента в каждом отдельном потоке определяется операция отображения. В результате получается объединенный поток.
// В описании возвращенного потока учтены типы данных обоих потоков
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // Поток 1
Tuple2<String, String>, // Поток 2
Tuple4<String, String, String, Integer> //Вывод
>() {
@Override
public Tuple4<String, String, String, Integer> //Обработка потока 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// Обработка потока 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});Листинг, демонстрирующий получение объединенного потока
Создание рабочего проекта
Итак, резюмируем: демо-проект загружен на GitHub. Там описано, как его собрать и скомпилировать. Это хорошая отправная точка, чтобы поупражняться с Flink.
Выводы
В этой статье описаны основные операции, позволяющие создать рабочее приложение для обработки потоков на основе Flink. Цель приложения – дать общее представление о важнейших вызовах, присущих потоковой обработке, и заложить базис для последующего создания полнофункционального приложения Flink.
Поскольку у потоковой обработки множество аспектов, и она сопряжена с разными сложностями, многие вопросы в этой статье остались не раскрыты; в частности, выполнение Flink и управление задачами, использование водяных знаков при установке времени для потоковых событий, подсадка состояния в события потока, выполнение итераций потока, выполнение SQL-подобных запросов к потокам и многое другое.
Надеемся, этой статьи было достаточно, чтобы вам захотелось попробовать Flink.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Актуальность темы
-
0,0%Пробовал Flink, тема интересна0
-
0,0%Не пробовал Flink, тема интересна0
-
0,0%Пробовал Flink, разочарован0
-
100,0%Предпочитаю альтернативную технологию1


