
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Команда VK Cloud перевела серию из двух статей о жизненном цикле ML-проекта, проектной документации, ценности для бизнеса и требованиях. О том, как начинать с малого и быстро отказываться от слабых идей. Руководство пригодится дата-сайентистам, специалистам по машинному обучению, руководителям отделов, техническим руководителям или тем, кто хочет дорасти до этого уровня.
Вместо введения
У многих дата-сайентистов и ML-инженеров, недавно получивших диплом, складывается превратное представление о будущей повседневной работе. Они рассчитывают, что она будет напоминать учебу:
Пробуешь классные современные алгоритмы на относительно чистых датасетах из постоянных данных и выбираешь наиболее точный вариант.
Но в учебе не нужно:
- думать о ценности проекта для бизнеса и бесконечном списке требований;
- собирать, маркировать и очищать данные для датасета. В некоторых случаях даже разбивка на обучающие, проверочные и тестовые сделана за вас;
- тщательно оценивать модель, проверять смещения и проводить A/B-тесты;
- деплоить модели для тысяч (или даже миллионов) пользователей и следить, чтобы они работали 99,9 % времени;
- отслеживать эффективность модели, выявлять снижение точности и переобучать по мере необходимости;
- собирать новые данные сразу же после развертывания предыдущей версии и начинать работать над новой моделью, надеясь, что в этот раз она выйдет получше.
В учебе подобного нет, а вот в реальной жизни именно это становится чрезвычайно важным.
В реальной жизни множество людей используют вашу модель всеми мыслимыми и немыслимыми способами. Эти люди ожидают, что она всегда будет работать быстро, точно и в целом без смещения. Поведение пользователей все время меняется, начинаются эпидемии и войны. А ваша компания пытается выйти в прибыль, предоставляя пользователям то, что им нужно. И добиваться конкурентного преимущества, применяя машинное обучение так, как это еще никому не удавалось.
Из статей этой серии вы поймете, что для создания качественных проектов машинного обучения нужно воспринимать их именно как систему, обращать внимание на все ее компоненты и их взаимосвязи.
Каждый проект должен начинаться с плана
Ниже представлен жизненный цикл проекта по машинному обучению:
- Понять задачу и определиться с тем, что нужно сделать.
- Собрать, промаркировать и очистить данные.
- Собственно смоделировать.
- Оценить модели и выбрать лучшую.
- Задеплоить модель и отслеживать ее производительность.

Изображение автора статьи
Все ли на этом? Нет, это только начало.
Во время мониторинга может выясниться, что модель не работает, как надо для того или иного сабсета пользователей. Или что ее точность со временем снижается. Тогда цикл повторяется: понять проблему → собрать данные → создать и оценить модель → выполнить деплоймент.
Или на этапе оценки выясняется, что модель недостаточно хороша для деплоймента. Тогда цикл повторяется снова: понять, что не работает и как это исправить → собрать больше данных → создать больше моделей → оценить модели, надеясь, что результат будет получше.
Если вы сейчас впервые услышали о жизненном цикле ML-проекта, советую почитать статью Антона Моргунова «Жизненный цикл проекта по машинному обучению и его этапы».
Важно понять вот что:
- Создание системы машинного обучения — это итеративный процесс. Он продолжается бесконечно, пока модель не выводят из продакшена. Покой нам только снится.
- На рисунке 1 представлена упрощенная схема разработки ML-системы. Но в реальности переходы между этапами не такие плавные. Чаще всего на каждом этапе что-то идет не так, и это отбрасывает вас назад на пару шагов или даже в самое начало. Добро пожаловать в реальный мир.

Изображение автора статьи
У специалистов с опытом в разработке, возможно, возникнет вопрос: «В чем разница между ML-проектами и разработкой традиционного программного обеспечения? Где тесты, сборки и релизы?» Хороший вопрос. Проект по машинному обучению — это подкласс проекта по разработке ПО. Так что все передовые методы разработки ПО отлично подходят и для ML-проектов. В связи с этим позвольте представить вам истинно реалистичный жизненный цикл проекта по разработке ПО с компонентом машинного обучения:
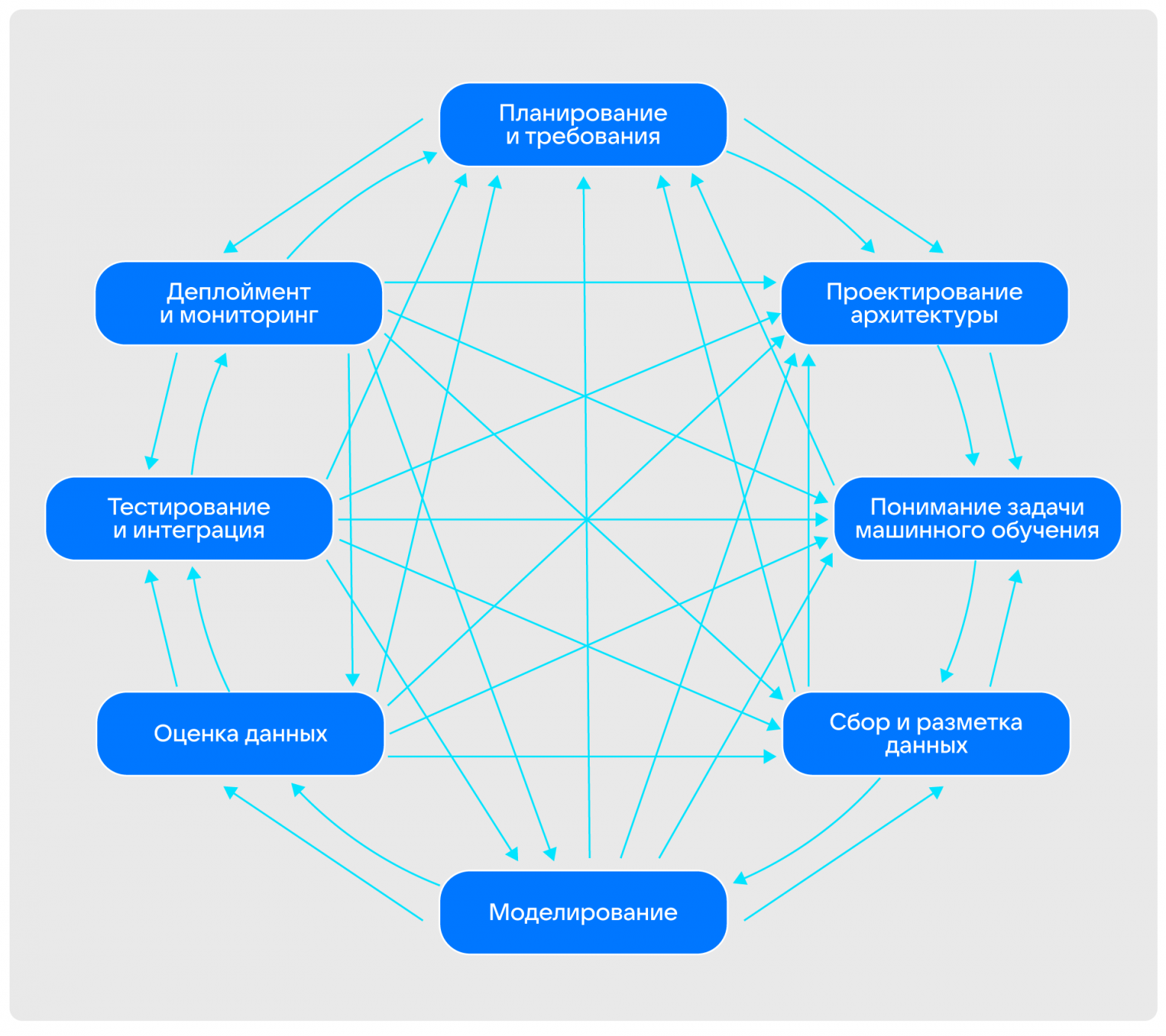
Изображение автора статьи
В статье Сатиша Чандра Гупты «MLOps: жизненный цикл в машинном обучении» можно прочитать про жизненный цикл разработки ML-программ.
Прежде чем потратить тысячи долларов на аннотирование данных и многие недели на разработку модели машинного обучения, нужно сделать четыре вещи. Назовем это предварительным этапом. Закройте пока что PyCharm. Все, что вам нужно, — это документ Google, мозги и Zoom.
1. Оцените ценность ML-проекта для бизнеса
Цель любой компании — заработать побольше денег. Или повысить качество обслуживания клиентов, чтобы заработать побольше денег. Отталкиваясь от этой понятной аксиомы, убедите начальника, высшее руководство, стейкхолдеров, что рассматриваемый ML-проект — сто̒ящая инвестиция.
В идеале нужно предоставить примерные расчеты, как ML-модель помогает увеличить доход компании, повысить вовлеченность пользователей или ускорить обработку запросов. Подойдите к вопросу творчески, отключите перфекционизм и не стесняйтесь просить о помощи коллег из финансового и маркетингового отделов.
Не забудьте: позднее эти метрики будут использовать для оценки проекта, так что придерживайтесь в обещаниях здорового реализма.
2. Соберите требования
Когда вы убедили всех в необходимости ML-модели, начните собирать требования. Каждая область деятельности имеет свою специфику, каждый проект уникален. Не существует исчерпывающего списка требований, на который можно положиться. Так что доверьтесь своему опыту и сотрудничайте с коллегами.
Вот полезный совет: составьте список общих вопросов и спрашивайте — свой список я приведу ниже. Начинайте разговор, и по мере обсуждения вопросы естественным образом станут более специализированными. Вот что спрашиваю я:
- Сколько у нас данных? Как их маркировать?
- Какова задержка модели?
- Где будет происходить деплоймент модели — в облаке или в локальной среде? Каковы спецификации экземпляра?
- Есть ли требования к конфиденциальности данных и объяснимости модели?
Если какую-то задачу в принципе можно решить с помощью машинного обучения, это еще не значит, что ее нужно решать именно так. В этой точке пора пересмотреть ситуацию. Может быть, подходящим решением станет сугубо программное решение или базовый подход на основе правил. Вот статьи, которые помогут разобраться с другими подходами:
- «Когда использовать машинное обучение» от Amazon;
- «Четыре ситуации, когда не нужно использовать машинное обучение» от Svenja Szillat.
Не бывает машинного обучения без данных. Звучит очевидно, но, к сожалению, за годы работы я видела, что слишком много компаний допускают одну и ту же ошибку. Они хотят ИИ, но датасеты у них маленькие, неочищенные или с нехваткой важных признаков. В отличной статье «Иерархия потребностей в ИИ» Моника Рогати предлагает воспринимать ИИ как верхушку пирамиды потребностей, а сбор данных, их хранение и очистку — как ее основание.

Рисунок 4. Иерархия потребностей в ИИ. На основании рисунка из статьи Моники Рогати «Иерархия потребностей в ИИ»
3. Начинайте с малого и быстро отказывайтесь от плохих идей
Даже если вы хотите создать ML-систему, которая обслуживает миллионы людей каждый день, разумно начать с малого:
- PoC (доказательство концепции). Вручную извлеките данные из хранилищ, пройдите быстрые итерации, ограничившись парой алгоритмов в Jupyter Notebook, и, наконец, докажите (или опровергните) гипотезу, что на имеющихся у вас данных вы можете обучить модель машинного обучения с удовлетворительной точностью. На этапе PoC вы также поймете, что нужно для развертывания и масштабирования модели.
- MVP (минимально жизнеспособный продукт). Допустим, этап PoC прошел успешно и теперь вы создаете и выпускаете продукт только с базовыми функциями. Что это значит в разрезе машинного обучения? Развертываем модель для сегмента пользователей и оцениваем, приносит ли она ожидаемую ценность для бизнеса.
Как только вы осознали, что идея не срабатывает, откажитесь от нее с чистой совестью и переходите к следующей. Сделать это гораздо проще, если вы еще не потратили на нее годы работы или сотни тысяч долларов. Низкая цена неудачи — ключевой фактор в успехе проекта.
Чтобы подробнее изучить эту тему, прочитайте статью Дмитрия Чекалина «POC vs MVP: что выбрать, чтобы создать отличный продукт».
4. Подготовьте проектную документацию
В разработке программного обеспечения проектная документация — это описание архитектуры системы ПО, ее общей структуры, отдельных компонентов и их взаимосвязей. Эту документацию можно оформить в любом виде, у нее может быть любая структура, она может быть официальной или неформальной, общей или подробной — все это решает команда. На этапе внедрения проектная документация служит готовой схемой, которой должны следовать разработчики.
Это передовая практика разработки, и, как я упоминала ранее, все передовые методы разработки отлично подходят для проектов по машинному обучению.
Лично я люблю проектную документацию по следующим причинам:
- Ее написание запускает мыслительный процесс. Подготовка проектной документации похожа на реализацию проекта в общих чертах: вы еще не пишете код, но уже принимаете решения по данным, алгоритмам и инфраструктуре. Вы рассматриваете все сценарии и оцениваете компромиссы, а это значит, что в будущем вы сэкономите время и деньги, избегая тупиковых ситуаций.
- Проектная документация упрощает синхронизацию и совместную работу в команде. К ней имеют доступ все сотрудники, так что они могут ознакомиться с самим документом, изучить дизайн системы и обсудить необходимые моменты. Никто не остается в стороне, и каждый может внести свой вклад.
Если вы уже готовы начать подготовку проектной документации, вот шаблон для систем машинного обучения, предложенный Юджином Яном. Берите его в качестве образца и вносите необходимые изменения.
Если вы хотите узнать больше о понятии проектной документации, советую вам эти статьи:
- «Как подготовить проектную документацию для систем машинного обучения», Юджин Ян;
- «Проектная документация в Google», Малте Убл.
Заключение
Каждый проект должен начинаться с плана, потому что ML-системы слишком сложны, чтобы внедрять их спонтанно. Мы обсудили жизненный цикл ML-проекта, выяснили, как и зачем прогнозировать ценность проекта для бизнеса, как собирать требования, а потом трезво оценивать, действительно ли в данном случае нужно именно машинное обучение. Узнали, как начинать с малого и быстро отказываться от плохих идей, используя концепции PoC или MVP. И наконец, поговорили о важности проектной документации на этапе планирования.
В следующих статьях вы узнаете о том, как собирать и маркировать данные, разрабатывать модель, отслеживать эксперименты, проводить оценку онлайн и офлайн, выполнять деплоймент, мониторить, переобучать и многое другое — все это поможет вам создавать качественные системы машинного обучения.
На этапе планирования важно также выбрать инструмент для машинного обучения. Попробуйте ML Platform от VK Cloud — она помогает построить процесс работы с ML-моделями от дизайна до деплоя, контролировать качество экспериментов и моделей. Для тестирования мы начисляем новым пользователям 3000 бонусных рублей и будем рады вашей обратной связи.
Stay tuned
Присоединяйтесь к телеграм-каналу «Данные на стероидах». В нем вы найдете все об инструментах и подходах к извлечению максимальной пользы из работы с данными: регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.



