
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Компании могут разными способами помочь своим разработчикам добиться максимальной продуктивности: от изменения офисного пространства до приобретения более совершенных инструментов и очистки исходного когда. Но какие решения повлияют сильнее всего? Опираясь на литературу по разработке ПО и промышленной/организационной психологии, мы выявили связанные с продуктивностью факторы и опросили 622 разработчика из трёх компаний. Нас интересовали упомянутые факторы и то, как люди сами оценивают свою продуктивность. Полученные нами результаты предполагают, что на самооценку больше всего влияют нетехнические факторы: энтузиазм в работе, поддержка новых идей вашими коллегами, а также получение полезной обратной связи о вашей продуктивности. По сравнению с другими работниками умственного труда, оценка своей продуктивности разработчиками ПО сильнее зависит от разнообразия задач и возможности работать удалённо.
1. Введение
Важно повышать продуктивность разработчиков. По определению, когда они завершают свои задачи, они могут тратить освободившееся время на другие полезные задачи: внедрение новых функций и новые проверки. Но что помогает разработчикам быть более продуктивными?
Компании нуждаются в практическим руководстве, какими факторами нужно манипулировать для максимального повышения продуктивности. Например, должен ли разработчик тратить время на поиск более совершенных инструментов и подходов, или ему следует выключать уведомления в течение рабочего дня? Следует ли руководителю вкладываться в рефакторинг для уменьшения сложности кода или дать разработчикам больше автономности в работе? Следует ли начальству вложиться в более совершенный инструментарий разработки или в создание более комфортного офиса? В идеальном мире мы вложились бы в разные факторы повышения продуктивности, но время и деньги ограничены, так что приходится выбирать.
Эта статья посвящена самому широкому на сегодняшний день исследованию прогнозирования продуктивности разработчиков ПО. Как описано в разделе 3.1, продуктивность можно измерить объективно (например, в строках кода за месяц) или субъективно (как её оценивает сам разработчик). Хотя ни один из подходов не является предпочтительным, мы постарались широко охватить эту тему с помощью субъективной оценки, чтобы ответить на три вопроса:
- Какие факторы позволяют лучше всего спрогнозировать оценку разработчиком своей продуктивности?
- Как эти факторы меняются в зависимости от компании?
- Что прогнозирует оценку разработчиком своей продуктивности, в частности, по сравнению с другими работниками умственного труда?
Для ответа на первый вопрос мы провели исследование в большой компании, разрабатывающей ПО.
Для ответа на второй вопрос, который помогает понять, в какой степени полученные результаты можно обобщить, мы провели исследование в двух компаниях из разных отраслей.
Для ответа на третий вопрос, который помогает понять, чем разработчики отличаются от других, мы провели исследование среди представителей иных профессий и сравнили с результатами, полученными при исследовании разработчиков.
Согласно нашим результатам, в исследованных нами компаниях на самооценку своей продуктивности сильно влияют энтузиазм в работе, поддержка коллегами новых идей, а также получение полезной обратной связи о своей продуктивности. По сравнению с другими работниками умственного труда, оценка своей продуктивности разработчиками ПО сильнее зависит от разнообразия задач и возможности работать удалённо. Компании могут использовать наши результаты для приоритизации инициатив, связанных с продуктивностью (раздел 4.7).
В разделе 2 описаны исследованные нами компании. В разделе 3 описана методология исследования. В разделе 4 описаны и проанализированы полученные результаты. А в разделе 5 описаны другие работы по этой теме.

2. Исследованные компании
2.1. Google
У Google около 40 офисов разработки по всему миру, в которых работают десятки тысяч разработчиков. В компании ценится тесное взаимодействие внутри команд, и офисы обычно имеют открытую планировку, чтобы участники одной команды были ближе друг к другу. Компания относительно молода (основана в конце 1990-х), её организационная структура довольно плоская, у разработчиков большая автономия. Процесс продвижения по службе включает обратную связь от коллег, и для продвижения разработчикам не нужно переходить на управленческие должности. Разработчики сами планируют своё время, их календари отображаются в корпоративной сети. В Google используются гибкие процессы разработки (например, Agile), обычно применяемые ко всей команде.
В Google ценят открытость. Большинство разработчиков трудятся над общей монолитной кодовой базой, поощряется внесение изменений в код чужих проектов. В компании сильная культура тестирования и анализа кода: отправленный в репозиторий код анализируется другим разработчиком, обычно с применением тестов. Большинство пишет серверный код, который часто релизится и позволяет относительно легко выкатывать фиксы. Инструментарий разработки в основном унифицирован (за исключением редакторов) и создан внутри компании, в том числе инструменты для анализа и непрерывной интеграции, а также инфраструктура для релиза.
2.2. ABB
У ABB далеко за 100 000 сотрудников по всему миру. Поскольку это инженерный конгломерат, в компании работают представители многочисленных профессий. Здесь около 4000 обычных разработчиков ПО и свыше 10 000 разработчиков приложений, которые создают промышленные системы с помощью характерных для разных отраслей визуальных и текстовых языков. Для эксплуатации своей большой ИТ-инфраструктуры в компании поддерживается значительный штат сотрудников, в чьи обязанности входит скриптовое и упрощённое программирование.
Хотя ABB поглотила ряд более мелких компаний, у неё есть центральная организация, отвечающая за унификацию процессов разработки ПО. Так что, несмотря на различия между департаментами, большинство инструментов и подходов унифицированы. То же самое относится и к большинству этапов карьерного роста: для технарей от младшего до старшего разработчика, а для управленцев — от лидера группы до лидера департамента и центрального руководства.
2.3. National Instruments
Компания National Instruments основана в 1970-х. Создание ПО в основном сосредоточено в четырёх международных центрах исследования и разработки. Календари сотрудников видны всей компании, любой может назначить встречу с любым другим сотрудником.
Служебные обязанности способствуют процессам разработки. Разработчики не могут самостоятельно выбирать проект, но могут браться за конкретные задачи или фичи. Большинство работает с общей монолитной кодовой базой, у её разных логических частей есть конкретные владельцы. Вносимый код должен получить одобрение от «владельца». Желательно, чтобы код анализировался техлидами. Эта политика не обязательна, но многие ей следуют.
У разработчиков много свободы в выборе инструментом. Общих инструментов нет, если только это не даёт немедленного преимущества. Например, выбор IDE сильно зависит от задачи. Есть ряд самописных инструментов для сборки и тестирования. В разных частях компании стандартизированы разные системы управления исходным кодом и его анализа. Обновления ПО обычно релизят поквартально или ежегодно, за исключением редких критических патчей.
Таблица 1. Профили трёх изученных компаний:
| ABB | National Instruments | ||
| Размер | Большая. | Большая. | Маленькая. |
| Офисы | Открытые офисы. | Открытые и закрытые офисы. | Открытые офисы. |
| Инструментарий | В основном унифицированные инструменты разработки. | Одинаковые инструменты. | Гибкость при выборе инструментов |
| Тип разработки | В основном серверный и мобильный код. | Сочетание веб-разработки, встроенного и настольного ПО. | В основном встроенное и настольное ПО. |
| Репозиторий | Монолитный репозиторий. | Отдельные репозитории. | Монолитный репозиторий. |
| Уклон | Разработка ПО. | Инженерный конгломерат. | Разработка ПО и оборудования. |
3. Методология
Наша цель: выяснить, какие факторы позволяют прогнозировать продуктивность разработчиков ПО. Для этого мы провели исследование, содержащее набор вопросов, набор факторов продуктивности и набор демографических переменных.
3.1 Оценка своей продуктивности
Сначала опишем, как мы будем измерять продуктивность. Рамирез (Ramírez) и Нембхард (Nembhard) предложили классификацию методик измерения продуктивности, описанных в литературе, в том числе анализ функциональных точек, самооценку, оценку коллегами, пропорциональность результатов и усилий, а также профессиональное использование времени [2]. Эти методики можно разделить на объективные (например, сколько строк кода написано за неделю) и субъективные измерения (например, самостоятельная оценка или оценка коллегами).
Ни одна методика не является предпочтительной, у обеих категорий есть недостатки. Объективным измерениям не хватает гибкости и игровой составляющей. Возьмём количество строк код в неделю. Продуктивный разработчик может написать однострочное исправление труднонаходимого бага. А непродуктивный разработчик легко может раздуть количество строк. С другой стороны, субъективные измерения могут быть неточными из-за когнитивных предубеждений. Возьмём оценку коллегами: продуктивного разработчика они могут недолюбливать, и поэтому его оценки будут хуже, даже если коллеги будут стремиться к объективности.
Как и коллектив исследователей под руководством Майер (Meyer), которые проанализировали продуктивность разработчиков ПО [3], мы использовали вопросы своего исследования в качестве субъективной оценки продуктивности. Основных причин две. Во-первых, как отметили Рамирез и Нембхард, исследования это «простой и популярный способ измерения продуктивности [работников умственного труда]». Во-вторых, исследования позволяют получить ответы от разработчиков, занимающих разные должности, а также позволяют респондентам добавлять различную информацию в оценку своей продуктивности.
Рис. 1. Методология исследования:

Мы спросили респондентов, насколько они согласны с утверждением:
Я регулярно достигаю высокой продуктивности.
С его помощью мы хотели измерить продуктивность максимально широко. Сначала мы сформулировали восемь вариантов вопроса, а затем свели их к вышеуказанному, неформально поговорив с пятью разработчиками Google об их интерпретации фразы (Рис. 1, внизу слева). В вопрос мы по трём причинам добавили оценочные слова «высоко» и «регулярно». Во-первых, мы хотели зафиксировать состояние, с которым люди могут себя сравнивать. Во-вторых, мы хотели, чтобы это состояние характеризовало высокий уровень, чтобы избежать эффектов достижения потолка в ответах респондентов. В-третьих, мы хотели, чтобы респонденты сосредоточились на двух конкретных мерах продуктивности — интенсивности и частоте. В будущем исследователи могут применять более подробные меры, разделив интенсивность и частоту по двум отдельным вопросам.
Мы проверили получившийся вариант на практике, попросив трёх руководителей в Google разослать его своим командам с вопросом: «Что вы учитывали при ответе на утверждение о продуктивности?». Мы получили ответы от 23 разработчиков (Рис. 1, внизу в центре). Вариант сочли приемлемым для наших целей, потому что соображения респондентов совпали с нашими ожиданиями относительно значения продуктивности. Эти соображения охватывали проблемы с рабочим процессом, результаты работы, пребывание в зоне или в потоке, счастье, достигнутые цели, эффективность программирования, прогресс и минимизацию пустых усилий. В этой работе мы не анализировали эти ответы, однако в исследование включены четыре дополнительные, уточнённые меры продуктивности, взятые из предыдущих работ [2], [4], [5].
Мы выбрали две удобные меры продуктивности, чтобы добавить объективные данные для контекстуализации самооценки, а затем коррелировали их друг с другом в Google. Первой объективной мерой было количество изменённых разработчиком строк кода в неделю — популярная, но непростая оценка продуктивности [6], [7]. Второй мерой было количество сделанных разработчиком изменений в основной кодовой базе Google за единицу времени. Она практически эквивалентна мере пул-реквестов в месяц, которую использовал коллектив под руководством Василешку (Vasilescu) [8]. Для оценки своей продуктивности мы использовали ответы на аналогичное исследование в Google (n = 3344 ответа). Мы не могли использовать для этого анализа данные из нашего исследования, потому что ответы не содержали идентификаторы участников, по которым можно было бы сопоставить объективные меры продуктивности. В том исследовании задавали аналогичный вопрос: «Как часто вы ощущаете, что достигли высокой продуктивности на работе?». Участники могли отвечать «Редко или никогда», «Иногда», «Примерно половину времени», «Большую часть времени» и «Всегда или почти всегда». Затем мы создали линейную регрессию с самооценкой продуктивности в качестве порядковой зависимой переменной (ordinal dependent variable) (закодировав 1, 2, 3, 4 и 5 соответственно). Линейная регрессия подразумевает равное расстояние между рейтингами продуктивности. Учитывая использованные в вопросе слова, мы считаем это предположение оправданным. Для упорядоченной логистической регрессии такого предположения не требуется. Применение здесь этой методики даёт надёжные результаты: одни и те же коэффициенты значимы и в линейной, и в упорядоченной модели.
В качестве независимых переменных мы используем логарифмированные объективные меры, потому что они обе имеют положительную асимметрию (positively skewed). Для контроля мы взяли код работы (например, программный инженер, инженер-исследователь и т.д.) в виде категориальной переменной, а также ранг (junior, middle, senior и т.п.) в виде числа (например, 3 для программного инженера начального уровня в Google). Код работы был статистически значимым для двух рабочих ролей в каждой линейной модели. Всего моделей было три: две с одной из объективных мер и одна с обеими объективными.

Рис. 2: Модели, прогнозирующие субъективную оценку продуктивности на основании двух объективных мер. n.s. означает статистически незначимый фактор с p > 0,05, ** означает p < 0,01, *** означает p < 0,001. Полное описание моделей дано в Дополнительных материалах.
Результаты контекстуализации приведены на рис. 2. Каждая модель демонстрирует статистически значимый уровень с отрицательной оценкой, что мы интерпретировали так: разработчики более высокого ранга склонны оценивать себя немного менее продуктивными. Это сильный аргумент в пользу контроля за рангом (раздел 3.7.). Первые две модели демонстрируют важную позитивную взаимосвязь между объективной и субъективной мерой продуктивности. То есть чем больше написано строк кода или сделано изменений, тем более продуктивным считает себя разработчик. Итоговая объединённая модель и оценки по двум первым моделям позволяют предположить, что количество сделанных изменений является более важным признаком продуктивности, чем количество написанных строк. Но обратите внимание, что во всех моделях параметр R2, представляющий долю объяснённой дисперсии, довольно низок — менее 3 % для каждой модели.
В целом, полученные результаты говорят о том, что количество строк кода и сделанных изменений влияют на оценку разработчиками своей продуктивности, но незначительно.
3.2. Факторы продуктивности
Затем в ходе исследования мы расспросили участников о факторах, которые в других работах считаются связанными с продуктивностью. Мы собрали вопросы из четырёх источников (рис. 1, слева посередине). Эти источники взяты потому, что, насколько нам известно, они представляют собой наиболее полные обзоры отдельных факторов продуктивности исследованиях программистов и других работников умственного труда.
Первый источник — инструмент, созданный коллективом под руководством Палвалин (Palvalin) для обзора мер продуктивности работников умственного труда [4]. Инструмент под названием SmartWoW применялся в четырёх компаниях и охватывает аспекты физического, виртуального и социального рабочего пространства, личных рабочих методик, а также благополучия на работе. Мы изменили некоторые вопросы, чтобы они лучше отражали современную терминологию разработчиков и больше соответствовали американскому английскому. Например, в SmartWoW спрашивается:
I often telework for carrying out tasks that require uninterrupted concentration.
Мы перефразировали:
I often work remotely for carrying out tasks that require uninterrupted concentration.
Из SmartWoW мы сначала подобрали для нашего исследования 38 вопросов.
Второй источник — обзор Хернаусом (Hernaus) и Микуличем (Mikulić) влияния характеристик условий работы на продуктивность работников умственного труда [9]. Их проверенная работа является отражением предыдущих исследований продуктивности: опросника для проектирования рабочей среды [10], диагностического исследования рабочей среды [11], оценки группового сотрудничества [12] оценки «природы задач» [13]. Мы изменили вопросы, чтобы они были краткими и последовательными. С той же целью мы взяли вопросы напрямую из работы [12], которая посвящена рабочим группам с небольшими соображениями о личной продуктивности.
Третий источник — структурированный обзор Вагнера (Wagner) и Руэ (Ruhe) факторов продуктивности в разработке ПО [14]. В отличие от других источников, эта работа не была тщательно проверена научным сообществом и не содержит оригинального эмпирического исследования. Но насколько нам известно, это наиболее полный обзор исследований продуктивности в программировании. Сформулированные Вагнером и Руэ факторы разделены на технические и не поддающиеся количественной оценке, а затем дополнительно выделены факторы окружения, корпоративной культуры, проекта, продукта и среды разработки, возможностей и опыта.
Четвёртый источник — исследование разработчиков Microsoft, проведённое коллективом под руководством Майера (Meyer). Из него мы почерпнули пять главных причин продуктивных рабочих дней, в том числе постановку целей, рабочие встречи и отрывы от работы [15].
Также мы добавили три фактора, которые, по нашему мнению, не были должным образом учтены в предыдущих работах, но которые оказались важны в условиях Google. Один из них — оценка продуктивности работников умственного труда [16], неопубликованный предшественник SmartWoW. Мы адаптировали его так:
Предоставленная мне информация (отчёты об ошибках, пользовательские сценарии и т.д.) точна.
Второй фактор взят из опросника для проектирования рабочей среды и адаптирован так:
Я получаю полезную обратную связь о моей рабочей продуктивности.
И мы создали третий фактор, который был важен в условиях ABB:
Мне требуется прямой доступ к определённому оборудованию для тестирования моего ПО.
Сначала мы подобрали 127 факторов. Чтобы свести их к такому количеству вопросов, на которые респонденты смогут ответить без значительного утомления [17], мы воспользовались критериями, изображёнными в центре рис. 1:
- Убрали дубли. Например, в SmartWoW [4] и работе Майер с коллегами [15] важным фактором продуктивности считается постановка целей.
- Объединили близкие факторы. Например, Хернаус и Микулич описывают разные аспекты взаимодействия между рабочими группами, повышающие продуктивность, но мы свели их к одному фактору [9].
- Предпочтение отдавалась факторам с очевидной полезностью. Например, в SmartWoW [4] есть такой фактор:
У работников есть возможность видеть календари друг друга.
В Google это везде верно и вряд ли изменится, поэтому у фактора низкая полезность.
Мы применили эти критерии совместно и итеративно. Сначала распечатали большой плакат всех вопросов-претендентов на использование в исследовании. Затем повесили плакат в Google рядом с нашим офисом. Затем каждый из нас независимо проанализировал вопросы с учётом вышеописанных критериев. Плакат висел несколько недель, мы периодически дополняли и снова пересматривали список. В конце концов был составлен финальный список вопросов.
В наше исследование вошли 48 факторов в форме утверждений (рис. 4, левая колонка). Респонденты указывали степень своего согласия с этими утверждениями по пятибалльной шкале, от «Полностью не согласен» до «Полностью согласен». Факторы можно объединить в блоки, относящиеся к методикам, нацеленности, опыту, работе, возможностям, людям, проекту, ПО и контексту. Также мы задавали один открытый вопрос о факторах, которые, по мнению респондентов, мы могли упустить. Полный опросник из нашего исследования приведён в Дополнительных материалах.

Рис. 3: Пример вопроса из исследования.
3.3. Демография
Мы задавали вопросы о нескольких демографических факторах, как показано на рис.1:
- Пол.
- Должность.
- Ранг.
Авторы предыдущих работ предположили, что пол связан с факторами продуктивности разработчиков ПО, например, с успешностью отладки [18]. Поэтому в исследовании был опциональный вопрос о поле (мужской, женский, отказываюсь отвечать, своё). Респонденты, не ответившие на вопрос, были отнесены к группе «отказываюсь отвечать» (Google n = 26 [6 %], ABB n = 4 [3 %], National Instruments n = 5 [6 %]). Мы обращались с этим данными как с категориальными.
Что касается должности, то стаж работы в Google мы взяли у отдела кадров. С ABB и National Instruments такой возможности не было, так что мы добавили в исследование опциональный вопрос. В ABB при отсутствии ответов (n = 4 [3 %]) мы брали 12 лет опыта, это среднее значение по собранным данным. В National Instruments мы по той же причине мы взяли 9 лет (n = 1 [1 %]). Можно делать сложнее [19], например, с помощью подстановок прогнозировать отсутствующие значения на основе имеющихся данных. Скажем, отсутствующую информацию о ранге можно достаточно точно заполнить на основе должности и пола. Однако мы подставляли просто среднестатистические значения, поскольку демографические факторы не были для нас первоочередными, они лишь были сопутствующей информацией для контроля. Эти данные мы обрабатывали как числа.
Что касается ранга, то в Google мы просили участников указать их уровень в виде числа. Отсутствующие ответы (n = 26 [6 %]) мы относили к наиболее распространённому значению.
В ABB участники могли по желанию указать «младший или «старший разработчик ПО», хотя многие указывали «другую» должность. Если в ответе были слова:
- старший
- ведущий
- менеджер
- архитектор
- исследователь
- основной
- учёный
то мы относили такие ответы к «старшим». Остальных относили к «младшим». Отсутствующие ответы (n = 4 [3 %]) мы относили к наиболее распространённому значению — «старший».
В National Instruments были варианты:
- претендент
- штатный
- старший
- основной архитектор/инженер
- главный архитектор/инженер
- заслуженный инженер
- участник
- другое
Единственный «другой» оказался стажёром, которого мы перенесли к «претендентам». Отсутствующие ответы (n = 3 [4 %]) мы относили к наиболее распространённому значению — «старший».
Ранги во всех компаниях мы кодировали числами.
3.4. Сравнение с неразработчиками
Далее нас интересовало, что именно позволяет прогнозировать оценку разработчиками своей продуктивности. Например, мы предполагали, что на продуктивность влияет отрыв от работы, но это можно было бы сказать про любого работника умственного труда. Поэтому возникает естественный вопрос: влияет ли это как-то по-особенному на продуктивность разработчиков?
Чтобы ответить на этот вопрос, мы выбрали профессии, сравнимые с разработчиками ПО. Сначала попробовали подбирать на основе должностей в Google. Хотя часть должностей говорила о том, что это работники умственного труда, однако самым распространённым и, по нашему мнению, самым надёжным индикатором подходящего неразработчика было наличие в должности слова «аналитик». Мы решили сравнить аналитиков и разработчиков Google, а не сравнивать аналитиков Google с разработчиками всех трёх компаний. Мы решили, что это позволит нам контролировать характерные для компании особенности (например, если вдруг сотрудники Google статистически более или менее чувствительны к отрыву от работы, чем сотрудники других компаний).
Затем мы адаптировали наше исследование к аналитикам. Убрали вопросы, явно относящиеся к разработке ПО, например, «Требования к моему ПО часто меняются». Другие вопросы мы переделали специально под аналитиков. Например, вместо «Для разработки ПО я использую лучшие инструменты и методики» мы написали «Для выполнения моей работы я использую лучшие инструменты и подходы».
Оценка своей продуктивности измерялась так же, как и у разработчиков. То же самое касается оценки пола, должности и ранга. «Аналитическую» версию исследования мы испытали на удобной выборке из пяти аналитиков, которые сказали, что в целом исследование понятное, и внесли несколько небольших правок. Мы их приняли и провели полноценное исследование неразработчиков.

3.5. Контрольный вопрос
Чтобы исключить ответы, которые даны необдуманно, примерно через 70 % от начала исследования мы вставили вопрос на внимательность [20]: «Ответьте на это «Скорее не согласен»». Те бланки, в которых не было такого ответа на этот вопрос, мы не учитывали.
3.6. Доля ответов
В Google мы на основе данных из отдела кадров выбрали 1000 случайных сотрудников, работающих на полную ставку, у которых были должности, относившиеся к разработке ПО. Мы получили от них 436 заполненных бланков, то есть доля ответов составила 44 %, это очень высокий показатель для исследований среди разработчиков [21]. После удаления бланков с неправильным ответом на контрольный вопрос (n = 29 [7 %]) осталось 407 ответов.
Для опроса работников умственного труда мы выбрали 200 случайных сотрудников Google на полную ставку, в должностях которых было слово «аналитик». Мы решили не исследовать слишком много аналитиков, потому что нашей целью были разработчики ПО. На наши вопросы ответили 94 человека, 47 %. После удаления анкет с ошибочным ответом на контрольный вопрос (n = 6 [6 %]) осталось 88.
Мы разослали свои анкеты примерно 2200 случайно выбранным разработчикам ПО в ABB и получили 176 ответов. Это 8 %, по нижней границе для подобных исследований [21]. После удаления ошибочных анкет (n = 39 [22 %]) осталось 137.
Наконец, мы разослали анкеты примерно 350 разработчикам ПО в National Instruments и получили 91 ответ (26 %). После удаления ошибочных анкет (n = 13 [14 %]) осталось 78.
3.7. Анализ
По каждому фактору в каждой компании мы применили индивидуальные линейные регрессионные модели, используя фактор в качестве независимой переменной (например, «Сроки по моему проекту сжатые»), а оценку своей продуктивности — в качестве зависимой переменной. Мы прогоняли отдельные модели по каждой компании ради сохранения приватности, чтобы исходные данные разных компаний не смешивались. Для уменьшения влияния сопутствующих переменных мы добавили в каждую регрессионную модель имеющиеся демографические переменные. При интерпретации результатов мы сосредоточились на трёх аспектах коэффициента фактора продуктивности:
- Оценка. Означает степень влияния каждого фактора при сохранении демографической постоянной. Чем больше значение, тем выше влияние.
- Стандартная ошибка. Означает вариативность прогноза. Чем ниже значение, тем меньше вариативность.
- Значимость. Также мы проанализировали статистическую значимость при пороговом значении p < 0,05. По каждой компании мы прогнали 48 статистических тестов и могли случайно обнаружить ряд взаимосвязей, поэтому для каждой компании мы скорректировали значения p по методу Бенджамини-Хохберга, созданному для исправления ложного обнаружения [22].
При интерпретации результатов мы сосредоточились больше на степени влияния (оценке) и меньше на статистической значимости, потому что её можно извлечь из достаточно больших наборов данных, даже если практическая значимость низкая. Как мы увидим ниже, статистически значимые результаты чаще всего были получены в Google, с максимальной долей ответов; реже всего — в National Instruments, где доля ответов была ниже. Мы сочли, что это различие по большей части связано со статистической мощность. Призываем вас быть более уверенными в результатах со статистической значимостью.
Для обеспечения контекста мы также проанализировали, насколько демографические факторы коррелируют с оценкой своей продуктивности. Для этого мы по каждой компании прогнали множественную линейную регрессию с демографическими переменными в качестве независимых переменных и с оценкой своей продуктивности в качестве зависимой переменной. Затем мы проанализировали общее прогнозное значение получившейся модели, а также влияние каждой независимой переменной.
3.8. О причинности
Наша методология позволяет оценить взаимосвязи между факторами продуктивности и оценкой своей продуктивности, хотя по сути нас интересует, какова степень влияния каждого фактора на изменение продуктивности. Насколько корректным будет полагать, что есть причинно-следственные связи между факторами и продуктивностью?
Корректность зависит в основном от силы доказательств причинно-следственной связи в предыдущих работах. И эта сила разная для разных факторов. Например, коллектив под руководством Гуццо (Guzzo) провёл мета-анализ 26 статей об оценке и обратной связи, и его результаты прекрасно доказывают, что обратная связь действительно повышает продуктивность на рабочем месте [23]. Однако определение силы доказательств по каждому исследованному фактору требует большой работы, которая выходит за рамки этой статьи.
Подытожим: хотя наше исследование не позволяет установить причинно-следственной связи, но опираясь на предыдущие работы мы можем с определённой уверенностью полагать, что указанные факторы влияют на продуктивность, однако интерпретируйте наши результаты с определённой осторожностью.

4. Результаты
Для начала мы опишем взаимосвязи между всем факторами продуктивности и оценкой своей продуктивности при контроле демографических характеристик. Эти данные будут использованы для ответа на каждый ответ исследования, с последующим обсуждением результатов. Затем мы обсудим связь между демографическими характеристиками и оценкой своей продуктивности. И наконец, обсудим последствия и риски.
4.1. Факторы продуктивности
На рис. 4 показаны результаты нашего анализа, описанного в разделе 3.7. В первой колонке приведены факторы, которые были предложены участникам в форме утверждений; затем идут метки факторов (F1, F2 и т.д.), которые мы присвоили после завершения анализа. Отсутствие данных означает, что эти факторы характерны для разработчиков и не предлагались аналитикам (например, F10).
Рис. 4: Взаимосвязи между 48 факторами и оценкой своей продуктивности разработчиками и аналитиками в трёх компаниях:
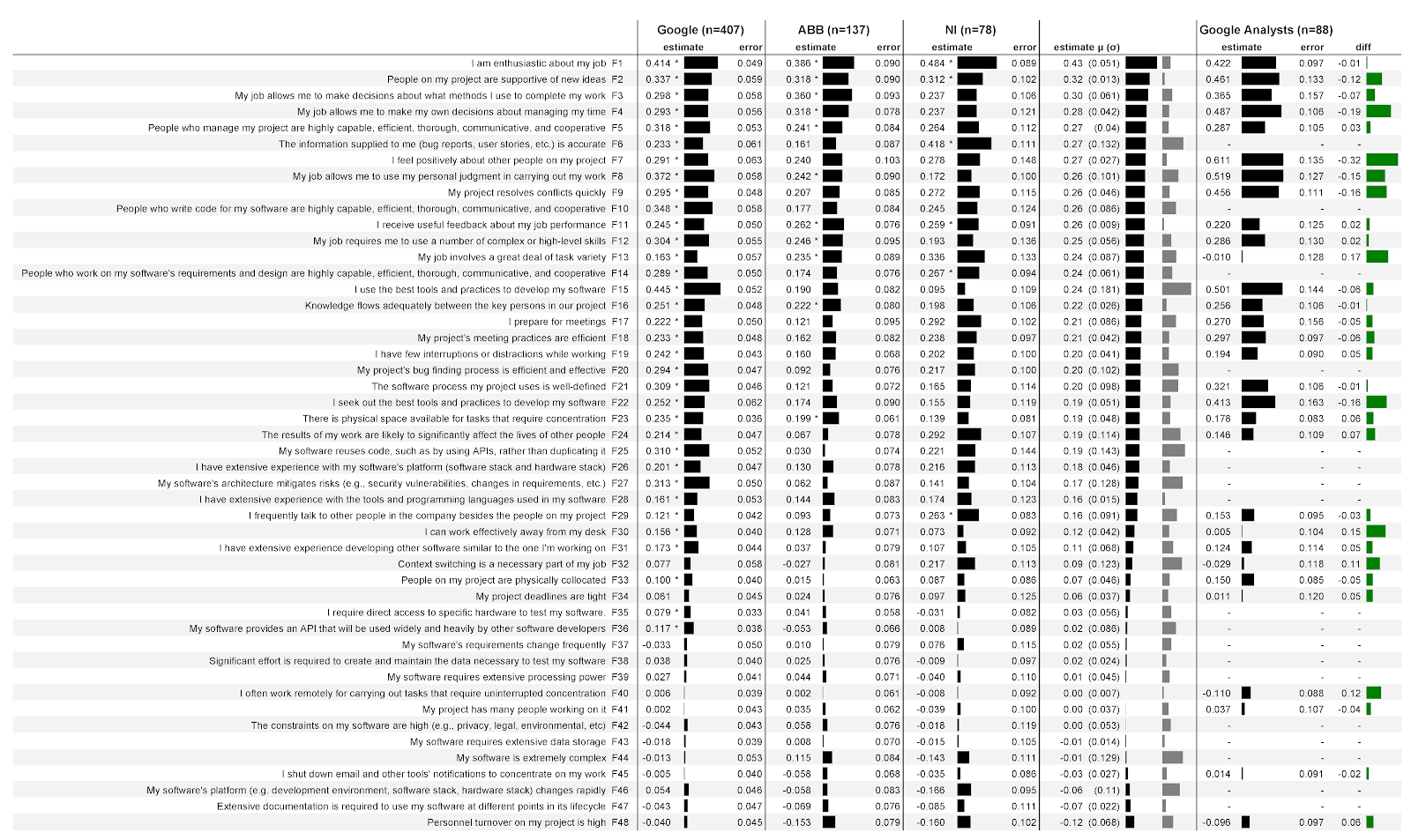
Далее в трёх колонках представлены данные, полученные в трёх компаниях, а также данные по аналитикам Google. Каждая из этих колонок разделена на две подколонки.
Подколонка estimate (оценка) содержит коэффициенты регрессии, количественно определяющие силу ассоциации фактора с оценкой своей продуктивности. Чем больше число, тем сильнее ассоциация. Например, в первой колонке Google estimate равно 0,414. В данном случае это означает, что на каждый пункт усиления согласия с утверждением о энтузиазме в работе (F1) модель прогнозирует увеличение рейтинга продуктивности респондента на 0,414 пункта с контролем демографических переменных. Оценки могут быть и отрицательными. Например, во всех трёх компаниях чем больше текучка кадров в команде (F48), тем ниже оценка своей продуктивности. Рядом с каждым значением оценки находится индикатор, наглядно отражающий величину оценки.
Обратите внимание, что оценки означают не более высокие рейтинги факторов, а более высокую корреляцию между фактором и оценкой своей продуктивности. Например, оценка энтузиазма в работе в National Instruments (F1) выше, чем в других компаниях. Это не означает, что там разработчики испытывают больше энтузиазма: в этой компании он является более сильным фактором прогнозирования оценки своей продуктивности. Мы не приводим сами рейтинги, потому что это запрещено по условиям сотрудничества. Без полного контекста рейтинги могут быть интерпретированы неверно. Например, если мы сообщим, что разработчики в одной компании испытывают меньший энтузиазм в работе, чем разработчики другой компании, у вас может возникнуть впечатление, что в этой другой компании лучше не работать.
Вторая подколонка error (погрешность) содержит стандартные ошибки модели по каждому фактору. Чем ниже значение, тем лучше. Интуитивно кажется, что более низкие значения говорят о том, что при изменении факторов модель надёжнее прогнозирует оценку своей продуктивности. Общие значения погрешностей довольно стабильны от фактора к фактору, особенно в Google с большим количеством респондентов.
Звёздочка (*) говорит о том, что этот фактор был статистически значимым в модели. Например, энтузиазм в работе (F1) статистически значим во всех трёх компаниях, а подготовка ко встречам (F17) значима только в Google.
Следующая колонка содержит среднюю (µ) оценку по всем трём компаниям со стандартным отклонением в скобках (σ). Первый индикатор наглядно показывает величину средней оценки, второй индикатор — величину стандартного отклонения. Например, средняя оценка для энтузиазма в работе (F1) была равна 0,43, стандартное отклонение — 0,051. Таблица отсортирована по средней оценке.
В последней колонке содержатся значения разницы (diff) между оценками для разработчиков ПО и аналитиков в Google. Положительные значения говорят о том, что оценки для разработчиков выше, отрицательные — что выше оценки для аналитиков. Например, по энтузиазму (F1) у аналитиков оценки чуть ниже, чем у разработчиков.
4.2. Какие факторы лучше всего позволяют прогнозировать оценку разработчиками своей продуктивности?
Самыми сильными прогнозными факторами являются утверждения с наибольшей абсолютной средней оценкой. Самые слабые прогнозные факторы — с наименьшей абсолютной средней оценкой. Иными словами, факторы в верхней части таблицы на рис. 4 позволяют прогнозировать лучше всего. Чтобы понять, какой фактор обеспечивает наибольшую уверенность в результате, мы выделили результаты, которые статистически значимы для всех трёх компаний:
- Энтузиазм в работе (F1)
- Поддержка коллегами новых идей (F2)
- Полезная обратная связь о рабочей продуктивности (F11)
Обсуждение. Обратите внимание, что первые 10 факторов продуктивности не относятся к техническим. Это удивительно, с учётом того, что, по нашей оценке, большинство исследований разработчиков ПО сосредоточено на технических аспектах. Поэтому активная переориентация на человеческий фактор может привести к значительному росту влияния исследователей на отрасль. Например, особенно плодотворными могут быть ответы на следующие вопросы:
- Что заставляет разработчиков ПО испытывать энтузиазм в работе? Что объясняет различия в энтузиазме? Какие вмешательства могут повысить энтузиазм? Эта статья может дополнить работы по исследованию счастья [24] и мотивации [25].
- Какого рода новые идеи обычно высказывают в сфере разработки ПО? Какие действия вызывают у разработчика ощущение, что его идеи поддерживают? Какие вмешательства могут повысить поддержку новых идей с сохранением текущих обязательств?
- Какую обратную связь по работе получают разработчики, и что делает её полезной? Какая обратная связь не является полезной? Какие вмешательства могут повысить регулярность и полезность обратной связи?
Другой важной особенностью является ранжирование факторов из направления исследований COCOMO II. Эти факторы, полученные в ходе эмпирических изучений отраслевых программных проектов и проверенные с помощью численного анализа 83 проектов [26], изначально формулировались для оценки стоимости разработки ПО. Например, к факторам продуктивности из COCOMO II относится волатильность базовой платформы и сложность продукта. Любопытно, что учтённые в нашем исследовании факторы COCOMO II (F5, F10, F14, F16, F24, F26, F28, F32, F33, F34, F36, F38, F39, F43, F44, F46, F47, F48) получили более низкие значения. Можно предположить, что они позволяют хуже прогнозировать продуктивность. В верхнюю половину прогнозных факторов (F1–F24) вошло только 5 из COCOMO II, а в нижнюю половину — 14 факторов. Мы можем предложить две разные интерпретации. Первая: в COCOMO II не хватает несколько важных факторов продуктивности, и будущие итерации COCOMO II могут давать более точные прогнозы, если внедрить больше исследованных нами факторов, например, поддержку в компании автономности рабочих подходов. Другая интерпретация: COCOMO II адаптирован под текущую задачу — фиксацию продуктивности на уровне проекта [6], [27], [28], [29], [30], [31] — но хуже подходит для фиксации продуктивности на уровне отдельного разработчика. Эта интерпретация подчёркивает важность и новизну наших результатов.
Кроме того, все факторы COCOMO II были относительно низкими и статистически незначимыми прогнозными факторами продуктивности во всех трёх компания. Например:
- Моему ПО нужна значительная вычислительная мощность (F39).
- Моему ПО нужно обширное хранилище данных (F43).
- Моя программная платформа (например, среда разработки, программный или аппаратный стек) быстро меняется (F46).
Одно из объяснений: за 20 лет с момента создания и проверки COCOMO II платформы стали меньше различаться с точки зрения продуктивности. Вероятно, стандартизированные операционные системы теперь защищают разработчиков от потерь продуктивности из-за аппаратных изменений (например, Android в мобильной разработке). Аналогично, облачные платформы могут защищать разработчиков от потерь продуктивности в результате масштабирования процессов и потребностей в хранении данных. Не говоря уже о том, что современные фреймворки и облачные платформы просты в использовании. К тому же разница в продуктивности при обработке большого и небольшого количества данных могла исчезнуть со времён создания COCOMO II.
4.3. Как эти факторы различаются в зависимости от компании?
Для ответа на этот вопрос можно взглянуть на стандартное отклонение в оценках по трём компаниям. Вот три фактора с наименьшей вариативность, то есть с наиболее стабильными значениями по компаниям:
- Использование удалённой работы для сосредоточенности (F40).
- Полезная обратная связь о рабочей продуктивности (F4).
- Поддержка коллегами новых идей (F2).
Мы полагаем, что стабильность этих факторов делает их хорошими кандидатами на обобщаемость. Вероятно, другие компании получат аналогичные результаты по этим факторам.
А вот три фактора с наибольшей вариативностью, то есть с наибольшим разбросом значений по компаниям:
- Использование лучших инструментов и подходов (F15).
- Повторное использование кода (F25).
- Точность входящей информации (F6).
Обсуждение. Три наименее вариативных фактора (F40, F4 и F2) имеют общую черту — относятся не к технике, а к социуму и среде. Возможно, это говорит о том, что где бы разработчики не работали, на них одинаково влияет удалённая работа, обратная связь и поддержка коллегами новых идей. Изменение этих трёх факторов может оказаться наибольшее влияние.
А почему так сильно различаются в разных компаниях факторы F15, F25 и F6? По каждому из них у нас есть возможное объяснение, основанное на том, что нам известно об этих компаниях.
Использование лучших инструментов и подходов (F15) сильнее всего связано с оценкой своей продуктивности в Google, но при этом незначительно связано в National Instruments. Возможное объяснение: кодовая база Google значительно больше. Следовательно, использование лучших инструментов и подходов для эффективной навигации и понимания более крупной кодовой базы значительно влияет на продуктивность. А в National Instruments продуктивность меньше зависит от инструментов, потому что кодовая база меньше и понятнее.
Повторное использование кода (F25) сильно связано с оценкой своей продуктивности в Google, но при этом незначительно связано в ABB. Возможное объяснение: в Google легче использовать код повторно. Кодовая база монолитна, все разработчики могут исследовать практически каждую строку кода в компании, так что повторное использование не требует больших усилий. А в ABB много репозиториев, к которым приходится получать доступ. И в этой компании прирост продуктивности (через повторное использование) может быть сведён на нет потерями продуктивности (из-за поиска и получения нужного кода).
Точность информации (F6) сильно связана с оценкой своей продуктивности в National Instruments, но при этом незначительно связана в ABB. Возможное объяснение: разработчики в ABB лучше изолированы от влияния неточной информации. В частности, в ABB несколько уровней команды поддержки занимаются получением от клиентов корректной информации о багах. Если разработчик получает неточную информацию, то его продуктивность может упасть, потому что ему приходится делегировать задачу по уточнению данных обратно команде поддержки.
4.4. Что позволяет прогнозировать оценку разработчиком своей продуктивности, в частности, по сравнению с другими работниками умственного труда?
Для ответа на этот вопрос обратимся к последней колонке на рис. 4. Если посмотреть на несколько взаимосвязей между максимальными оценками, то увидим, что оценка аналитиками своей продуктивности сильнее связана с:
- Позитивными восприятием своих коллег по команде (F7).
- Автономностью в организации рабочего времени (F4).
С другой стороны, оценка разработчиками своей продуктивности сильнее связана с:
- Выполнением в рамках работы разнообразных задач (F13).
- Эффективной работой вне своих рабочих мест (F30).
Обсуждение. В целом результаты говорят о том, что разработчики в чём-то похожи на других работников умственного труда, а в чём-то отличаются. Например, лучше всего прогнозировать продуктивность разработчиков позволяет энтузиазм в работе, и у аналитиков ситуация почти такая же. Мы считаем, что компании могут использовать полученные нами результаты для выбора инициатив в сфере повышения продуктивности, нацеленные именно на разработчиков, либо выбрать инициативы более широкого действия.
Унифицированный инструментарий разработки в Google может объяснить, почему повышение разнообразия задач связан с повышением оценки своей продуктивности у разработчиков, а не у аналитиков. Разнообразие задач может снизить скуку и повысить продуктивность в обеих группах, однако унифицированный инструментарий разработки в Google может означать, что разработчики могут использовать одни и те же инструменты для разных задач. А аналитикам может потребоваться использовать разные инструменты для разных задач, что повышает когнитивные усилия при переключении контекста.
Отрывы от работы могут объяснять, почему повышение рабочей эффективности вдали от рабочего места у разработчиков сильнее связано с ростом продуктивности, чем у аналитиков. Мы полагаем, отрыв от работы более вреден в ходе программирования, чем в ходе аналитической работы.
Парнин (Parnin) и Ругабер (Rugaber) обнаружили, что возврат к работе после прерывания — частая и постоянная проблема для разработчиков [32], приводящая к тому, что им нужны более совершенные инструменты, помогающие вернуться к работе над задачей [33].

4.5. Другие факторы продуктивности
В конце анкеты респонденты могли указать дополнительные факторы, по их мнению влияющие на продуктивность. По большей части эти дополнения представляли собой те же или более уточнённые описания наших 48 факторов. Такие дополнения мы отбрасывали, но при необходимости создавали новые факторы. В Дополнительных материалах приведены описания новых факторов, а также уточнённые описания предложенных нами изначально. Будущие исследователи могут новый вопрос о смешанной команде для работы над проектом, а также уточнить или предложить более конкретные разбивки вопросов для факторов F15, F16 и F19.
4.6. Демография
В Google и National Instruments ни общие демографические модели, но индивидуальные сопутствующие переменные не были статистически значимыми факторами прогнозирования оценки своей продуктивности.
Для ABB демографическая модель оказалась значимой (F = 3,406, df = (5, 131), p < 0,007). Пол тоже оказался статистически значимым фактором (p = 0,007), у женщин оценка своей продуктивности на 0,83 пункта выше, чем у мужчин. Участники иных полов («другое») продемонстрировали оценку на 1,6 пункта выше, чем у мужчин (p = 0,03). Значимые результаты показала и должность (p = 0,04), каждый дополнительный год в компании повышал оценку своей производительности на 0,02 пункта. Насколько нам известно, различия между ABB и двумя другими компаниями не объясняют, почему эти демографические факторы оказались значимыми для прогнозирования только в ABB и нигде больше.
4.7. Применение на практике и в исследованиях
Как использовать наши результаты на практике? Мы предоставили ранжированный список наиболее важных для прогнозирования продуктивности факторов, с помощью которого можно приоритизировать инициативы. Примеры инициатив можно найти в предыдущих исследовательских работах.
Например, чтобы повысить энтузиазм в работе, Маркос (Markos) и Шридеви (Sridevi) предложили помогать работникам расти профессионально [34] с помощью мастер-классов по технологиям и межличностным коммуникациям. Также исследователи предложили внедрить практику признательности за хорошую работу. К примеру, в ABB экспериментируют с публичной признательностью разработчикам, внедрившим инструменты и методики навигации по структурированному коду [35].
Чтобы повысить поддержку новых идей, Браун (Brown) и Дюгайд (Duguid) предложили формальный и неформальный способы делиться лучшими подходами [36]. В Google одностороннее распространение знаний происходит с помощью инициативы «Тестирование на туалете»: разработчики пишут краткие новостные заметки о тестировании или другой сфере, а потом эти заметки развешиваются в туалетах по всей компании.
Для повышения качества обратной связи о рабочей продуктивности Лондон (London) и Смизер (Smither) предлагают сосредоточиться на обратной связи, которая является неосуждающей, основанной на поведении, интерпретируемой и нацеленной на результат [37]. В Google такую обратную связь можно получить через безобвинительные постмортемы: после важных негативных событий вроде падения сервисов инженеры совместно пишут отчёт, посвящённый действиям, которые повлияли на исходную причину проблемы, без обвинения конкретных сотрудников.
Мы видим несколько направлений будущих исследований на основе нашей работы.
Во-первых, систематизированный анализ статей, характеризующий влияние и контекст доказательств каждого рассмотренного здесь фактора продуктивности, улучшит практическую применимость нашей работы за счёт создания причинно-следственных связей. Там, где они слабы, применимость можно повысить, проведя ряд экспериментов для установления причинно-следственных связей.
Во-вторых, как упоминалось в разделах 4.5 и 4.6, будущие исследователи могут использовать дополнительные факторы, предложенные нашими респондентами, и изучить влияние пол и других демографических факторов на продуктивность разработчиков.
В-третьих, влияние исследования продуктивности в разработке ПО можно улучшить с помощью многомерного набора метрик и инструментов, проверенных с помощью эмпирических исследований и триангуляции.
В-четвёртых, если исследователи могут посчитать затраты на изменение факторов, влияющих на продуктивность, компании смогут принимать более продуманные инвестиционные решения.
4.8. Риски
При интерпретации результатов этого исследования нужно учитывать несколько рисков для его достоверности.
4.8.1. Риски для достоверности данных
Во-первых, мы рассказали только об одном измерении — оценке своей продуктивности. Есть и другие измерения, в том числе объективные меры, например, количество строк кода, написанных за день, этот подход используют в Facebook [38]. Как мы указывали в разделе 3.1, все метрики продуктивности имеют недостатки, в том числе оценка своей продуктивности. К примеру, разработчики могут слишком легкомысленно оценивать свою продуктивность, либо искусственно завышать свою оценку из-за предвзятости в обществе [39]. Несмотря на эти недостатки, коллектив под руководством Зеленски (Zelenski) опирается на предыдущие работы, чтобы аргументировать обоснованность оценки своей продуктивности [40], которая использована и в этой статье.
Во-вторых, мы оценивали свою продуктивность с помощью одного вопроса, который вряд ли охватывает весь спектр продуктивности разработчиков. Например, вопрос сосредоточен на частоте и интенсивности, но не учитывает качество. Мы также не просили респондентов ограничивать свои ответы определённым временным промежутком, поэтому некоторые участники могли отвечать на основе своего опыта за последнюю неделю, в том время как другие оценивали свой опыт за последний год. В ретроспективе исследование должно оперировать фиксированным временным промежутком.
В-третьих, из-за ограниченности количества вопросов мы опирались лишь на те факторы, чтобы исследованы в предыдущих работах. Выбранные нами 48 вопросов могли не охватывать все аспекты поведения, влияющего на продуктивность. Или же выбранные нами факторы могли быть слишком общими в определённых случаях. К примеру, в ретроспективе фактор, касающийся лучших «инструментов и подходов» (F14) мог бы оказаться более действенным, если бы мы отделили инструменты от методик.
4.8.2. Внутренние риски для достоверности
В-четвёртых, как мы упоминали в разделе 3.8, мы опирались на предыдущие работы при установлении причинно-следственных связей между факторами и продуктивностью, однако сила доказательств связей может варьироваться. Может оказаться, что какие-то факторы влияют на оценку своей продуктивности лишь опосредовано, через другие факторы, или связь их вообще имеет обратную направленность. Например, вполне вероятно, что главный фактор продуктивности, повышенный энтузиазм в работе (F1), на самом деле может быть вызван повышением продуктивности.
4.8.3. Внешние риски для достоверности
В-пятых, несмотря на то, что мы исследовали три достаточно разные компании, обобщаемость с другими типами компаний, с другими организациями и другими типами работников умственного труда ограничена. В этой работе мы выбрали аналитиков в качестве представителей неразработчиков, но в эту категорию вошли несколько типов работников умственного труда — врачи, архитекторы и юристы. Другим риском для достоверности является смещение из-за отсутствия ответов: люди, которые ответили на анкеты, были выбраны самостоятельно.
В-шестых, мы проанализировали каждый фактор продуктивности в отдельности, но многие факторы могут сопутствовать друг другу. Это проблема не анализа, а применимости результатов. Если факторы созависимы, то изменение одного может неблагоприятно повлиять на другой.
4.8.4. Риски для конструктивной достоверности
В-седьмых, при создании этого исследования нас беспокоила возможность, что респонденты смогут распознать методику нашего анализа и не отвечать правдиво. Мы постарались снизить эту вероятность, отделив вопрос продуктивности от её факторов, но респонденты, возможно, смогли сделать вывод о нашей методике анализа.
Наконец, мы перефразировали некоторые вопросы, чтобы адаптировать исследование под аналитиков, что могло нежелательным образом поменять значение вопросов. Следовательно, различия между разработчиками и аналитиками могли возникнуть из-за различия в вопросах, а не в профессии.
5. Связанные работы
Многие исследователи изучали отдельные факторы продуктивности разработчиков ПО. Например, Мозер (Moser) и Нирштраз (Nierstrasz) проанализировали 36 проектов разработки ПО и исследовали возможность влияния объектно-ориентированных технологий на повышение продуктивности разработчиков [41].
Другой пример — исследование ДеМарко (DeMarco) и Листером (Lister) 166 программистов из 35 организаций, выполнявших однодневное упражнение по программированию. Авторы выяснили, что рабочее место и организация связаны с продуктивностью [42].
Третий пример — лабораторный эксперимент Керстена (Kersten) и Мёрфи (Murphy) с участием 16 разработчиков. Оказалось, что те, кто использовали инструмент для сосредоточенности на задаче, были гораздо продуктивнее остальных [43].
Кроме того, систематизированный анализ Вагнера и Руэ даёт хорошее представление о связи индивидуальных факторов и продуктивности [14]. Коллектив под руководством Майер предложил ещё более свежий анализ обзор факторов продуктивности [3]. В целом, наша работа базируется на этих исследованиях отдельных факторов с более широким изучением их разнообразия.
В систематизированном обзоре Петерсена (Petersen) говорится, что в семи работах численно оцениваются факторы, позволяющие прогнозировать продуктивность разработчиков ПО [44]. В каждой работе для прогнозирования используются численные методы, обычно это регрессия, которую мы тоже использовали в своём исследовании. Наиболее распространённые факторы связаны с размером проекта, а 6 из 7 факторов явно сформулированы на основе драйверов продуктивности COCOMO II ([6], [27], [28], [29], [30], [31]). В самой сложной модели прогнозирования в исследовании Петерсена используется 16 факторов [6].
У нашей работы два основных отличия. Во-первых, по сравнению с предыдущими работами мы оцениваем больше факторов (48), а их разнообразие шире. Мы подбирали факторы, опираясь на промышленную и организационную психологию. Во-вторых, у нас был иной объект для анализа: предыдущие исследователи изучали, что может прогнозировать продуктивность в рамках проекта, а нас интересовала личная продуктивность людей.
Помимо разработки ПО в предыдущих работах сравнивались факторы, позволяющие прогнозировать продуктивность и в других профессиях, в частности, в сфере промышленной и организационной психологии. Хотя такие исследования были посвящены продуктивности на уровне компании [45] и физическому труду, например, производству [46], наиболее близким направлением является продуктивность работников умственного труда. То есть людей, активно использующих в работе знания и информацию, обычно с применением компьютера [47]. Сравнение факторов для таких профессий представлено в двух основных работах. Первая — исследование коллектива под руководством Палвалин, посвящённое 38 факторам, которые в предыдущих исследованиях были сопоставлены с продуктивностью. Эти факторы охватывают физическое, виртуальное и социальное рабочее пространство, личные рабочие подходы и благополучие на работе [4]. Вторая работа — исследование Хернаусом и Микуличем 512 работников умственного труда. Авторы изучили 14 факторов, разбитых на три категории [9]. Мы опирались на обе эти работы при подготовке нашего исследования (раздел 3.2).
Однако в исследованиях, посвящённых сравнению факторов продуктивности для работников умственного труда, не уделялось внимания разработчикам ПО. На то есть две основные причины. Во-первых, неясно, в какой степени полученные общие результаты проецируются на разработчиков. Во-вторых, подобные исследования обычно абстрагированы от характерных для разработчиков факторов, например, повторного использования ПО и сложности кодовой базы [48]. Поэтому в литературе существует пробел в понимании факторов, позволяющих прогнозировать продуктивность разработчиков. Заполнение этого пробела имеет практическое значение. Мы создали три исследовательские группы в трёх компаниях ради повышения продуктивности. Заполнение упомянутого пробела в знаниях помогает нашим группам в исследованиях, а компаниям — в инвестировании в продуктивность разработчиков.
6. Заключение
На продуктивность разработчиков влияет много факторов, но у организаций ограничены ресурсы, которые можно направить на повышение продуктивности. Мы создали и провели исследование в трёх компаниях, чтобы ранжировать и сравнить разные факторы. Разработчики и руководители могут использовать наши результаты для приоритизации своих усилий. Попросту говоря, в предыдущих работах было предложено много способов повышения продуктивности разработчиков ПО, а мы предложили, как можно приоритизировать эти способы.

Блок вопросов
Что делает разработчика продуктивным?
Это одностраничное анонимное исследование займёт у вас 15 минут и поможет нам лучше понять, что влияет на продуктивность разработчиков. Пожалуйста, отвечайте открыто и честно.
В исследовании будут вопросы о вас, вашем проекте и вашем ПО. Пожалуйста, помните:
Моё ПО относится к основному ПО, которое вы разрабатываете в ABB, в том числе продуктам и инфраструктуре. Если вы работаете над разными программами, то отвечайте только по основной из них.
Мой проект относится к команде, с которой вы создаёте ПО. На относящиеся к этой сфере вопросы отвечайте касательно других разработчиков ПО в ABB.
В некоторых вопросах затрагиваются потенциально чувствительные темы. Заполняйте ответы так, чтобы никто не мог подсмотреть из-за плеча, и очистите браузерную историю и куки после заполнения анкеты.
Пожалуйста, оцените степень своего согласия со следующими утверждениями.
Список вопросов из исследования





Эти вопросы созданы для всесторонней оценки факторов, которые могут влиять на продуктивность. Мы что-нибудь упустили?
Пол (по желанию)
Ваша должность? (по желанию)
В каком году вы пришли в ABB?
Дополнительные материалы
Отмеченные респондентами факторы продуктивности
В этом разделе мы перечисляем факторы, описанные респондентами в ответах на открытый вопрос. Сначала опишем несколько новых факторов, а затем приведём описания факторов, относящихся к уже имевшимся в исследовании. Мы дополнили комментарии респондентов кодами с использованием наших факторов. Здесь мы не обсуждаем и не оцениваем ответы людей, не дополняем уже имеющиеся описания наших факторов.
Новые факторы
В комментариях было поднято 4 темы, не отражённые в нашем исследовании. В шести ответах были подняты темы смешанной команды проекта, в частности, соотношение руководителей и разработчиков; наличия достаточного количества сотрудников в проекте; а также позволяет ли руководство поддерживать сильное владение продуктом. Один респондент отметил влияние на продуктивность типа ПО (серверное, клиентское, мобильное и т.д.). Другой отметил влияние физиологических факторов, таких как количество часов сна. Ещё один упомянул возможности личностного роста.
Имеющиеся факторы
F1. Пять респондентов отметили факторы, связанные с энтузиазмом в работе: двое упомянули рабочую мотивацию и признание, один — мораль, ещё один — удручающее офисное здание.
F3. Четверо респондентов отметили факторы, связанные с автономностью в выборе рабочих методов. Один упомянул автономность на уровне команды, другой — о политике, мешающей использовать хорошую open source-систему, третий — о принятых в компании приоритетах, ограничивающих применение в командах определённых методик.
F4. Один респондент отметил автономность в планировании рабочего времени, которая ограничивается приоритетами, диктуемыми потребностью в продвижении по службе.
F5. Три респондента отметили компетентность руководства. Один упомянул руководство с последовательной стратегией, второй — конфликтующие приоритеты, спущенные руководством, третий — управление продуктивностью сотрудников.
F6. Восемь респондентов отметили предоставление точной информации. Трое упомянули межкомандное взаимодействие через документацию (и другие каналы), а двое — чёткую определённость целей и планов команды.
F7. Двое респондентов отметили позитивные чувства по отношению к коллегам в свете сплочения команды и всего коллектива.
F8. Один респондент отметил автономность в выполнении работы: политика компании диктует, какие ресурсы можно использовать.
F9. Один респондент отметил разрешение конфликтов, указав, что личные привычки коллег по команде противоречат социальным нормам.
F10. Четыре респондента отметили компетентность разработчиков. Один упомянул сложности в понимании кода, другой — владение предметной областью, третий — серьёзность отношения к тестированию.
F11. Один респондент отметил обратную связь о рабочей продуктивности: получение признания от коллег и руководства, продвижение по службе.
F12. Один респондент отметил сложность реализации ПО «из моего мозга в отгружаемый продукт».
F13. Двое респондентов отметили разнообразие задач, в частности, перехват заданий от имени своей команды и переключение контекста.
F14.Четыре респондента отметили компетентность людей, вырабатывающих требования и архитектуру. Один упомянул недостаточное внимание к проблемам, другой — читабельность архитектурных документов, третий — качество проектных планов, четвёртый — наличие «адекватной поддержки при выработке требований».
F15. Тридцать два респондента отметили использование лучших инструментов и подходов. Двенадцать упомянули производительность инструментов, особенно проблемы со скоростью и задержками при сборке и тестировании. Пять человек упомянули доступные функции, трое — проблемы с совместимостью и миграцией, двое — что даже самый лучший доступный инструмент может не удовлетворять потребностям. В других комментариях по инструментам и подходом упоминался уровень автоматизации, предлагаемый инструментами; специализированные отладчики и симуляторы; Agile-подходы; flaky-тесты и соответствующие инструменты; инструменты, хорошо работающие удалённо; выбор языков программирования; устаревшие инструменты; отделение личных предпочтений в инструментарии от принятых в компании.
F16. Девятнадцать респондентов отметили адекватную передачу знаний между людьми. Девять человек упомянули сложности коммуницирования с другими командами: трое — согласование целей между командами, один — согласование целей внутри большой команды, другой — достижение соглашения между командами. Двое отметили трудности согласования работы в международной или разбросанной по часовым поясам команде. Ещё двое отметили необходимость опираться на документацию других команд. Двое прокомментировали длительность проведения анализа кода. Ещё двое упомянули осведомлённость о рабочих объектах товарищей по команде. Один упомянул поиск нужного человека, другой — задержки во взаимодействии, третий — коммуницирование между инженерами и специалистами в предметной области. Наконец, один упомянул важность прояснить, какие каналы связи лучше использовать в тех или иных ситуациях.
F18. Двое респондентов отметили подходы к проведению встреч, один упомянул, что эффективность встреч зависит от доступности переговорных комнат.
F19. Двадцать четыре респондента отметили отрывы и отвлечения от работы. Десять упомянули шумное окружение, семь указали, что открытые офисы снижают продуктивность. Четверо упомянули сложности с многозадачностью и переключением контекста. Ещё четверо сообщили о необходимости сосредоточиться либо на основной работе, либо на «необязательных» задачах вроде проведения собеседований. Двое упомянули сложности с сосредоточенностью при поездках на работу и обратно.
F25. Один респондент отметил повторное использование кода, указав, что API из 2-3 строк повышают сложность при минимальном вкладе в уменьшение дублирования.
F26. Один респондент отметил опыт работы с программной платформой, указав, что проблемы усугубляются, когда разработчик переключается между проектами.
F27. Трое респондентов отметили программную архитектуру и уменьшение рисков. Один указал: «насколько хорошо известна архитектура продукта, насколько она взаимосвязана и как поддерживает людей, знающих свои роли и способных сосредоточиться, знающих свои обязанности и ограничения, а также чем они владеют». Другой отметил, что архитектура за счёт модульности может способствовать обмену между программными компонентами. Третий предположил, что архитектура должна соответствовать структуре организации.
F32. Четверо респондентов отметили необходимость в переключении контекста. Двое упомянули, что переключение необходимо при переходе между проектами. Один пояснил, что необходимость в переключении контекста отличается от удовольствия от переключения. Другой упомянул, что «проекты по повышению продуктивности» сами по себе могут снижать продуктивность.
F34. Пять респондентов отметили жёсткие сроки. Один указал, что это способствует росту технического долга, другой — что такие дедлайны могут приводить к бесполезной трате ресурсов.
F42. Три респондента отметили ограничения ПО. Двое указали на ограничения в приватности, один — на критические ограничения в безопасности.
F44. Одиннадцать респондентов отметили сложность ПО. Двое упомянули особую сложность устаревшего кода, двое — технический долг, и каждый отметил версионирование, сопровождение ПО и
понимание кода.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.786969 0.111805 24.927 < 0.0000000000000002 ***
log(lines_changed + 1) 0.045189 0.009296 4.861 0.00000122 ***
level -0.050649 0.015833 -3.199 0.00139 **
job_codeENG_TYPE2 0.194108 0.172096 1.128 0.25944
job_codeENG_TYPE3 0.034189 0.076718 0.446 0.65589
job_codeENG_TYPE4 -0.185930 0.084484 -2.201 0.02782 *
job_codeENG_TYPE5 -0.375294 0.085896 -4.369 0.00001285 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.8882 on 3388 degrees of freedom
Multiple R-squared: 0.01874, Adjusted R-squared: 0.017
F-statistic: 10.78 on 6 and 3388 DF, p-value: 0.000000000006508
Рис. 5: Модель 1: полные результаты линейной регрессии
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.74335 0.09706 28.265 < 0.0000000000000002
log(changelists_created + 1) 0.11220 0.01608 6.977 0.00000000000362
level -0.04999 0.01574 -3.176 0.00151
job_codeENG_TYPE2 0.27044 0.17209 1.571 0.11616
job_codeENG_TYPE3 0.02451 0.07644 0.321 0.74847
job_codeENG_TYPE4 -0.21640 0.08411 -2.573 0.01013
job_codeENG_TYPE5 -0.40194 0.08559 -4.696 0.00000275538534
(Intercept) ***
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 *
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3388 degrees of freedom
Multiple R-squared: 0.02589, Adjusted R-squared: 0.02416
F-statistic: 15.01 on 6 and 3388 DF, p-value: < 0.00000000000000022
Рис. 6: Модель 2: полные результаты линейной регрессии
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.79676 0.11141 25.102 < 0.0000000000000002
log(lines_changed + 1) -0.01462 0.01498 -0.976 0.32897
log(changelists_created + 1) 0.13215 0.02600 5.082 0.000000394
level -0.05099 0.01578 -3.233 0.00124
job_codeENG_TYPE2 0.27767 0.17226 1.612 0.10706
job_codeENG_TYPE3 0.02226 0.07647 0.291 0.77102
job_codeENG_TYPE4 -0.22446 0.08452 -2.656 0.00795
job_codeENG_TYPE5 -0.40819 0.08583 -4.756 0.000002057
(Intercept) ***
log(lines_changed + 1)
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 **
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3387 degrees of freedom
Multiple R-squared: 0.02616, Adjusted R-squared: 0.02415
F-statistic: 13 on 7 and 3387 DF, p-value: < 0.00000000000000022
Рис. 7: Модель 3: полные результаты линейной регрессии.
Список литературы
[1] R. S. Nickerson, “Confirmation bias: A ubiquitous phenomenon in many guises.” Review of general psychology, vol. 2, no. 2, p. 175, 1998.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.



