
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

К современным IT-системам предъявляются очень жесткие требования — они должны быть доступны практически 24/7, чтобы выдерживать конкуренцию на рынке. Для обеспечения такой надежности и доступности существует особый подход — SRE, Site Reliability Engineering.
Меня зовут Иван Круглов, я работаю в компании Databricks и уже несколько лет занимаюсь построением и поддержкой сложных и крупных IT-систем. Хочу рассказать, что такое подход SRE, зачем он нужен, какие критерии надежности существуют и как их определять.
Что такое SRE
Все в команде: программисты, админы, тестировщики и системные инженеры, работают над одной системной целью — создавать продукт, который приносит пользу клиентам. Есть множество инструментов, подходов и принципов для достижения этой цели: Agile в управлении проектами, DevOps в построении инфраструктуры и взаимодействии и т.п.
Одним из таких подходов является SRE — Site Reliability Engineering. Его суть в том, что вся инфраструктура должна быть построена по определенным стандартам, которые обеспечивают ее максимальную надежность и доступность. При этом над инфраструктурой должна работать вся команда вместе, так что это история не только про технологии, но и про коммуникации внутри комманды.
SRE — тема не очень новая, впервые об этом подходе заговорили в 2016 году. Но сейчас в индустрии нет четкого определения этого понятия, поэтому я буду говорить о своем опыте, который я вынес из практики и чтения книг и материалов на эту тему.
Что входит в SRE
В моем видении SRE включает в себя три большие составляющие: культуру, технику организацию. Вот как схема выглядит полностью:
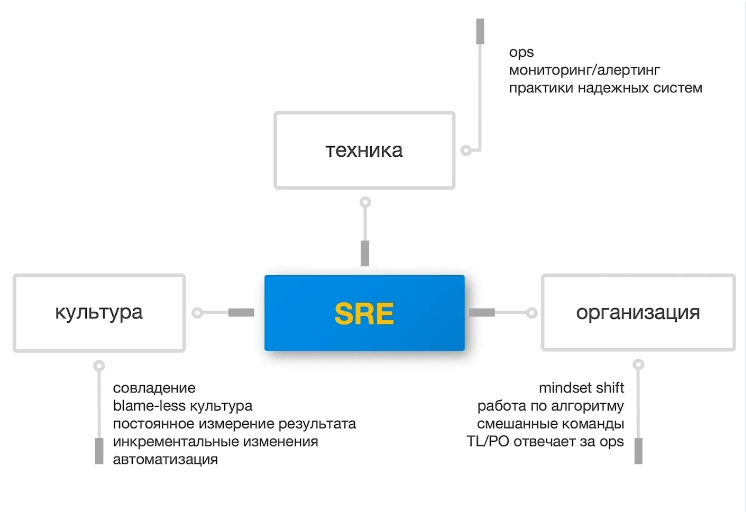
Поговорим про каждый аспект отдельно.
Культура. Это в первую очередь общие принципы работы — не технические, а именно управленческие. Для SRE они такие:
Совместное владение — все команды, которые работают над продуктом, трудятся вместе над одной целью.
Blame-less культура — при ошибке не ищут виноватых, а вместе разбираются над проблемой.
Постоянное измерение результатов. В SRE есть четкий алгоритм принятия решений на основе данных, а значит, эти данные следует постоянно замерять.
Инкрементальные изменения. Мы стараемся выкатывать все как можно быстрее, дробить работу на мелкие итерации и создавать стабильные промежуточные результаты. Это пришло из Agile.
Автоматизация. Все, что можно автоматизировать, нужно автоматизировать.
Техника. Это приемы и подходы по построению operation, поддержки, мониторинга и алертинга. Об этом много говорит Google в своих архитектурных докладах: например, о том, как построить высоконадежную систему из набора низконадежных систем.
Организация. Это чисто менеджерские и организационные вопросы, переосмысление и изменение принципов работы. В первую очередь здесь речь о совместной ответственности. Специалисты остаются, но нет отдельных людей, которые тестируют, занимаются Линуксом, отвечают за исправление конкретных ошибок. Все работают вместе, и каждый может помочь другим с их зоной ответственности. В этом и есть суть SRE.
Чем SRE отличается от DevOps
На мой взгляд, классический DevOps — это более общая вещь. По сути это agile like framework, который говорит, куда именно двигаться, но не объясняет, как и что для этого сделать. То есть «Давайте делать хорошее и тогда все будет хорошо».
Подход SRE вырос из DevOps, но он уже гораздо более конкретизированный. У нас есть четкий алгоритм действий, конкретные подходы и инструкции, описанные в конкретных книгах. То есть это как раз ответ на вопрос «как и что делать, чтобы все было хорошо».
Главные книги по теме SRE — это «Site Reliability Engineering. Надежность и безотказность как в Google» и «Site Reliability Workbook: практическое применение»
Конечно, SRE тоже не дает все ответы, а только их часть. Но эти ответы уже гораздо более конкретные и применимые на практике.
Главный аспект SRE, который мы рассмотрим — это SLO, Service Level Objective.
Что такое SLO
SLO задает целевой качества предоставляемой услуги. Это часть SLA — полного соглашения об уровне услуг, которые оказывают клиенту. Если SLA — это все соглашение, то SLO — конкретные измеримые характеристики. И это как раз те самые измерения, которые являются одним из аспектов SRE.
SLO позволяет определить, работает ли наша система так, как мы хотим. Помогает приоритизировать фичи в работе. И показывает, насколько мы в действительности соответствуем принципам SRE.
SLO — это инструмент data-driven приоритизации. У нас есть метрика, конкретные данные, и на их основе мы можем решать, что будем делать. Становится просто решить, чем конкретно в среднесрочной перспективе команда будет заниматься. Проблем по SLO нет — можно развивать новые фичи и двигать продукт. Проблемы есть — нужно бросить силы на их решение и повышать стабильность системы.
Как определять SLO на практике
SLO — это всегда про конкретные цифры. И их нельзя взять с потолка. Поскольку SRE — это про счастье и комфорт пользователей, целевое значение ключевых показателей должно быть таким, чтобы выше него пользователи были довольны, а ниже — жаловались и уходили. Это четкая граница, но как ее определить?
В первую очередь для этого нужно включить в процесс не только инженеров, но и клиентов. Лучший способ для этого — выписать не только те метрики, которые интересны вам, но и те, которые важны для пользователей. Например, вам важно, чтобы сервис не падал. А что важно клиенту? Может быть, время отклика? Или скорость работы? Узнайте это с помощью опросов.
Обычно «стандартно» SLO можно определить так — сервис должен работать быстро, бесперебойно и хранить и предоставлять достоверные данные. Но за таким кратким описанием кроется много вопросов. Попробуем их разобрать.
Что значит бесперебойно?
Бесперебойно — это работа в 100% случаев? Однозначно нет. Построить систему, которая работает вообще без сбоев, просто невозможно по нескольким причинам:
Всегда есть «последняя миля» — ноутбук пользователя, его интернет, электричество в розетке. И электричество на ваших серверах. Вы за это не отвечаете, но на работу вашего сервиса это влияет.
100% надежности не гарантирует идеальный клиентский опыт. Клиентам может быть нужно другое, и концентрируясь на надежности, вы это упустите.
Если вы построите на 100% надежную систему, вы уже не сможете ее изменить. Потому что любое изменение снизит надежность. А в нашем постоянно меняющемся мире это равносильно смерти сервиса.
Значит, от идеи построить систему с доступностью 100% мы отказываемся. Но сколько процентов тогда выставлять? Есть вот такая табличка:
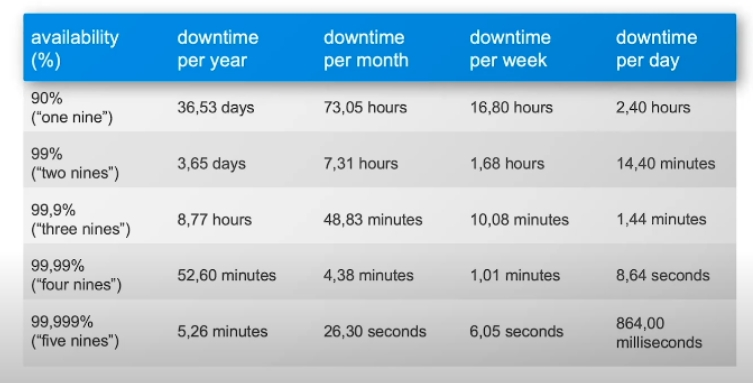
Здесь показано, что при доступности на одну девятку вы можете себе позволить 2,5 часа даунтайма в день, то есть 10% дневного времени сервис может быть недоступен. Три девятки — это 1,44 минуты, а 5 девяток — уже меньше, чем секунда. То есть при добавлении каждой девятки показатель вырастает очень сильно.
Теперь представим, что вам нужно что-то сделать, например, переключиться между репликами. С одной девяткой у вас есть на это 2,5 часа — можно все сделать руками. С тремя девятками у вас только 1 минута 44 секунды — уже точно понадобится скрипт. А все, что выше — это уже полная автоматизация.
Как на надежность влияет число микросервисов
Есть еще одна интересная вещь, о которой многие забывают. Сейчас принято все делать на микросервисах. Но чем больше у системы компонентов, тем сильнее падает ее надежность и доступность. Это можно наблюдать на графике:
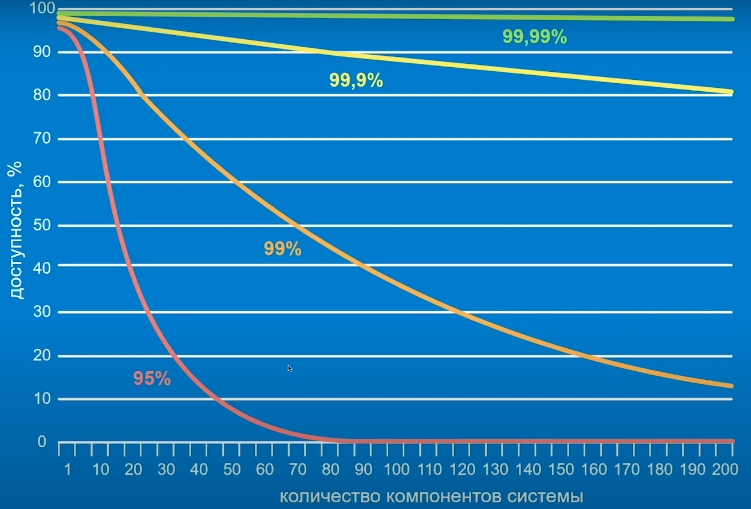
То есть, если у каждого компонента доступность 95% то у системы из 10 компонентов она будет уже 70%.И чтобы добиться трех девяток, нужно либо снижать количество компонентов, либо делать каждый сервис высокодоступным.
Какие цифры надежности обычно задают на практике
В своей практике я встречают с тремя, либо с тремя с половиной девятками. То есть надежностью на 99,9% или 99,95%. Четыре девятки тоже встречал — например, у нас в Booking это был сервис, который отвечал за хранение важных данных. Там нужна была доступность 99,99%.
Обычно чем более сервис зрелый и критичный, тем более высокая у него доступность. Две–две с половиной девятки тоже хорошее значение. Пять — огромная редкость, я такого не встречал.
Ответ за одну секунду — это быстро?
Здесь мы говорим о скорости работы. Нам важно понять, «быстро» — это как? Ответ зависит от того, что именно ожидают наши пользователи.
Например, на веб-сайте пользователь готов ждать загрузки страницы максимум пару секунд. После этого он либо уйдет, либо потеряет фокус, и конверсия в любом случае снизится. А вот подбора билетов на самолет пользователь готов ждать даже дольше 10 секунд, и для него это все равно будет быстро.
Плюс при оценке скорости отклика важно понимать, где именно мы ее оцениваем. Обычно у нас есть API, за ним стоит балансер нагрузки, например, Ingress, и уже за ним клиент. И время отклика везде будет разное:
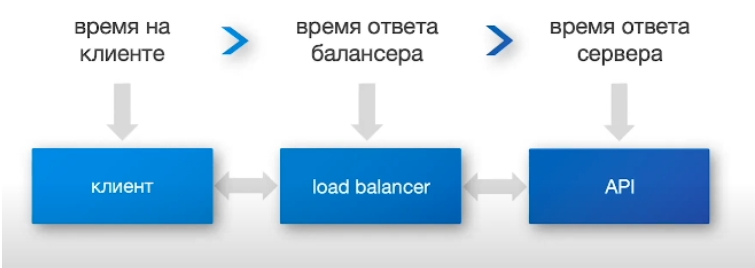
Поэтому то время ответа, которое вы видите на стороне сервера — далеко не показатель. Вам нужно попытаться «надеть тапки» пользователя и посмотреть на систему его глазами.
Для примера, случай из практики. Есть два графика:
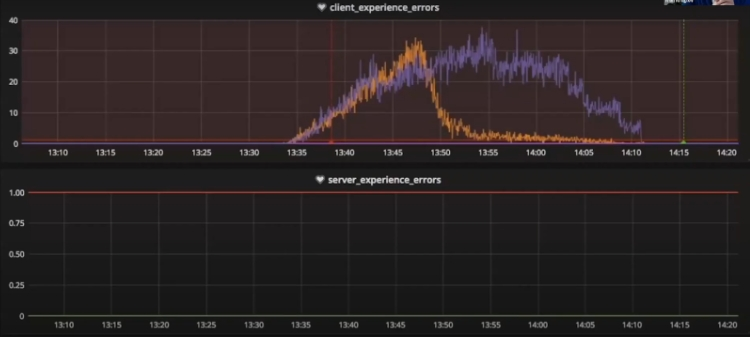
Сверху у нас клиентский опыт ошибок, снизу – серверный. Как видите, на сервере ошибок нет вообще, а вот у клиента их достаточно. И если бы мониторинга алертов на клиентской стороне не было, ошибок мы бы просто не заметили. Ведь на сервере все работает идеально.
Что делать с плохими данными
Представим, что пользователь прислал невалидный ID на сеанс. Или к примеру пытается забронировать в отеле место, которого не существует. Понятно, что хранить эти данные смысла нет, но как учитывать их в SLO?
Учитывать нужно те данные, которые когда-то были хорошими, а потом повредились. Мы ответственны за их поломку, и с этим нужно что-то делать.
Данные, которые невалидны изначально, учитывать не стоит. Если пользователь неправильно прочел спецификацию или что-то сделал не так, это не наша ошибка. И к SLO точно не относится.
Но из второго случая есть исключения. Мы иногда специально включали в метрики примеры как раз таких ошибок. Потому что они могут быть признаком проблем с документацией, гайденсом или юзабилити системы. Пользователь ошибается не потому, что он дурак, а потому что просто не понимает, как пользоваться системой. Он совершает ошибки, не получает желаемого — и в итоге становится несчастлив. Это противоречит SRE, а значит, может быть учтено в SLO для исправления.
Кратко: самое главное об SRE
SRE — это подход, который задает стандарты работы внутри команды для построения надежной, стабильной и высокодоступной инфраструктуры.
SRE объединяет конкретные технологии, особую культуру работы и организационные процессы.
В отличие от DevOps, SRE предлагает не только общее направление, но и конкретные инструменты для достижения целей.
Для SRE очень важно SLO — конкретные измеримые характеристики доступности системы.
Обычно «стандартно» SLO можно определить так — сервис должен работать быстро, бесперебойно и хранить и предоставлять достоверные данные.
9 июня в 19:00 бесплатный вебинар по SRE
На вебинаре:
Поговорим, что такое SRE и с чем его едят, в чем ценность.
Нужны ли эти внедрения вам и вашей компании, каких результатов можно достичь, а каких - нет.
Обсудим опыт внедрения SRE в компаниях участников прошлых интенсивов, поговорим про показатели.
Ответим на ваши вопросы и разыграем 5 бесплатных мест на интенсив.
В результате вебинара:
Инженеры, разработчики: поймут как этот интенсив встраивается в их карьерный путь, что важно для компании и менеджмента, и как продать идею внедрения SRE в своем отделе / компании.
Представили компании: узнают какой профит получит компания, если отправит к нам на курс 2-3, 10 или 50 человек.
Зарегистрироваться на вебинар.
Курс по SRE.




