
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
При создании проектов в машинном обучении зачастую сложнее всего бывает начать работу. Какой должна быть структура репозитория? Каким стандартам следовать? Смогут ли ваши коллеги воспроизвести результаты экспериментов? Автор материала делится шаблоном проекта, наработанным за годы изучения науки о данных, а наш флагманский курс по Data Science стартует 25 января.
Вместо попыток найти идеальную структуру репозитория самостоятельно, не лучше ли иметь шаблон, с которого можно было бы начать?
Поэтому я создала шаблон data-science-template, где обобщены лучшие практики, о которых я узнала за годы работы над структурированием проектов в области науки о данных.
Этот шаблон — итог моего многолетнего поиска наилучшей структуры проекта в науке о данных. Он позволит вам:
- создать читаемую структуру проекта;
- эффективно управлять зависимостями в проекте;
- создавать короткие и читаемые команды для повторяемых задач;
- перезапускать только модифицированные компоненты конвейера данных;
- Наблюдать и автоматизировать код;
- включить подсказки типов во время исполнения кода;
- проверять проблемы в коде перед фиксацией изменений (перед коммитом);
- автоматически документировать код;
- автоматически запускать тесты при коммите.
Инструменты, используемые в этом шаблоне
Это легковесный шаблон, в нём используются только инструменты, которые могут быть универсальными для разных случаев:
- Poetry: управление зависимостями Python.
- Prefect: упорядочение и просмотр конвейера данных.
- Pydantic: валидация данных с помощью аннотаций типа в Python.
- pre-commit plugins: форматирование, тестирование и документирование кода согласно лучшим практикам.
- Makefile: автоматизация повторяемых задач короткими командами.
- GitHub Actions: автоматизация конвейера непрерывной интеграции и непрерывного развёртывания приложений (CI/CD).
- pdoc: автоматическое документирование для API вашего проекта.
Начинаем
Начните с установки Cookiecutter для загрузки шаблона:
pip install cookiecutterCоздайте проект на основе шаблона:
cookiecutter https://github.com/khuyentran1401/data-science-templateИ опробуйте его согласно этим инструкциям.
Далее некоторые важные фичи шаблона обсудим в деталях.
Читаемая структура
Структура проекта на основе этого шаблона стандартизирована и проста для понимания:

Вот краткое описание ролей этих файлов:
├── data
│ ├── final # данные после тренировки модели
│ ├── processed # данные после обработки
│ ├── raw # сырые данные
├── docs # документация проекта
├── .flake8 # конфигурация инструмента форматирования
├── .gitignore # игнорируемые при коммите в Git файлы
├── Makefile # хранит команды настройки среды
├── models # хранит модели
├── notebooks # хранит интерактивные блокноты
├── .pre-commit-config.yaml # конфигурация pre-commit
├── pyproject.toml # зависимости poetry
├── README.md # описание проекта
├── src # хранит исходники
│ ├── __init__.py # делает src модулем Python
│ ├── config.py # хранит конфигурации
│ ├── process.py # обрабатывает данные перед обучением модели
│ ├── run_notebook.py # выполняет блокноты
│ └── train_model.py # тренирует модель
└── tests # хранит тесты
├── __init__.py # делает tests модулем Python
├── test_process.py # тестирует функции в process.py
└── test_train_model.py # тестирует функции в train_model.py Эффективное управление зависимостями
Poetry — это инструмент управления зависимостями в Python, альтернатива pip. С его помощью можно:
- разделить основные зависимости и подзависимости на два отдельных файла (вместо того, чтобы хранить все зависимости в requirements.txt)
- удалять все неиспользуемые подзависимости при удалении библиотеки
- избежать установки новых пакетов, которые конфликтуют с имеющимися
- упаковывать свой проект в несколько строк кода
Инструкции по установке Poetry можно найти здесь.
Создание кратких команд для повторяемых задач
Makefile позволяет создавать короткие и читаемые команды для задач. Если вы не знакомы с Makefile, посмотрите это краткое руководствоl.
Makefile можно использовать для автоматизации таких задач, как настройка окружения:
initialize_git:
@echo "Initializing git..."
git init
install:
@echo "Installing..."
poetry install
poetry run pre-commit install
activate:
@echo "Activating virtual environment"
poetry shell
download_data:
@echo "Downloading data..."
wget https://gist.githubusercontent.com/khuyentran1401/a1abde0a7d27d31c7dd08f34a2c29d8f/raw/da2b0f2c9743e102b9dfa6cd75e94708d01640c9/Iris.csv -O data/raw/iris.csv
setup: initialize_git install download_dataТеперь, когда люди захотят настроить среду для ваших проектов, им достаточно будет выполнить:
make setup
make activateИ последовательность команд будет исполнена!

Перезапуск только изменённых элементов конвейера
make полезен, если хочется запускать задачу всякий раз, когда меняются её зависимости.
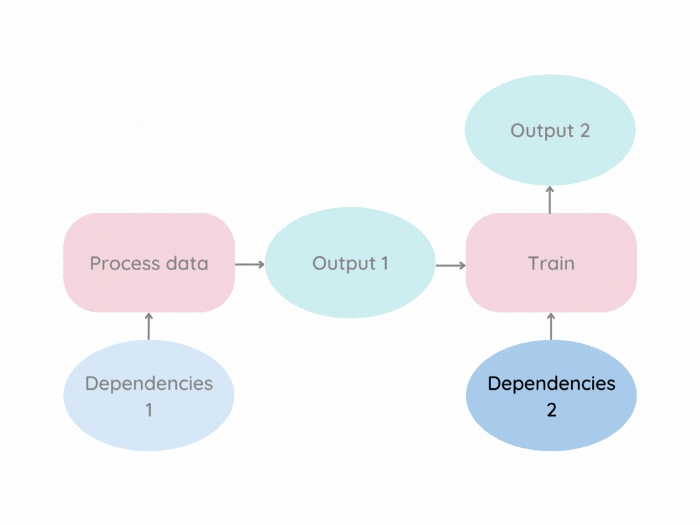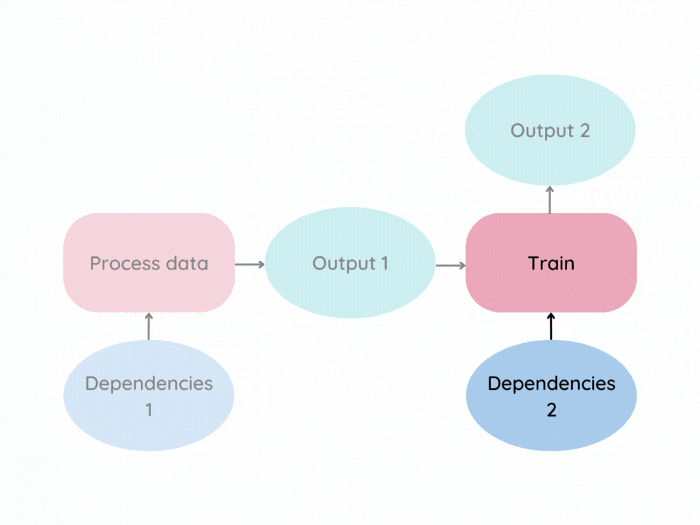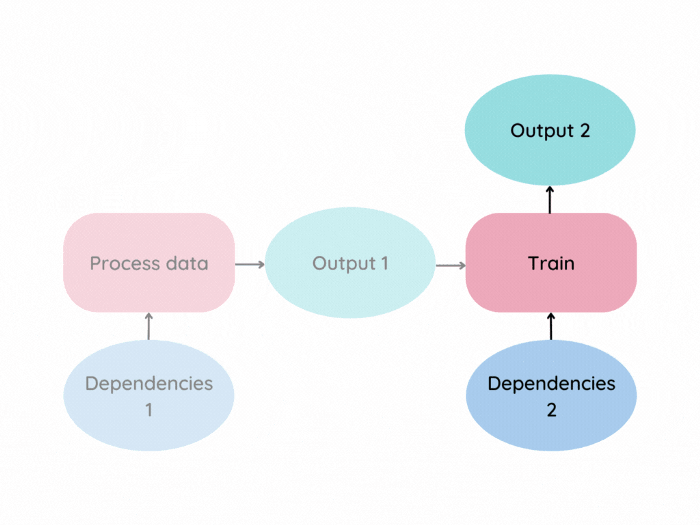
В качестве примера изобразим связь файлов в Makefile:

data/processed/xy.pkl: data/raw src/process.py
@echo "Processing data..."
python src/process.py
models/svc.pkl: data/processed/xy.pkl src/train_model.py
@echo "Training model..."
python src/train_model.py
pipeline: data/processed/xy.pkl models/svc.pkДля создания файла models/svc.pkl можно выполнить:
make models/svc.pklПоскольку data/processed/xy.pkl и src/train_model.py являются предварительными требованиями для цели models/svc.pkl, make запускает рецепты создания и data/processed/xy.pkl, и models/svc.pkl.
Processing data...
python src/process.py
Training model...
python src/train_model.pyЕсли в предварительном условии (prerequisite) models/svc.pkl нет изменений, make пропустит обновление models/svc.pkl.
Таким образом make поможет избежать потери времени на запуск ненужных задач.
Наблюдение и автоматизация кода
В этом шаблоне используется Prefect, чтобы наблюдать запуски из Perfect UI:

Помимо прочего, Prefect может помочь:
- повторить попытку, когда ваш код не работает;
- запланировать выполнение кода;
- отправлять уведомления о сбоях в работе потока (flow).
Вы можете получить доступ к этим функциям, просто превратив свою функцию в поток Prefect.
from prefect import flow
@flow
def process(
location: Location = Location(),
config: ProcessConfig = ProcessConfig(),
):
...Подсказки типа во время выполнения программы
Pydantic — библиотека Python для валидации данных с привлечением аннотаций типов.
Модели Pydantic устанавливают типы данных для параметров потока и проверяют их значения при выполнении потока.

Если значение поля не соответствует аннотации типа, вы получите ошибку в рантайме:
process(config=ProcessConfig(test_size='a'))pydantic.error_wrappers.ValidationError: 1 validation error for ProcessConfig
test_size
value is not a valid float (type=type_error.float)Все модели Pydantic хранятся в файле src/config.py.
Выявление проблем кода до коммита
Перед коммитом в Git необходимо убедиться, что код:
- проходит модульные тесты (unit tests)
- соответствует лучшим практикам и руководствам по стилю
Однако ручная проверка этих критериев может утомить. pre-commit — фреймворк, который выявляет проблемы в коде до коммита.
Вы можете добавлять различные плагины в конвейер pre-commit. Перед коммитом файлы будут проверены на соответствие стандартам соответствующих инструментов — это black, flake, isort и iterrogate. Если проверки не пройдут, код не будет отправлен в коммит.

Все плагины в этом шаблоне можно найти в этом файле

Автоматическое документирование кода
Дата-сайентисты при работе над проектом часто взаимодействуют с другими членами команды. Поэтому очень важно создать хорошую документацию. Чтобы создать документацию API на основе docstrings ваших файлов и объектов Python, выполните команду:
make docs_viewВывод:
Save the output to docs...
pdoc src --http localhost:8080
Starting pdoc server on localhost:8080
pdoc server ready at http://localhost:8080Теперь документацию можно увидеть по адресу http://localhost:8080:

Автоматически запускаемые тесты
GitHub Actions автоматизируют интеграцию приложения, ускоряют сборку, тестирование и развертывание кода.
Тесты из папки tests при создании коммита выполняются автоматически.

Поздравляем! Вы только что узнали, как пользоваться шаблоном для создания проекта ML, который можно использовать вторично и редактировать. Этот шаблон задуман как гибкий. Не стесняйтесь корректировать проект в соответствии с вашими потребностями.

- Профессия Data Scientist (24 месяца)
- Профессия Fullstack-разработчик на Python (16 месяцев)
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия «Белый хакер»
А также
- Курс по DevOps
- Все курсы




