
Вступление
На мой скромный взгляд, Kubernetes используют так или иначе сейчас примерно все, но и задачи решаются совсем разные. Я расскажу про наши требования и разработанные именно под них решения. По теме GitOps я нахожу не так много статей и обсуждений на Хабре, в отличие от англоязычных источников, поэтому будет интересно услышать мнение тех, кто применял подход на своей практике.
Наша задача.
На тарелке подано: ряд Kubernetes кластеров, часть работающих в self-hosted режиме на виртуальных машинах VMWare, а часть как инфраструктура на базе Google Kubernetes Engine. Они объединены группами по определенным признакам. Признаки могут быть разными:
среда: dev/stage/prod
запущенные проекты: есть ряд независимых групп приложений, которые запускаются в разных кластерах
назначение: внешние/внутренние сервисы
Также в связи со спецификой бизнеса, есть требование держать безопасность кластеров на должном уровне, отсюда необходимость централизованно управлять сетевыми политиками, политиками безопасностями подов, RBAC и прочим.
Поиски решения.
Когда количество кластеров выросло до 20+, стало понятно, что требуется единый механизм управления общими ресурсами. Естественным образом напрашивается GitOps управление, и тем же естественным образом на поверхность вышло сравнение двух закрепившихся в широком пользовании инструментов ArgoCD и FluxCD. Сравнительных статей по этому поводу есть масса, я лишь скажу, что наш выбор пал на Flux как более простой и удобный инструмент, позволяющий дедуплицировать конфигурацию кластеров. ArgoCD выглядел интересно с точки зрения отслеживания процесса деплоя приложений, но показался менее удобным в плане управления множеством кластеров в своей исходной задумке. С использованием Helm Operator, а также с помощью Git submodules (об этом подробно позже), получилось выстроить модульный процесс наполнения K8S кластеров нужным содержимым. Далее расскажу на пальцах из каких элементов состоит решение.
Подготовка репозитория.
Раз мы решили управлять кластерами через Git, то первым шагом, ещё до создания кластера, идёт подготовка репозитория с нужным содержимым. Был создан шаблонный репозиторий, который можно использовать как базу. Разберу из чего он состоит:
1) Файл default-cluster-values.yaml - пожалуй, основной элемент в структуре, определяющий все значения, которые уникальны для данного кластера. Здесь определяются такие настройки как тип хостинга кластера, имя среды, регион, специфичные сетевые настройки, а также подсекциями настройки приложений, если они необходимы. Все эти значение в дальнейшем используются в устанавливаемых Helm чартах и влияют на конечную их конфигурацию. Нам было важно выделить все отличающиеся настройки в одно место для удобства пользования. Настройки в виде объекта ConfigMap попадают в кластер в неймспейс Flux и может использоваться дальше как набор добавочных значений для устанавливаемых Helm чартов.
Пример default-cluster-values.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: default-cluster-values
namespace: flux
data:
values.yaml: |
k8s_cluster_type: "gke" # Supported values for cluster type: "gke" or "self-hosted"
environment_name: "test"
region: "euwe1"
prometheus:
enabled: true # For some test clusters we may skip setting up monitoring
tainted_node_pool: true # Set to 'false' if there is no separate node pool dedicated to monitoring
replicas: 1 # Change to 2 for Production environments on GKE
retention: "30d"
storage_class: "standard" # "standard" or "pd-ssd"
storage_size: "50G" # Approximate rough calculation: 100 pods / 10 days = 5 GB
load_balancer_ip: "10.123.32.40" # use .40 of nodes IP range for GKE and .112 of MetalLB range for self-hosted
fluent_bit:
enabled: true # Optionally, GKE-only environments may have it set to 'false' and use Stackdriver only
graylog_ip: "10.123.43.205" # 10.123.43.205 for Staging and Production, Dev clusters have their separate Graylog instances
graylog_port: "12201" # 12201 for Dev and Staging, 12202 for Production
gelf_mode: "tcp" # We use "tcp" everywhere, but this could also be "udp" occasionally
metallb:
enabled: true # Only used with self-hosted clusters
addresses: "10.123.55.100-10.123.55.119" # The range of addresses dedicated to MetalLB for Kubernetes LoadBalancer service type allocations
nginx_ingress:
kind: "daemonset" # Defines how to deploy nginx ingress controller: deployment (basic) or daemonset (HA)
traffic_policy: "Local" # Defines externalTrafficPolicy value for nginx ingress controller service resources within the cluster
public:
enabled: true # To enable public facing ingresses
port: 31882 # We tend to use standard nodePorts, but leave it possible to modify it
whitelisted:
enabled: false # To enable whitelisted ingresses
port: 31883 # We tend to use standard nodePorts, but leave it possible to modify itПример HelmRelease объекта, использующего default-cluster-values:
apiVersion: helm.fluxcd.io/v1
kind: HelmRelease
metadata:
name: default-cluster-network-policies
namespace: flux # we put HelmRelease resources into flux namespace to make use of secretRef with Git credentials
spec:
releaseName: default-cluster-network-policies
targetNamespace: kube-system # the namespace where Helm chart gets deployed
chart:
git: "https://bitbucket.org/altenar/helm"
path: "security/default-cluster-network-policies"
version: "0.1.0"
secretRef:
name: flux-git-auth
valuesFrom:
- configMapKeyRef:
name: default-cluster-values2) Файл .gitmodule для указания, что можно выполнить git sumodules add и подключить любые репозитории-модули, которые добавят в кластер набор типовых приложений и настроек. Таким образом мы ставим prometheus для мониторинга, fluent-bit как сборщика логов, добавляем политики безопасности, правила для уведомлений, а также такой подход позволяет включить любое новое приложения для использования по умолчанию и развернуть его сразу на всех серверах. Здесь как раз отсылка к группам кластеров, объединенных по разным признакам. Каждый такой признак может быть отдельным репозиторием-подмодулем и быть добавленным только на подгруппу кластеров.
3) Пример добавления в кластер неймспейса. Мы придерживаемся структуры, что каждая папка на репозитории (если это не подключенный submodule) - это отдельный неймспейс, и нам нужно любой неймспейс создавать с определенным содержимым. Здесь хотел бы подсветить, что Flux имеет важную аннотацию, которую нужно осознанно использовать для тех неймспейсов, которые критически важны, чтобы случайным коммитом не удалить все содержимое:
annotations:
fluxcd.io/ignore: sync_only Эта аннотация указывает не удалять объект, если он пропал с репозитория, при включенной настройке "сборки мусора" (а у нас она включена везде по умолчанию).
Также в базовой структуре неймспейса идут сетевые политики. Для них был создан отдельный чарт default-namespace-network-policies и сгруппированы политики для основных нужд. Я могу просто перечислить настройки, и они будут понятны по своему смыслу:
Создавая неймспейс, нужно пройтись и выставить в true нужные значения для своего приложения.
values:
allow_namespace_traffic: false
allow_ingress_cluster_traffic: false
allow_egress_cluster_traffic: false
allow_ingress_private_traffic: false
allow_egress_private_traffic: false
allow_monitoring: false
allow_apiserver: false
allow_internet: false
allow_ingress_traffic: false
allow_egress_traffic: false
4) Два служебных файла .flux.yaml и kustomization.yaml. Они присутствует как "рабочий костыль", позволяющий использовать сабмодули, т.к. Flux не поддерживает их из коробки. Здесь можно сослаться на имеющееся обсуждение и можно упомянуть, что сабмодули уже поддерживаются следующим поколением Flux v2, который уверенными шагами идёт к полноценному релизу.
5) Конфигурация линтеров и pre-commit хуков для самопроверки синтаксиса манифестов.
6) И конечно README файл с подробным описанием как пользоваться GitOps.
Создание кластера
После того, как репозиторий с базовым набором содержимого кластера подготовлен, процесс создания заключается в следующих шагах:
Создание собственно самого кластера через Terraform: здесь для GKE используем штатный модуль, а для создания кластера на VMWare - самописный модуль, который включает в себя создание VMWare машин и разворачивания K8S кластера с помощью kubespray.
Установка связки Flux CD + Helm Operator через Terraform модуль, принимающий на вход только пароль для выделенного пользователя BitBucket и имя кластера, которое совпадает с именем репозитория.
/*
[Flux CD](https://fluxcd.io/) is installed in the deployed Kubernetes cluster(s) to manage all resources inside of it.
The repository can be found in [Kubernetes Bitbucket Project](https://bitbucket.org/altenar/workspace/projects/K8S) named by the cluster name.
Flux CD uses `altenar-azure-devops-bot-flux` BitBucket account for integration, and its app password should be provided for the setup.
*/
module "flux" {
source = "git@bitbucket.org:altenar/terraform-module-flux.git?ref=0.1.2"
flux_bot_password = var.flux_bot_password
k8s_cluster_name = var.cluster_name
}
(Здесь сразу оговорюсь, что в целях безопасности мы используем pull-only режим и Git пользователь идет на репозитории в режиме read-only. Прав на запись пользователь не имеет, и мы не пользуемся той частью функционала FluxCD, которая создает git коммиты.)
Далее, применив terraform apply и сходив за чашкой кофе, мы получаем созданный свежий кластер, подключенный к репозиторию с конфигурацией и сразу встроенный в нашу внутреннюю инфраструктуру со всеми нужными параметрами. И мы имеем возможность далее наполнять кластер как специфичными приложениями, нужными только ему, так и общими элементами через обновление репозиториев сабмодулей. Весь процесс проходит через git, а это значит, что изменения будут прозрачны и лишний раз просматриваться коллегами на этапе Pull Request.
Мониторинг
Такая система управления кластерам, конечно же, требует мониторинга, ибо все процессы происходят неявно и асинхронно. Собственно, Flux и Helm Operator имеют встроенные метрики и рекомендуемые формулы для мониторинга:
Flux CD monitoring
Helm Operator monitoring
Разумеется, мониторинг начинает работать только после первичного создания и наполнения кластера, поэтому самый первый шаг нужно будет внимательно сопроводить и убедиться, что кластер способен отправлять уведомления в нужные каналы.
Плюсы / минусы
Какие плюсы мы получаем от такой структуры:
Удобство и простота создания нового кластера. Да, здесь есть первичный барьер вхождения, когда нужно всю схему понять и принять. В самом сложном варианте она может выглядеть так:
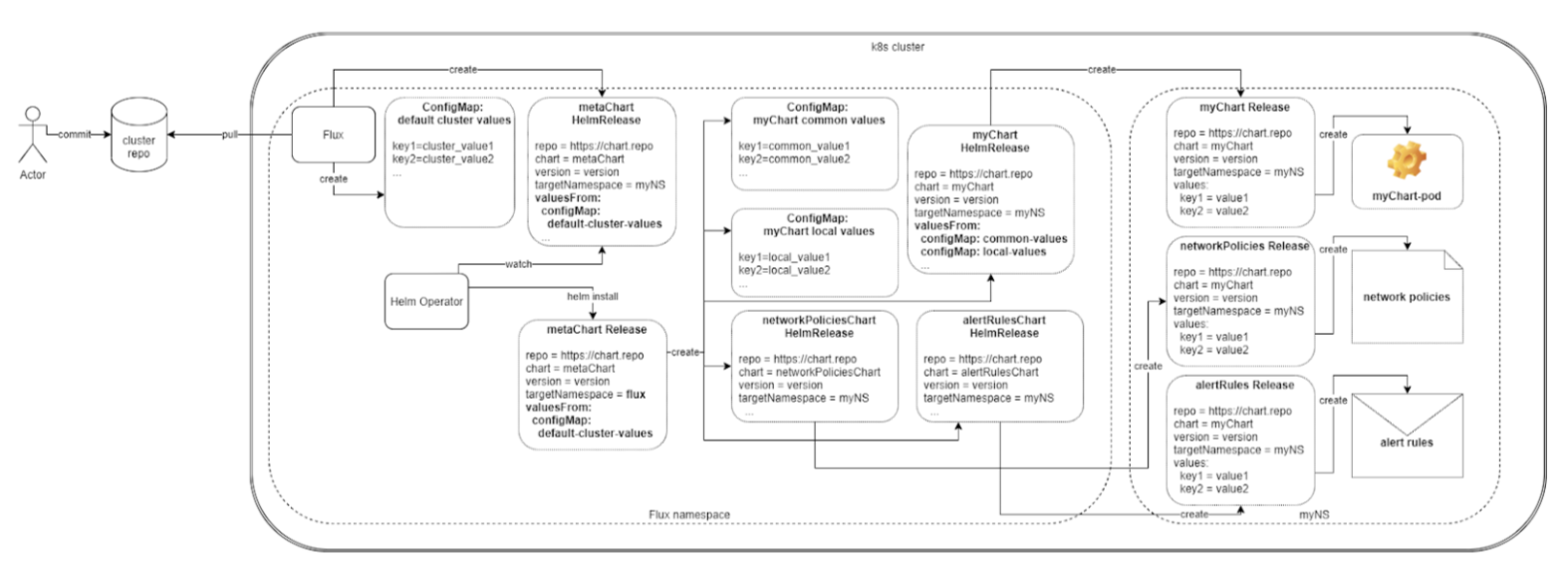
Но после этого процесс ускоряется и она в дальнейшем себя окупает. Также стоит упомянуть, что сильно упрощается и пересоздание кластера в случае выхода из строя. Инфраструктура как код в ее лучшем проявлении.
Очень просто централизованно обновлять стек. Допустим, захотели обновить версию Prometheus. Достаточно протестировать ее на выделенном дев кластере, понять, что новая версия ничего не ломает и не ухудшает производительность, и применить ее в репозиторий модуля, сразу обновив все кластера в своей инфраструктуре. Процесс отката, к слову, в данном случае, тоже является просто
git revertкоммита (разумеется, если откат поддерживается целевым Helm чартом).Очень удобно добавлять новые компоненты инфраструктуры.
Какие есть минусы или о чем нужно помнить, поддерживая такой подход:
За удобством скрывается и большая ответственность: нужно всегда понимать, что изменения в модули будут сразу прилетать на ряд кластеров, в том числе боевых, и быть полностью уверенными, что изменения не влекут проблем. Также нужно точно знать и быть уверенным, что в случае этих проблем, мы узнаем о них сразу посредствам рабочего мониторинга и будем готовы к откату.
Конкретно в нашем случае релизный цикл именно приложений использует CI/CD систему, которая не взаимосвязана с Flux. Поэтому нужно понимать, что не всё, что работает внутри кластера, присутствует в его репозитории.
Нет какой-либо явной возможности полностью запретить устанавливать что-либо в кластер, минуя Flux, при наличии прав доступа администратора. Здесь по-прежнему работает доверие к своим коллегам и настроенные политики (например, Falco), которые будут уведомлять о таких действиях.
Нужно понимать и быть готовыми к тому, что "живой дебаггинг" на кластере станет сложнее, любые изменения, скорее всего, будут в течение 5 минут откатываться и сбрасывать на состояние репозитория. Это в то же время и очень хорошо, мы решаем вопрос с конфигурационным дрейфом. Но и момент усложненного дебага тоже нужно понимать и подготовиться к нему.
Будущее
Разработчики FluxCD в данный момент очень сильно сподвигают всех пользователей мигрировать на новую версию, куда они внесли много доработок и переосмыслили GitOps Engine на фундаментальном уровне. Думаю, что v1 успешно показала, что решение рабочее, так что будем пробовать переходить на v2 и поделимся опытом уже после.
Фидбек
Хотелось бы узнать от других пользователей инфраструктур, построенных на множестве Kubernetes кластеров, как решаются подобные вопросы и были ли выбраны схожие или совсем другие решения.
Спасибо за внимание!



