
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Индексирование баз данных — это техника, повышающая скорость и эффективность запросов к базе данных. Она создаёт отдельную структуру данных, сопоставляющую значения в одном или нескольких столбцах таблицы с соответствующими местоположениями на физическом накопителе, что позволяет базе данных быстро находить строки по конкретному запросу без необходимости сканирования всей таблицы. Применяются разные типы индексов, однако они занимают пространство и должны обновляться при изменении данных. Важно тщательно продумывать стратегию индексирования базы данных и регулярно её оптимизировать.
Как базы данных создают индексы

Индексирование базы данных обычно выполняется при помощи алгоритма, определяющего, как должен создаваться и храниться индекс. Конкретный процесс создания индекса может варьироваться в зависимости от типа используемой системы базы данных, однако в целом общие этапы выглядят так:
- Определение столбца или столбцов в таблице базы данных, которые нужно индексировать. Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
- Выбор алгоритма индексирования, подходящего для типа индексируемых данных. Например, индексы в виде B-деревьев обычно используются для индексирования строковых или числовых данных, а полнотекстовые индексы — для индексирования текстовых данных.
- Применение алгоритма индексирования к выбранным столбцам, что создаёт структуру данных, сопоставляющую значения в столбцах с местоположениями соответствующих записей таблицы.
- Сохранение индекса в отдельной структуре данных, обычно в другой части диска или в памяти, чтобы доступ к ней был более эффективным, чем к соответствующим табличным данным.
- Обновление индекса в случае добавления новых записей, удаления или изменения записей в таблице.
Создание индекса может существенно улучшить производительность запросов к базе данных и операций поиска, поскольку оно позволяет системе базы данных находить соответствующие записи быстрее и эффективнее. Однако индексирование также может обладать и недостатками, например, увеличение требований к объёму хранилища и замедление выполнения операций вставки и обновления, поэтому перед созданием индекса следует взвесить плюсы и минусы.
Алгоритмы индексирования
Как говорилось выше, существует множество алгоритмов индексирования, используемых для оптимизации скорости операций получения данных при помощи создания индексов столбцов таблиц. Вот некоторые из самых популярных алгоритмов индексирования баз данных:
- B-дерево
- Bitmap-индекс
- Хэш-индекс
- GiST (Generalized Search Tree, обобщённое поисковое дерево)
- Полнотекстовый индекс
Каждый алгоритм индексирования имеет свои сильные и слабые стороны; давайте рассмотрим их по порядку.
B-дерево
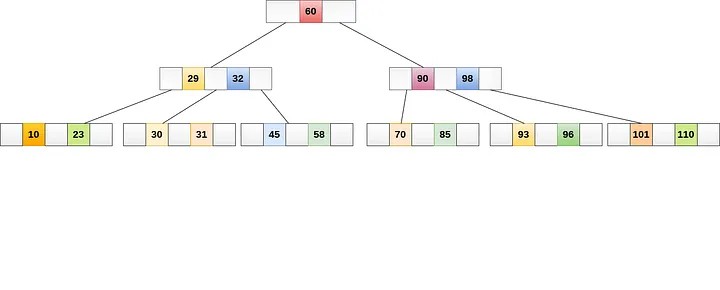
▍ Определение
B-дерево — это структура данных самобалансирующегося дерева, которая часто используется в качестве алгоритма индексирования в базах данных. Каждый узел дерева состоит из набора ключей и указателей на дочерние узлы; хранение данных осуществляется в иерархической структуре. Деревья B-узлов упорядочены таким образом, что позволяют быстро выполнять поиск, вставку и удаление данных.
Самое большое преимущество алгоритма B-дерева заключается в минимизации количества дисковых операций ввода-вывода, необходимых для доступа к данным, потому что в B-дереве все узлы-листья находятся на одном уровне, а каждый узел может хранить множество ключей и указателей. Количество ключей и указателей, которое может храниться в узле, определяется параметром, называемым «порядок» дерева.
▍ Как это работает
Алгоритм B-дерева работает следующим образом:
- Инициализация: при создании B-дерева создаётся пустой корневой узел. Параметр, задающий максимальное количество ключей («порядок»), которые могут храниться в каждом узле, управляет B-порядком дерева.
- Вставка: при добавлении нового узла в B-дерево алгоритм сначала подыскивает подходящий узел-лист, в который нужно вставить ключ. B-дерево разделяет заполненный узел-лист на два новых узла и перемещает медианный ключ в родительский узел. Пока не достигнут корневой узел, процесс разделения может распространяться по дереву. Благодаря этой процедуре дерево остаётся сбалансированным, а узлы-листья находятся на одинаковой высоте.
- Удаление: когда ключ удаляется из B-дерева, алгоритм ищет узел, который изначально хранил ключ. Если узел-лист хранил ключ, то ключ извлекается и узел может нуждаться в перебалансировке. Алгоритм удаляет предшествующий или последующий лист после листа-узла, удалив ключ с ним, если ключ обнаружен не в узле-листе.
- Поиск: в процессе поиска ключа в B-дереве алгоритм начинает с корневого узла и рекурсивно движется вверх по дереву, пока не найдёт нужный узел-лист. Метод поиска сравнивает искомый ключ с ключами, содержащимися в каждом узле, а затем использует соответствующий указатель для перехода к дочернему узлу, в котором может находиться ключ. Этот процесс продолжается, пока не будет найден искомый ключ или пока не будет определено, что он отсутствует в дереве.
Однако B-деревья обладают некоторыми недостатками:
- Излишняя трата ресурсов: B-деревья задействуют большой объём излишнего пространства, поскольку каждый узел в B-дереве содержит указатель на родительский и дочерний узлы.
- Сложность: алгоритмы, используемые для вставки, удаления и поиска данных в B-дереве, сложнее по сравнению с другими структурами данных. Это усложняет реализацию и поддержку B-деревьев.
- Медленные обновления: обновление данных в B-дереве может быть относительно медленным по сравнению с другими структурами данных. Каждая операция обновления требует множества операций доступа к диску, и этот процесс может быть медленным для больших B-деревьев.
▍ Bitmap-индексирование
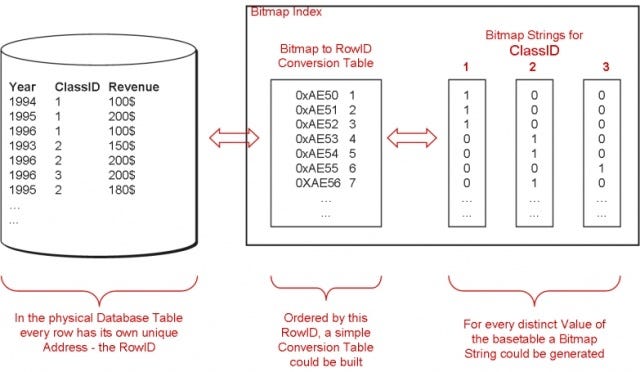
▍ Определение
Bitmap-индексирование — это методика индексирования данных, использующая битовые карты (bitmap) для обозначения наличия или отсутствия значения в таблице. Это успешная техника индексирования для таблиц с низкой кардинальностью, где количество уникальных значений в столбце довольно мало по сравнению с общим количеством строк.
Bitmap-индексирование может быть очень эффективным для столбцов с низкой кардинальностью, поскольку битовые карты крайне компактны и их можно быстро сканировать для извлечения данных. Bitmap-индексы очень удобны для применения в хранилищах данных, где необходимо быстро сканировать огромные объёмы данных. Кроме того, они полезны для баз данных, в которых много операций чтения, но мало обновлений или вставок.
▍ Как это работает
- Для создания bitmap-индекса столбца для каждого уникального значения столбца создаётся отдельный bitmap. Каждый bitmap имеет длину, равную количеству строк в таблице.
- Если значение присутствует в строке, соответствующему биту в bitmap присваивается значение 1, а если оно отсутствует, то присваивается значение 0. (Представьте таблицу, где столбец «Gender» имеет два уникальных значения, например, «Male» и «Female». Если этот столбец имеет bitmap-индекс, можно создать два bitmap, длина каждого из которых равна количеству строк в таблице. Когда в строке встречается «Male» или «Female», соответствующий бит в bitmap «Male» или «Female» получает значение 1, и наоборот. В случае отсутствия значения «Male» или «Female» соответствующему биту присваивается значение 0.)
- Чтобы выполнить запрос при помощи bitmap-индекса, соответствующие в запросе значения bitmap комбинируются при помощи побитовых операторов AND, OR и NOT. (например, если мы хотим найти все строки, где «Gender» равно «Male» И «Age» больше 30, нам сначала нужно получить bitmap «Male» и bitmap «Age > 30» из соответствующих индексов. Затем мы комбинируем эти два bitmap при помощи побитового оператора AND и получаем окончательный bitmap только с единицами в тех позициях, где оба условия истинны. Затем окончательный bitmap используется для получения из таблицы строк, удовлетворяющих запросу.)
Bitmap-индексы имеют множество недостатков, и в том числе:
- Большой размер: Bitmap-индексы могут быть большими, особенно при работе с крупными датасетами. Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
- Столбцы с высокой кардинальностью: Bitmap-индексы неэффективны для столбцов с высокой кардинальностью, где количество уникальных значений очень высоко. В таких случаях bitmap-индексы могут становиться очень большими и не помещаться в памяти.
- Смещённое распределение данных: если данные смещены, у нескольких значений может быть гораздо более высокая частота, чем у других, и bitmap-индексы окажутся неэффективными. Это вызвано тем, что bitmap для наиболее частых значений становятся очень большими и могут доминировать в индексе.
Хэш-индекс
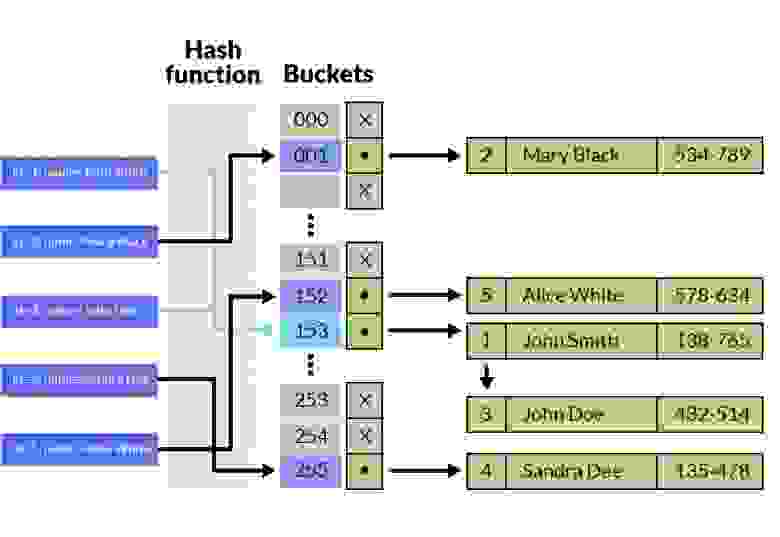
▍ Определение
Хэш-индекс — это разновидность методики индексирования баз данных, использующая хэш-функцию для сопоставления ключей индекса с местоположениями соответствующих записей данных. Это быстрый метод индексирования для запросов точного соответствия в одном столбце.
Сопоставление ключей индекса с местоположениями соответствующих записей данных позволяет выполнять быстрый поиск и вставки за постоянное время O(1). Однако этот метод плохо работает с запросами диапазонов или частичными совпадениями и может страдать от коллизий, с которыми можно справляться при помощи различных техник разрешения коллизий.
▍ Как это работает
Чтобы объяснить, как работает хэш-индекс, давайте рассмотрим пример. Допустим, у нас есть таблица базы данных, содержащая информацию о сотрудниках, в том числе, номера их пользовательских ID. Мы хотим создать хэш-индекс столбца пользовательских ID, чтобы получить возможность быстрого поиска данных пользователей на основании номера их ID.
- Мы создадим хэш-функцию, получающую на входе пользовательский ID и генерирующую на выходе уникальный хэш-код. Хэш-функция должна быть спроектирована таким образом, чтобы генерировать равномерно распределённое множество хэш-кодов для равномерного распределения записей по корзинам в файле индекса. На практике хэш-функция может использовать для генерации хэш-кода различные методики, например, модульную арифметику или побитовые операции.
- Мы создаём файл хэш-индекса, содержащий набор корзин (bucket), каждая из которых соответствует уникальному хэш-коду сгенерированному хэш-функцией. Каждая корзина содержит указатель на файл базы данных, содержащий записи для этого хэш-кода.
- При выполнении запроса к значению запроса применяется хэш-функция для генерации хэш-кода. Затем хэш-код используется для нахождения соответствующей корзины в файле хэш-индекса. Записи с одинаковым хэш-кодом хранятся в одной корзине, поэтому мы можем просто просканировать записи в этой корзине и найти совпадающую запись/записи. Если присутствуют коллизии (то есть несколько записей с одинаковым хэш-кодом), то для их разрешения можно использовать техники наподобие создания цепочек или открытой адресации.
- Чтобы вставить новую запись в хэш-индекс, мы применяем к значению ключа записи хэш-функцию, чтобы сгенерировать его хэш-код, а затем вставляем запись в соответствующую корзину в файле хэш-индекса. Если коллизии отсутствуют, вставку можно выполнить за постоянное время O(1), так как нам нужно всего лишь вычислить хэш-код и вставить запись в корзину. Если коллизии есть, нам может потребоваться проделать дополнительные операции, например, вставку записи в связанный список в корзине или проверку других корзин, пока не будет найден свободный слот.
Хэш-индексы также имеют множество недостатков, в том числе:
- Ограниченные возможности поиска: хэш-индексы предназначены для обработки только поисков равенства (например, «найти все записи, где столбец A равен значению»). Они плохо подходят для запросов диапазонов или сортировки.
- Коллизии: хэш-индексы могут иметь коллизии, при которых несколько ключей соответствуют одному хэш-значению. Это может привести к снижению производительности, поскольку базе данных нужно будет выполнять дополнительные операции для разрешения коллизий.
- Непредсказуемые требования к размеру хранилища: размер хэш-индекса невозможно предугадать, так как он зависит от количества уникальных значений в индексируемом столбце. Это усложняет планирование требований к размеру хранилища.
▍ GiST
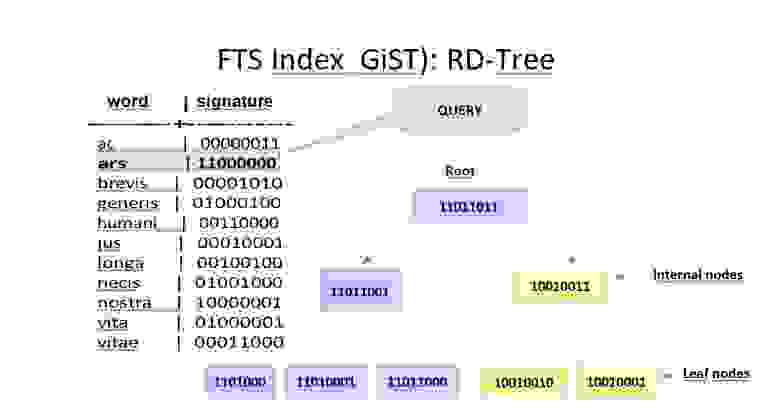
▍ Определение
GiST (Generalized Search Tree, обобщённое поисковое дерево) — это техника индексирования баз данных, которая может использоваться для индексирования сложных типов данных, например, геометрических объектов, текста или массивов. Это сбалансированная древовидная структура, состоящая из узлов с множественными дочерними узлами. Каждый узел описывает диапазон или множество значений и связан с предикативной функцией, проверяющей, принадлежит ли значение диапазону или множеству. Предикативная функция зависит от типа индексируемых данных и может быть подстроена под разные типы данных.
▍ Как это работает
Чтобы проиллюстрировать принцип работы индекса GiST, рассмотрим пример индексирования пространственных данных. Допустим, у нас есть таблица базы данных, содержащая информацию о городах, в том числе их названия и координаты в формате широты и долготы.
- Зададим множество предикатов и функций преобразования, специфичных для индексируемого типа пространственных данных. В данном случае мы должны задать предикат, проверяющий, находится ли заданная точка в ограничивающем прямоугольнике, описанном узлом в индексе, и функцию преобразования, преобразующую точку в набор ключей на основании её позиции в ограничивающем прямоугольнике.
- Создаём файл индекса GiST, состоящий из множества узлов, каждый из которых описывает ограничивающий прямоугольник, охватывающий диапазон координат.
Корневой узел описывает весь диапазон координат в таблице базы данных, а каждый дочерний узел описывает подмножество этого диапазона.
Каждый узел связывается с предикативной функцией и функцией преобразования, специфичными для индексируемого типа пространственных данных. - При выполнении запроса значение в запросе преобразуется при помощи функции преобразования в набор ключей.
Затем ключи сравниваются с предикатами, связанными с каждым узлом индекса, начиная с корневого узла.
Поиск продолжается вниз по дереву и выбирает дочерний узел, содержащий значение из запроса.
Процесс повторяется, пока не будет достигнут узел-лист, содержащий элементы индекса, соответствующие значению в запросе. - Для вставки в индекс нового города координаты города сначала при помощи функции преобразования преобразуются в набор ключей.
Затем ключи вставляются в соответствующие узлы индекса, начиная с корневого узла.
Если узел заполнен, выполняется операция разделения для создания двух новых узлов и ключи распределяются между узлами.
GiST имеет несколько недостатков, которые нужно учитывать:
- Сниженная скорость вставок и обновлений: структуры индексирования GiST могут быть сложнее, чем традиционные структуры индексирования, что может привести к снижению скорости операций вставки и обновления.
- Больше дискового пространства: структуры индексирования GiST могут требовать больше дискового пространства, чем другие методики индексирования, поскольку хранят дополнительную информацию для поддержки различных типов поиска.
- Подходит не для всех типов данных: GiST оптимизирован под индексирование сложных типов данных, например, пространственных данных, однако может быть не лучшим выбором для индексирования более простых типов данных, например, целочисленных значений или строк.
- Повышенные затраты на поддержку: из-за сложности реализации индексы GiST требуют больше обслуживания по сравнению с традиционными индексами.
▍ Полнотекстовый индекс
▍ Определение
Полнотекстовое индексирование — это методика индексирования баз данных, используемая для повышения эффективности поиска текстовых запросов. Это особый вид индекса, спроектированный для работы с текстовыми данными. В отличие от традиционных индексов, хранящих значения отдельных столбцов, полнотекстовый индекс хранит текстовое содержимое одного или нескольких столбцов как множества слов или токенов. Эти слова или токены используются при выполнении поискового запроса для быстрого нахождения релевантных строк.
Полнотекстовое индексирование способно существенно улучшить производительность текстовых поисковых запросов, особенно при работе с большими объёмами текстовых данных. Однако оно требует дополнительного дискового пространства и вычислительных ресурсов, а также тщательной настройки параметров индексирования для обеспечения оптимальной производительности.
▍ Как это работает
Процесс полнотекстового индексирования состоит из нескольких этапов:
- Токенизация: текстовое содержимое индексируемого столбца разбивается на отдельные слова или токены, которые затем сохраняются в индекс. При создании полнотекстового индекса система базы данных сначала анализирует текстовое содержимое индексируемых столбцов, а затем разбивает его на отдельные слова или токены. Этот процесс называется токенизацией, он может включать в себя фильтрацию игнорируемых слов (например, «the», «and», «or») и выделение корней (редуцирование слов до их базовой формы).
- Индексирование: затем токены индексируются при помощи специальной структуры данных, например, B-дерева или инвертированного индекса. Структура индекса обеспечивает возможность эффективного поиска и извлечения строк, содержащих указанные токены.
- Построение и выполнение запросов: система базы данных использует полнотекстовый индекс для поиска строк, содержащих релевантные токены. В процессе поиска токены запроса сопоставляются с индексированными токенами и извлекаются строки, соответствующие запросу. Результаты поиска можно ранжировать на основании их релевантности запросу, который вычисляется при помощи алгоритмов наподобие TF-IDF (term frequency-inverse document frequency).
Полнотекстовое индексирование имеет некоторые недостатки:
- Сниженная скорость индексирования и поиска: полнотекстовое индексирование может быть более сложным, чем другие техники индексирования, что может приводить к снижению скорости индексирования и поиска, особенно в больших базах данных со множеством текстовых полей.
- Подходит не для всех типов данных: полнотекстовое индексирование лучше всего подходит для баз данных, содержащих большие объёмы текстовых данных. Оно может и не быть наиболее эффективной техникой для баз данных, по большей мере, для содержащих числовую или другую нетекстовую информацию.
- Зависимость от языка: полнотекстовое индексирование может быть не очень эффективно для многоязычных баз данных, поскольку требует отдельных индексов для каждого языка и может оказаться неспособным справиться с нюансами различных языков и систем письменности.
Заключение
Индексирование баз данных — критически важная технология, повышающая эффективность запросов к базам данных. Оно заключается в создании специальных структур данных, обеспечивающих эффективный поиск и извлечение данных на основании одного или нескольких столбцов таблицы. Для оптимизации запросов под различные типы данных и сценарии использования применяются разные типы алгоритмов индексирования, например, B-деревья, bitmap-индексы, хэш-индексы и GiST-индексы.
Подробнее об индексировании баз данных можно узнать из следующих ресурсов:
- “Use The Index, Luke!”, Markus Winand — это подробное руководство по индексированию баз данных SQL, в котором освещаются как основы, так и расширенные возможности.
- “Database Indexing Explained”, DigitalOcean — в этом туториале представлено понятное для новичков введение в концепции и методики индексирования с примерами на PostgreSQL.
- “Indexing Strategies for MySQL and MariaDB”, Severalnines — в этом посте представлены практические советы по проектированию и оптимизации индексов в MySQL и MariaDB.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх
Поделиться ссылкой:
Интересные статьи
Интересные статьи

Мой open-source продукт. Rete neurale per la previsione di Dati tabulari. (it.)Простая реализация архитектуры глубокой нейронной сети для табличных данных с автоматической генерацией слоев и послойны...

На Joomla CMS сделано очень много сайтов для образовательных учреждений самого разного уровня и сложности. На сайты образовательных учреждений распространяется (на момент написания статьи) Приказ Росо...

Привет, Хабр! Сегодня хотим представить вам проект студентов магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online (подразделении SkillFactory по работе с университета...
Рост объемов данных остается беспрецедентным, причем они поступают из огромного множества источников. Все более сложные перемещения данных по большому многообразию экосистем существен...
При использовании стандартных методов отправки данных в Google Analytics есть вероятность, что система не успеет отправить все события, если процесс был прерван перезагрузкой страницы. В начале э...