Прим. перев.: автор этой статьи — ведущий инженер по инфраструктуре в Smarkets, что позиционирует себя как «одну из самых прибыльных [по доходам на каждого сотрудника] компаний в Европе». Работая с большой и чувствительной к мониторингу инфраструктурой на базе Kubernetes, инженеры компании нашли своё счастье с VictoriaMetrics, которая помогла им решить проблемы с Prometheus, возникшие после добавления новых K8s-кластеров.
Мониторинг внутренних endpoint'ов и API Kubernetes может быть проблематичным, особенно если стоит задача использовать автоматизированную инфраструктуру как сервис. Мы в Smarkets еще не достигли этой цели, но, к счастью, уже довольно близки к ней. Я надеюсь, что наш опыт в этой области поможет и другим реализовать нечто подобное.
Мы всегда мечтали о том, чтобы разработчики прямо «из коробки» получали возможность мониторинга для любого приложения или сервиса. До перехода на Kubernetes эта задача выполнялась либо с помощью метрик Prometheus, либо с помощью statsd, который пересылал статистику на базовый хост, где она конвертировалась в метрики Prometheus. Наращивая применение Kubernetes, мы начали разделять кластеры, и нам захотелось сделать так, чтобы разработчики могли экспортировать метрики напрямую в Prometheus через аннотации к сервисам. Увы, эти метрики были доступны только внутри кластера, то есть их нельзя было собирать глобально.
Эти ограничения стали «бутылочным горлышком» для нашей конфигурации, существовавшей до полного перехода на Kubernetes. В конечном итоге они заставили пересмотреть архитектуру и способ мониторинга сервисов. Как раз об этом путешествии и пойдет речь ниже.
Для метрик, связанных с Kubernetes, мы используем два сервиса, предоставляющих метрики:
Можно (и в течение некоторого времени мы делали это) выставлять сервисы с метриками за пределы кластера или открывать прокси-подключение к API, однако оба варианты не были идеальны, поскольку замедляли работу и не обеспечивали должную независимость и безопасность систем.
Обычно разворачивалось решение для мониторинга, состоящее из центрального кластера из Prometheus-серверов, работающих внутри Kubernetes и собиравших метрики с самой платформы, а также внутренние метрики Kubernetes с этого кластера. Основная причина, по которой был выбран такой подход, состояла в том, что в процессе перехода на Kubernetes мы собрали все сервисы в одном и том же кластере. После добавления дополнительных Kubernetes-кластеров наша архитектура выглядела следующим образом:
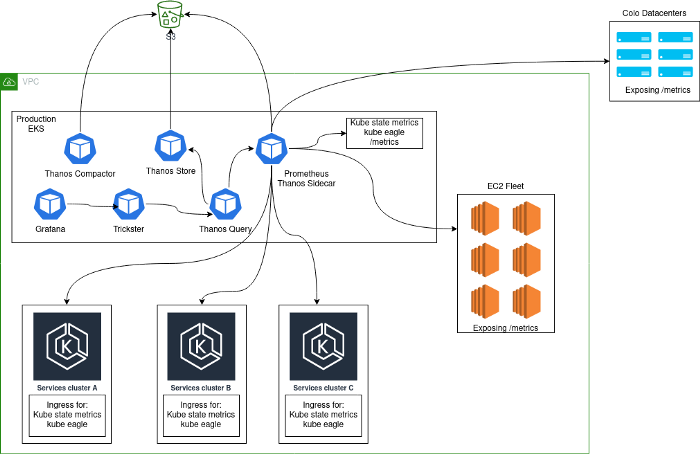
Подобную архитектуру нельзя назвать устойчивой, эффективной и производительной: ведь пользователи могли экспортировать statsd-метрики из приложений, что приводило к невероятно высокой кардинальности некоторых метрик. Подобные проблемы могут быть вам знакомы, если приведенный ниже порядок величин кажется привычным.
При анализе 2-часового блока Prometheus:
Столь высокая кардинальность преимущественно связана с выставлением наружу таймеров statsd, включающих HTTP-пути. Мы знаем, что подобная реализация не идеальна, однако эти метрики используются для отслеживания критических ошибок в канареечных развертываниях.
В спокойное время собиралось около 40 000 метрик в секунду, однако их число могло вырастать до 180 000 в отсутствии каких-либо проблем.
Некоторые специфические запросы по метрикам с высокой кардинальностью приводили к тому, что у Prometheus (предсказуемо) заканчивалась память — весьма неприятная ситуация, когда он (Prometheus) используется для алертов и оценки работы канареечных развертываний.
Другая проблема состояла в том, что в условиях, когда на каждом экземпляре Prometheus хранились данные за три месяца, время запуска (WAL replay) оказывалось очень высоким, и это обычно приводило к тому, что тот же самый запрос направлялся на второй экземпляр Prometheus и «ронял» уже его.
Чтобы устранить эти проблемы, мы внедрили Thanos и Trickster:
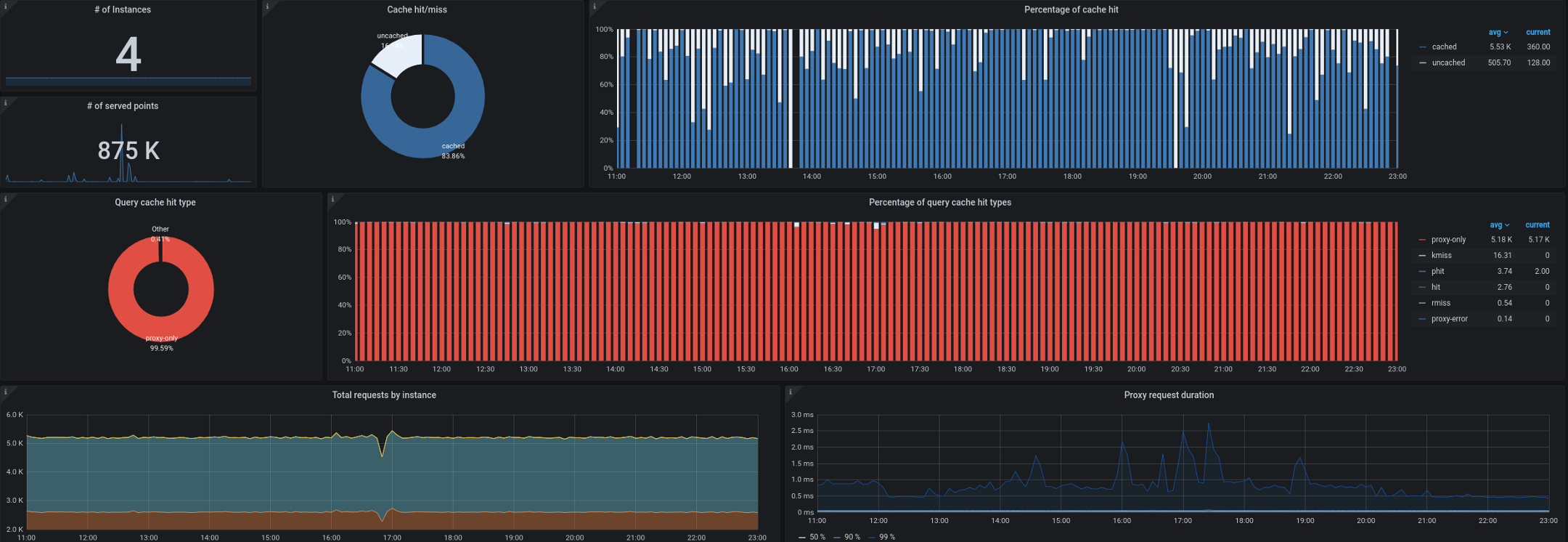
У нас также начали возникать проблемы при сборе kube-state-metrics из-за пределов кластера. Как вы помните, частенько приходилось обрабатывать до 180 000 метрик в секунду, а сбор тормозил уже при выставлении 40 000 метрик в единственном ingress’е kube-state-metrics. У нас установлен целевой 10-секундный интервал для сбора метрик, а в периоды высокой нагрузки этот SLA часто нарушался удаленным сбором kube-state-metrics или kube-eagle.
Размышляя над тем, как улучшить архитектуру, мы рассмотрели три различных варианта:
Подробную информацию о них и сравнение характеристик можно найти в интернете. В нашем конкретном случае (и после тестов на данных с высокой кардинальностью) явным победителем оказалась VictoriaMetrics.
Пытаясь улучшить описанную выше архитектуру, мы решили изолировать каждый кластер Kubernetes как отдельную сущность и сделать Prometheus его частью. Теперь любой новый кластер идет со включенным «из коробки» мониторингом и метриками, доступными в глобальных dashboard'ах (Grafana). Для этого сервисы kube-eagle, kube-state-metrics и Prometheus были интегрированы в кластеры Kubernetes. Затем Prometheus конфигурировался с помощью внешних лейблов, идентифицирующих кластер, а
База данных временных рядов VictoriaMetrics реализует протоколы Graphite, Prometheus, OpenTSDB и Influx. Она не только поддерживает PromQL, но и дополняет его новыми функциями и шаблонами, позволяя избежать рефакторинга запросов Grafana. Кроме того, ее производительность просто потрясает.
Мы развернули VictoriaMetrics в режиме кластера и разбили на три отдельных компонента:
Этот компонент отвечает за хранение данных, импортированных
Этот компонент получает данные от deployment'ов с Prometheus и переправляет их в
Принимает PromQL-запросы от Grafana (Trickster) и запрашивает исходные данные из
Текущая реализация выглядит следующим образом:
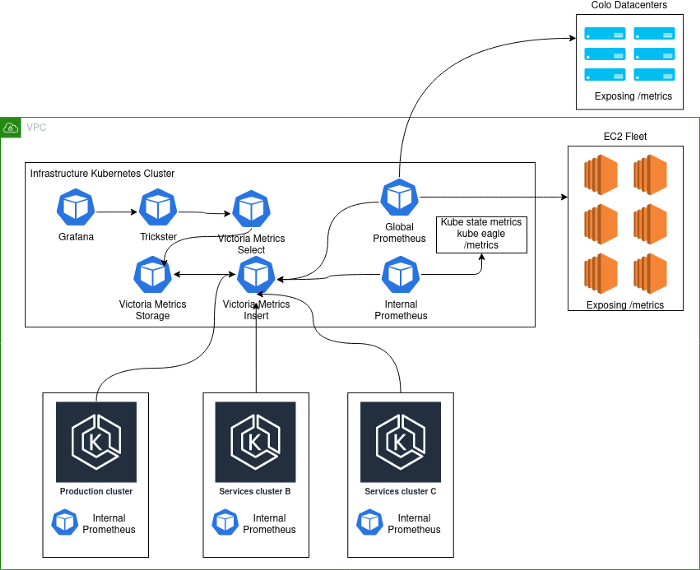
Примечания к схеме:
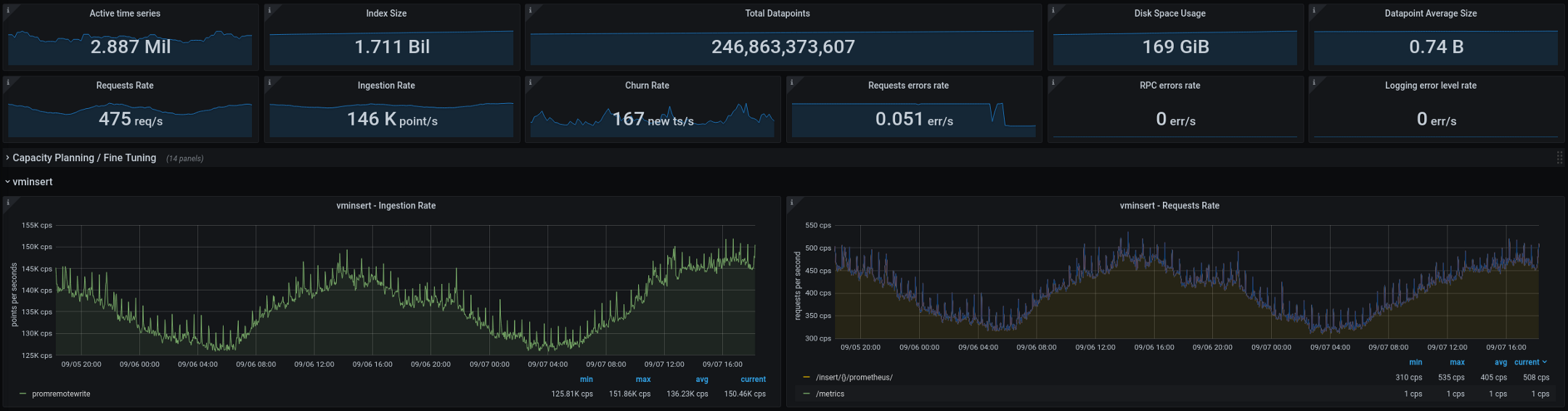
Ниже приведены метрики, которые в настоящее время обрабатывает VictoriaMetrics (итоговые данные за две недели, на графиках показан промежуток в два дня):
Новая архитектура отлично себя зарекомендовала после перевода в production. На старой конфигурации у нас случалось по два-три «взрыва» кардинальности каждую пару недель, на новой их число упало до нуля.
Это отличный показатель, но есть еще несколько моментов, которые мы планируем улучшить в ближайшие месяцы:
Если у вас есть предложения или идеи, связанные с озвученными выше улучшениями, пожалуйста, свяжитесь с нами. Если же вы работаете над улучшением мониторинга Kubernetes, надеемся, что эта статья, описывающая наш непростой путь, оказалась полезной.
Читайте также в нашем блоге:
Мониторинг внутренних endpoint'ов и API Kubernetes может быть проблематичным, особенно если стоит задача использовать автоматизированную инфраструктуру как сервис. Мы в Smarkets еще не достигли этой цели, но, к счастью, уже довольно близки к ней. Я надеюсь, что наш опыт в этой области поможет и другим реализовать нечто подобное.
Мы всегда мечтали о том, чтобы разработчики прямо «из коробки» получали возможность мониторинга для любого приложения или сервиса. До перехода на Kubernetes эта задача выполнялась либо с помощью метрик Prometheus, либо с помощью statsd, который пересылал статистику на базовый хост, где она конвертировалась в метрики Prometheus. Наращивая применение Kubernetes, мы начали разделять кластеры, и нам захотелось сделать так, чтобы разработчики могли экспортировать метрики напрямую в Prometheus через аннотации к сервисам. Увы, эти метрики были доступны только внутри кластера, то есть их нельзя было собирать глобально.
Эти ограничения стали «бутылочным горлышком» для нашей конфигурации, существовавшей до полного перехода на Kubernetes. В конечном итоге они заставили пересмотреть архитектуру и способ мониторинга сервисов. Как раз об этом путешествии и пойдет речь ниже.
Отправная точка
Для метрик, связанных с Kubernetes, мы используем два сервиса, предоставляющих метрики:
-
kube-state-metricsгенерирует метрики для объектов Kubernetes на основе информации от API-серверов K8s; -
kube-eagleэкспортирует метрики Prometheus для pod’ов: их request'ы, limit'ы, использование.
Можно (и в течение некоторого времени мы делали это) выставлять сервисы с метриками за пределы кластера или открывать прокси-подключение к API, однако оба варианты не были идеальны, поскольку замедляли работу и не обеспечивали должную независимость и безопасность систем.
Обычно разворачивалось решение для мониторинга, состоящее из центрального кластера из Prometheus-серверов, работающих внутри Kubernetes и собиравших метрики с самой платформы, а также внутренние метрики Kubernetes с этого кластера. Основная причина, по которой был выбран такой подход, состояла в том, что в процессе перехода на Kubernetes мы собрали все сервисы в одном и том же кластере. После добавления дополнительных Kubernetes-кластеров наша архитектура выглядела следующим образом:
Проблемы
Подобную архитектуру нельзя назвать устойчивой, эффективной и производительной: ведь пользователи могли экспортировать statsd-метрики из приложений, что приводило к невероятно высокой кардинальности некоторых метрик. Подобные проблемы могут быть вам знакомы, если приведенный ниже порядок величин кажется привычным.
При анализе 2-часового блока Prometheus:
- 1,3 млн метрик;
- 383 имени лейблов;
- максимальная кардинальность на метрику — 662 000 (больше всего проблем именно из-за этого).
Столь высокая кардинальность преимущественно связана с выставлением наружу таймеров statsd, включающих HTTP-пути. Мы знаем, что подобная реализация не идеальна, однако эти метрики используются для отслеживания критических ошибок в канареечных развертываниях.
В спокойное время собиралось около 40 000 метрик в секунду, однако их число могло вырастать до 180 000 в отсутствии каких-либо проблем.
Некоторые специфические запросы по метрикам с высокой кардинальностью приводили к тому, что у Prometheus (предсказуемо) заканчивалась память — весьма неприятная ситуация, когда он (Prometheus) используется для алертов и оценки работы канареечных развертываний.
Другая проблема состояла в том, что в условиях, когда на каждом экземпляре Prometheus хранились данные за три месяца, время запуска (WAL replay) оказывалось очень высоким, и это обычно приводило к тому, что тот же самый запрос направлялся на второй экземпляр Prometheus и «ронял» уже его.
Чтобы устранить эти проблемы, мы внедрили Thanos и Trickster:
- Thanos позволил хранить меньше данных в Prometheus и сократил число инцидентов, вызванных чрезмерным использованием памяти. Рядом с контейнером Prometheus Thanos запускает sidecar-контейнер, который складирует блоки данных в S3, где их затем сжимает thanos-compact. Таким образом, с помощью Thanos'а было реализовано долгосрочное хранение данных за пределами Prometheus.
- Trickster, со своей стороны, выступил обратным прокси и кэшем для баз данных временных рядов. Он позволил нам закэшировать до 99,53% всех запросов. Большинство запросов поступает от панелей мониторинга, запущенных на рабочих станциях/ТВ, от пользователей с открытыми контрольными панелями и от алертов. Прокси, способный выдавать только дельту во временных рядах, отлично подходит для подобной нагрузки.
У нас также начали возникать проблемы при сборе kube-state-metrics из-за пределов кластера. Как вы помните, частенько приходилось обрабатывать до 180 000 метрик в секунду, а сбор тормозил уже при выставлении 40 000 метрик в единственном ingress’е kube-state-metrics. У нас установлен целевой 10-секундный интервал для сбора метрик, а в периоды высокой нагрузки этот SLA часто нарушался удаленным сбором kube-state-metrics или kube-eagle.
Варианты
Размышляя над тем, как улучшить архитектуру, мы рассмотрели три различных варианта:
- Prometheus + Cortex (https://github.com/cortexproject/cortex);
- Prometheus + Thanos Receive (https://thanos.io);
- Prometheus + VictoriaMetrics (https://github.com/VictoriaMetrics/VictoriaMetrics).
Подробную информацию о них и сравнение характеристик можно найти в интернете. В нашем конкретном случае (и после тестов на данных с высокой кардинальностью) явным победителем оказалась VictoriaMetrics.
Решение
Prometheus
Пытаясь улучшить описанную выше архитектуру, мы решили изолировать каждый кластер Kubernetes как отдельную сущность и сделать Prometheus его частью. Теперь любой новый кластер идет со включенным «из коробки» мониторингом и метриками, доступными в глобальных dashboard'ах (Grafana). Для этого сервисы kube-eagle, kube-state-metrics и Prometheus были интегрированы в кластеры Kubernetes. Затем Prometheus конфигурировался с помощью внешних лейблов, идентифицирующих кластер, а
remote_write указывал на insert в VictoriaMetrics (см. ниже).VictoriaMetrics
База данных временных рядов VictoriaMetrics реализует протоколы Graphite, Prometheus, OpenTSDB и Influx. Она не только поддерживает PromQL, но и дополняет его новыми функциями и шаблонами, позволяя избежать рефакторинга запросов Grafana. Кроме того, ее производительность просто потрясает.
Мы развернули VictoriaMetrics в режиме кластера и разбили на три отдельных компонента:
1. VictoriaMetrics storage (vmstorage)
Этот компонент отвечает за хранение данных, импортированных
vminsert. Мы ограничились тремя репликами этого компонента, объединенными в StatefulSet Kubernetes../vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
VictoriaMetrics insert (vminsert)
Этот компонент получает данные от deployment'ов с Prometheus и переправляет их в
vmstorage. Параметр replicationFactor=2 реплицирует данные на два из трех серверов. Таким образом, если один из экземпляров vmstorage испытывает проблемы или перезапускается, все равно остается одна доступная копия данных../vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics select (vmselect)
Принимает PromQL-запросы от Grafana (Trickster) и запрашивает исходные данные из
vmstorage. В настоящее время у нас выключен кэш (search.disableCache), поскольку в архитектуре присутствует Trickster, который и отвечает за кэширование; поэтому надо, чтобы vmselect всегда извлекал последние полные данные./vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
Общая картина
Текущая реализация выглядит следующим образом:
Примечания к схеме:
- Production-кластер и кластеры со вспомогательными сервисами более не хранят данные мониторинга. Цель данного конкретного изменения состояла в том, чтобы ограничить глобальную функцию кластеров K8s и предотвратить каскадные отказы. В случае выхода из строя какого-либо кластера важно иметь доступ к метрикам и логам, которые помогут установить суть проблемы. Совместная работа сервисов в одних и тех же кластерах повышала вероятность каскадных отказов и затрудняла диагностику первопричины сбоя.
- Каждый deployment в составе кластера K8s идет вместе с локальным Prometheus'ом, который собирает исключительно внутренние метрики и отправляет их в VictoriaMetrics insert в инфраструктурном кластере Kubernetes.
- В инфраструктурном кластере Kubernetes работают два deployment'а с Prometheus, выполняющие разные функции. Вообще говоря, подобная схема не была строго обязательной, однако она придала процессу мониторинга Kubernetes необходимую согласованность, так что любые изменения теперь автоматически и единообразно применяются ко всем кластерам. Global Prometheus теперь отвечает только за сбор метрик с экземпляров EC2, с colocation-хостинга и любых других не-Kubernetes-сущностей.
Заключение
Ниже приведены метрики, которые в настоящее время обрабатывает VictoriaMetrics (итоговые данные за две недели, на графиках показан промежуток в два дня):
Новая архитектура отлично себя зарекомендовала после перевода в production. На старой конфигурации у нас случалось по два-три «взрыва» кардинальности каждую пару недель, на новой их число упало до нуля.
Это отличный показатель, но есть еще несколько моментов, которые мы планируем улучшить в ближайшие месяцы:
- Снизить кардинальность метрик, улучшив интеграцию statsd.
- Сравнить кэширование в Trickster и VictoriaMetrics — нужно оценить влияние каждого решения на эффективность и производительность. Есть подозрение, что от Trickster можно вообще отказаться, ничего не потеряв.
- Превратить Prometheus в stateless-сервис — пока он работает как stateful, однако для этого нет особых причин. Мы до сих пор используем лейблы на основе постоянного сетевого имени, предоставляемого StatefulSet'ом, так что об этом придется помнить (как и о pod disruption budgets).
- Оценить работу
vmagent— компонента VictoriaMetrics для сбора метрик с Prometheus-совместимых exporter'ов. Учитывая, что на данный момент наш Prometheus только этим и занимается, это перспективное направление для улучшения. В будущемvmagentпозволит полностью отказаться от Prometheus (его бенчмарки выглядят многообещающе!).
Если у вас есть предложения или идеи, связанные с озвученными выше улучшениями, пожалуйста, свяжитесь с нами. Если же вы работаете над улучшением мониторинга Kubernetes, надеемся, что эта статья, описывающая наш непростой путь, оказалась полезной.
P.S. от переводчика
Читайте также в нашем блоге:
- «Будущее Prometheus и экосистемы проекта (2020)»;
- «Мониторинг и Kubernetes» (обзор и видео доклада);
- «Устройство и механизм работы Prometheus Operator в Kubernetes».



