

Под катом вас ждёт чертёж установки, блок-схемы агента, работающего методом проб и ошибок, а также визуализации, видеоролики и, конечно, код. Материалом делимся к старту нашего флагманского курса по Data Science.
Агент-критик Softmax оптимизирует выработку энергии в моделируемой по реальным данным меняющейся среде освещения.
О моделировании среды
Особенности среды, определяющие лучшее расположение панелей, то есть положение Солнца в любое время суток моделировать легко; труднее моделировать особенности конкретного места или панели. Изменения тени, например от деревьев, дефекты панелей, дрейф осей по мере деградации системы — всё это может сильно повлиять на выработку энергии.
Вместо моделирования, калибровки и обновления всех этих факторов для каждой двухосной солнечной установки это исследование скорее направлено на демонстрацию того, как использующий обучение с подкреплением (RL) агент может увеличить выработку энергии, не зная ни об одной из этих особенностей.
Системы управления и обучение с подкреплением
RL — сдвиг парадигмы моделирования и управления сложными системами. Разработчикам агента не нужно моделировать динамику управляемой системы или понимать, как управлять этой динамикой.
Наша задача — предельно увеличить выработку энергии панелью, то есть разместить панель так, чтобы за сутки с учётом изменения освещённости она вырабатывала как можно больше энергии.
Используя традиционные методы, мы выбрали бы подход к разработке, где пытаемся смоделировать все влияющие на выработку энергии особенности, и разработать логику управления с учётом каждой мелочи. В попытках достичь наилучшего поведения мы пробовали бы по-разному настраивать модели и также по-разному управлять ими.

В случае RL разработчикам агента не нужно знать, как настраивать модель и управлять ею: мы просто определяем цель, и агент учится добиваться наилучшего решения.

ИИ постоянно взаимодействует со средой и получает награду. Исходя из награды, он обновляет вероятность выбора действий в текущем состоянии:
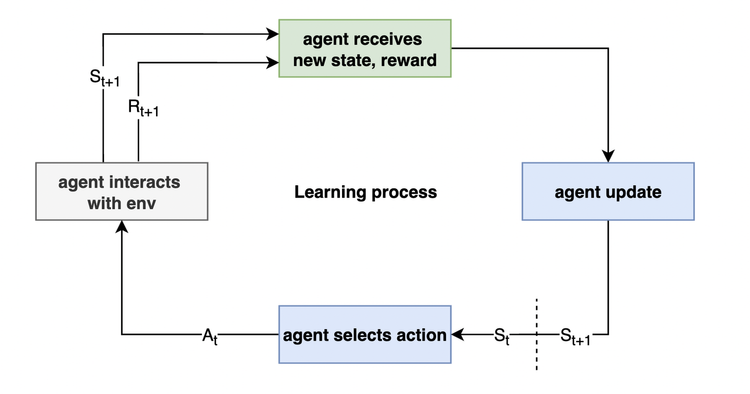
Зная это, поговорим о конкретной реализации RL в нашей задаче.
Принципы обучения с подкреплением в подробностях.
Полезные ресурсы об RL.
Реализация
Рассмотрим аппаратную часть системы, затем поговорим об алгоритмах и ПО..
Двухосная панель
Каждая ось управляется сервомотором, который поворачивается на 180°. На каждом временном отрезке через последовательный порт или порт USB панель передаёт агенту RL данные о положении сервомотора и вырабатываемой мощности. Посмотрите чертёж установки:
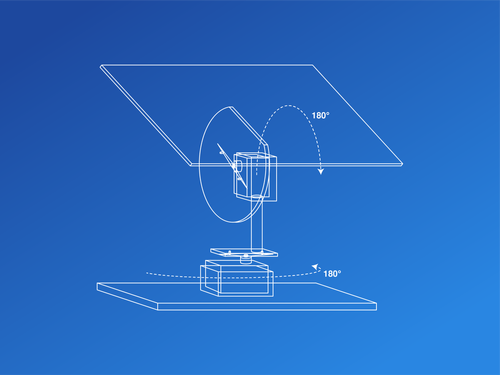

Дизайн системы.
Электрическая схема.
Архитектура двухосной панели.
Взаимодействие агента со средой
На каждом шаге агент решает, как расположить сервомоторы, чтобы вырабатывать наибольшую энергию. Каждый сервомотор можно расположить в диапазоне от 0 до 180°, но используемые в проекте шестерёнки напечатаны на 3D-принтере и дают точность позиционирования только около 5°. Учитывая это, я индексирую 0–180° с шагом в 5°, то есть каждый сервомотор может иметь положения от 0 до 36.
Чтобы упростить структуру памяти агента, преобразуем двумерный индекс положения сервомотора: [36, 1] в одномерный индекс с плоским отображением, например [1333]. Так единственное число передаёт состояние обоих сервомоторов.
За сутки среда изменяется, поэтому агент отслеживает время суток как часть своего состояния. Настраиваемый шаг времени увеличивает или уменьшает дискретизацию состояний, изучаемых агентом.
Здесь шаг времени равен 24 для сопоставления с часами суток.

Чтобы достичь своей цели, агент запрашивает индексы положения сервомоторов, а затем учится на мощности в конкретных положениях в данное время суток.
Архитектура агента
В проекте агент использует алгоритм актор — критик Softmax с табличным представлением сетей актора и критика. Эту реализацию я выбрал после первых экспериментов с агентом Q-обучения с эпсилон-жадной политикой, которая затруднялась в изучении пространства действий, насчитывающего 1369 действий в любом состоянии.
Учитывая непрерывность задачи, уравнения обновления акторов и критиков вместо коэффициента дисконта и значения будущего состояния использует среднее значение.


Уравнение обновления актора агента. Подробности об этом упрощении градиента смотрите в RL Agent — Softmax Actor-Critic.

Во всех состояниях агент выбирает индекс будущего положения сервомотора, при этом один из индексов соответствует статичному положению. Когда агент принимает решение, среда меняет положение панели и возвращает вознаграждение — количество энергии, выработанной в новом состоянии, за вычетом энергии на вращение сервомоторов.
Вот так агент выбирает действие:

Измерения сетей акторов и критиков — [время суток, количество состояний, количество действий]. Здесь это [24, 1369, 1369]. Значения внутри сети акторов соответствуют не ожидаемой в каждом состоянии мощности, а скорее вероятности выбора действия. У критика тоже трёхмерная структура памяти, однако он изучает ожидаемую мощность от каждого действия в данном состоянии.

После разработки агента переходим к тренировочной среде, где агент учится решать задачу.
О реализации агентов в этом проекте.
Генерация симуляции среды
Агенты RL учатся через исследование, а исследование требует времени. Обычно агента ориентируют в смоделированных средах, где шаг времени намного короче настоящего. Так можно быстро понять, подходит ли агент для задачи, и исследовать гиперпараметры.
Здесь не хочется моделировать всю основную динамику, влияющую на реальную выработку электроэнергии в данном месте и в данное время, поэтому с помощью двухосной панели смоделируем среду, просканировав освещённость батареи Солнцем:

Сбор данных о мощности по всем индексам сервомотора
Съёмка выше покадровая, не в реальном времени:
Преобразование в двумерный массив


Класс среды
Класс среды эмулирует реальную среду меняющегося освещения. Сдвиг массива каждые N шагов отражает движение Солнца. Каждые M шагов (дней) агент возвращается в исходное положение.
N и M равны 3600 и 86400: 3600 шагов модели — час реального времени; 86 400 шагов — это сутки:
Класс среды штрафует за энергозатраты на вращение сервомоторов.
Для проверки агента достаточно произвольно определить потребляемую сервомотором мощность на угол: за вращение сервомоторов агента хочется штрафовать, чтобы научить его балансировать между затратами энергии на вращение и статичным положением, не требующим тока.
Так, награда агенту от среды составляет:
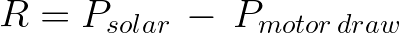
Вот потребляемая сервомотором мощность:
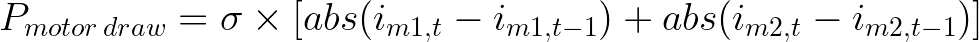
Сигма — некоторая константа. Здесь она равна 0,0001 Вт на градус движения на двигатель.
Подробности о среде и создании симуляций:
Результаты
Сначала я исследую гиперпараметры, изменяя температуру агента, размеры шагов актора и критика, а также средний размер шага вознаграждения от 1e-5 до 1e-0 с шагом x10. Это даёт 625 перестановок гиперпараметров агента.
Гиперпараметры я исследую на одном миллионе шагов и в конце симуляции оцениваю производительность по скользящему среднему количеству энергии. Исходя из этого исследования, лучшим признан этот набор гиперпараметров:
temperature: 0.001
actor_step_size: 1.0
critic_step_size: 0.1
avg_reward_step_size: 1.0
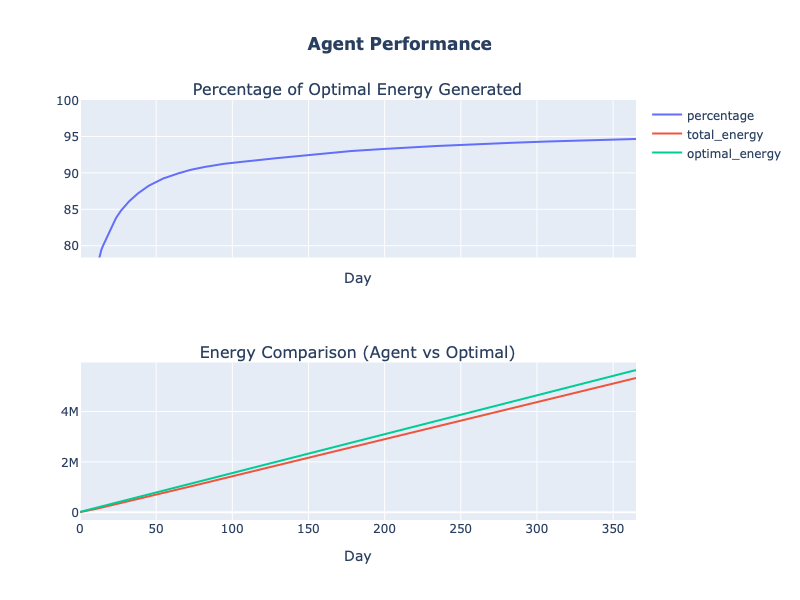
Чтобы осмыслить производительность нашей системы, моделируется один год её работы. Полученная энергия сравнивается с энергией, которая была бы выработана, если бы панель всегда была расположена идеально. Шаг симуляции равен одной секунде, поэтому нужно 365 * 86 400 = 31 536 000 шагов.
Запустив код, получим производительность агента:

За месяц агент каждый день вырабатывает более 90% максимума энергии без каких-либо моделей или участия человека для сбора данных и управления динамикой среды. Он продолжает учиться и повышать выработку энергии весь год, к его концу достигая 96% суточного предела.
Изучая поведение агента в начале симуляции, мы увидим, как при первом столкновении с каждым состоянием агент исследует множество действий, и спустя несколько часов сужает их выбор.
Вот первые 5 дней работы по часам:
Сравнивая мощность качения на первом миллионе шагов с последним миллионом шагов, увидим, как поведение агента сходится к оптимальному, в то же время он продолжает учиться.

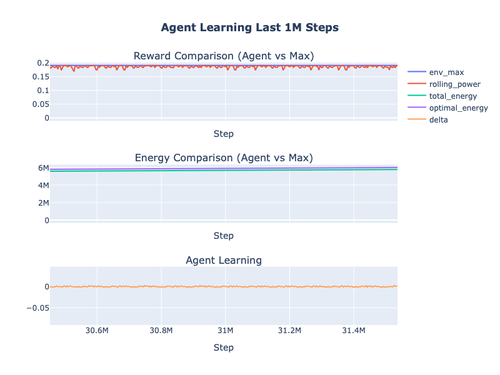
Чтобы проверить производительность агента ещё раз, снова просканируем свет с тем же алгоритмом и гиперпараметрами агента. И теперь области высокой и низкой мощности выражены намного сильнее:


К концу года длиной в 31 536 000 шагов агент снова вырабатывает около 95% максимальной энергии:
Заключение
Агент-критик Softmax оптимизирует выработку энергии двухосной солнечной панелью без помощи распределения вероятности перехода или знаний предметной области. Работая с несколькими динамическими световыми средами в симуляции, которая имитировала год работы, агент добивается 95% от максимума.
Подобную задачу оптимизации теоретически можно решить традиционными методами, при помощи знаний предметной области, но они не обязательно масштабируются по мере увеличения количества панелей в установке: посмотрите динамику затенения между панелями. Традиционные методы также неприменимы к другим задачам, с которыми мы столкнёмся при переходе на возобновляемые источники энергии.
Я считаю, что RL позволяет решать больше задач оптимального управления сложными энергосистемами за меньшее время, меньшими усилиями и более подходящим образом, чем традиционные методы без применения ИИ.
Материалы проекта
Подробную техническую информацию обо всех этапах проекта смотрите в разделе Project Overview.
Код проекта хранится здесь.
Направления дальнейшей работы
Я не стану развивать это исследование, но вижу для него три многообещающих направления:
Обновление Q-Network и сети политики до глубоких нейросетей. Избавившись от табличных представлений состояний и действий, агент приобретает гораздо большую универсальность и может быть легко адаптирован к управлению несколькими панелями.
Управление несколькими панелями. Использовать базовый алгоритм агента для управления несколькими панелями, когда одни панели затеняются другими.
Портирование агента на C/C++ для автономного онлайн-развёртывания. Хотя агент в нынешнем виде технически может работать как онлайн-агент, нужно, чтобы к Arduino был подключен ноутбук с Python. Портированный на C/C++ агент можно прошить на Arduino и запускать автономно, когда Arduino включена.
А мы поможем вам прокачать навыки или с самого начала освоить профессию, актуальную в любое время:
Профессия Data Scientist
Профессия Fullstack-разработчик на Python
Выбрать другую востребованную профессию.

Краткий список курсов и профессий
Data Science и Machine Learning
Профессия Data Scientist
Профессия Data Analyst
Курс «Математика для Data Science»
Курс «Математика и Machine Learning для Data Science»
Курс по Data Engineering
Курс «Machine Learning и Deep Learning»
Курс по Machine Learning
Python, веб-разработка
Профессия Fullstack-разработчик на Python
Курс «Python для веб-разработки»
Профессия Frontend-разработчик
Профессия Веб-разработчик
Мобильная разработка
Профессия iOS-разработчик
Профессия Android-разработчик
Java и C#
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия C#-разработчик
Профессия Разработчик игр на Unity
От основ — в глубину
Курс «Алгоритмы и структуры данных»
Профессия C++ разработчик
Профессия Этичный хакер
А также
Курс по DevOps
Все курсы




