
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Всем привет. Сегодня я попытаюсь рассказать про сетевое программирование на довольно низком уровне, с библиотеками libpacp и libdnet. Про последнюю многие наверное и не слышали, т.к. информации о ней в сети фактически нет. А ведь её использует сам Fyodor :)
Изложу предысторию. В своё время активного сисадминства был весьма огорчён несовершенством существующих свободных систем мониторинга. Настолько огорчён, что даже начал разрабатывать собственный плугин к zabbix, позволяющий визуализировать L3 карту сети. Потом у меня пропал доступ к «полигону» и данный pet-проект начал тихо угасать.
Долгое время я порывался его возродить, даже написал небольшую статью на habr, чтобы сохранить некие принципы формирования карты, но дальше этого не пошло.
Конечно, были размышления на тему поднять сетку из кучи виртуалок или задействовать что-нибудь вроде GNS, но на всё это нужны вычислительные ресурсы. Весьма нескромные ресурсы.
Второй вариант — в системе мониторинга написать какую-нибудь обёртку к функциям snmpget/snmpwalk которая будет выдавать по запросам заранее подготовленные данные (у меня сохранились дампы со всего активного сетевого оборудования полигона). Ну и подшаманить тот-же zabbix некими внешними скриптами. Не стал двигаться в данном направлении — внутренний перфекционист скверно выругался и отказался сотрудничать.
И вот относительно недавно, мне довелось заглянуть в исходники LaBrea tarpit. Если кто не в курсе это honeypot, довольно древний и интерес в настоящее время представляет исключительно академический. Вот в его исходниках я и увидел libpcap, libdnet, а также возможность создания нового полигона — легковесного эмулятора сети.
Вот собственно рассмотрением «базовых кирпичиков», позволяющих реализовать данный эмулятор, мы и займёмся.Как оказалось, не я первый до этого додумалсяПо запросу «SNMP agent simulator» гуглится довольно много коммерческого и бесплатного софта с аналогичными функционалом. Однако я уже достаточно продвинулся, чтобы бросать начатое — буду доделывать.
▍ Задача

На одной машине развёрнута «тестовая» система мониторинга и там я пишу (вернее, буду дописывать) свою карту L3 к системе мониторинга. На этой машине добавляется маршрут к сети 10.0.0.0/16 (можно меньше или больше, но в заголовке статьи я обещал /16).

На машине эмуляторе-сети никаких настроек, только эмулятор. Какие от него ожидания:
- Положительно отвечать на пинги, идущие к определенным адресам.
- Сообщать о недоступности определённых хостов/сетей.
- Отзываться на snmp-запросы (v1 и только udp — поддерживать вручную tcp-сессии сложновато) и выдавать соответствующую информацию, привязанную к определённому хосту.
Сразу скажу, что не всё готово и поэтому доступ к исходникам не раздаю. Здесь опишу только общий костяк программы и реализацию первых двух пунктов.
Также хочу обратить внимание, что куски кода, которые фигурируют в статье, не являются эталоном стиля программирования. Пишу самый минимум, без нормального контроля ошибок, без комментариев (они будут по тексту отдельно), исключительно для демонстрации «полезной» нагрузки. Но при этом всё будет работоспособно и воспроизводимо в домашних условиях.
▍ Первые шаги
Мне кажется, что libpcap известна практически всем системным администраторам — она служит основой
tcpdump/wireshark/snort/nmap/L0phtCrack и т.д. Библиотека занимается захватом и анализом сетевых пакетов, поступающих на сетевую карту. А в promiscous-режиме и тех, что проходили мимо. В сети достаточно обучающих примеров с рабочими исходниками.А теперь про libdnet. Это библиотека для ручного формирования, разбора, отправки и приёма сетевых пакетов. Из полезной информации только сайт и man dnet, нет даже странички в википедии как у libpcap, хотя список связанных проектов довольно большой и включает в себя легендарный сканер nmap.
Как я уже писал ранее, идея эмулятора сети родилась, после работы с исходниками LaBrea, и первые эксперименты производились прямо по её коду. Через некоторое время решил начать с «чистого листа», но с заимствованием некоторых элементов из LaBrea (её можно скачать на github), поэтому создаём каталог netemu, и там размещаем следующие файлы из архива LaBrea:А можно по-другому?Хоть глубоко и не копал, но мельком глянул на штатные ядрёные Divert sockets. Судя по описанию и примерам, ими можно целиком и полностью заменить связку libpcap и libdnet.
На картинке приведено позиционирование Divert sockets относительно сетевых уровней, причём имеются стрелочки в обоих направлениях. А вот место функционирования libpcap обозначено как libcap socket (tcpdump) и в виду отсутствия обратной стрелки нам необходима libdnet.
В общем — можно.

bget.h
bget.c
pkt.h
pkt.cДалее создаём файл netemu.c:
#include <stdio.h>
#include <string.h>
#include <pcap.h>
#include "pkt.h"
struct io_s {
/* control structures (mostly uses netwk byte order) */
struct intf_entry *ifent; /* Interface */
ip_addr_t myip; /* My own IP addr (in host byte order) */
struct addr *mymac; /* My own IP MAC addr */
/* global variables */
u_char buf[1024];
uint32_t net; /* Subnet for capture */
uint32_t mask; /* Netmask for capture */
/* handles */
eth_t *eth;
intf_t *intf;
pcap_t *pcap;
rand_t *rnd;
};
typedef struct io_s io_t;
io_t io;
char *lbio_ntoa(const ip_addr_t ip)
{
ip_addr_t ip_tmp = htonl(ip);
return(ip_ntoa(&ip_tmp));
}
void pkt_handler(u_char* client_data, const struct pcap_pkthdr* pcpkt, const u_char* pktdata)
{
return;
}
int main(int argc, char **argv)
{
char dev[1024]="eno1";
char bpfilter[1024]="dst net 10.0.0.0/16";
io.rnd = rand_open();
if ((io.intf = intf_open()) == NULL) {
printf("*** Unable to get libdnet handle for interface %s\n", io.ifent->intf_name);
return;
}
io.ifent = (struct intf_entry *)io.buf;
io.ifent->intf_len = sizeof(io.buf);
strncpy(io.ifent->intf_name, dev, sizeof(io.ifent->intf_name));
if (intf_get(io.intf, io.ifent) < 0) {
printf("*** Unable to get information for interface %s\n", io.ifent->intf_name);
return;
}
if ((io.eth = eth_open(io.ifent->intf_name)) == NULL ) {
printf("*** Couldn't open libdnet link interface\n");
return;
}
char ebuf[PCAP_ERRBUF_SIZE];
#define PCAP_TIMEOUT 100
if ((io.pcap = pcap_open_live(dev, BUFSIZ, 1, -1, ebuf)) == NULL) {
printf("*** Couldn't open pcap device for sniffing\n" );
return;
}
printf("Initiated on interface: %s\n", io.ifent->intf_name);
if (io.myip == 0) {
if (io.ifent->intf_addr.addr_type == ADDR_TYPE_IP) {
if (io.mask == 0) {
addr_btom(io.ifent->intf_addr.addr_bits, &io.mask, IP_ADDR_LEN);
io.mask = ntohl(io.mask);
io.net = ntohl(io.ifent->intf_addr.addr_ip);
io.net &= io.mask;
}
io.myip = ntohl(io.ifent->intf_addr.addr_ip);
} else {
printf("*** Unable to determine IP address from the interface.\n");
return;
}
}
if (io.mymac == NULL) {
if (io.ifent->intf_link_addr.addr_type == ADDR_TYPE_ETH) {
io.mymac = &(io.ifent->intf_link_addr);
} else {
printf("*** The interface must be of type Ethernet.\n");
return;
}
}
printf("Host system IP addr: %s, MAC addr: %s\n", lbio_ntoa(io.myip), addr_ntoa(io.mymac));
struct bpf_program fcode;
if (pcap_compile(io.pcap, &fcode, bpfilter, 0, io.myip) < 0) {
printf("*** Error pcap_compile: %s\n", bpfilter);
return;
}
if (pcap_setfilter(io.pcap, &fcode) == -1) {
printf("*** Error pcap_setfilter\n");
return;
}
printf("Set filter: %s\n", bpfilter);
pkt_init(100);
printf("Init complete\n\n");
pcap_loop(io.pcap, -1, &pkt_handler, NULL);
return;
}
Как писал выше, программирование тут весьма скоренькое и аскетичное — я бы даже назвал всё это прототипированием. В начале подключены стандартные хэдеры для ввода/вывода на консоль и функций работы с памятью. Ещё здесь подключен заголовочный файл pcap.h для захвата пакетов. Заголовочный файл dnet.h не вписываем, т.к. он фигурирует в файле pkt.h от LaBrea.
Структура
io_s это наследие LaBrea, хоть и значительно покоцанное. В неё собраны различные структуры (ссылки) от библиотек dnet/pcap/pkt. Можно было вынести в отдельные глобальные переменные, но проще оставить как есть, мы заведём одну переменную данного типа с именем io.Также из файла
lbio.c позаимствована (скопирована) функция lbio_ntoa для преобразования IP-адреса в текстовый вид.Функция
pkt_handler пока в состоянии «заглушка», мы до неё доберёмся, когда будем пристально рассматривать входящие пакеты.Собственно функция main также чуть менее чем полностью собрана из системы инициализации LaBrea, но хочу обратить внимание, что инициализация и переход в основной цикл обработки у всех программ, использующих libpcap, практически одинаков. Здесь лишь добавлена инициализация для libdnet.
В первых строках видно захардкоженное имя сетевого интерфейса и выражение для фильтра. Сознательно не стал переписывать из примеров libpcap строчки перебора интерфейсов и прочую обвязку. Если необходимо, нагуглите сами, а здесь это будет только раздувать код. Я про это писал в самом начале, просто повторяю.
Жёстко зашитое имя сетевого интерфейса необходимо поменять под свой стенд. Также, если хочется, чтобы машина-эмулятор вообще не светилась в сети, можно расширить выражение фильтра адресом машины, с которой будем работать с фантомной сетью.
Следом идёт инициализация внутренних структур для libdnet. Обучающих материалов по libdnet, как я уже писал, в сети нет и конкретно эти строчки также взяты из LaBrea — они рабочие.
При желании можно заглянуть в исходники libdnet на github и/или посмотреть объявления функций в заголовочных файлах — в моих, отечественных дистрибутивах они находятся в
/usr/include/dnet. У меня вот желания не возникло, поэтому «заклинания» из LaBrea перекочевали в проект практически без изменений.По libpcap имеется достаточное количество обучающих статей и рассматривать каждую строчку не вижу смысла. И также особо туда не вникал — если первый рабочий прототип запустился, то бегом писать полезную нагрузку!
Функция
pkt_init с параметром 100. Данная функция также из комплекта LaBrea, из файлика pkt.c и занимается она тем, что с помощью собственного менеджера памяти (bget.c, bget.h) формирует буфер на 100 пакетов. Можно было бы открутить и заменить на malloc, но решил пока оставить.pcap_loop — финальная функция, которая фильтрует все пакеты по нашему выражению bpfilter и передаёт в функцию pkt_handler.Компилируем и запускаем также на коленке (исходников мало и они небольшие — будет всё быстро):
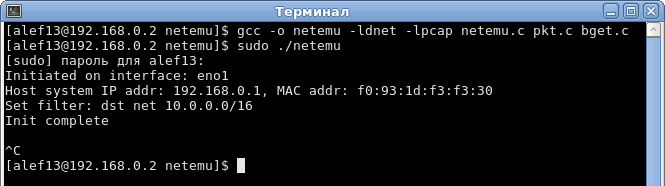
Т.к. у нас не реализована обработка сигналов или другие методы корректного завершения программы, то прерываем её выполнение по Ctrl+C и приступаем к следующему этапу.
▍ Первичная обработка входных пакетов
Функция
pkt_handler в настоящее время пустая и нам необходимо заменить её содержимое.void pkt_handler(u_char* client_data, const struct pcap_pkthdr* pcpkt, const u_char* pktdata)
{
struct pkt *pkt;
if (pktdata == NULL)
return;
if (pcpkt->caplen > PKT_BUF_LEN) {
printf("Dropping oversize packet");
return;
}
if ((pkt = pkt_new()) == NULL) {
printf("Error allocating new packet");
return;
}
memcpy(pkt->pkt_data, pktdata, pcpkt->caplen);
pkt->pkt_end = pkt->pkt_data + pcpkt->caplen;
pkt_decorate(pkt);
if (ntohs(pkt->pkt_eth->eth_type) == ETH_TYPE_IP) {
if (pkt->pkt_ip == NULL) return;
ip_handler(pkt);
}
pkt_free(pkt);
return;
}
В самом начале мы объявили указатель на структуру pkt, которая будет хранить метаданные, связанные с этим пакетом.
Структура объявлена в pkt.h и полностью состоит из структур библиотеки libdnet, а также буфера, в котором содержится сетевой кадр в чистом виде.
Далее мы проверяем наличие данных, длину пакета и делаем копию пакет в нашу структуру pkt.
Потом стоит вызов функции
pkt_decorate(pkt), также взятой из LaBrea. Тут следует как раз более глубоко познакомиться со структурой pkt и её назначением. В заголовочных файлах libdnet — eth.h, arp.h, icmp.h, ip.h, tcp.h, udp.h и т.д. очень хорошо расписана структура заголовков соответствующих протоколов. И если правильно разместить указатели структуры pkt на «сырые» данные перехваченного пакета, то можно легко адресовать и манипулировать полями протоколов верхнего уровня. Т.е. pkt_eth поставить на начало пакета ethernet, то в eth_data надо аккуратно занести адрес первого байта после заголовка Ethernet. По полю eth_type мы определим формат полезной нагрузки и, соответственно, будем использовать либо struct ip_hdr *ip либо struct arp_hdr *arp либо u_char *eth_data для доступа к полям IP, ARP или сырым данным. Объединение ссылок на структуры в union позволяет производить настройку адресации всех структур одним присвоением. Вот именно этим и занимается довольно жирная функция pkt_decorate, а также там проводится небольшая работа по исправлению кривых пакетов. Для удобства имеются несколько макроопределений вида pkt_arp, pkt_ip, pkt_icmp, pkt_tcp_data которыми мы в дальнейшем будем активно пользоваться.После проверки на тип пакета
ETH_TYPE_IP и проверки на корректность указателя структуры pkt_ip мы отдаём пакет на обработку функции ip_handler. Но, т.к. её пока нет, можно написать простейшую заглушку и заново откомпилировать программу. Впрочем, новых визуальных эффектов мы не получим, а посему самое время приступить к написанию более содержательной функции ip_handler.▍ Рассматриваем IP-пакет
А вот здесь начинается уже интересное!
Кусочек кода, который вставляем чуть выше функции
pkt_handler:static void ip_handler (struct pkt *pkt)
{
printf("pkt_eth src:%s dst:%s proto:%04X\n",
eth_ntoa(&pkt->pkt_eth->eth_src),
eth_ntoa(&pkt->pkt_eth->eth_dst),
ntohs(pkt->pkt_eth->eth_type));
printf("pkt_ip v:%d hl:%d tos:%0X len:%d id:%04X off:%0X ttl:%d p:%d sum:%04X src:%s dst:%s\n",
pkt->pkt_ip->ip_v, pkt->pkt_ip->ip_hl*4, pkt->pkt_ip->ip_tos,
ntohs(pkt->pkt_ip->ip_len), ntohs(pkt->pkt_ip->ip_id),
pkt->pkt_ip->ip_off,
pkt->pkt_ip->ip_ttl, pkt->pkt_ip->ip_p,
ntohs(pkt->pkt_ip->ip_sum),
lbio_ntoa(ntohl(pkt->pkt_ip->ip_src)),
lbio_ntoa(ntohl(pkt->pkt_ip->ip_dst)));
switch(pkt->pkt_ip->ip_p) {
case IPPROTO_TCP:
if (pkt->pkt_tcp == NULL) return;
printf("pkt_tcp sport:%d dport:%d seq:%0d ack:%d off:%d flags:%0X win:%d sum:%04X\n",
ntohs(pkt->pkt_tcp->th_sport), ntohs(pkt->pkt_tcp->th_dport),
ntohl(pkt->pkt_tcp->th_seq), ntohl(pkt->pkt_tcp->th_ack),
pkt->pkt_tcp->th_off*4, pkt->pkt_tcp->th_flags,
ntohs(pkt->pkt_tcp->th_win), ntohs(pkt->pkt_tcp->th_sum));
break;
case IPPROTO_UDP:
if (pkt->pkt_udp == NULL) return;
printf("pkt_udp sport:%d dport:%d ulen:%d sum:%04X\n",
ntohs(pkt->pkt_udp->uh_sport), ntohs(pkt->pkt_udp->uh_dport),
ntohs(pkt->pkt_udp->uh_ulen), ntohs(pkt->pkt_udp->uh_sum));
break;
case IPPROTO_ICMP:
if (pkt->pkt_icmp == NULL) return;
printf("pkt_icmp type:%d, code:%d, cksum:%04X\n",
pkt->pkt_icmp->icmp_type,
pkt->pkt_icmp->icmp_code,
ntohs(pkt->pkt_icmp->icmp_cksum));
return;
default:
break;
}
printf("\n");
return;
}
В настоящее время эта функция выводит заголовки сетевых протоколов. В параметрах функции printf наглядно видно, как обращаться к полям заголовков различных протоколов, а также где требуется преобразование порядка следования байт.
Мы смело пишем заголовки ethernet и ip без проверки протоколов, т.к. чётко понимаем, что именно нам отдаёт libpcap на основе фильтра. А вот далее нам необходимо производить рассмотрение пакетов в зависимости от типа протокола в IP-пакете.
В начале каждого case у нас стоит проверка на NULL, на случай сбоя
pkt_decorate. Что означают данные, которые мы рисуем, необходимо смотреть в соответствующей литературе. Приведу источники:- INTERNET PROTOCOL — RFC 791
- Transmission Control Protocol (TCP) — RFC 9293
- User Datagram Protocol — RFC 768
- ICMP — RFC 792, 950, 1256, 1393, 1475, 2002, 2521
По протоколу TCP сослался на самый свежий RFC, по нему недавно была здесь
статья, однако libdnet опирается на RFC 793. Ничего страшного в этом нет, т.к. радикально нового и несовместимого в RFC 9293 не занесли — просто собрали все расширения вместе.
Читать RFC в оригинале круто, интересно, схемы и структуры пакетов там клёвые, но иногда хочется что-нибудь более доходчивое и на родном языке. В данном случае могу посоветовать книгу У.Р.Стивенса «Unix. Разработка сетевых приложений»:

После компиляции можно пробовать. Для начала с соседней машины попингуем какой-либо адрес из нашей несуществующей сети. На консоли должна отобразиться расшифровка входящих icmp-пакетов. Затем очередь протокола UDP. Это просто — запускаем snmpget на тот-же адрес. И завершаем проверкой TCP (запуск telnet):

Всё работает как и ожидалось — уже понятно, что можно получать пакеты и как разбирать их структуру.
В дальнейшем, когда начнёте формировать сетевые пакеты вручную, рекомендую трафик рассматривать через tcpdump или wireshark — они показывают структуру пакетов в более детальном виде, а также указывают ошибки в некорректных пакетах.
▍ Отвечаем на ping
Сначала небольшое изменение в функцию ip_handler — после вывода на консоль содержимого icmp-пакета добавим несколько строк кода:
struct addr a;
addr_aton("10.0.0.13", &a);
if ((pkt->pkt_icmp->icmp_type == ICMP_ECHO)
&& (pkt->pkt_icmp->icmp_code == ICMP_CODE_NONE))
if (pkt->pkt_ip->ip_dst == a.addr_ip) send_icmp_reply(pkt);
Здесь всё просто и понятно — мы завели структуру для IP-адреса и занесли туда информацию из привычной нам десятично-точечной формы IP-адреса (и структура и функция задекларированы в dnet/addr.h). Далее проверяем, что полученный пакет
ICMP_ECHO — было-бы нелогично отзываться на пакеты другого типа. Затем проверяем кого пингуют — если это хост 10.0.0.13 то вызываем функцию send_icmp_reply которой в параметрах передадим исходный пакет.Для этого создадим чуть выше функции ip_handler нашу новую функцию:
void send_icmp_reply(struct pkt *pkt)
{
struct pkt *new = NULL;
new = pkt_dup(pkt);
new->pkt_icmp->icmp_type = ICMP_ECHOREPLY;
eth_pack_hdr(new->pkt_eth,
pkt->pkt_eth->eth_src, /* orig src MAC becomes new dest MAC */
io.mymac, /* my own mac becomes new src MAC */
ETH_TYPE_IP);
ip_pack_hdr(new->pkt_ip,
0, /* tos */
ntohs(new->pkt_ip->ip_len), /* IP hdr length */
rand_uint16( io.rnd ), /* ipid */
0, /* frag offset */
IP_TTL_DEFAULT,
IP_PROTO_ICMP, /* ip protocol of original pkt */
pkt->pkt_ip->ip_dst, /* orig dst becomes new src addr */
pkt->pkt_ip->ip_src);
ip_checksum(new->pkt_ip, new->pkt_end - new->pkt_eth_data);
int ret_code = eth_send(io.eth, new->pkt_eth, new->pkt_end - (u_char *) new->pkt_eth);
if (ret_code < 0)
printf("*** Problem sending packet\n");
pkt_free(new);
return;
}
Это довольно простая функция, т.к. ответный пакет icmp на пинг имеет очень идентичную структуру и состав. Первым делом формируем новый пакет, но не с нуля, а полным дублированием входящего пакета. Это значительно упрощает нашу задачу, т.к. пакет запроса и ответа фактически одинаковые и в них только меняется тип пакета с исходным и приёмным адресами. Также функция
pkt_dup корректно расставляет указатели на заголовки пакетов.После дублирования ставим тип icmp-пакета как
ICMP_ECHOREPLY.Макросом
eth_pack_hdr (объявлен в dnet/eth.h) корректируем поля eth — в качестве приёмникаMAC-адрес машины, которая нас пингует. В поле src вписываем свой MAC-адрес, т.к. мы находимся в одном домене коллизий и являемся «честным» маршрутизатором :).
Следующий макрос
ip_pack_hdr (объявлен в dnet/ip.h) правим заголовки IP. Аналогично меняем местами IP-адреса. Можно ещё поменять ttl пакета, чтобы показать, что мы находимся за несколькими маршрутизаторами, или как здесь поставить IP_TTL_DEFAULT.Считаем контрольную сумму IP-пакета и производим отправку его в сеть.
Компилируем и пробуем пинговать адреса 10.0.0.13 и 10.0.0.1:
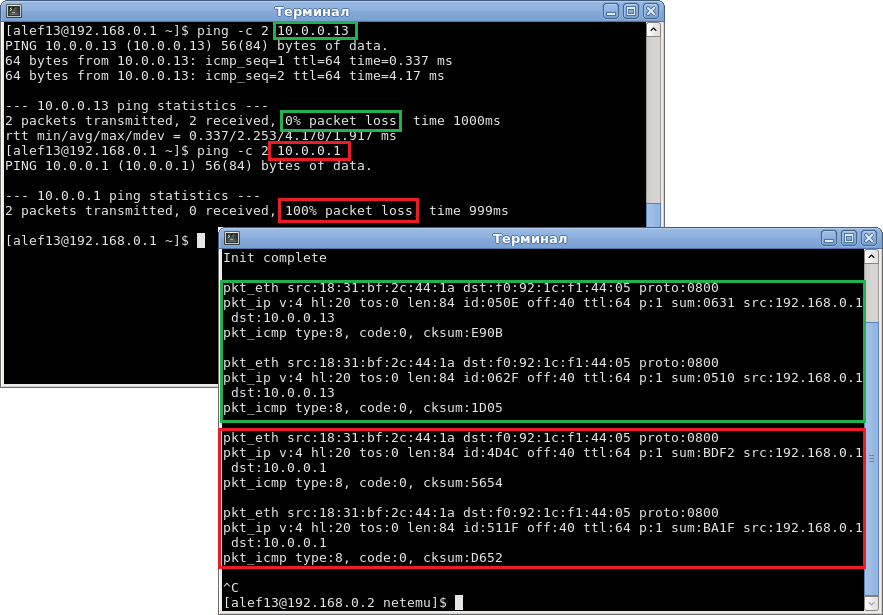
▍ Усложняем пример — грамотно отказываемся пинговаться
Правим ip_handler:
if (pkt->pkt_ip->ip_dst == a.addr_ip)
send_icmp_reply(pkt);
else
send_icmp_unreach(pkt, "10.0.5.30", ICMP_UNREACH_NET);
Изменения в логике программы — мы пингуем и получаем честный ответ от 10.0.0.13, а остальное нам должно выводить отбой в виде сообщения «Destination Net Unreachable» и не просто 100% потерю пакетов, как раньше, а ещё полноценное количество ошибок.
Как видно у нас появляется новая функция send_icmp_unreach с дополнительными параметрами. Связано это с тем, что пакет типа
ICMP_UNREACH детализирует причину отбоя в поле code. Причин этих может быть несколько, а точнее 16 видов. Перечислять и толковать их здесь не буду — сами посмотрите в соответствующей литературе или в dnet/icmp.h. В нашей ситуации идеально подойдут ICMP_UNREACH_NET и ICMP_UNREACH_HOST.А вот и реализация
send_icmp_unreach:void send_icmp_unreach(struct pkt *pkt, char *host, int reason)
{
struct pkt *new = NULL;
if ((new = pkt_new()) == NULL) {
printf("*** Error allocating the new outbound pkt\n");
return;
}
eth_pack_hdr(new->pkt_eth,
pkt->pkt_eth->eth_src, /* orig src MAC becomes new dest MAC */
io.mymac, /* my own mac becomes new src MAC */
ETH_TYPE_IP);
int quote_len = pkt->pkt_ip->ip_hl*4 + 8; /* original packet IP header + 8 bytes */
struct addr a;
addr_aton(host, &a);
ip_pack_hdr(new->pkt_ip,
0, /* tos */
(IP_HDR_LEN + ICMP_LEN_MIN + quote_len), /* IP hdr length */
rand_uint16( io.rnd ), /* ipid */
0, /* frag offset */
IP_TTL_DEFAULT,
IP_PROTO_ICMP, /* ip protocol of original pkt */
a.addr_ip,
pkt->pkt_ip->ip_src);
new->pkt_icmp_msg = (union icmp_msg *)(new->pkt_ip_data + ICMP_HDR_LEN);
new->pkt_end = (u_char *)new->pkt_eth_data + ntohs(new->pkt_ip->ip_len);
icmp_pack_hdr_quote(new->pkt_icmp, ICMP_UNREACH, reason, 0, pkt->pkt_ip, quote_len);
/*
new->pkt_icmp->icmp_type = ICMP_UNREACH;
new->pkt_icmp->icmp_code = reason;
new->pkt_icmp_msg->unreach.icmp_void = 0;
memcpy(new->pkt_icmp_msg->unreach.icmp_ip, pkt->pkt_ip, quote_len);
*/
ip_checksum(new->pkt_ip, new->pkt_end - new->pkt_eth_data);
int ret_code = eth_send(io.eth, new->pkt_eth, new->pkt_end - (u_char *) new->pkt_eth);
if (ret_code < 0)
printf("*** Problem sending packet\n");
pkt_free(new);
return;
}
На первый взгляд функция не особо отличается от
send_icmp_reply, однако здесь всё сложнее.Для начала — новый пакет мы получаем не дублированием входящего, а созданием с нуля.
Манипуляции с eth без изменений — тут ничего дополнительно не придумать.
Далее вычисляем длину «цитируемого» участка (quote_len). Это необходимо потому, что когда формируется пакет icmp-unreachable, то в качестве данных прикладывается заголовок ip-дейтаграммы и первые 8 байт исходного пакета. Этих данных обычно достаточно для проведения дальнейшей диагностики причины недоставки пакета.
Как её считаем: берём размер заголовка ip исходного пакета (он указывается в 32-битовых словах, поэтому умножим на 4) и добавляем ещё 8 байт.
Формирование заголовка IP для нашего нового пакета. Очень важный момент — правильно посчитать длину пакета. Длина ip-пакета будет состоять из длины IP-заголовка (IP_HDR_LEN — dnet/ip.h), длины ICMP-заголовка (ICMP_LEN_MIN — dnet/icmp.h) и длины цитируемого участка (quote_len).
Также тут в качестве IP-адреса исходящего пакета указан «левый» адрес — по стандарту отбой генерирует устройство, которое обнаружило проблему.
Именно данная возможность позволяет нам отследить маршрут трафика к конечному устройству. С помощью traceroute последовательно отправляются в адрес устройства пакеты с нарастающим ttl — от 1 до победы. После каждого «прыжка» через маршрутизатор ttl уменьшается на единицу. Если ttl обнулилось, то маршрутизатор, который это заметил, генерирует в адрес отправителя пакет icmp типа
ICMP_TIMEXCEED со своим адресом, в качестве исходящего адреса пакета. На основании этих пакетов утилита traceroute выводит перечень транзитных узлов до целевой системы. Ну и также следует упомянуть что отбой можно генерировать не только на icmp-пакеты, как в примере, а вообще на ip-пакеты с любым протоколом.Так как мы сформировали пакет «с нуля», то для дальнейшей работы необходимо правильно разместить указатели в структуре pkt. Следующие две строчки приводят в порядок указатели
pkt_icmp_msg и pkt_end. Мы не можем здесь воспользоваться pkt_decorate, т.к. наш пакет ещё не доделан.Корректная установка
pkt_icmp_msg позволяет нам использовать макрос icmp_pack_hdr_quote (dnet/icmp.h), который соберёт ответный пакет и вложит в него необходимое количество байт из оригинального пакета. Если нет желания применять макрос, то собираем данные для icmp-ответа вручную. Соответствующий код закомментирован.В конце стандартно — подсчёт контрольной суммы и отправка.
Повторяем эксперимент с пингами, результат завораживает:

И если бы мы не знали как сформированы эти ответы, то были бы немного удивлены каким образом могут приходить пинги из недостижимой сети :)
▍ SNMP
Задача на первый взгляд также несложная. Однако и тут есть некоторые тонкости, из-за которых возникает желание убрать из названия слово Simple. Прежде всего это использование ASN.1 для кодирования всей информации — как запросов, так и ответов. Насколько это просто можно глянуть в статье ASN.1 простыми словами..
Ну и сам протокол SNMP также заслуживает особого внимания.
Для своих нужд, я не стал занимался реализации asn.1 декодера/кодера с нуля, да и внутренности snmp-пакетов разбирал только на бумажке, когда прикручивал к своему проекту библиотеку csnmp (Copyright © 2019 Nikifor Seryakov).
В виду большого объёма как пояснений, так и примеров, это всё планирую вынести в отдельную статью.
▍ Конец
Вот и всё, проект свой я ещё не завершил, но «кирпичиков» для его фундамента уже достаточно, чтобы на слабой офисной машинке развернуть огромную сеть-мираж, где будут пинговаться несуществующие хосты, приходить непонятные отбои и бесследно исчезать сетевые пакеты.
На этом закругляемся — думаю, что первое знакомство с libpcap и libdnet состоялось.
Telegram-канал и уютный чат




