Привет, Хабр! Меня зовут Виктор Кантор, я директор Big Data МТС. Около 14 лет я работаю с технологиями, связанными с Machine Learning, Big Data, Data Science. Но есть одна проблема, с которой я постоянно сталкиваюсь. Например, поставлена задача, которую нужно решить при помощи ML-моделей. А потом появляется новая, с аналогичным процессом разработки и кодом. А затем ещё одна, вторая, третья…
В итоге я решил всё это формализовать, структурировать, привести к состоянию платформ, которые можно использовать повторно. Зачем? Чтобы специалисты по ML, Data Science и из смежных отраслей не писали один и тот же код много раз. В статье об этом и поговорим. Если тема вас заинтересовала, прошу под кат.

Как извлечь пользу из данных
Существует два больших направления работы с Big Data:
Аналитика. Построение отчетности, дашбордов, сегментация клиентов ручными правилами, подведение итогов экспериментов. Например, это может быть создание графиков, которые помогают понять, что команде стоит улучшить и оптимизировать при развитии продукта. Это направление помогает принимать решения на основе данных.
Пример — система оповещений и индикации по заданным параметрам от бизнеса. Также это может быть изучение рынка и операционных показателей компании и профилирование.
Аналитику можно интегрировать с ML. Какие возможности это даёт?
Выявление аномалий в метриках, искать закономерности и делать выводы;
Предсказание трендов и коридоров, прогнозирование (например, качества продаж или размера контракта);
Оценка дальнейших действий (например, рациональности инвестиций в каналы до, собственно, инвестиций и потерь)
Машинное обучение. Построение прогнозов на основе набора данных. Например, вероятностная модель действий клиента — откликов на предложения, рисков, предсказание возврата инвестиций (ROI) и прибыль от конкретных клиентов (LTV клиента). Используется для автоматизации принятия решений на базе определенного набора информации.
В этой статье я хочу сделать упор как раз на машинное обучение.
Под спойлером ниже я рассказываю о стандартных задачах, которые решает машинное обучение. Этот раздел особенно актуален для людей, ранее не знакомых (или знакомых мало) с ML. Загляните под спойлер, если хотите узнать об этом больше.
Спойлер
Итак, что такое машинное обучение? Для наглядности приведу таблицу с примерами:

В этой таблице — информация по клиентам: как часто они что-то у нас покупают, сколько при этом жалоб от них поступало, средний чек, срок сотрудничества с клиентом в целом. Также дан такой параметр, как отказ от работы с нашей продукцией.
На этих данных мы учим алгоритм работать с похожими ситуациями. Например, мы не знаем, уйдёт от нас клиент или нет, и пытаемся спрогнозировать его действия в ближайшем будущем с помощью алгоритма. Например, если модель показывает, что человек готов уйти, мы начинаем работать на его удержание.
Прогностическая модель нуждается в математическом описании объектов, которые мы анализируем. Эти данные и есть то, что мы собираем в Big Data.
С помощью машинного обучения можно решать несколько видов задач.
Например, классификация:
анализ того, будет ли кредит возвращен в срок. Классы — «да» или «нет»;
определение позитивной и негативной тональности отзыва;
прогноз, прекратит ли клиент пользоваться услугами компании;
определение темы текста. Классы — заранее заданный набор тем.

А ещё — регрессия:
прогнозирование размера выплаты по задолженности;
определение массы дефекта на производстве;
вероятностный анализ стоимости ценной бумаги;
прогностическая модель температуры, давления и скорости ветра в регионе.

Ещё одна стандартная задача — кластеризация:
выделение тем в большом наборе текстов без предварительного списка тем;
выявление сегментов целевой аудитории;
распределение водителей по типу вождения в логистической компании (например, «лихачи» и водящие спокойно) для предсказания поломок, подбора страховки и т. д.

В некоторых задачах есть примеры правильных ответов (supervised learning), а есть те, где их нет (unsupervised learning).

Конечно, для бизнеса полезнее всего задачи с supervised learning, в особенности классификация. Почему? Во-первых, такие задачи мы решаем лучше всего, а во-вторых, бизнесу нужны точные данные, а их обеспечивают supervised learning и классификация.
Какие ML-платформы требуются бизнесу
Для нас очевидно, что ML-модели нужны, причем для самых разных направлений работы и отраслей. Но создавать их каждый раз вручную нерационально и невыгодно: ведь для каждой новой задачи разрабатывается примерно одно и то же.
Мы решили создать универсальные «кубики», из которых собираются новые модели для любого продукта, что повышает эффективность работы.
Но что можно платформизировать, а что нет? Ответ не такой уж и простой, зайду немного издалека. Так, у нас есть какие-то простые платформы, которые описывают функционирование нашего бизнеса. Посмотрим на юнит-экономику сервиса музыки.

Если взять B2C, то наша модель влияет на все составляющие юнит-экономики. Ведь если мы хотим, чтобы пользователь оставался с нами, продлевал подписку на сервис, то нам нужно больше его вовлекать и помогать ему регулярно возвращаться к сервису.

Есть ещё один нюанс — эффективность трат в юнит-экономике можно оценить далеко не всегда. Кроме затрат на привлечение пользователя есть и другие виды расходных статей. Это, например, поддержка и разработка сервиса.
И таких скрытых статей расходов довольно много. Но ML может оптимизировать и их. Например, машинным обучением можно автоматизировать ответы на обращения в саппорт, что снизит для компании затраты на техподдержку.
Посмотрим на всё это с продуктовой точки зрения. Например, при развитии продукта есть несколько стадий:
На стадии интенсивного захвата рынка бизнесу важны конверсии в просмотры, действия на сайте и в приложении, retention и другие показатели вовлечения.
Когда доля рынка уже получена и прибыль оптимизируют, актуальность обретают денежные метрики. Иными словами, где это возможно, деньги начинают экономить.

Если всё это максимально обобщить, то в любом процессе в компании есть определенный профит, который бизнес получает от взаимодействия с клиентом. И есть убытки — например, выдача кредита неблагонадежному клиенту.
Все ML-модели можно разложить в рамках этого представления.

У нас есть разные модели, одни больше влияют на конверсии, другие — на деньги, третьи — на убытки, позволяя ими управлять. С другой стороны — факторы, которые влияют на компанию, включая персонал. Его эффективность работы можно повышать. Есть в компании и необходимость учета материальных ресурсов — например, базовые станции или ритейл в магазинах.
Для каждого упомянутого элемента можно создать модель, которая решает определенные проблемы и выполняет необходимые для бизнеса задачи.

Так, для повышения конверсии нужна рекомендательная система, для улучшения финансовых показателей требуется смарт-прайсинг на базе определенных данных, а для работы с убытками используется скоринговая модель или модель для таргетинга.
То же касается и самой компании. Так, для оптимизации численности можно автоматизировать, например, техподдержку, для процессов вводить process mining, для материальной базы — smart CAPEX, планирование оправданных инвестиций.
Примеры ML-платформ МТС
Сейчас расскажу, как мы это используем в сервисах экосистемы МТС.
Рекомендации. Это центральный элемент нашей экосистемы. Для того чтобы она работала, требуются каталог продуктов и история поведения пользователя — что он лайкнул, что ему не понравилось и т. п.

Мы стандартизируем данные на входе — кто что смотрел и лайкал в каталоге, что покупали пользователи и так далее. Данные должны иметь одинаковый формат, с идентичными ID, типами события и так далее. Внутри платформы сами витрины называются одинаково, имеют одинаковые колонки и типы данных.
Дальше данные уходят в модуль для загрузки исходной информации — ETL для автоматизированного построения ML-моделей.
Чтобы внешний сервис мог «забрать» рекомендации, наружу выставляется API. Сервис-потребитель (например, KION), спрашивает: «Что я могу порекомендовать пользователю?», а API отдает результат — «Рекомендуй вот то и вот это.»
На выходе получаем либо персонализированную подборку для пользователя, либо рекомендации для какой-то позиции каталога.

Сейчас расскажу, как мы используем рекомендации в сервисе KION.
Подробно об этом мои коллеги уже писали в статье «Бегущий по витринам KION. Как контент попадает на витрины приложений». Если коротко, то во всех онлайн-кинотеатрах используются рекомендательные системы, без них в современном мире никуда. В наш сервис встроены различные модели, на скрине — наиболее показательные примеры:

Конечно, мы регулярно проверяем, насколько эффективны ML-рекомендации по сравнению с экспертными.

Например, в декабре 2022 года одну из ML-полок в KION в порядке эксперимента заменили на ручные подборки. Но 16 января 2023 года мы вернули эту опцию. Как оказалось, использование Machine Learning в рекомендательных системах гораздо эффективнее «ручной» работы. Это видно на графике:
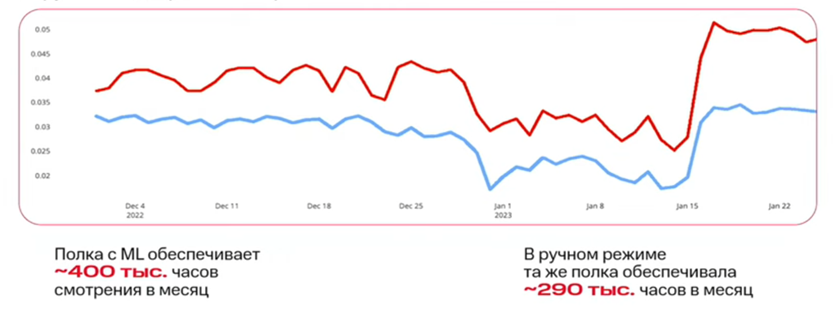
Паттерны поведеяния пользователей наблюдаются в любых сервисах, а значит, эксплуатирующие их рекомендации тоже можно применить в любом сервисе экосистемы. На базе «кубиков» системы, разработанной для KION, мы смогли создать аналогичный проект для онлайн-магазина МТС. Конечно, отдельные элементы потребовалось доработать: ритейл сильно отличается от потребления медиаконтента. Но в итоге всё заработало как нужно.
Digital HR

У нас было много экспериментов с использованием машинного обучения для работы с кадрами. Мы оцифровывали активность и эффективность работы сотрудников, скорость их адаптации, риски увольнения.
И наш главный вывод здесь вполне ожидаем: люди — это достаточно сложный объект и их не так просто просчитать математикой. Часто получается, что модели нам передают ложные выводы.
Например, у нас был кейс, когда сотрудник сменил место жительства, а ML-модель решила, что он собирается увольняться. Почему? Потому что кроме привычного ей рабочего круга общения у него появились новые контакты, связанные с переездом и взаимодействия с ними. Модель решила, что раз человек занимается чем-то кроме работы, он наверняка собрался увольняться. И таких примеров, на самом деле, много.
В итоге мы поняли, что цифровизацию HR-отрасли в виде интеграции ML, Big Data и прогностики внедрять нужно крайне осторожно.
Скоринговая платформа МТС

Термин «скоринг» пришёл к нам из банковского бизнеса. Для оценки надежности заемщика там применялись системы правил — скор-карты. Когда их составление автоматизировали с помощью моделей машинного обучения, название перешло на скоринговые модели.
Изначально так называлась система оценки заемщиков.
Кроме того, ML применяется и в других отраслях — например, в антифрод-системах. Владелец маркетплейса не хотел бы видеть мошенников среди своих пользователей и клиентов, верно? Для того чтобы с этим бороться, можно и нужно применять прогностические модели с целью выявления злоумышленников.

И для работы такой платформы можно использовать любую модель, которая может ответить на вопрос «Случится какое-либо событие или нет?». Например, модель, которая позволяет прогнозировать, останется с нами клиент или нет. «Вернет ли человек задолженность после первого звонка или нет?», «Погасит ли он кредит вовремя или нет?» и так далее.
Скоринговая платформа устроена достаточно просто, вот её структура:

Что внутри этой платформы?
Feature store для хранения моделей. Например, сами факты просрочек — это feature. Они хранятся хранятся в feature store вместе с конкретными значениями по пользователю, метаданными и т. д.
На этапе обучения модели мы используем скрипты автоматического обучения. При внедрении — методы CI/CD. А за применение отвечает оркестратор, запускающий модель.
Системы мониторинга поступающего потока данных. Мы контролируем его распределение и качество данных. Также мы следим, чтобы то, на чем применяется модель, соответствовало тому, на чем она обучалась. Например, модель, обученную на физлицах, нельзя применять к юрлицам.
В целом это похоже на рекомендательную систему, но со своими особенностями.
Прогнозирование дохода базовых станций радиодоступа
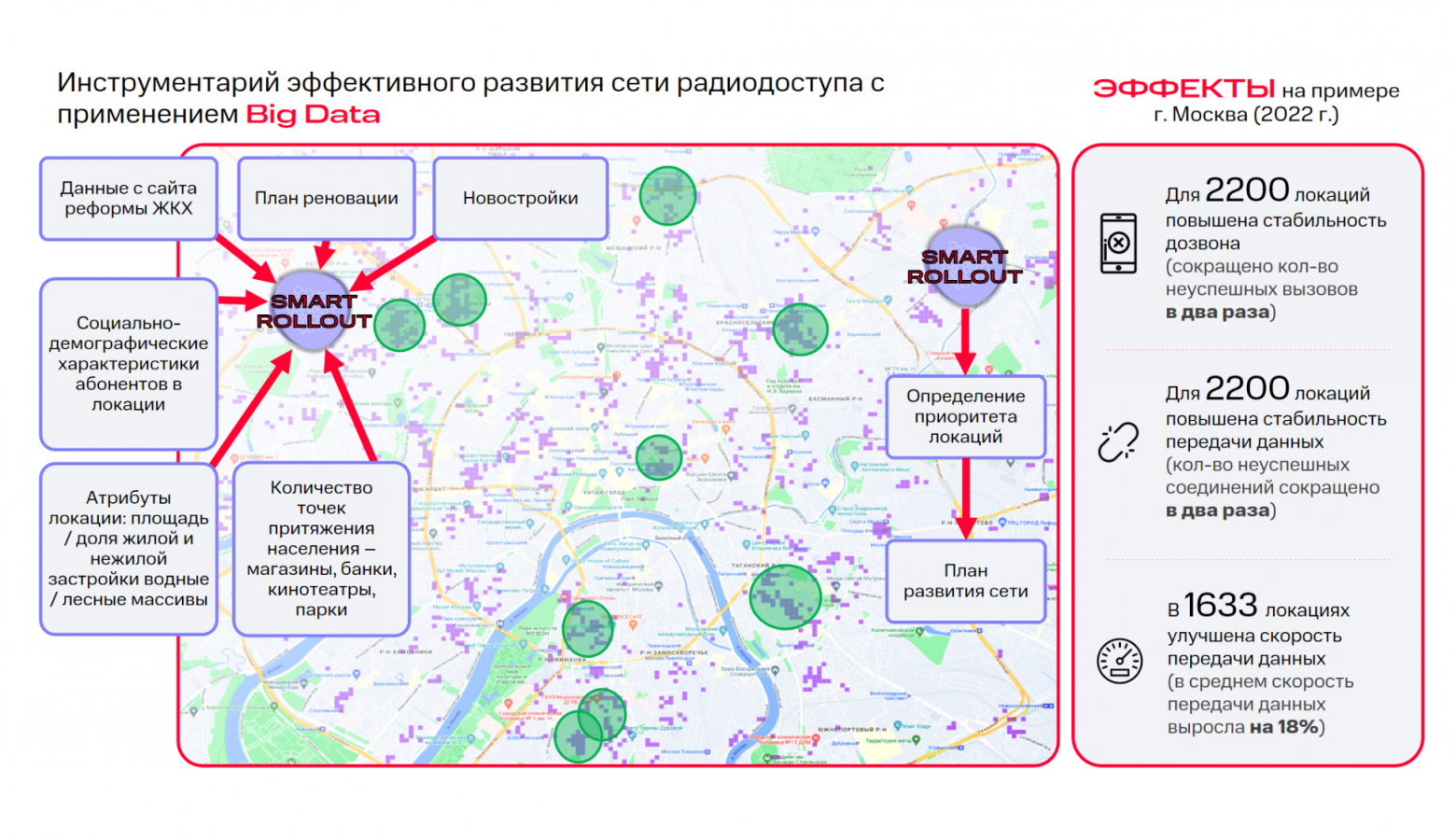
МТС — это ещё и мобильный оператор. Нам нужно расширять сеть и поддерживать ее работу, чтобы клиенты были довольны. Но бюджет не безграничен, всегда есть определенный лимит.
При работе с инфраструктурой часто возникают вопросы вроде постройки новых станций, отказа от развертывания других, обновления и ремонта оборудования и так далее. Нам нужно учитывать огромное количество исходных данных:
население региона;
плотность застройки;
наличие магазинов, банков, парков и т. п.
Тут на помощь приходит машинное обучение. Оптимизация инфраструктуры с применением ML дает возможность экономить миллиарды рублей ежегодно!
Система блокировки спама

Кого из нас не раздражают спам-звонки с предложениями купить квартиру или пройти диагностику позвоночника? Думаю, таких нет. Нам, как оператору связи, эти звонки тоже доставляют неприятности.
Спам-звонки, которые получают клиенты, — лишь малая толика подобных вызовов. Их гораздо больше, но мы стараемся отфильтровать большую часть.
Для этого мы отслеживаем паттерны поведения спамеров при помощи ML-моделей, вычисляем и блокируем их.
Управление ценами на основе данных

Управление ценами на основе данных (прайсинг) применяется часто, и его тоже можно разложить на «кубики».
Вот мы собрали данные о товарах, поняли поведение пользователя — что он купил, что не купил, за сколько. Дальше отдельным «кубиком» идет сбор информации о рынке — что есть в наличии у конкурентов, чего нет.
И третий «кубик» — это ответ на вопрос: «Что мы сейчас оптимизируем?». Так появляется модуль оптимизации. Если у нас период захвата большей доли на рынке, то мы можем оптимизировать количество продаж в штуках. Если мы хотим просто максимизировать выгоду компании, то здесь уже это всё переводится условно в деньги.
Геоэффект

Эта платформа — инструмент поддержки управленческих решений на основе данных о населении, геотрекинга, мобильного трафика и данных экосистемы МТС.
Она оказалась востребована не только внутри компании, но и для решения задач вовне. Её активно применяют, например, для решения задач транспорта в разных регионах, при планировании строительства, реконструкции и так далее.
Это не все наши платформы, я привёл лишь несколько примеров, которые демонстрируют роль машинного обучения в самых разных отраслях.
Развитие среды в ML
Здесь я хочу поговорить о том, кто вообще может решать задачи, о которых рассказывалось выше. Как оказалось, это сложный вопрос. Так, даже если собрать команду высококлассных специалистов для решения ряда похожих проблем, они охотнее выполнят рутинную работу, каждый раз создавая новый код, чем озаботятся вопросом переиспользования уже готовых модулей.
Как мне кажется, основных причин не-переиспользования кода две. Но очень хочу узнать мнение читателей и, возможно, в будущем дополнить этот список.
Возможно, первая причина в том, что специалистам — дата-инженерам, экспертам по машинному обучению и т. п. — не хочется снижать собственную ценность. И если вдруг нужно не из готовых кубиков собирать, а писать с нуля, то работа сложнее и ценнее. Поэтому платформы могут привести к противоречию с какими-то внутренними интересами конкретного специалиста.
Второй причиной может быть то, что для сборки из имеющихся универсальных «кубиков» требуется специфический опыт. Чаще всего те, кто говорят, что «Это невозможно, нельзя сделать все единой платформой», на самом деле, просто мало раз эту задачу решали. Но есть те, кто решил 3-4 раза одну и ту же задачу и начал подозревать, что это все можно переписать как некую единую библиотеку для решения таких задач.
Как же изменить ситуацию?
Для того чтобы появились специалисты по созданию универсальных платформ, необходимо их готовить. И мы это делаем — например, запустили «Школу аналитиков данных», сформировали курс по разработке рекомендательных систем на Python для магистрантов ИТМО и предприняли ряд других инициатив.

Для того чтобы наши новые сотрудники научились решать задачи построения ML-платформ, требуется уже в вузе прививать к этому интерес. И мы стараемся это делать. Например, предложили проект для студентов — настроить на базе платформы рекомендаций поиск фильмов по их неформальному описанию.

В итоге студенты начинают понимать, как работают рекомендательные системы, а также как формализовать решение похожих задач.
Кроме этого, наши наработки по платформам мы выкладываем в виде open source lib: Ambrosia для проведения A/B-тестов со множеством статистических подходов, RecTools для построения рекомендаций.

Подведу итог статьи:
Во-первых, проблема «не-переиспользования» кода, которую я обозначил в самом начале, нашла решение. Код можно дорабатывать, развивать, крутить всеми доступными способами. Это решение требует улучшений и изменений, но постепенно становится действительно универсальным. Думаю, уже скоро все команды МТС смогут использовать в работе своеобразные «конструкторы» для сервисов с машинным обучением.
Во-вторых, мы нашли решение проблемы нехватки кадров, готовых к работе с такими конструкторами. Хоть это и не решение «здесь и сейчас», но это работа на перспективу.
В-третьих, очень хочется продвигать идею удобства конструкторов ML-платформ для многих сфер и видов бизнеса. Полагаю, этот вопрос станет постепенно все более актуальным.
Спасибо, что дочитали эту статью. Если у вас остались вопросы — обязательно присылайте их в комментарии, обсудим эту тему.



