Большие предобученные модели для обработки естественного языка (Natural Language Processing, NLP), такие как BERT, RoBERTa, GPT-3, T5 и REALM, использующие корпусы полученных из Интернета текстов на естественном языке и тонко настроенные под конкретную задачу, добились значительных успехов в различных NLP задачах. Однако текст на естественном языке сам по себе представляет собой достаточно ограниченный набор знаний, а факты могут быть выражены множеством разных слов. Более того, обилие информации, неподкрепленной фактами, а также токсичное содержание текстов может в результате стать причиной наличия нежелательной предвзятости в итоговых моделях.
Альтернативным источником информации являются графы знаний (Knowledge Graphs, KGs), которые состоят из структурированных данных. Графы знаний фактологичны по своей природе, поскольку информация обычно извлекается из более авторитетных источников, и последующая пост-обработка и ручная редактура позволяют гарантировано избавиться от неприемлемого или некорректного содержания. Таким образом, модели, которые могут включить в себя графы знаний, обладают преимуществом, связанным с большей достоверностью и сниженной токсичностью. Однако структурированный формат графов осложняет их интеграцию в существующие корпуса для предварительного обучения языковых моделей.
В статье «Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training» (KELM), принятой на конференцию NAACL 2021, авторы исследуют возможность преобразования графов знаний в синтетические предложения на естественном языке для аугментации существующих корпусов, что позволяет включить графы в процесс предварительного обучения языковых моделей без изменения их архитектуры. В этой связи авторы использовали выложенный в открытый доступ граф English Wikidata KG и перевели его в текст на естественном языке для того, чтобы создать синтетический корпус. Затем в качестве метода для включения графов знаний в корпус, авторы аугментировали REALM, языковую модель на основе текстового поиска, с помощью созданного синтетического корпуса. Авторы выложили его в открытый доступ для более широкого круга исследователей.
Преобразование графов знаний в текст на естественном языке
Графы знаний состоят из фактической информации, представленной в явном виде в структурированном формате, как правило, в форме троек вида: [субъектная сущность, отношение, объектная сущность],
например, [10x10 Photobooks, основание, 2012 г.]. Группа связанных троек называется подграфом сущности. Примером такого подграфа, который основывается на предыдущем примере тройки, является: {[10x10 Photobooks, экземпляр, Некоммерческая организация], [10x10 Photobooks, основание, 2012]}, проиллюстрированный ниже. Граф знаний можно рассматривать как подграфы взаимосвязанных сущностей.
Преобразование подграфов в текст на естественном языке — стандартная задача в NLP, известная как генерация данных в текст (data-to-text generation). Несмотря на значительный прогресс в этой области на тестовых наборах данных, таких как WebNLG, генерация всего графа знаний в естественный текст сопряжена с дополнительными проблемами. Сущности и отношения в больших графах более обширны и разнообразны, чем небольшие тестовые наборы данных. Более того, последние состоят из предопределенных подграфов, которые могут формировать складные осмысленные предложения. Для всего же графа необходимо дополнительно создавать такую сегментацию на подграфы сущностей.
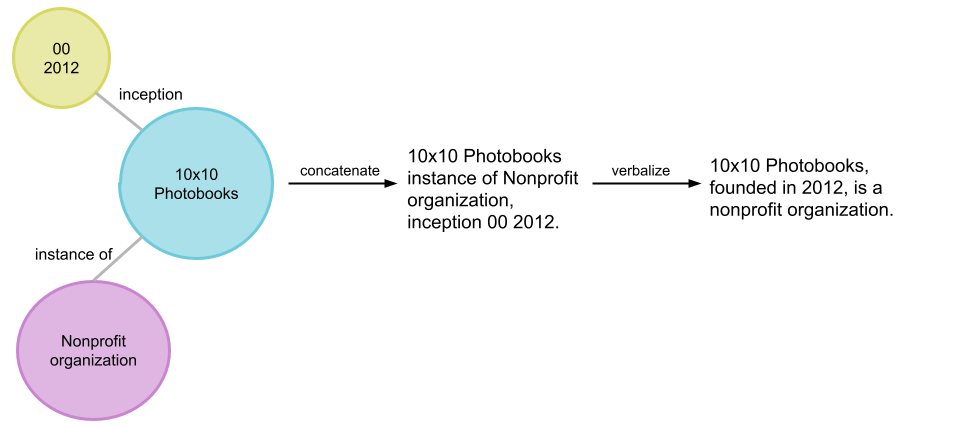
Пример иллюстрации того, как пайплайн преобразует подграф сущности (в пузырьках) в синтетические предложения на естественном языке (крайнее справа).
Чтобы преобразовать граф знаний Wikidata KG в синтетические естественные предложения, авторы разработали пайплайн вербализации под названием «Text from KG Generator» (TEKGEN), который состоит из следующих компонентов: большой обучающий корпус эвристически выровненного текста Википедии и троек Wikidata KG, text-to-text генератор (T5) для преобразования троек графа знаний в текст, модуль, создающий подграф сущности для генерации групп троек, которые будут вербализованы вместе, и, наконец, фильтр постобработки для удаления выходных данных низкого качества. Результатом является корпус, содержащий весь Wikidata KG в виде текста на естественном языке, который авторы называют корпусом модели языка с расширенными знаниями (Knowledge-Enhanced Language Model, KELM). Он состоит из ~18 млн предложений, охватывающих ~45 млн троек и ~1500 отношений.

Преобразование графа знаний в текст на естественном языке, который затем используется для аугментации языковой модели.
Интеграция графа знаний и естественного текста для предварительного обучения языковой модели
Оценка авторов показывает, что вербализация графа знаний является эффективным методом его интеграции с текстом на естественном языке. Авторы демонстрируют это, аугментируя корпус текстового поиска REALM, который включает только текст Википедии.
Чтобы оценить эффективность вербализации, авторы дополнили корпус текстового поиска REALM корпусом KELM (то есть «вербализованными тройками») и сравнили его эффективность с аугментацией конкатенированными тройками без вербализации. Авторы подсчитали точность (accuracy) каждого метода аугментации данных на двух популярных наборах данных с ответами на вопросы в открытой предметной области: Natural Questions и Web Questions.

Аугментация REALM даже конкатенированными тройками повышает точность, потенциально добавляя информацию, не выраженную в тексте явно или вообще. Однако аугментация вербализованных троек позволяет более плавно интегрировать граф знаний с корпусом текста на естественном языке, что демонстрируется более высокой точностью. Авторы наблюдали ту же тенденцию в исследовании знаний под названием LAMA, в котором в качестве запроса для модели использовались вопросы с заполнением пустых полей.
Вывод
KELM представляет собой общедоступный корпус, содержащий преобразованный в обычный текст на естественном языке граф знаний. Авторы показали, что вербализация графа может быть использована для его интеграции с корпусами текстов на естественном языке, позволяя преодолеть их структурные различия. Этот подход может быть использован для таких задач, требующих значительного объема знаний, как ответы на вопросы, где предоставление фактических знаний является необходимым. Более того, такие корпуса могут применяться при предварительном обучении больших языковых моделей и потенциально могут снизить токсичность и повысить достоверность. Авторы выражают надежду, что их работа будет способствовать дальнейшему прогрессу в интеграции источников структурированных знаний в предварительное обучение больших языковых моделей.
Авторы
- Автор оригинала – Siamak Shakeri, Oshin Agarwal
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей




