
На хабре не нашлось обзоров «более быстрой альтернативы Redis» — KeyDB. Получив достаточно свежий опыт его использования, хочется восполнить этот пробел.

Предыстория достаточно банальна: однажды с большим наплывом трафика была зафиксирована значительная деградация производительности приложения (а именно — времени ответа). На тот момент, к сожалению, не удалось провести нормальную диагностику происходящего, поэтому впоследствии запланировали ряд нагрузочных тестирований. После их проведения удалось обнаружить узкое место, коим стал кэш базы данных в Redis. Как это часто бывает, проблему нельзя было решить сию секунду и правильным путём — силами разработчиков (изменением логики работы). Поэтому включилось любопытство и желание побороть ситуацию обходным путём. Так и появилась эта статья.
Как многим известно, Redis — однопотоковая база данных. Если быть точнее, то она такова в контексте работы с пользовательскими данными. Ведь с четвертой версии служебные, внутренние операции Redis перевели на параллельное исполнение. Тем не менее, это изменение затронуло лишь малую часть нагрузки, поскольку основная работа приходится на пользовательские данные.
На эту тему сломано бесчисленное множество копий, но разработчики Redis упорно не хотят внедрять полноценную параллельность, упоминая, насколько это усложнит приложение и повысит накладные расходы, а также добавит количество багов. Их позиция такова: если вы столкнулись с проблемой одноядерности — у вас проблемы с архитектурой приложения и надо что-то менять в ней. Среди пользователей, впрочем, есть и «другой лагерь» — из тех, кто упёрся в одно ядро и утверждает, что Redis сами себе создают бутылочное горлышко. В случае реально больших нагрузок — рано или поздно — неизбежно столкновение с этой проблемой, что накладывает значительные ограничения на архитектуру и/или вынужденные усложнения в ней.
Не буду давать оценку тому или иному мнению. Вместо этого поделюсь нашим конкретным случаем и тем, как мы его решили.
У одного из проектов мы столкнулись с тем, что команда разработки настроила крайне агрессивное кэширование данных из БД (PostgreSQL) через Redis. Это был единственный путь, который во время резких наплывов трафика спасал от смерти саму PostgreSQL и, как следствие, приложение.
После серии нагрузочных тестов мы провели анализ ситуации и обнаружили, что Redis упирался в одно ядро (что называется, «в полку»), после чего следовала довольно быстрая деградация приложения. «Захлебывание» имело геометрическую прогрессию: как только достигался лимит производительности у Redis, всё переставало работать.
Выглядело это примерно так:
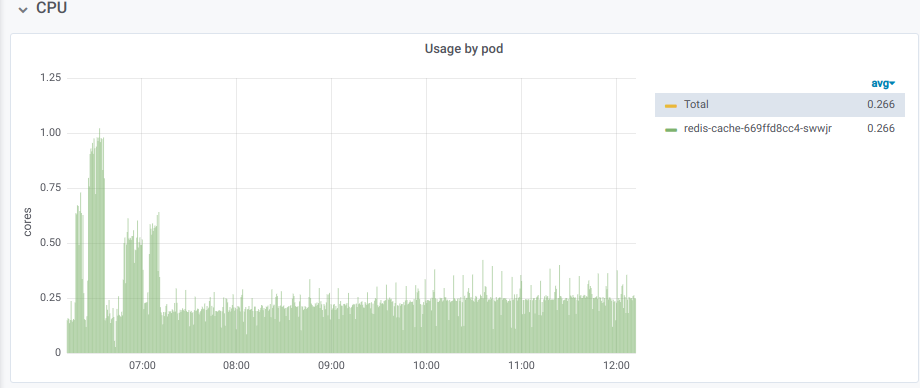
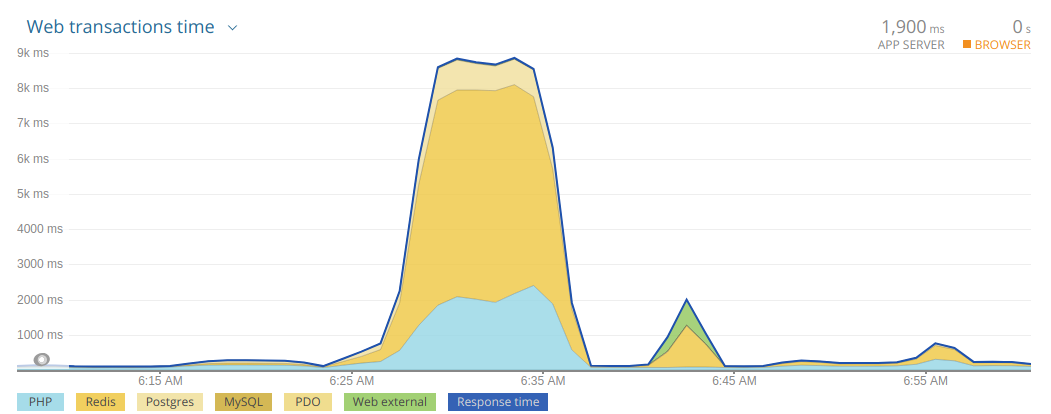
Со стороны New Relic однозначно идентифицировалась проблема:
А вот статистика по операции

После того, как проблему донесли во всех подробностях разработке, выяснилось, что «прямо сейчас решить проблему нельзя». Так начались поиски решения на стороне эксплуатации, и ответом стала уже упомянутая KeyDB.
Однако перед тем, как приступить к её обзору, стоит упомянуть, что в проекте используется standalone Redis, поскольку кластерное решение на основе Sentinel сильно уступает по задержкам (latency). Одним из очевидных решений было создание нескольких реплик кэша: и пусть приложение ходит повсюду с балансировкой! Однако, посовещавшись с разработчиками, мы были вынуждены отбросить этот вариант ввиду активного и сложного механизма инвалидации кэша у приложения. Та же проблема распространялась и на шардирование кэша.
В поисках возможного решения проблемы мы обнаружили приложение под названием KeyDB. Это форк Redis, разработанный канадской компанией и распространяемый под свободной лицензией BSD. Проект весьма молод: он существует с начала 2019 года. История его такова, что авторы тоже однажды столкнулись в свое время с ограничениями Redis… и решили сделать свой форк. Причём он не только решил известные проблемы, но и получил дополнительные возможности, которые доступны только в enterpise-версии Redis.
Для желающих подробнее ознакомиться с KeyDB есть хорошая вводная статья на Medium, которая представляет СУБД и краткие benchmark’и, сравнивающие её со своим «родителем» — Redis.
Прежде всего, нас привлекло в KeyDB потенциальное решение наших проблем, а заодно были интересны и некоторые дополнительные фичи. Использование KeyDB обещало следующие плюсы:
Более 3 тысяч звезд и множество контрибьюторов на GitHub также выглядели обнадеживающе. Приложение достаточно активно развивается и поддерживается, что хорошо заметно по коммитам, общению в issues, а также закрытым (принятым) PR. Отклик от основного мейнтейнера по всем фронтам всегда доброжелательный и оперативный. В общем, аргументов оказалось предостаточно.
Даже несмотря на то, что проект миграции был своеобразной авантюрой (ввиду новизны KeyDB), терять было особо нечего. Ведь откатить изменения достаточно быстро и просто — благо, вся инфраструктура развёрнута в Kubernetes, а встроенные механизмы Rolling Update отлично решают такие задачи.
В общем, мы подготовили Helm-шаблоны, переключили приложение в тестовом окружении на новую БД и выкатили это всё, отдав в QA-отдел клиента.
Началось тестирование, которое продолжалось около недели и в детали которого мы не погружались. Нам известно лишь о том, что заказчик проверил стандартные функции работы с Redis с помощью PHP-драйвера phpredis, а также провёл QA-тестирование пользовательского интерфейса. После этого нам дали зеленый свет: никаких побочных эффектов в использовании нового софта не обнаружилось. То есть с точки зрения приложения вообще ничего не поменялось.
Стоит отметить, что и в конфиге мы ничего не поменяли: буквально — просто заменили используемый образ. То же самое касается мониторинга и экспортинга метрик в Prometheus: самый распространенный из них отлично работает с KeyDB и без каких-либо доработок. Таким образом, можно смело сказать, что и с точки зрения эксплуатации это просто идеальный переезд.
Благодаря всему этому, после переключения приложения на новую СУБД можно ничего не менять, а в качестве «стабилизационной меры» — оставить его в таком виде поработать в бою на какое-то время. Однако, если вы хотите увидеть прирост производительности (либо вообще хоть какие-то изменения), надо не забывать, что по умолчанию параметр KeyDB, отвечающий за многопоточность (
После переключения, тестирования и некоторого времени жизни на новом приложении (с KeyDB) мы решили повторить нагрузочное тестирование с теми же параметрами, что использовались для Redis. Каковы были его результаты?..
По графику потребления CPU сразу стало заметно устранение проблем с «потолком» в одно ядро: процесс начал использовать доступные ресурсы:
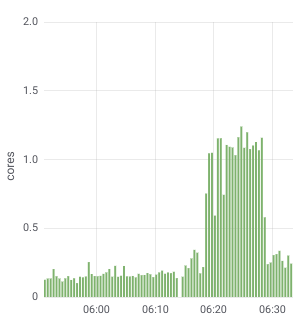
А впоследствии я пробовал достаточно сильно «истязать» приложение и увидел потребление вплоть до трёх ядер…
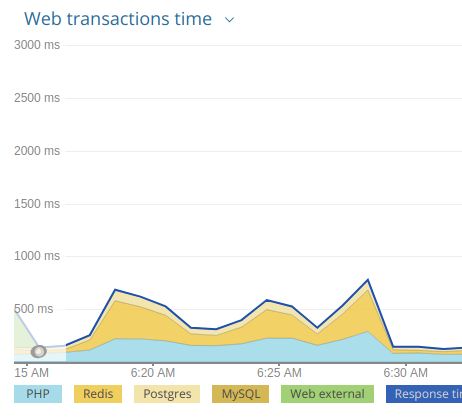
По показаниям New Relic, веб-приложение в целом, имея такую же нагрузку, стало вести себя заметно адекватнее. Некоторая деградация производительности всё равно наблюдалась, однако, сравнивая с аналогичным графиком выше, можете сами оценить существенный прогресс:
Показатель задержки у новой базы данных (KeyDB) тоже ухудшился, однако оставался в пределах допустимых значений:
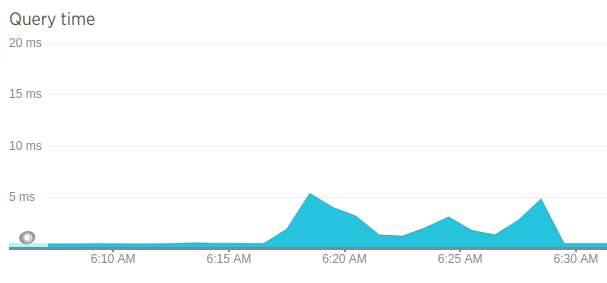
По следующему графику хорошо видно, что количество запросов в саму KeyDB аналогично:

Подводя итог по этим синтетическим тестам, можно сказать, что и Redis, и KeyDB показывают значительную деградацию производительности в latency (40 мс+) при существенном росте количества параллельных подключений (1000+). В нашем же случае веб-приложению удавалось «просаживать» latency Redis’а и при более низком количестве подключений (400+), хотя для KeyDB такая нагрузка оставалась приемлемой.
На данном примере прекрасна видна сила Open Source-сообщества в вопросах развития проектов, в которых оно заинтересовано. На просторах интернета мне встречалось отличное высказывание, общий смысл которого сводился к следующему: «Какая-то крупная компания создаёт интересный продукт, делает часть его функций открытой, но самую важную часть оставляет платной. Сообщество пользуется-пользуется, а потом кто-то махнёт рукой и сделает форк, реализовав в нём те самые платные фичи и открыв их для всех». Вот KeyDB — тот самый случай.
Говоря же о самой миграции, которая прошла на удивление просто, мы не получили настолько существенный прирост в производительности, какого можно ожидать, глядя на графики авторов KeyDB… Однако это лишь наш частный случай, в котором может быть множество отклонений, касающихся в том числе и пресловутой архитектуры приложения (например, огромное количество команд
В целом, KeyDB выглядит перспективно: по мере получения практического опыта работы с этой СУБД (а его ещё только предстоит набраться!) и развития самого проекта мы рассмотрим возможность его применения и в других ситуациях.
Однако не стоит рассматривать эту статью как руководство (и тем более — призыв) к действию по повсеместному отказу от Redis в пользу KeyDB. Несмотря на наш позитивный опыт, очевидно, что это не серебряная пуля. Случай был весьма специфичным: конкретно для решения сиюминутной проблемы в ситуации, когда нужно было сделать это быстро и с минимальными затратами, такое решение себя оправдало. Будет ли KeyDB полезен в вашем случае? По крайней мере, теперь вы знаете, что такая потенциальная возможность существует.
Читайте также в нашем блоге:
Предыстория достаточно банальна: однажды с большим наплывом трафика была зафиксирована значительная деградация производительности приложения (а именно — времени ответа). На тот момент, к сожалению, не удалось провести нормальную диагностику происходящего, поэтому впоследствии запланировали ряд нагрузочных тестирований. После их проведения удалось обнаружить узкое место, коим стал кэш базы данных в Redis. Как это часто бывает, проблему нельзя было решить сию секунду и правильным путём — силами разработчиков (изменением логики работы). Поэтому включилось любопытство и желание побороть ситуацию обходным путём. Так и появилась эта статья.
Проблематика
Про Redis в целом
Как многим известно, Redis — однопотоковая база данных. Если быть точнее, то она такова в контексте работы с пользовательскими данными. Ведь с четвертой версии служебные, внутренние операции Redis перевели на параллельное исполнение. Тем не менее, это изменение затронуло лишь малую часть нагрузки, поскольку основная работа приходится на пользовательские данные.
На эту тему сломано бесчисленное множество копий, но разработчики Redis упорно не хотят внедрять полноценную параллельность, упоминая, насколько это усложнит приложение и повысит накладные расходы, а также добавит количество багов. Их позиция такова: если вы столкнулись с проблемой одноядерности — у вас проблемы с архитектурой приложения и надо что-то менять в ней. Среди пользователей, впрочем, есть и «другой лагерь» — из тех, кто упёрся в одно ядро и утверждает, что Redis сами себе создают бутылочное горлышко. В случае реально больших нагрузок — рано или поздно — неизбежно столкновение с этой проблемой, что накладывает значительные ограничения на архитектуру и/или вынужденные усложнения в ней.
Не буду давать оценку тому или иному мнению. Вместо этого поделюсь нашим конкретным случаем и тем, как мы его решили.
Наш кейс
У одного из проектов мы столкнулись с тем, что команда разработки настроила крайне агрессивное кэширование данных из БД (PostgreSQL) через Redis. Это был единственный путь, который во время резких наплывов трафика спасал от смерти саму PostgreSQL и, как следствие, приложение.
После серии нагрузочных тестов мы провели анализ ситуации и обнаружили, что Redis упирался в одно ядро (что называется, «в полку»), после чего следовала довольно быстрая деградация приложения. «Захлебывание» имело геометрическую прогрессию: как только достигался лимит производительности у Redis, всё переставало работать.
Выглядело это примерно так:
Со стороны New Relic однозначно идентифицировалась проблема:
А вот статистика по операции
get в Redis:После того, как проблему донесли во всех подробностях разработке, выяснилось, что «прямо сейчас решить проблему нельзя». Так начались поиски решения на стороне эксплуатации, и ответом стала уже упомянутая KeyDB.
Однако перед тем, как приступить к её обзору, стоит упомянуть, что в проекте используется standalone Redis, поскольку кластерное решение на основе Sentinel сильно уступает по задержкам (latency). Одним из очевидных решений было создание нескольких реплик кэша: и пусть приложение ходит повсюду с балансировкой! Однако, посовещавшись с разработчиками, мы были вынуждены отбросить этот вариант ввиду активного и сложного механизма инвалидации кэша у приложения. Та же проблема распространялась и на шардирование кэша.
Беглый обзор KeyDB
В поисках возможного решения проблемы мы обнаружили приложение под названием KeyDB. Это форк Redis, разработанный канадской компанией и распространяемый под свободной лицензией BSD. Проект весьма молод: он существует с начала 2019 года. История его такова, что авторы тоже однажды столкнулись в свое время с ограничениями Redis… и решили сделать свой форк. Причём он не только решил известные проблемы, но и получил дополнительные возможности, которые доступны только в enterpise-версии Redis.
Для желающих подробнее ознакомиться с KeyDB есть хорошая вводная статья на Medium, которая представляет СУБД и краткие benchmark’и, сравнивающие её со своим «родителем» — Redis.
Прежде всего, нас привлекло в KeyDB потенциальное решение наших проблем, а заодно были интересны и некоторые дополнительные фичи. Использование KeyDB обещало следующие плюсы:
- получение полноценной многопоточности;
- полная и абсолютная совместимость с Redis (для нас это было особенно важно, т.к. выполнять какие-либо доработки со стороны приложения не представлялось возможным), что также сулило беспроблемную миграцию;
- встроенный механизм бэкапа в S3-хранилище;
- простая во внедрении active-репликация;
- простая кластеризация и шардирование без Sentinel и прочего вспомогательного ПО.
Более 3 тысяч звезд и множество контрибьюторов на GitHub также выглядели обнадеживающе. Приложение достаточно активно развивается и поддерживается, что хорошо заметно по коммитам, общению в issues, а также закрытым (принятым) PR. Отклик от основного мейнтейнера по всем фронтам всегда доброжелательный и оперативный. В общем, аргументов оказалось предостаточно.
Миграция и результаты
Даже несмотря на то, что проект миграции был своеобразной авантюрой (ввиду новизны KeyDB), терять было особо нечего. Ведь откатить изменения достаточно быстро и просто — благо, вся инфраструктура развёрнута в Kubernetes, а встроенные механизмы Rolling Update отлично решают такие задачи.
В общем, мы подготовили Helm-шаблоны, переключили приложение в тестовом окружении на новую БД и выкатили это всё, отдав в QA-отдел клиента.
Началось тестирование, которое продолжалось около недели и в детали которого мы не погружались. Нам известно лишь о том, что заказчик проверил стандартные функции работы с Redis с помощью PHP-драйвера phpredis, а также провёл QA-тестирование пользовательского интерфейса. После этого нам дали зеленый свет: никаких побочных эффектов в использовании нового софта не обнаружилось. То есть с точки зрения приложения вообще ничего не поменялось.
Стоит отметить, что и в конфиге мы ничего не поменяли: буквально — просто заменили используемый образ. То же самое касается мониторинга и экспортинга метрик в Prometheus: самый распространенный из них отлично работает с KeyDB и без каких-либо доработок. Таким образом, можно смело сказать, что и с точки зрения эксплуатации это просто идеальный переезд.
Благодаря всему этому, после переключения приложения на новую СУБД можно ничего не менять, а в качестве «стабилизационной меры» — оставить его в таком виде поработать в бою на какое-то время. Однако, если вы хотите увидеть прирост производительности (либо вообще хоть какие-то изменения), надо не забывать, что по умолчанию параметр KeyDB, отвечающий за многопоточность (
server-threads), равен единице, то есть СУБД работает ровно так же, как Redis.После переключения, тестирования и некоторого времени жизни на новом приложении (с KeyDB) мы решили повторить нагрузочное тестирование с теми же параметрами, что использовались для Redis. Каковы были его результаты?..
По графику потребления CPU сразу стало заметно устранение проблем с «потолком» в одно ядро: процесс начал использовать доступные ресурсы:
А впоследствии я пробовал достаточно сильно «истязать» приложение и увидел потребление вплоть до трёх ядер…
По показаниям New Relic, веб-приложение в целом, имея такую же нагрузку, стало вести себя заметно адекватнее. Некоторая деградация производительности всё равно наблюдалась, однако, сравнивая с аналогичным графиком выше, можете сами оценить существенный прогресс:
Показатель задержки у новой базы данных (KeyDB) тоже ухудшился, однако оставался в пределах допустимых значений:
По следующему графику хорошо видно, что количество запросов в саму KeyDB аналогично:
Подводя итог по этим синтетическим тестам, можно сказать, что и Redis, и KeyDB показывают значительную деградацию производительности в latency (40 мс+) при существенном росте количества параллельных подключений (1000+). В нашем же случае веб-приложению удавалось «просаживать» latency Redis’а и при более низком количестве подключений (400+), хотя для KeyDB такая нагрузка оставалась приемлемой.
Выводы
На данном примере прекрасна видна сила Open Source-сообщества в вопросах развития проектов, в которых оно заинтересовано. На просторах интернета мне встречалось отличное высказывание, общий смысл которого сводился к следующему: «Какая-то крупная компания создаёт интересный продукт, делает часть его функций открытой, но самую важную часть оставляет платной. Сообщество пользуется-пользуется, а потом кто-то махнёт рукой и сделает форк, реализовав в нём те самые платные фичи и открыв их для всех». Вот KeyDB — тот самый случай.
Говоря же о самой миграции, которая прошла на удивление просто, мы не получили настолько существенный прирост в производительности, какого можно ожидать, глядя на графики авторов KeyDB… Однако это лишь наш частный случай, в котором может быть множество отклонений, касающихся в том числе и пресловутой архитектуры приложения (например, огромное количество команд
get в Redis вместо более производительного варианта агрегированных запросов mget…). Тем не менее, положительных результатов удалось добиться, а вместе с ними — множество полезных функций, которые мы ещё только будем внедрять в ближайшее время.В целом, KeyDB выглядит перспективно: по мере получения практического опыта работы с этой СУБД (а его ещё только предстоит набраться!) и развития самого проекта мы рассмотрим возможность его применения и в других ситуациях.
Однако не стоит рассматривать эту статью как руководство (и тем более — призыв) к действию по повсеместному отказу от Redis в пользу KeyDB. Несмотря на наш позитивный опыт, очевидно, что это не серебряная пуля. Случай был весьма специфичным: конкретно для решения сиюминутной проблемы в ситуации, когда нужно было сделать это быстро и с минимальными затратами, такое решение себя оправдало. Будет ли KeyDB полезен в вашем случае? По крайней мере, теперь вы знаете, что такая потенциальная возможность существует.
P.S.
Читайте также в нашем блоге:
- «Базы данных и Kubernetes (обзор и видео доклада)»;
- «Миграция Cassandra в Kubernetes: особенности и решения»;
- «Беспростойная миграция MongoDB в Kubernetes»;
- «Беспростойная миграция RabbitMQ в Kubernetes».



