
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет, Хабр!
В этой статье речь пойдет о больших данных в финансовых сервисах, а точнее, о том, насколько легко – или сложно – повысить конверсию клиентов при проведении маркетинговых кампаний по специфичным банковским продуктам, с помощью BigData и умных моделей. Другими словами, как, основываясь на наших знаниях о клиентах, выбрать именно тех из них, для которых предлагаемые продукты будут наиболее интересны.
Итак, в чем собственно состоит наш кейс? К нам обратился отдел маркетинга с задачей организации коммуникаций с клиентом посредством рассылки SMS с предложением рефинансирования ипотеки. Предполагалось рассылать предложения клиентам, которые ранее оставляли у нас заявку на ипотечный кредит (и она была одобрена), но оформление кредита по каким-то причинам не произошло. При этом необходимо было сегментировать клиентов, выделив в отдельную выборку высокоприоритетных, тем самым обеспечив экономию и высокий уровень конверсии.
Обычно продвижение продуктов происходит за счет коммуникации с клиентом через различные каналы: SMS, Push, звонки и многие другие. Формирование сегментов для продвижения сейчас решается с помощью машинного обучения. В рамках этой задачи мы рассматриваем оптимизацию рассылки SMS с предложением рефинансирования ипотеки.
Существует 3 подхода для решения задачи:
Look-alike-модель оценивает вероятность того, что клиент выполнит целевое действие. В качестве обучающей выборки используются известные позитивные объекты (например, пользователи, установившие приложение) и случайные негативные объекты (сэмплирование небольшой подвыборки из всех остальных клиентов, у кого это приложение не было установлено). Модель будет пытаться искать клиентов, похожих на тех, кто совершил целевое действие;
Response-модель оценивает вероятность того, что клиент выполнит целевое действие при условии коммуникации. В этом случае обучающей выборкой являются данные, собранные после некоторого взаимодействия с клиентами. В отличии от первого подхода, в нашем распоряжении имеются реальные позитивные и негативные наблюдения (например, клиент оформил кредитную карту или отказался);
Uplift-модель оценивает чистый эффект от коммуникации, пытаясь выбрать тех клиентов, которые совершат целевое действие только при нашем взаимодействии. Модель оценивает разницу в поведении клиента при наличии воздействия и при его отсутствии.
В нашем случае у нас были исторические данные, реальные позитивные и негативные наблюдения. Таким образом между look-alike и response моделями мы выбрали response. Для uplift-модели нужен особый дизайн эксперимента изначально (при сборе обучающей выборки), а такими данными мы не располагали, поэтому от uplift-моделирования мы отказались.
В качестве обучающей выборки было взято множество записей X, описывающее параметры взаимодействия с клиентами по вопросу предложения рефинансирования, и множество записей Y с результатами этого взаимодействия:
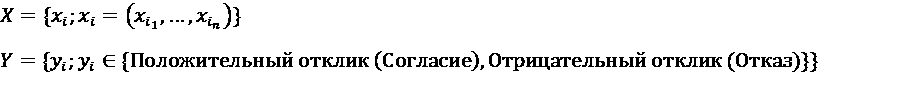
В итоге был разработан алгоритм определения вероятности положительного отклика на взаимодействие на первом этапе воронки по набору параметров CRM-кампании. Положительным откликом положили считать переход по ссылке внутри SMS. В качестве бизнес метрики выступала конверсия.
Поскольку выборка была сильно не сбалансирована относительно таргета (процент положительного отклика 1,8%), в качестве метрики машинного обучения была выбрана F-мера.
В качестве источников данных брались стандартные данные клиента: возраст, пол, доход, данные о месте проживания и работе, а также данные кредита: ставка, срок и некоторые другие параметры.
При подготовке датасета было много преобразований:
Исправление ошибок. Например, образование техническое и (техническое) по смыслу одно и тоже, или - средне и среднее;
Смысловые изменения. В графе семейное положение «не состою в браке», «холост», «не женат», «не замужем» по смыслу одно и тоже, поэтому можно заменить на какое-то одно значение, например, «не замужем». Статус места работы «госпредприятие» и «государственное предприятие» по смыслу одно и тоже;
Заполнение пропусков;
Удаление признаков с большим количеством пропусков.
Из множества оригинальных признаков путем их нелинейных преобразований было получено расширенное признаковое пространство.
Из алгоритмов для решения задачи мы выбрали Catboost из-за хорошего встроенного энкодера категориальных признаков. Отбор признаков производился на кросс-валидации с помощью permutation importance. Оптимизация параметров производилась с помощью пакета Hyperopt. Финальное качество проверялось на отложенной тестовой выборке. F-мера на тесте составила ~0.11 (что мало, но ожидаемо из-за сильно ограниченного набора данных).
Графики logloss и F-меры:
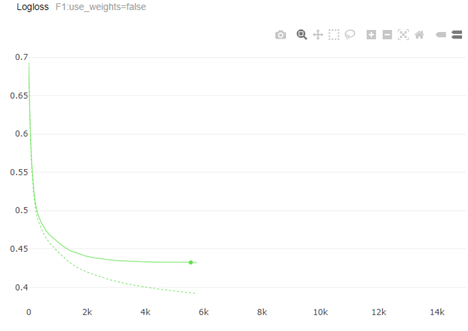

На продакшн модель была запущена в виде A/B теста: сравнивалось взаимодействие с полностью случайными клиентами, а также с работой других внешних и внутренних моделей. Первые результаты показали, что модель даёт конверсию в 2,5 раза больше, чем ранее применяемые методы. Выше заинтересованность клиента не только выслушать предложение о рефинансировании, но и приобрести его.
В дальнейшем мы планируем расширять пул источников данных, чтобы затащить в модель больше параметров для обучения и повысить степень влияния на целевую бизнес-метрику.




