
Привет Хабр.
В предыдущей части была проанализирована популярность различных разделов сайта, и параллельно возник вопрос — какие данные можно извлечь из комментариев к статьям. Также хотелось проверить одну гипотезу, о которой скажу ниже.

Данные получились довольно интересные, также удалось составить небольшой «мини-рейтинг» комментаторов. Продолжение под катом.
Для анализа мы будем использовать данные за этот, 2019 год, тем более что список статей в виде csv у меня уже был получен. Осталось извлечь из каждой статьи комментарии, к счастью для нас, они хранятся там же, и никаких дополнительных запросов делать не нужно.
Для выделения комментариев из статьи достаточно следующего кода:
Это позволяет нам получить список комментариев в примерно таком виде (ники убраны из соображений приватности):
Как можно видеть, для каждого комментария мы можем получить имя юзера, дату, рейтинг, ну и собственно текст. Посмотрим, что из этого мы можем получить.
Кстати, изначально, идея сбора рейтинга была немного другая — посмотреть, какие оценки ставят пользователи. Для примера, можно посмотреть на youtube — даже самый идеальный ролик, даже ролик не несущий никакой субъективной информации, чисто справочный или выпуск новостей, все равно набирает некоторое определенное количество минусов. Гипотеза была в том, что есть юзеры, которымчисто клинически вообще все не нравится, может серотонин в мозгу не вырабатывается или еще что-то. Может человеку уже надо не на Хабре сидеть, а депрессию лечить… Но как оказалось, проверить это здесь я не могу, т.к. список поставивших оценки, в комментарии или статье не сохраняется. Ну что есть, то есть, будем работать с имеющимися данными. В итоге получился «обратный» рейтинг — видно, какие оценки _получают_ пользователи. Что в принципе, тоже интересно.
Для начала, традиционный disclaimer. Данный рейтинг, как и все предыдущие, является неофициальным. Я не гарантирую, что нигде не ошибся. Для тех, кого интересуют технические подробности, более подробный код приведен в предыдущей части.
Итак, приступим. Для анализа были взяты комментарии за этот, 2019 год (который еще не кончился). На момент написания текста пользователями было написано 448533 комментария, размер csv-файла составляет 288МБайт. Мощно, внушает.
Сгруппируем комментарии по часам, разделив отдельно будние и выходные дни.

Тут нас интересуют не абсолютные значения, а относительные. Если просто смотреть «как есть», то получается что большая часть комментариев написана в рабочее время с 10 до 18 ;) С другой стороны, тут не учитываются часовые пояса, так что вопрос пока открытый.
Посмотрим распределение комментариев в течение года:
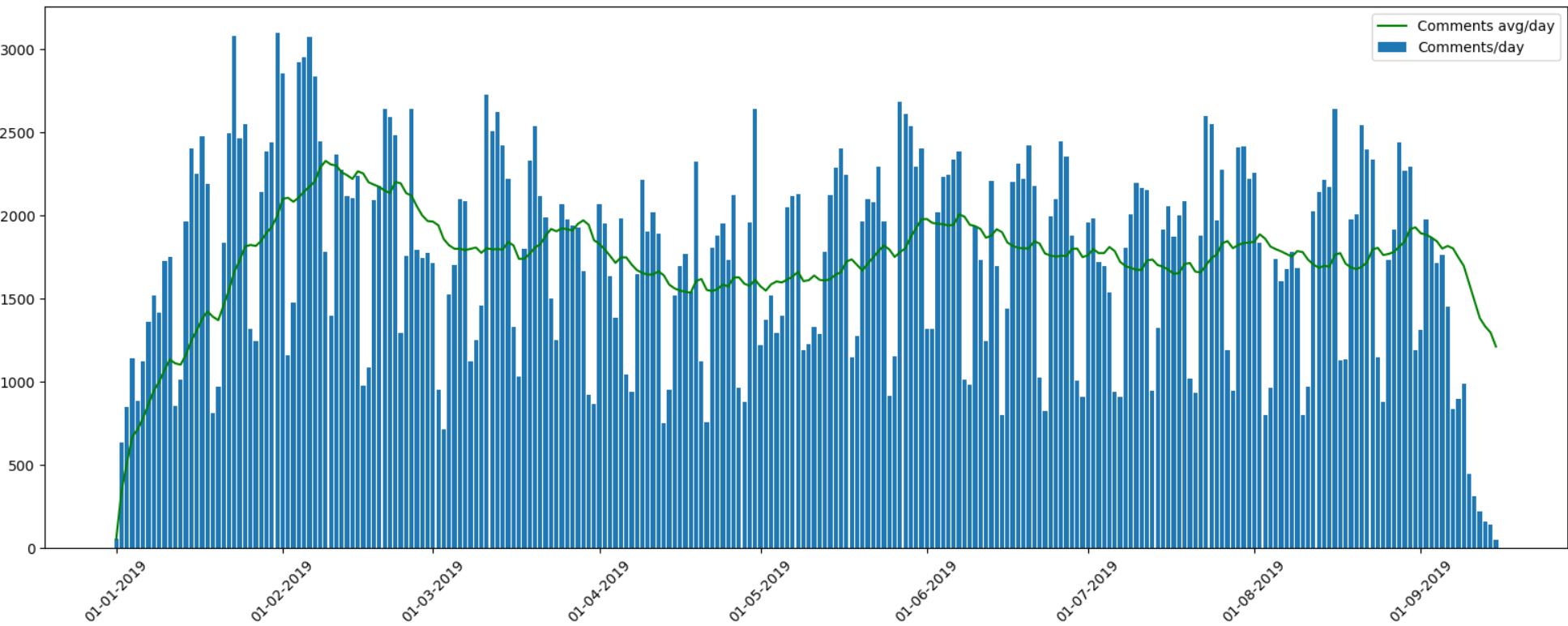
И все-такиона вертится четко виден всплеск в будние дни — недельная периодичность явно прослеживается, так что с достаточно большой уверенностью можно сказать, что народ читает и комментирует Хабр с работы (но это не точно).
Кстати, была идея проверить гипотезу, различается ли число полученных минусов или плюсов от дня или времени суток, но зависимости найти не удалось — время проставления оценки не сохраняется, а прямой связи с временем комментария тут нет.
Разумеется, точного количества пользователей на сайте я не знаю. Но тех, кто оставил хотя бы один комментарий за этот год, оказалось примерно 25000 человек.
График количества сообщений, оставленных пользователями, выглядит довольно интересно:
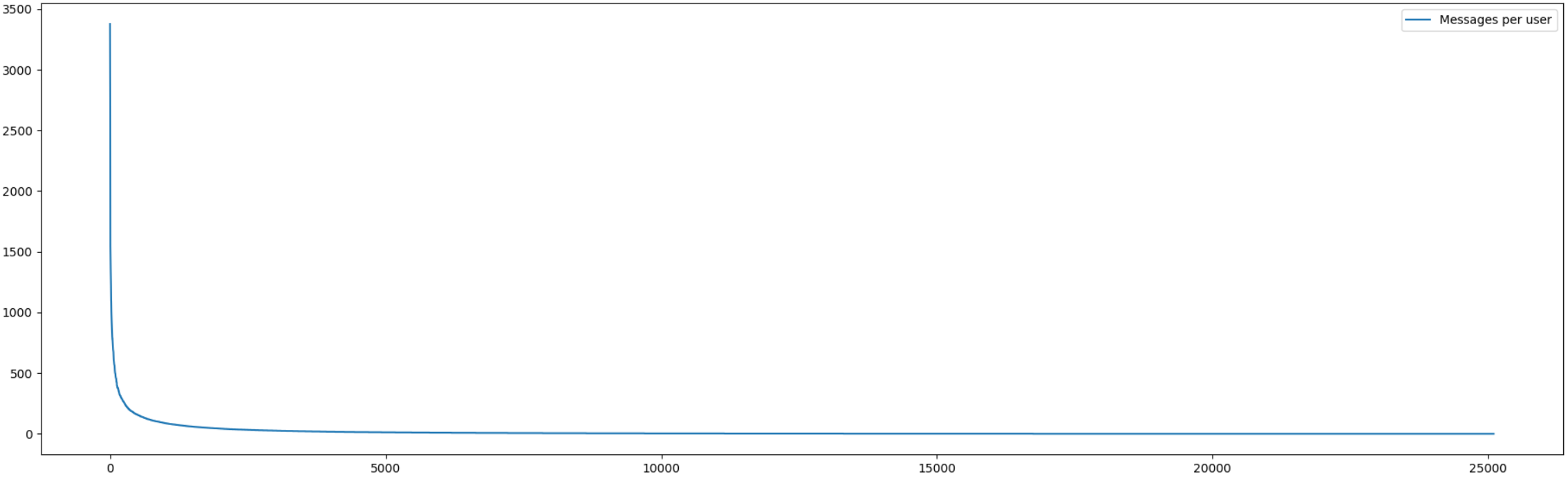
Я в начале не поверил сам, но вроде ошибки нет. 5% пользователей оставляют 60% сообщений. 10% — 74% всех сообщений (которых напомню, за этот год, 450тыс). Большинство же просто читает сайт, оставляя совсем редко комментарии, или не оставляют их вообще (такие естественно, в мой список не попали).
Переходим к последней, и самой веселой части статистики — рейтингам. Из соображений приватности я не буду приводить полные ники пользователей, кто захочет, думаю, себя узнает.
По количеству комментариев за этот год, топ 5 занимают VoXXXX (3377 комментариев), 0xdXXXXX (3286 комментария), strXXXX (3043 комментария), AmXXXX (2897 комментариев) и khXXXX (2748 комментариев).
По количеству полученных плюсов, топ 5 занимают amXXXX (1395 комментариев, рейтинги +3231/-309), tvXXXX (1544 комментария, рейтинги +3231/-97), WhuXXXX (921 комментарий, рейтинги +2288/-13), MTXXXX (1328 комментариев, +1383/-7) и amaXXXX (736 комментариев, рейтинг +1340/-16).
По абсолютному положительному рейтингу (ни одного негативно оцененного комментария) верхушку топа занимают Milfgard и Boomburum. В качестве исключения, привожу их ники полностью, думаю, они это заслужили.
С минусами тоже интересно. Топ по количеству набранных минусов за этот год занимают siXX (473 плюса, 699 минусов), khXX (1915 плюсов, 573 минуса) и nicXXXXX (456 плюса, 487 минуса). Но как можно видеть, и положительных комментариев у этих пользователей достаточно. А вот по абсолютному минусу в «антитоп» попадают vladXXXX (55 комментариев, 84 минуса, 0 плюсов), ekoXXXX (77 комментариев, 92 минуса, 1 плюс) и iMXXXX (225 комментариев, 205 минусов, 12 плюсов).
Удалось посчитать не все задуманное, но надеюсь, было интересно.
Как можно видеть, даже датасет с таким небольшим количеством полей может дать интересные данные для анализа. Тут еще есть далеко куда копать, от построения «облака слов» до анализа текста. Если появятся какие-то интересные результаты, они будут опубликованы.
В предыдущей части была проанализирована популярность различных разделов сайта, и параллельно возник вопрос — какие данные можно извлечь из комментариев к статьям. Также хотелось проверить одну гипотезу, о которой скажу ниже.
Данные получились довольно интересные, также удалось составить небольшой «мини-рейтинг» комментаторов. Продолжение под катом.
Сбор данных
Для анализа мы будем использовать данные за этот, 2019 год, тем более что список статей в виде csv у меня уже был получен. Осталось извлечь из каждой статьи комментарии, к счастью для нас, они хранятся там же, и никаких дополнительных запросов делать не нужно.
Для выделения комментариев из статьи достаточно следующего кода:
r = requests.get("https://habr.com/ru/post/467453/")
data_html = r.text
comments = data_html.split('<div class="comment" id=')
comments_list = []
for comment in comments:
body = Str(comment).find_between('<div class="comment__message', '<div class="comment__footer"').find_between('>', '</div>')# .replace('\n', '-')
if len(body) < 4: continue
body = body.translate(str.maketrans(dict.fromkeys("\t\n\r\v\f")))
body = body.replace('"', "'").replace(',', " ").replace('<br>', ' ').replace('<p>', '').replace('</p>', '').replace(' ', ' ')
user = Str(comment).find_between('data-user-login', '>').find_between('"', '"')
date_str = Str(comment).find_between('<time class="comment__date-time comment__date-time_published', 'time>').find_between('>', '<')
vote = Str(comment).find_between('<div class="voting-wjt', '</div>').find_between('<span', 'span>').find_between('>', '<')
date = dateparser.parse(date_str)
csv_data = "{},{},{},{}".format(user, date, vote, body)
comments_list.append(csv_data)
Это позволяет нам получить список комментариев в примерно таком виде (ники убраны из соображений приватности):
xxxxxxx,2019-02-06 11:50:00,0,А можно пример как именно?
xxxxxxx-02-24 16:15:00,+1,Побольше читайте независимые официальные источники чтобы таких вопросов не было.
xxxxxxx,2019-02-23 20:15:00,–5,А не важно главное в итоге в плюсе оказаться
Как можно видеть, для каждого комментария мы можем получить имя юзера, дату, рейтинг, ну и собственно текст. Посмотрим, что из этого мы можем получить.
Кстати, изначально, идея сбора рейтинга была немного другая — посмотреть, какие оценки ставят пользователи. Для примера, можно посмотреть на youtube — даже самый идеальный ролик, даже ролик не несущий никакой субъективной информации, чисто справочный или выпуск новостей, все равно набирает некоторое определенное количество минусов. Гипотеза была в том, что есть юзеры, которым
Обработка
Для начала, традиционный disclaimer. Данный рейтинг, как и все предыдущие, является неофициальным. Я не гарантирую, что нигде не ошибся. Для тех, кого интересуют технические подробности, более подробный код приведен в предыдущей части.
Итак, приступим. Для анализа были взяты комментарии за этот, 2019 год (который еще не кончился). На момент написания текста пользователями было написано 448533 комментария, размер csv-файла составляет 288МБайт. Мощно, внушает.
Время написания
Сгруппируем комментарии по часам, разделив отдельно будние и выходные дни.
Тут нас интересуют не абсолютные значения, а относительные. Если просто смотреть «как есть», то получается что большая часть комментариев написана в рабочее время с 10 до 18 ;) С другой стороны, тут не учитываются часовые пояса, так что вопрос пока открытый.
Посмотрим распределение комментариев в течение года:
И все-таки
Кстати, была идея проверить гипотезу, различается ли число полученных минусов или плюсов от дня или времени суток, но зависимости найти не удалось — время проставления оценки не сохраняется, а прямой связи с временем комментария тут нет.
Пользователи
Разумеется, точного количества пользователей на сайте я не знаю. Но тех, кто оставил хотя бы один комментарий за этот год, оказалось примерно 25000 человек.
График количества сообщений, оставленных пользователями, выглядит довольно интересно:
Я в начале не поверил сам, но вроде ошибки нет. 5% пользователей оставляют 60% сообщений. 10% — 74% всех сообщений (которых напомню, за этот год, 450тыс). Большинство же просто читает сайт, оставляя совсем редко комментарии, или не оставляют их вообще (такие естественно, в мой список не попали).
Рейтинги
Переходим к последней, и самой веселой части статистики — рейтингам. Из соображений приватности я не буду приводить полные ники пользователей, кто захочет, думаю, себя узнает.
По количеству комментариев за этот год, топ 5 занимают VoXXXX (3377 комментариев), 0xdXXXXX (3286 комментария), strXXXX (3043 комментария), AmXXXX (2897 комментариев) и khXXXX (2748 комментариев).
По количеству полученных плюсов, топ 5 занимают amXXXX (1395 комментариев, рейтинги +3231/-309), tvXXXX (1544 комментария, рейтинги +3231/-97), WhuXXXX (921 комментарий, рейтинги +2288/-13), MTXXXX (1328 комментариев, +1383/-7) и amaXXXX (736 комментариев, рейтинг +1340/-16).
По абсолютному положительному рейтингу (ни одного негативно оцененного комментария) верхушку топа занимают Milfgard и Boomburum. В качестве исключения, привожу их ники полностью, думаю, они это заслужили.
С минусами тоже интересно. Топ по количеству набранных минусов за этот год занимают siXX (473 плюса, 699 минусов), khXX (1915 плюсов, 573 минуса) и nicXXXXX (456 плюса, 487 минуса). Но как можно видеть, и положительных комментариев у этих пользователей достаточно. А вот по абсолютному минусу в «антитоп» попадают vladXXXX (55 комментариев, 84 минуса, 0 плюсов), ekoXXXX (77 комментариев, 92 минуса, 1 плюс) и iMXXXX (225 комментариев, 205 минусов, 12 плюсов).
Заключение
Удалось посчитать не все задуманное, но надеюсь, было интересно.
Как можно видеть, даже датасет с таким небольшим количеством полей может дать интересные данные для анализа. Тут еще есть далеко куда копать, от построения «облака слов» до анализа текста. Если появятся какие-то интересные результаты, они будут опубликованы.

