
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Вот и меня посетило желание что-нибудь написать для читателей Хабра. Чем же ещё заняться в отпуске?
Казалось бы, про пейджинг уже написано всё, что только можно было. И этот текст тоже на уникальность и открытия не претендует. Но, по крайней мере, лично мне не попадалось таких текстов, чтобы тема пейджинга в реляционных базах была раскрыта не отдельными аспектами, а последовательно и подробно. Поэтому я всё-таки попробую и буду надеяться, что хотя бы одна-две детали в этом тексте покажутся читателю интересными.
Для демонстрации некоторых примеров далее будет использоваться тестовая база данных PostgreSQL. Она очень простая. Фактически нам будет интересна единственная таблица, которую мы и будем «листать». В ней четыре поля: идентификатор, имя, фамилия, возраст. Данные в ней генерируются случайным образом – один миллион записей – с использованием словарей с именами и фамилиями. Надо учитывать, что в реальных промышленных системах полей будет больше, каждый кортеж будет тяжелее, выборка, вероятно, будет производиться из нескольких связанных таблиц и т.д. С учётом этого почти все приводимые далее оценки будут усугубляться.
Лично я поднимаю БД для тестов в docker’е, где уже подготовлены тестовые данные. Берём здесь. Запускаем из каталога docker командой docker-compose up -d. СУБД PostgreSQL стартует вместе с web-версией утилиты pgadmin. Её надо немного настроить. В браузере заходим по адресу http://localhost:5050/. Логин/пароль: cop/postgres. В дереве навигации уже должен быть сервер cop. Нужно будет только ввести пароль – postgres.
Теперь мы готовы погонять тесты.
Итак, пишем про пейджинг. Сначала по понятиям. Под пейджингом подразумеваем не только листание некоторых списковых данных пользователем, которому они представляются в виде порций, называемых страничками. Под этим термином мы также подразумеваем последовательную обработку наборов записей порциями в случаях, когда по какой-то причине мы не можем держать постоянное соединение с БД и долгую транзакцию для получения этих порций, например, из открытого курсора. Это замечание важно, так как пользователь, как правило, предпочитает работать только на первой странице, а не переходить к уровню безнадёжности «вторая страница гугла». А вот алгоритмическое листание (всякие батчинги и пр.) может дойти до тысячной страницы и более. Для упрощения далее алгоритмы будем также называть пользователями.
Не смотря на некоторое усложнение, вероятно, многие скажут, что всё проще некуда, и старые добрые конструкции типа OFFSET/LIMIT способны решить любые задачи. И будут правы. Почти. Как говорит один мой коллега, «есть нюансики».
Итак, оффсетный пейджинг
Его недостатки, которые почти сразу приходят на ум, – это:
Появление дубликатов записей или пропуск записей при пролистывании страниц, то есть неконсистентность результата.
Посмотрим, как это происходит. Имеем следующую табличку.
id name age 11
12
13
14
15Jane
Peter
Margarett
Manuel
Richard25
36
41
21
4916
17
18
19
20Elliot
Helen
Katrine
Elvis
Joan61
53
19
33
69Записи отсортированы по идентификатору.
Один пользователь просматривает первую страницу – записи с идентификаторами 11-15. Для него значения
OFFSETиLIMITравны 0 и 5 соответственно. В это время второй пользователь удаляет, например, запись о Peter с идентификатором 12. Далее, первый пользователь решает перейти ко второй странице со значениямиOFFSETиLIMIT, равными 5. Для него отобразятся 4 записи с 17 по 20, а не с 16 по 20, как можно было бы ожидать. Таким образом, запись об Эллиоте с идентификатором 16 пользователь пропустит.
Аналогично выглядит пример с дублированием: если второй пользователь не удалит запись, а добавит новую, например, с идентификатором 10, то первый пользователь, перейдя на вторую страницу, увидит записи с 15 по 19. Таким образом запись о Ричарде с идентификатором 15 станет дублем.
Теперь представьте, что может произойти, если активных пользователей станет пара тысяч…
Помимо сдвигов записей вследствие изменения состава кортежей, попадающих под выборку, есть ещё ситуации, когда из-за самой СУБД порядок записей может измениться. Далее мы ещё вернёмся к этой теме и рассмотрим, почему это может произойти.
Линейный рост сложности при выполнении запроса с увеличением номера страницы или неэффективность смещения.
Проиллюстрируем это на нашей тестовой базе данных.
План выполнения запроса для получения второй страницы (10 записей на страницу):
SELECT * FROM test_paging OFFSET 10 LIMIT 10;Limit (cost=0.17..0.34 rows=10 width=25) (actual time=0.011..0.013 rows=10 loops=1)
-> Seq Scan on test_paging (cost=0.00..17190.00 rows=1000000 width=25)
(actual time=0.009..0.010 rows=20 loops=1)
Planning Time: 0.043 ms
Execution Time: 0.023 ms
Сотой страницы:
SELECT * FROM test_paging OFFSET 990 LIMIT 10;Limit (cost=17.02..17.19 rows=10 width=25) (actual time=0.136..0.138 rows=10 loops=1)
-> Seq Scan on test_paging (cost=0.00..17190.00 rows=1000000 width=25)
(actual time=0.009..0.094 rows=1000 loops=1)
Planning Time: 0.044 ms
Execution Time: 0.149 ms
Видим рост времени выполнения с 0,023 мс до 0,149 мс – в 6,5 раз.
С помощью простого теста можно получить следующую картинку:
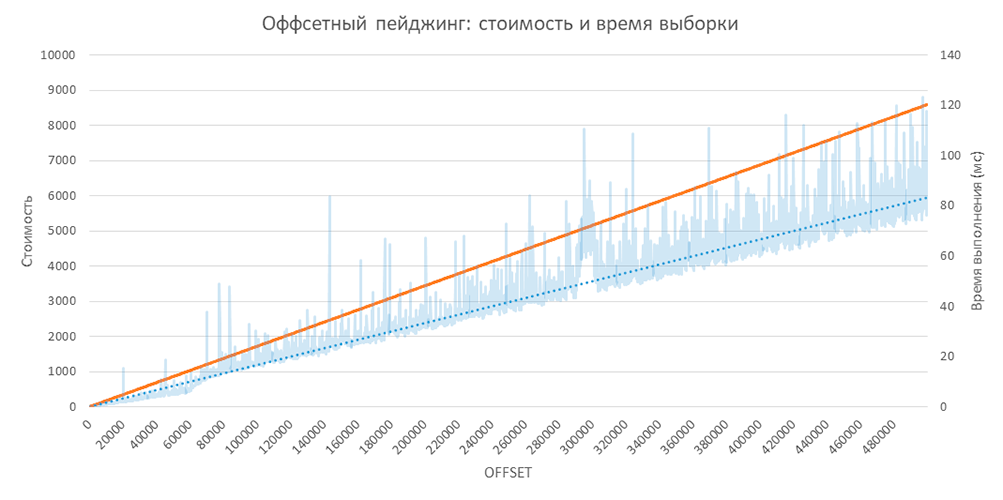
Тут нужно учитывать, что тестовые данные синтетические и очень компактные. То есть в реальной жизни угол будет более крутым.
Сортировка
Тема – довольно общая, но очень важная с точки зрения пейджинга. Пожалуй, то, с чего хотелось бы начать: сортировка в большинстве случаев – это зло для системы. Почему?
Самое худшее, что здесь можно сделать для большой базы данных, – это отсортировать всё по неиндексированному полю и отобрать верхние 10 записей. Да, часто пользователь пытается сделать именно так, не догадываясь воспользоваться фильтрацией. В действительности довольно редко требуется обеспечить строгий порядок в отбираемых записях. Ещё реже этот порядок нужно обеспечивать по двум и более полям. И совсем непредсказуемое поведение можно получить, предоставив пользователю возможность сортировать по любому набору полей, так как затраты растут по всем фронтам: на хранение дополнительных индексов, на вставку во все индексы, на сортировку неиндексированных полей, на физические чтения и т.д. К пейджингу это имеет не совсем прямое отношение, но это нужно всегда держать в голове, стараться избегать лишних сортировок и предпочитать хранить данные в естественном порядке – в том, в котором они обычно нужны пользователю.
Есть ещё один любопытный момент. При сортировке по неуникальному полю снова может возникнуть эффект проскальзывания записей между страниц, так как реляционные СУБД и SQL не гарантируют в этом случае воспроизводимый порядок возвращаемых записей. И в целом реляционная модель определяет таблицу как неупорядоченный набор записей. Для решения этой проблемы в оффсетном пейджинге обычно используют дополнительную сортировку по уникальному полю. Иногда такое поле предоставляется самой СУБД, например, rowid в случае Oracle. Иногда такого псевдо-поля нет. Например, в PostgreSQL ctid непостоянно и может изменять своё значение. То есть в некоторых случаях уникальное поле нужно создавать, индексировать и хранить. Казалось бы, плёвая задача: первичный ключ с типом, например, bigint, значение которого заполнено с помощью sequence. Но в распределённых системах это может создать некоторые проблемы, так как ключи генерируются независимо в нескольких точках системы. Обычно в этом случае используется UUID, занимающий в два раза больше места относительно bigint, практически гарантирующий уникальность значения для всей системы в целом и не требующий соперничества за общий ресурс. Этот тип не задумывался для генерации упорядоченных значений, что влечёт за собой проблему фрагментации данных. Возможно, стоит обратить внимание на «младшего» брата UUID – ULID, который даёт нам упорядоченные значения, и использовать его.
Итак, посмотрим, как будут выглядеть планы выполнения постраничных запросов с учётом сортировки. У нас в тестовой таблице имеется индексированное поле с именем и не индексированное с фамилией. Получение первой страницы будет выглядеть так:
SELECT * FROM test_paging ORDER BY first_name, id OFFSET 0 LIMIT 10;Limit (cost=0.42..1.02 rows=10 width=25) (actual time=0.013..0.021 rows=10 loops=1)
-> Index Scan using ix_test_paging_first_name_id on test_paging
(cost=0.42..59804.38 rows=1000000 width=25)
(actual time=0.013..0.019 rows=10 loops=1)
Planning Time: 0.054 ms
Execution Time: 0.030 msКак видим, оценка – выше, так как приходится читать помимо таблицы ещё и индекс, и время выполнения соответственно больше, но сопоставимо с временем выполнения запроса без сортировки, так как в индексе элементы присутствуют в нужном нам порядке.
Вариант без индекса выглядит очевидно существенно хуже:
SELECT * FROM test_paging ORDER BY last_name, id OFFSET 0 LIMIT 10;Limit (cost=21360.71..21361.88 rows=10 width=25) (actual time=140.228..140.232 rows=10 loops=1)
-> Gather Merge (cost=21360.71..118589.80 rows=833334 width=25)
(actual time=140.227..142.041 rows=10 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=20360.69..21402.36 rows=416667 width=25)
(actual time=136.528..136.529 rows=10 loops=3)
Sort Key: last_name, id
Sort Method: top-N heapsort Memory: 26kB
Worker 0: Sort Method: top-N heapsort Memory: 26kB
Worker 1: Sort Method: top-N heapsort Memory: 26kB
-> Parallel Seq Scan on test_paging (cost=0.00..11356.67 rows=416667 width=25)
(actual time=0.009..49.571 rows=333333 loops=3)
Planning Time: 0.051 ms
Execution Time: 142.063 msСУБД приходится сортировать все элементы, чтобы выбрать нужные 10.
Вот как это выглядит при «листании» страниц:
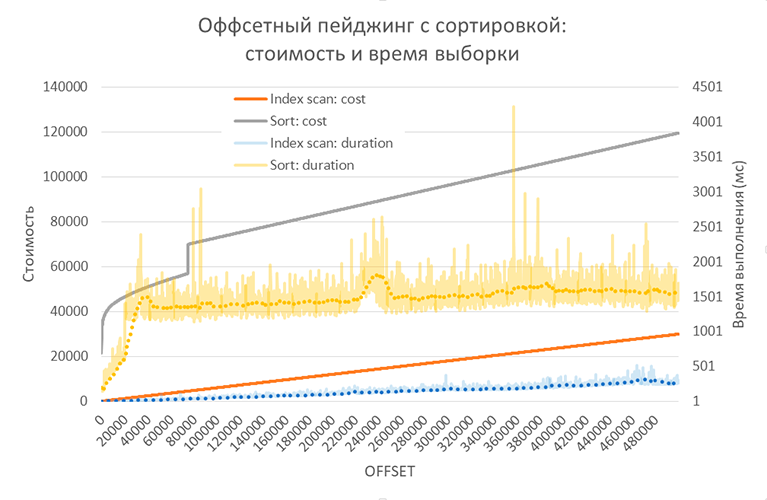
Вариант с использованием индекса – естественно лучше сортировки, но дороже по сравнению с вариантом без сортировки вообще.
В варианте без использования индекса любопытен порог, возникший для при смещениях в 20154-20155 записей. Причина в том, что в этот момент верхние сортируемые значения перестают умещаться в памяти (настройка PostgreSQL work_mem, равная по умолчанию 4Мб) и СУБД переключается с алгоритма быстрой сортировки в памяти на сортировку с сохранением промежуточных значений на диск.
SELECT * FROM test_paging ORDER BY last_name, id OFFSET 20155 LIMIT 10;Limit (cost=46582.39..46583.56 rows=10 width=25) (actual time=849.134..849.137 rows=10 loops=1)
-> Gather Merge (cost=44230.81..141459.90 rows=833334 width=25)
(actual time=842.371..857.326 rows=20165 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=43230.79..44272.46 rows=416667 width=25)
(actual time=786.262..788.072 rows=7207 loops=3)
Sort Key: last_name, id
Sort Method: external merge Disk: 11184kB
Worker 0: Sort Method: external merge Disk: 11600kB
Worker 1: Sort Method: external merge Disk: 14488kB
-> Parallel Seq Scan on test_paging (cost=0.00..11356.67 rows=416667 width=25)
(actual time=0.009..38.524 rows=333333 loops=3)
Planning Time: 0.055 ms
Execution Time: 860.577 msПричина скачка в значениях оценочной стоимости выборки без использования индекса при смещениях 74888-74889 записей мне неизвестна. Кто может подсказать – прошу в комментарии.
В качестве промежуточного итога можно сделать выводы:
- возможности пользователя в части сортировки должны быть ограниченными: сортировка допустима только по тем полям, по которым имеется соответствующий индекс; сортировка по нескольким полям может быть использована только в исключительных случаях – для таких кейсов должны применяться соответствующие аналитические инструменты и хранилища;
- индекс при необходимости должен включать дополнительное уникальное поле.
Курсорный пейджинг
Оффсетный пейджинг достаточно популяризирован и обычно по умолчанию есть во всяких ORM и пр. Его можно рассматривать как доступ к элементам массива по их номеру. При этом алгоритмическая сложность составляет O(offset + limit). Мы это видели выше на графике.
Курсорный пейджинг менее популяризирован и встречается реже. С точки зрения алгоритмической сложности он аналогичен доступу к связанному списку. Посмотрим, как он работает и какие условия ему необходимы.
Типичный запрос выглядит так:
SELECT * FROM test_paging WHERE id >= ? ORDER BY id LIMIT ?;Первый параметр – это последний идентификатор из предыдущей страницы или 0 в случае первой страницы. Второй параметр – размер страницы, увеличенный на единицу в случае первой страницы или двойку в случае всех остальных страниц. Увеличенный размер страницы позволяет сразу относительно недорого (без дополнительного запроса) определить, имеется ли следующая (предыдущая) страница или пользователь долистал все записи до последней страницы. Имеет смысл всегда использовать один и тот же запрос с разными параметрами, чтобы не размывать кэш, в котором хранятся SQL операторы, для которых уже выполнен синтаксический разбор.
План запроса для первой и любой другой страницы:
Limit (cost=0.42..0.85 rows=12 width=25) (actual time=0.019..0.023 rows=12 loops=1)
-> Index Scan using ix_test_paging_id on test_paging
(cost=0.42..17789.08 rows=498552 width=25)
(actual time=0.018..0.021 rows=12 loops=1)
Index Cond: (id >= 500000)
Planning Time: 0.063 ms
Execution Time: 0.034 ms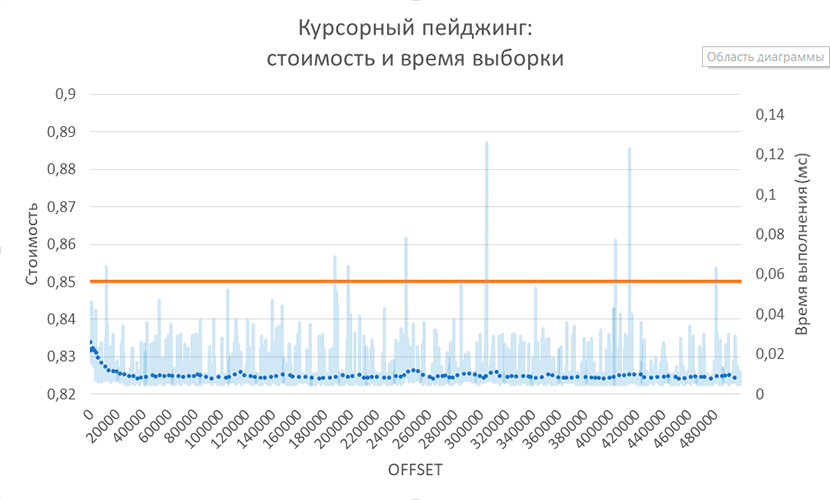
Тот случай, когда добавить нечего: O(limit). Подкупают и абсолютные значения, и тенденция. Нет проблем с проскальзыванием страниц. Таким должен быть пейджинг!
Но… чем мы за это платим?
- Мы просто так не можем перейти на произвольную страницу. Можно, конечно, выполнить «финт» с использованием
OFFSET, но мне лично кажется это в принципе избыточным, так как сложно представить, для чего вдруг пользователю может понадобиться перейти сходу на страницу с номером, например, 1234. Но это ограничение нужно учитывать. - По умолчанию мы можем перейти только на следующую и предыдущую страницы, так как всегда имеем их опорные идентификаторы. Немного усложнив логику приложения, можно сохранять шлейф идентификаторов большего количества страниц, на которых пользователь уже побывал, и организовать возможность перехода на счётное количество соседних страниц. По мне так это вполне допустимое решение.
- Вообще, реализация курсорного пейджинга – несколько более сложная задача по сравнению с оффсетным пейджингом.
- Мы должны всегда сортировать записи относительно уникальных и последовательных значений. Соответственно, для этого нужно такие значения иметь и построить для них индексы. По умолчанию эту роль всегда может выполнить первичный ключ – он уникален, индексирован и при любом раскладе можно обеспечить монотонное возрастание его значений (вспоминаем
ULID). Экзотические случаи таблиц без первичных ключей мы не рассматриваем.
А вот кейсы более сложных сортировок необходимо рассмотреть. При этом держим в уме, что в общем случае сортировок мы стараемся избегать, и, как правило, пользователю они не нужны.
Итак, как будет выглядеть запрос в курсорном пейджинге с учётом сортировки по одному полю? Очевидно, что в сортировке должно участвовать ещё и уникальное поле. Основная сортировка выполняется по неуникальному полю, а внутри диапазонов записей с повторяющимися значениями выполняется сортировка по уникальному полю. Таким образом обеспечивается воспроизводимая упорядоченная последовательность записей, которую можно разбить на страницы и листать. Условие отбора должно работать сразу для пары полей. В некоторых источниках всерьёз рассматривается вариант применения конкатенации двух полей в выражении условия (CONCAT(first_name, id) >= CONCAT(‘Peter’, 17)). Можно, конечно, создать функциональный индекс для этих целей, но нужно понимать, что результат конкатенации неоднозначен. Например, `a`+`bcd` даст такой же результат, как и `abc`+`d`. То есть в общем случае подход не применим.
Правильное условие должно быть построено с использованием операций над кортежами (в этом примере и далее нужно учитывать, что данные таблицы test_paging генерируются случайно, и в моей БД они будут другие):
SELECT * FROM test_paging WHERE (first_name, id) >= ('Abagail', 911281) ORDER BY first_name, id LIMIT 12;Limit (cost=0.42..1.17 rows=12 width=25) (actual time=0.014..0.023 rows=12 loops=1)
-> Index Scan using ix_test_paging_first_name_id on test_paging
(cost=0.42..62184.70 rows=996361 width=25)
(actual time=0.013..0.021 rows=12 loops=1)
Index Cond: (ROW((first_name)::text, id) >= ROW('Abagail'::text, 911281))
Planning Time: 0.095 ms
Execution Time: 0.044 msКак видно из плана выполнения запроса и собранной статистики, выросла оценка и время выполнения. Заметим, что успешно используется композитный индекс, и время выполнения всё ещё несопоставимо мало по сравнению с общим временем выполнения, включающим передачу результатов по сети (условно 20 мс и более).
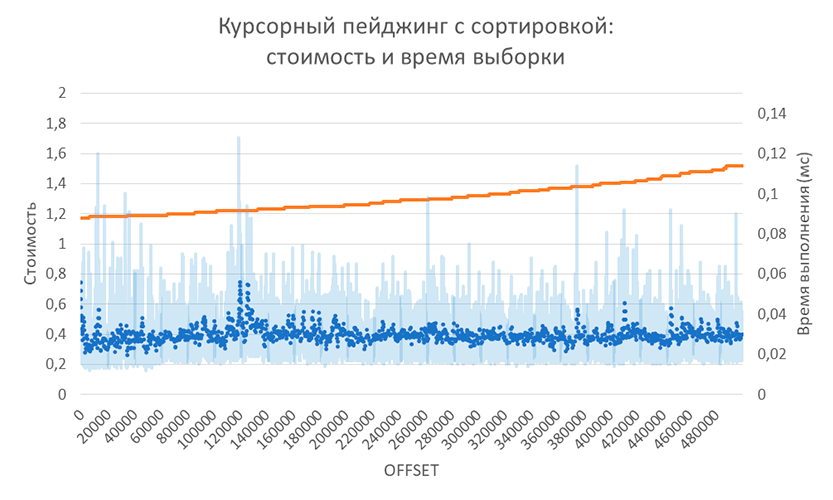
В тесте пришлось перебрать страницы без пропусков, так как для каждой очередной страницы требовались опорные значения (имя и идентификатор). На моём ноутбуке на весь тест для полумиллиона записей ушло 12 секунд. Мне кажется, всё пока идёт очень хорошо. С такими показателями можно организовать так называемый непрерывный пейджинг, когда очередные записи подгружаются при приближении скролла к концу текущей порции загруженных записей: прокрутка будет достаточно плавной.
Рассмотрим сортировку по двум полям. Пока забудем о том, что допускать такой сценарий работы – не лучшее решение для нагруженной БД. Типичный запрос будет выглядеть так:
SELECT * FROM test_paging WHERE (first_name, last_name, id) >= (?, ?, ?) ORDER BY first_name, last_name, id LIMIT ?;План запроса, его оценка и время выполнения не будет принципиально отличаться от варианта с сортировкой по одному полю. Оставлю проверку этого факта читателю.
А вот какой запрос должен получиться, если пользователь захочет (и ему позволить…) отсортировать имена по возрастанию, а фамилии – по убыванию? Очевидно, что операция над кортежем уже не может быть применена. Видимо, эта задачка скорее умозрительная. Мне приходит в голову только такое общее решение:
SELECT * FROM test_paging
WHERE (first_name > ?)
OR (first_name = ? AND last_name < ?)
OR (first_name = ? AND last_name = ? AND id >= ?)
ORDER BY first_name, last_name DESC, id;При условии наличия подходящих индексов, в зависимости от направлений сортировки и от номера страницы (от неё зависит селективность) у нас возможен редкий оптимистичный вариант, когда PostgreSQL примет решение выполнить операцию BitmapOr:
Sort (cost=420.14..420.41 rows=110 width=25) (actual time=0.272..0.278 rows=100 loops=1)
Sort Key: first_name, last_name DESC, id
Sort Method: quicksort Memory: 32kB
-> Bitmap Heap Scan on test_paging
(cost=14.48..416.41 rows=110 width=25)
(actual time=0.060..0.154 rows=100 loops=1)
Recheck Cond: (((first_name)::text > 'Zula'::text) OR (((first_name)::text = 'Zula'::text) AND ((last_name)::text < 'Harber'::text)) OR (((first_name)::text = 'Zula'::text) AND ((last_name)::text = 'Harber'::text) AND (id >= 228020)))
Heap Blocks: exact=100
-> BitmapOr (cost=14.48..14.48 rows=110 width=0)
(actual time=0.048..0.048 rows=0 loops=1)
-> Bitmap Index Scan on ix_test_paging_fn_ln_id (cost=0.00..4.43 rows=1 width=0)
(actual time=0.005..0.005 rows=0 loops=1)
Index Cond: ((first_name)::text > 'Zula'::text)
-> Bitmap Index Scan on ix_test_paging_fn_ln_id (cost=0.00..5.52 rows=110 width=0)
(actual time=0.037..0.037 rows=98 loops=1)
Index Cond: (((first_name)::text = 'Zula'::text) AND ((last_name)::text < 'Harber'::text))
-> Bitmap Index Scan on ix_test_paging_fn_ln_id (cost=0.00..4.44 rows=1 width=0)
(actual time=0.005..0.005 rows=2 loops=1)
Index Cond: (((first_name)::text = 'Zula'::text) AND ((last_name)::text = 'Harber'::text) AND (id >= 228020))
Planning Time: 0.297 ms
Execution Time: 0.328 msТакже возможен более вероятный пессимистичный вариант, когда PostgreSQL вынужден будет сканировать таблицу:
Sort (cost=155731.58..158230.75 rows=999670 width=25) (actual time=3357.573..4437.847 rows=999902 loops=1)
Sort Key: first_name DESC, last_name, id
Sort Method: external merge Disk: 37240kB
-> Seq Scan on test_paging (cost=0.00..32190.00 rows=999670 width=25)
(actual time=4.289..288.607 rows=999902 loops=1)
Filter: (((first_name)::text < 'Zula'::text) OR (((first_name)::text = 'Zula'::text) AND ((last_name)::text > 'Harber'::text)) OR (((first_name)::text = 'Zula'::text) AND ((last_name)::text = 'Harber'::text) AND (id >= 228020)))
Rows Removed by Filter: 98
Planning Time: 0.177 ms
JIT:
Functions: 2
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 0.926 ms, Inlining 0.000 ms, Optimization 0.640 ms, Emission 3.253 ms, Total 4.819 ms
Execution Time: 4500.573 msВ любом случае лучшим решением выглядит не давать пользователю возможность выполнять такие сортировки.
В качестве промежуточного итога хочу перечислить некоторые соображения, которые на мой взгляд имеют смысл с точки зрения взаимодействия с пользователем и общей производительности БД:
- Однозначно не стоит давать пользователю выполнять сложные сортировки. Наоборот, имеет смысл ограничить состав полей, доступных для для сортировки.
- Имеет смысл устроить интерфейс пользователя таким образом, чтобы пользователю приходилось применять достаточно селективный предикат, естественным образом ограничивающий выборку. Например, это может быть выбор некоторого периода времени, с которым пользователь собирается работать.
- Имеет смысл убрать возможность перехода пользователя к произвольной странице. Можно оставить возможность перехода только на соседние страницы.
- Возможность подсчёта общего количества страниц имеет смысл ограничить: убрать совсем или предусмотреть только при явном указании пользователя выполнить этот подсчёт, так как такой подсчёт будет означать как минимум вычитывание индекса по первичному ключу целиком или частичное вычитывание индекса при фильтрации с селективным предикатом.
- Запросы к БД имеет смысл выполнять только с ограничением по времени (например,
setQueryTimeout(int)в случаеJDBC). По истечении времени выводить пользователю соответствующую ошибку.
Мне кажется, с учётом перечисленных соображений с помощью курсорного пейджинга можно создавать быстрые и удобные листинги.
Спецификация GraphQL Connection
Не могу не упомянуть спецификацию от facebook как одно из красивых (на мой личный вкус и цвет, конечно же) решений для курсорного пейджинга. Чтобы не тратить время на чтение описания, посмотрим сразу на пример. Заходим на https://developer.github.com/v4/explorer/, вводим текст запроса:
{
repository(name: "engine", owner: "docker") {
pullRequests(
first: 3, # 1
after: "Y3Vyc29yOnYyOpK5MjAyMC0wMS0yMlQyMDowNjozNCswMzowMM4V0DI3", # 2
orderBy: {field: CREATED_AT, direction: DESC} # 3
) {
edges {
node { # 4
url
title
}
cursor # 5
}
pageInfo { # 6
hasPreviousPage
hasNextPage
}
}
}
}
Жмём Ctrl-Enter. Вуаля! Что-то произошло…
- Здесь мы указали количество записей, которые нам нужно запросить.
- Это опорный идентификатор записи, которую мы уже просмотрели на предыдущей странице. Если убрать этот параметр, то мы получим первую страницу.
- Требуемая сортировка. Кстати, тут можно указать только одно поле и только из очень ограниченного списка.
- Перечень запрашиваемых полей.
- По сути это идентификатор для каждой записи. Это значение для одной из записей мы указали в п. 2.
- Сведения о текущей странице. Нас интересует два значения: существует ли предыдущая и следующая страница.
В ответе сервера мы получили несколько pull-request’ов популярного репозитория на github’е – docker/engine:
{
"data": {
"repository": {
"pullRequests": {
"edges": [
{
"node": {
"url": "https://github.com/docker/engine/pull/453",
"title": "[19.03] vendor: update buildkit to 926935b5"
},
"cursor": "Y3Vyc29yOnYyOpK5MjAyMC0wMS0yMlQwMjo1MjowNSswMzowMM4VynV6"
},
{
"node": {
"url": "https://github.com/docker/engine/pull/452",
"title": "[19.03] Bump Golang 1.12.15"
},
"cursor": "Y3Vyc29yOnYyOpK5MjAyMC0wMS0xN1QxNzoxNzoxNSswMzowMM4VtKzr"
},
{
"node": {
"url": "https://github.com/docker/engine/pull/451",
"title": "[19.03 backport] assorted swagger / API docs fixes"
},
"cursor": "Y3Vyc29yOnYyOpK5MjAyMC0wMS0xN1QxMzoyNTozOCswMzowMM4Vs0nl"
}
],
"pageInfo": {
"hasPreviousPage": true,
"hasNextPage": true
}
}
}
}
}Почти каждая коллекция запрашивается таким образом. Лично я в своё время взял подход на вооружение.
Ещё пэйджинг!
Тут можно было бы закончить, но справедливости ради, считаю, нужно перечислить ещё некоторые виды пейджинга как представителей не само лучшей и распространённой практики.
Курсоры. Можно открыть курсор на уровне БД и листать его. В случае двухзвенки вариант вполне можно рассмотреть: у вас имеются гарантии самой БД, что результат останется консистентным с учётом текущего уровня изоляции транзакции; реализация достаточно проста. Из минусов следует упомянуть длинную транзакцию, которая будет потреблять существенные ресурсы на всём протяжении своего существования, невозможность использования пулов соединений, невозможность использования в многозвенных архитектурах, то есть во всех современных архитектурах.
Существуют реализации пейджинга с использованием сведений из БД о том, в какой блок (страницу) физически размещена запись. Не будем погружаться в этот подход, он довольно странный: фильтрация не доступна, размер страницы непостоянен, применим только для отдельных СУБД.
Также иногда предпочитают выбрать идентификаторы всех записей в память на уровне приложения, разбить их на страницы и уже точечно запрашивать записи с помощью известных идентификаторов. Очевидно, что такой подход не применим для серьёзных объёмов данных.
Вместо заключения
Так получилось, что большая часть текста получилась про курсорный пейджинг. И мне кажется, что он действительно интересен и показывает лучшие показатели производительности по сравнению со всеми остальными видами пейджинга. Те ограничения, которые он за собой тянет, – это по сути только сложность реализации. Все остальные минусы так или иначе универсальны для всех видов пейджинга.



